[논문] YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
https://arxiv.org/abs/2112.02418
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
YourTTS는 multi-lingual zero-shot multi-speaker TTS를 수행할 수 있습니다. 저자들의 method는 VITS model을 기반으로 하며, 여러 가지 새로운 변경들을 추가하여 zero-shot multi-speaker and multi-lingual training이 가능합니다. 저자들은 VCTK dataset에서 zero-shot multi-speaker TTS에 대해서 SOTA를 달성했으며, SOTA zero-shot voice conversion과 유사한 성능을 달성했습니다. 그리고 저자들의 method가 single-speaker dataset만으로 target language에서 유망한 결과를 얻었으며, 이는 low-resource language에 대해서도 zero-shot multi-speaker TTS와 zero-shot voice conversion system에서의 가능성을 보여주었습니다. 마지막으로 YourTTS model을 1분보다 더 짧은 speech를 가지고 fine-tuning 했을 때 SOTA voice similarity를 달성할 수 있었으며 합리적인 quality도 보였다고 합니다.
Introduction
TTS system은 최근 몇 년 동안 deep learning 방식을 사용하여 많은 발전을 이루었습니다. 대부분의 TTS system은 single speaker's voice에 맞춰져 있지만, 최근에는 몇 초 정도의 speech만 가지고도 학습 때 보지 못했던 새로운 speaker의 voice를 가지고 speech를 합성하는 것에 대한 관심이 증가하고 있습니다. 이러한 방식을 zero-shot multi-speaker TTS (ZS-TTS)라 부릅니다.
deep learning을 사용하는 ZS-TTS 예시 중 하나는 DeepVoice 3 method를 발전시켰습니다. 이후 Tacotron2 는 generalized end-to-end loss를 사용하여 학습된 speaker encoder로부터 추출된 외부 speaker embedding을 사용합니다. 이를 통해 target speaker과 유사한 speech를 합성할 수 있게 됩니다. Attentron은 다양한 reference sample로부터 detailed style을 추출하기 위해 attention mechanism을 사용하는 fine-grained encoder와 coarse grained encoder를 제안했습니다. 여러 reference sample을 사용한 결과로, unseen speaker에 대해서 더 좋은 voice similarity를 달성했다고 합니다. ZSM-SS는 normalizaiton architecture를 사용하는 Transformer-based model이며, Wav2vec 2.0 기반 외부 speaker encoder를 사용합니다. 저자들은 normalized architecture에 speaker embedding, pitch, energy를 condition으로 적용했습니다. SG-GlowTTS는 ZS-TTS에 처음으로 flow-based model을 적용한 연구입니다. 이전 연구들과 비교할 만한 quality를 유지한 상태로 unseen speaker와의 voice similarity를 향상시켰습니다.
이러한 발전에도 불구하고, 학습 과정에서의 observed and unobserved speaker 사이 유사도 차이는 여전히 풀어야 할 문제로 남아있습니다. ZS-TTS model은 여전히 학습할 때 많은 수의 speaker를 필요로 하며, low-resource language에 대한 high-quality model을 얻는데 어려움이 발생하게 됩니다. 그리고 ZS-TTS model의 현재 quality는 충분히 좋은 것은 아니며, 특히 학습 과정에서 봤던 speech 특성과 다른 target speaker에 대해서는 특히 심하다고 합니다. SC-GlowTTS가 VCTK dataset 중 11명 speaker만 사용하여 유망한 결과를 달성했지만, unseen voice에 대한 generalization이 잘 이뤄지지는 않았다고 합니다. ZS-TTS와 동시에 multilingual TTS도 발전되고 있으며, 이는 동시에 여러 언어에 대해 학습하는 것을 목표로 합니다. 이러한 model들 중 일부는 문장의 일부를 다른 언어로 변경하면서 목소리를 그대로 유지하는 것을 성공했습니다.
이 논문에서 저자들은 zero-shot multi-speaker and multi-lingual training에 초점을 맞춘 새로운 연구인 YourTTS을 제안합니다. multi-speaker TTS에서 SOTA를 달성했을 뿐만 아니라, zero-shot voice conversion에 대해서도 SOTA와 유사한 결과를 보여준다고 합니다. 저자들의 새로운 zero-shot multi-speaker TTS는 다음과 같은 contribution이 있습니다.
