밑바닥부터 시작하는 딥러닝을 바탕으로 제작하였습니다.
8.1. 더 깊게
■ 더 깊은 MNIST 신경망

이와 같이 구성된 CNN을 만들고자 합니다. 여기에서 사용하는 합성곱 계층은 모두 3x3 크기의 작은 필터로, 층이 깊어지면서 채널 수가 더 늘어나는 것이 특징입니다(합성곱 계층의 채널 수는 앞 계층에서부터 순서대로 16, 16, 32, 32, 64, 64로 늘어갑니다). 또 그림과 같이 풀링 계층을 추가하여 중간 데이터의 공간 크기를 점차 줄여갑니다. 그리고 마지막 단의 완전연결 계층에서는 드롭아웃 계층을 사용합니다.
가중치 초깃값으로 He 초깃값을 사용하고, 가중치 매개변수 갱신에는 Adam을 사용하겠습니다. 이렇게 생성한 CNN의 정확도는 99.38%라는 매우 훌룡한 성능을 보여줍니다.
■ 정확도를 더 높이려면
이미 좋은 성능을 보여주지만 더 좋은 결과를 얻기 위한 방법에 대해서 알아보겠습니다. 앙상블 학습, 학습률 감소, 데이터 확장 등 여러가지 방법이 존재하는데 특히 데이터 확장은 손쉬운 방식이면서도 정확도 개선에 아주 효과적입니다.
데이터 확장(data augmentation)은 입력 이미지를 알고리즘을 동원해 인위적으로 확장합니다.

옆에 사진과 같이 이미지를 회전하거나 세로로 이동하는 등 미세한 변화를 주어 이미지의 개수를 늘리는 방법입니다. 이는 특히 데이터가 몇 개 없을 때 특히 효과적인 수단입니다.
데이터 확장은 더 다양한 방법이 존재합니다. 예를 들어 이미지 일부를 잘라내는 crop이나 좌우를 뒤집는 flip등이 있습니다. 일반적인 이미지에는 밝기 등의 외형 변화나 확대, 축소 등의 스케일 변화도 효과적입니다.
■ 층을 깊게 하는 이유
층을 깊게 하는 것의 중요성은 ILSVRC로 대표되는 대규모 이미지 인식 대회의 결과에서 파악할 수 있습니다. 층을 깊게 할 때의 이점을 설명하겠습니다.
1. 신경망의 매개변수 수가 줄어든다.
층을 깊게 한 신경망은 깊지 않은 경우보다 적은 매개변수로 같은 (혹은 그 이상) 수준의 표현력을 달성할 수 있습니다. 예를 들어

5x5 피렅로 구성된 합성곱 계층이 있습니다. 출력 데이터의 각 노드가 입력 데이터의 어느 영역으로부터 계산되었는지가 중요합니다. 이 예에서는 각각의 출력 노드는 입력 데이터의 5x5 크기 영역에서 계산됩니다.
이번에는 3x3 의 합성곱 연산을 2회 반복하는 경우를 생각해보겠습니다.

이 경우 출력 노드 하나는 중간 데이터의 3x3 영역에서 계산됩니다. 중간 영역의 노드 하나는 입력 데이터의 5x5 크기의 영역에서 계산되어 나오는 것을 볼 수 있습니다. 즉, 출력 데이터는 입력 데이터의 5x5 영역을 보고 계산됩니다. 5x5의 합성곱 연산 1회는 3x3의 합성곱 연산을 2회 수행하여 대체할 수 있습니다. 그리고 5x5 연산의 매개변수는 25개(5x5)인 반면, 3x3은 총 18개(2x3x3)이며, 매개변수 수는 층을 반복할수록 적어집니다. 그리고 그 개수의 차이는 층이 깊어질수록 커집니다.
2. 학습의 효율성
층을 깊게 하면 학습 데이터의 양을 줄여 학습을 고속으로 수행할 수 있습니다. 앞단의 합성곱 계층에서는 에지 등의 단순한 패턴에 뉴런이 반응하고 층이 깊어지면서 텍스처와 사물의 일부와 같이 점차 더 복잡한 것에 반응합니다. 신경망을 깊게 하면 학습해야 할 문제를 계층적으로 분해할 수 있습니다.
3. 정보를 계층적으로 전달
층을 깊게하면 정보를 계층적으로 전달할 수 있습니다. 예를 들어 에지를 추출한 층의 다음 층은 에지 정보를 쓸 수 있고, 더 고도의 패턴을 효과적으로 학습하리라 기대할 수 있습니다.
8.2. 딥러닝 모델
■ VGG
VGG는 합성곱 계층과 풀링 계층으로 구성되는 기본적인 CNN입니다.