- English Language에서 SOTA를 달성했습니다.
- zero-shot multi-speaker TTS에 대해서 multi-lingual을 수행하는 첫 연구입니다.
- model을 학습할 때 target language에 대해 오직 1명의 speaker만 있어도 유망한 quality와 similarity를 보여주는 zero-shot multi-speaker TTS and zero-shot Voice Conversion이 가능합니다.
- 학습 과정에서 봤던 voice/recording characteristic과 매우 다른 speaker로의 fine-tuning을 수행할 때, 1분보다 짧은 speech로도 충분하며 good similarity and quality result를 보여줍니다.
YourTTS Model
YourTTS는 VITS를 기반으로 설계되었지만 zero-shot multi-speaker and multilingual training을 위해 여러 수정을 포함합니다. 먼저 이전 연구들과 다르게, 저자들의 model은 phoneme input 대신 raw text를 input으로 사용합니다. 이를 통해 open-source grapheme-to-phoneme converter가 없는 언어에서도 더 현실적인 결과를 얻을 수 있게 됩니다.
이전 연구들처럼 저자들은 transformer-based text encoder를 사용합니다. 하지만 multi-lingual 학습을 위해, 저자들은 각 input character에 학습 가능한 4-dimensional language embedding을 concatenate 합니다. 그리고 transformer block 수를 10개까지 늘리고 hidden channel도 196까지 늘렸습니다. decoder의 경우, VITS model처럼 저자들은 4개 affine coupling layer를 stack 하고, 각 layer들은 4개 WaveNet residual block을 stack 한 형태입니다.
vocoder로 저자들은 HiFi-GAN ver 1을 사용했습니다. 그리고 discriminator도 사용했습니다. 또한 효율적인 end2end 학습을 위해, 저자들은 VAE를 사용하여 TTS model에 vocoder를 connect 했습니다. 이를 위해 Posterior Encoder를 사용했으며, 이 encoder는 16개 non-causal WaveNet residual block으로 구성되어 있습니다. posterior encoder는 input으로 linear spectrogram을 받고 latent variable을 예측합니다. 이 latent variable은 vocoder와 flow-based decoder의 input으로 사용됩니다. 그래서 mel-spectrogram과 같은 중간 representation을 필요로 하지 않습니다. 이는 model이 중간 representation을 학습할 수 있게 만들어 줍니다. 이를 통해 vocoder와 TTS를 따로따로 학습하는 two stage training보다 더 좋은 결과를 달성하게 됩니다. 그리고 저자들의 model이 input text로부터 다양한 rhythm을 가진 speech를 합성할 수 있도록 만들기 위해, 저자들은 stochastic duration predictor를 사용했습니다.

YourTTS의 학습, 추론 과정은 위와 같습니다. 위 식에서 +는 concatenate를 의미합니다. red connection은 gradient가 전달되지 않는 부분을 의미하고 점산은 option입니다. 저자들은 HiFi-GAN discriminator를 간단하게 수정했습니다.
model이 zero-shot multi-speaker generation을 수행할 수 있도록, 저자들은 flow-based decoder의 모든 affine coupling layer, posterior encoder, vocoder에 speaker embedding을 condition으로 제공했습니다. 저자들은 coupling layer의 residual block 뿐만 아니라 posterior encoder에 global conditioning을 사용했습니다. 그리고 저자들은 speaker embedding과 text encoder output, decoder output을 더해 duration predictor, vocoder에 pass 했습니다. 저자들은 linear projection layer를 사용하여 dimension을 맞춘 다음 element-wise summation을 수행했습니다.
그리고 저자들은 Speaker Consistency Loss (SCL)을 final loss로 사용했습니다. pre-traiend speaker encoder를 사용하여 생성된 audio와 ground-truth audio의 speaker embedding을 추출하였으며, 이 embedding 사이 cosine similarity를 maximize 하도록 학습시키는 loss입니다.

Φ()를 speaker embedding을 구해주는 function이라고 하고, cos_sim을 cosine similarity function이라고 하고, α를 final loss에서의 SCL의 영향력을 control 하는 positivie real number라 하고, n을 batch size라 하면, 위와 같이 SCL을 정의할 수 있게 됩니다. g는 ground truth audio, h는 generated speaker audio를 나타냅니다.
학습 과정에서 posterior encoder는 linear spectrogram과 speaker embedding을 input으로 받아 latent variable z를 predict 합니다. latent variable과 speaker embedding은 waveform을 생성하는 GAN-based vocoder generator의 input으로 사용됩니다. end-to-end vocoder 학습의 효율성을 위해, 저자들은 random 하게 z로부터 상수 길이 partial sequence를 sample 했습니다. flow-based decoder는 latent variable z와 speaker embedding을 prior distribution P_{Z_p}의 condition으로 만드는 것을 목표로 합니다. P_{Z_p} 분포를 text encoder output과 align 시키기 위해, 저자들은 Monotonic Alignment Search (MAS)를 사용합니다. stochastic duration predictor는 input speaker embedding, language embedding, MAS를 통해 구한 duration을 받습니다. 사람 같은 speech의 rhythm을 생성하기 위해, stochastic duration predictor는 phoneme duration의 log-likelihood의 variational lower bound를 objective로 합니다.
inference 할 때는 MAS를 사용하지 않습니다. 대신 text encoder와 random noise를 inverse stochastic duration predictor에 feed 한 다음 정수로 변환하여 P_{Z_p} 분포를 예측합니다. 이 방법에서 latent variable z_p는 distribution P_{Z_p}로부터 sampling 됩니다. inverted Flow-based decoder는 latent variable z_p와 speaker embedding을 input으로 받고, z_p를 vocoder generator의 input으로 pass 되는 latent variable z로 변환합니다. 그 결과 최종 waveform을 합성할 수 있습니다.
Experiments
Speaker Encoder
speaker encoder로 저자들은 H/ASP model을 사용합니다. 이는 Prototypical Angular plus Softmax loss function을 가지고 학습되었습니다. 이 model은 VoxCeleb1 test subset에서 SOTA를 달성했습니다.
Audio Datasets
저자들은 model을 학습하기 위해 각 언어마다 1개 dataset을 사용하여 3가지 언어에 대한 실험을 진행했습니다. 모든 dataset의 경우, pre-processing을 진행해 비슷한 loudness의 sample로 만들고 긴 시간의 slience는 제거했습니다. 모든 audio는 16kHz로 만들고 voice activity detection을 사용하여 silence를 제거했습니다. 그리고 저자들은 모든 audio에 RMS-based normalization을 사용하여 -27dB를 적용하는 정규화를 수행했습니다.
- English
VCTK dataset은 109명 speaker, 44시간 길이 speech로 구성됩니다. sampling rate는 48kHz입니다. test set은 11명의 speaker가 존재하며 다른 set과는 겹치지 않습니다.
- Protuguese
TTS-Portuguese Corpus라는 single-speaker dataset을 사용했습니다. 10시간 길이의 speech이며 48kHz입니다. studio가 아닌 환경에서 녹음되었기 때문에, 배경 noise가 포함되어 있습니다. FullSubNet model을 denoiser로 사용하고 data를 16kHz로 resample 했습니다.
- French
M-AILABS dataset을 사용했으며, 이는 LibriVox를 기반으로 하는 dataaset입니다. 2명의 여성 (104시간)과 3명의 남성 (71시간)을 사용했습니다.
영어에서의 model의 zero-shot multi-speaker 성능을 평가하기 위해, 저자들은 11명의 VCTK speaker를 사용하여 test를 진행했습니다. VCTK domain 외의 성능을 평가하기 위해, 저자들은 LibriTTS dataset의 10명 speaker에 대해서도 test를 진행했습니다. Portuguese의 경우, 저자들은 Multilingual LibriSpeech (MLS) dataset에서 10명 speaker를 골랐습니다. 마지막으로 speaker adaptation 실험에서는 더 현실적인 설정을 모방하기 위해, Common Voice dataset에서 4명 speaker를 선택해 사용했습니다.