비중 있는 층(합성곱 계층, 완전연결 계층)을 모두 16층(혹은 19층)으로 심화한 게 특징입니다(층의 깊이에 따라서 'VGG16'과 'VGG19'로 구분하기도 합니다). VGG에서 주목할 점은 3x3의 작은 필터를 사용한 합성곱 계층을 연속으로 거친다는 것입니다. 합성곱 계층을 2~4회 연속으로 풀링 계층을 두어 크기를 절반으로 줄이는 처리를 반복합니다.
■ GoogLeNet
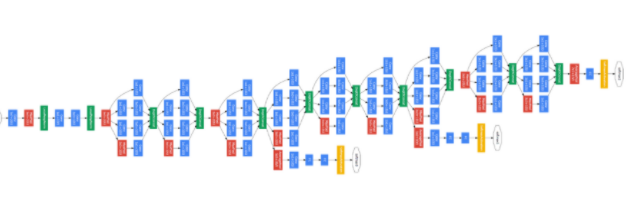
GoogLeNet 구조는 위와 같습니다. 그림의 사각형이 합성곱 계층과 풀링 계층 등의 계층을 나타냅니다. GoogLeNet은 CNN과 같지만 세로 방향 깊이뿐 아니라 가로 방향도 깊게 층이 존재한다는 것이 특징입니다. GoogLeNet에는 가로 방향에 '폭'이 있습니다. 이를 인셉션 구조라 하며, 그 기반 구조는
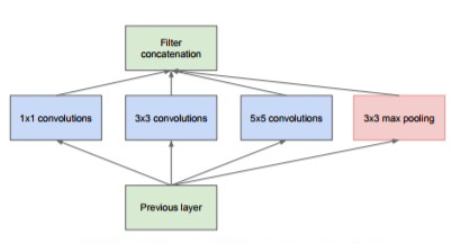
이와 같습니다. 인셉션 구조는 크기가 다른 필터(와 풀링)를 여러 개 적용하여 그 결과를 결합합니다. 이 인셉션 구조를 하나의 빌딩 블록으로 사용하는 것이 GoogLeNet의 특징입니다.
■ ResNet
ResNet(Residual Network)은 마이크로소프트의 팀이 개발한 네트워크로 지금까지 보다 층을 더 깊게 할 수 있습니다. 딥러닝은 층을 깊게 하는 것이 성능 향상에 중요하지만 딥러닝 학습에서는 층이 지나치게 깊으면 학습이 잘 되지 않고, 오히려 성능이 떨어지는 경우도 많습니다. ResNet은 그러한 문제를 해결하기 위해서 스킵연결(skip connection)을 도입합니다. 이 스킵연결 덕분에 층의 깊이에 비례해 성능을 향상시킬 수 있습니다.
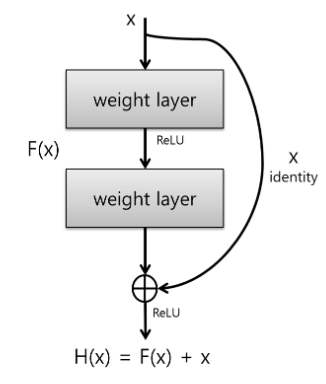
스킵연결은 위와 같이 입력 데이터를 합성곱 계층을 건너뛰어 출력에 바로 더하는 구조입니다. 입력 x를 연속한 두 합성곱 계층을 건너뛰어 출력에 바로 연결합니다. 이 단축 경로가 없었다면 두 합성곱 계층의 출력이 F(x)가 되나, 스킵 연결로 인해 F(x) + x가 되는 게 핵심입니다. 스킵 연결은 층이 깊어져도 학습을 효율적으로 할 수 있도록 해주는데, 이는 역전파 때 스킵 연결이 신호 감쇠를 막아주기 때문입니다.
'Deep Learning(강의 및 책) > 밑바닥부터 시작하는 딥러닝' 카테고리의 다른 글
| 7. 합성곱 신경망(CNN) (0) | 2022.02.18 |
|---|---|
| 6. 학습 관련 기술들 (0) | 2022.02.15 |
| 5. 오차역전파법 (0) | 2022.02.14 |
| 4. 신경망 학습 (0) | 2022.02.07 |
| 3. 신경망 (0) | 2022.02.07 |