Experimental setup
저자들은 yourTTS에 대해 4가지 실험을 수행했습니다. Experiment 1은 단일 언어 VCTK dataset을 사용합니다. Experiment 2는 2가지 언어에 대해 VCTK와 TTS-Portuguese를 사용합니다. Experiment 3는 3가지 언어에 대해 VCTK, TTS-Portuguese, M-AILABS french dataset을 사용합니다. Experiment 4는 experiment3에서 구한 model에 대해 추가적인 1151명의 english speaker로 학습을 더 진행합니다.
모든 실험에서 학습 속도를 향상시키기 위해, 저자들은 transfer learning을 수행했습니다. experiment 1에서 저자들은 LJSpeech에 대해 1M 번 학습된 model에 추가적으로 VCTK datase을 이용해 200K step 학습을 진행했습니다. 하지만 이러한 변화 때문에 model의 몇 layer들은 weight의 형태가 맞지 않아 random 하게 초기화되었습니다. experiment 2, 3에서는 이전 실험에서 학습된 model을 이어서 약 140k step 더 학습시켰으며, 각 언어마다 140k step 학습을 진행했습니다. 그리고 각 실험에서 fine-tuning은 Speaker Consistency Loss를 사용하여 50k step 진행되었으며 여기서 α = 9로 설정했습니다. 마지막으로 experiment 4의 경우, 저자들은 fine-tuned experiment 3 model을 가지고 이어서 학습을 진행했습니다. 최신 ZS-TTS는 VCTK dataset만 사용하는데, 이 dataset은 109명이라는 제한된 수의 speaker만 포함하고 있으며 recording condition의 다양성이 매우 적습니다. 그래서 일반적으로 VCTK만 가지고 학습한다면 ZS-TTS model은 학습 과정과 매우 다른 recording condition or voice characteristic에 대해서는 일반화 성능이 많이 부족하게 됩니다.
Results and Discussion
이 논문에서 저자들은 Mean Opinion Score (MOS)를 사용하여 합성된 speech의 quality를 평가합니다. 합성된 voice와 원래 speaker 사이 유사도를 평가하기 위해, 저자들은 두 audio에 대해서 speaker encoder를 적용해 speaker embedding을 추출한 후 Speaker Encoder Cosine Similarity (SECS)을 계산합니다. similarity는 -1 ~ 1 사이고, 값이 클수록 유사도가 높다는 것을 나타냅니다. 이전 연구들처럼 Resemblyzer package의 speaker encoder를 사용하여 SECS를 계산합니다. 그리고 저자들은 Similarity MOS (Sim-MOS)를 구했습니다.
실험은 3가지 언어를 포함하지만, MOS metric의 high cost 때문에 가장 speaker 수가 많은 영어와 가장 수가 적은 포르투갈어에 대해서만 MOS evaluation을 진행했습니다. 그리고 unseen speaker에 대해서만 평가를 진행했습니다.
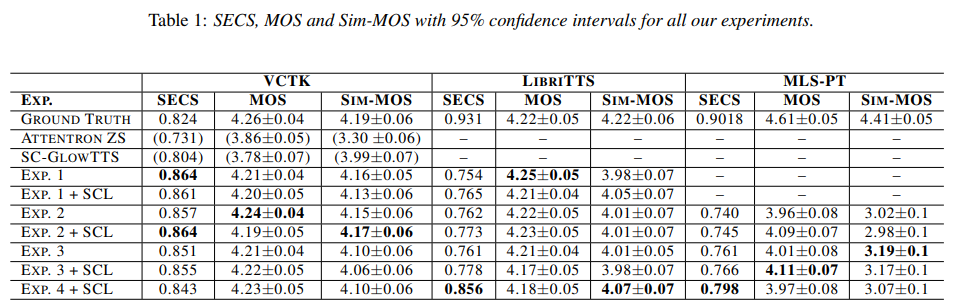
실험 결과는 위와 같습니다. VCTK, LibriTTS가 English에 대한 실험이고, MLS-PT가 Portuguese에 대한 결과입니다.
VCTK dataset
VCTK dataset의 경우, experiment 1, 2 + SCL에서 가장 좋은 simialirty 결과를 얻을 수 있었습니다. SECS는 동일한 성능을 기록했으며, Sim-MOS는 유사한 결과를 보여줍니다. SECS에 따르면, 3개 실험 중 2개 실험에서 SCL을 사용했을 때 성능 향상되는 결과를 보였습니다. 그리고 VCTK dataset에 대해, 모든 SECS 결과가 ground truth보다 높은 것을 볼 수 있습니다. 이는 VCTK dataset 자체의 특징으로 설명될 수 있습니다. 예를 들어 대부분의 audio에서 큰 숨소리가 있기 때문에 이러한 결과를 보일 수 있다고 합니다. speaker encoder는 이러한 feature를 처리하지 못해 ground-truth의 secs가 낮아졌을 가능성이 있습니다. similarity (SECS and Sim-MOS)와 quality (MOS) 결과가 가장 좋은 경우, ground truth와 유사한 결과를 보여줍니다. 그리고 zero-shot mutli-speaker TTS에서는 SOTA를 달성하는 모습을 보여줍니다.
LibriTTS dataset
저자들은 experiment4에서 가장 좋은 similarity를 달성했습니다. 다른 실험들보다 더 많은 speaker를 사용했기 때문에 이러한 결과를 얻었다고 합니다. 뿐만 아니라 monolingual case에서도 MOS에 대해서 가장 좋은 모습을 보여줍니다. 아마 학습 dataset의 quality 때문이라고 저자들은 생각한다고 합니다. Experiment 1은 VCTK dataset만 사용하며, 이는 다른 dataset보다 더 좋은 quality를 보여줍니다.
Zero-Shot Voice Conversion
SC-GlowTTS model와 같이, encoder에 speaker identity에 대한 어떠한 정보를 제공하지 않기 때문에, encoder에 의해 예측된 분포가 speaker에 독립적이게 됩니다. 그러므로 YourTTS가 model의 Posterior Encoder, decoder, HiFi-GAN Generator를 사용하여 voice를 변환할 수 있습니다. 그래서 YourTTS를 외부 speaker embedding에 condition화 되도록 만들었기 때문에, YourTTS는 zero-shot voice conversion setting에서 unssen speaker에 대한 voice도 생성할 수 있습니다. 저자들의 model을 비교하기 위해, 저자들은 8명 speaker를 선택해서 test를 진행했습니다.
Intra-lingual results
English speaker를 다른 English speaker로 변환하는 zero-shot voice conversion의 경우, 저자들의 model이 MOS는 4.20을 달성하고 Sim-MOS는 4.07을 달성했습니다. AutoVC은 MOS를 3.54를 달성했고, Sim-MOS는 1.91을 달성했습니다. 반면에 NoiseVC model은 MOS를 3.38을 달성했으며, Sim-MOS는 3.05를 달성했습니다. 저자들의 model이 zero-shot voice conversion에 있어 SOTA와 비교할 만큼의 성능을 달성했습니다. 비록 model이 더 많은 data와 speaker에 대해 학습을 진행했지만(experiment 4), VCTK의 유사도는 experiment 1이 더 좋은 결과를 보여주기도 합니다. 그러므로 YourTTS를 VCTK dataset으로만 학습한 경우 매우 유사하거나 훨씬 뛰어난 zero-shot voice conversion 성능을 보여줄 수 있을 것이라고 합니다.
Portuguese speaker에서 다른 Portuguese speaker로의 zero-shot voice conversion에 대한 MOS는 3.64를 달성하고 Sim-MOS는 3.43을 달성했습니다. 저자들의 model이 남성에 대한 voice transfer (3.80)보다 여성에 대한 voice transfer (3.35)에서 더 좋지 않은 모습을 보여주었습니다. 이는 Portuguese language에 대한 여성 speaker 수가 부족하기 때문이라고 합니다.
Cross-lingual results
English와 Portuguese speaker 사이 변환은 Portuguese speaker 사이 변환만큼 잘 동작합니다. 하지만 Portuguese speaker에서 English speaker로의 변환은 MOS 결과가 떨어지는 모습을 보여줍니다. 특히 남성 Portuguese speaker에서 여성 English speaker로의 변환이 크게 quality가 떨어지는 결과를 보여줍니다. model 학습에서 femal speaker가 부족하기 때문에 female speaker로의 변환이 좋지 않은 결과를 보인다고 합니다.
Speaker Adaptation
다른 recording condition은 zero-shot multi-speaker TTS model의 일반화는 challenge입니다. 학습에서 사용된 voice와 매우 다른 voice를 가지는 speaker 또한 challenge입니다. 그럼에도 불구하고 저자들의 model은 새로운 speaker/recording condition으로의 adaptation의 잠재력을 보이기 위해, 저자들은 20~61초 길이의 speech를 선택하여 sample을 만들었습니다. 2명의 Portuguese speaker와 2명의 English speaker를 선택했으며, 이 4명에 대해 각 speaker에 대한 SCL를 적용하여 fine-tuning 했습니다.
fine-tuning 과정 중 multilingual synthesis의 성능 저하를 막기 위해, experiment 4에서 사용된 dataset을 사용했습니다. 하지만 adpated speaker의 sample이 batch의 1/4 정도 되도록 weighted random sampling을 사용했습니다. model을 1500 step 학습 진행했습니다.
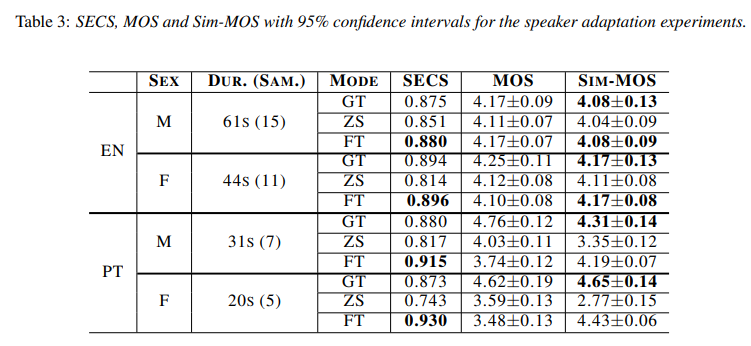
실험 결과는 위와 같습니다. GT는 grond-truth, ZS는 zero-shot multi-speaker TTS mode, FT는 fine-tuning을 의미합니다. 저자들의 model을 학습 때 보지 못한 speaker가 녹음한 1분보다 짧은 길이의 speech로 fine-tuning 하는 것이 매우 유망한 결과를 보여주었으며, 모든 실험에서 유사도가 크게 향상된 모습을 보여줍니다.
model이 target speaker의 speech를 몇 초만 사용해도 높은 similarity를 달성할 수 있지만, 위 결과와 같이 speech의 양과 MOS 간에는 직접적인 관계가 있는 것으로 봉비니다. 약 1분 가량의 speech만으로도 speaker의 speech characteristic을 copy 할 수 있으며 zero-shot mode의 자연스러움도 향상시킬 수 있습니다. 반면 44초 이하의 음성을 사용할 경우, zero-shot 또는 ground-truth model과 비교했을 때 성성된 음성의 quality/naturalness가 감소합니다. 따라서 45초 이상의 speech를 사용하는 것이 더 높은 qualtiy를 보장하기에 적절합니다.
Conclusions, limitations
이 연구에서 저자들은 YourTTS를 제안했으며, 이는 zero-shot multi-speaker TTS와 zero-shot voice conversion에서 SOTAA를 달성했습니다. 그리고 저자들의 model이 single speaker dataset만 가지고도 target language에서의 유망한 결과를 보였습니다. 추가적으로 학습 과정에서 봤던 것과 voice가 매우 다르거나 recording condition이 매우 다른 speaker에 대해서도 저자들의 model이 1분보다 짧은 speech로 잘 조절되는 것을 보여줬습니다.
하지만 저자들의 model은 몇 가지 한계점이 존재합니다. 모든 언어의 TTS 실험에서, 특정 speaker나 문장에 대해 stochastic duration predictor가 부자연스러운 duration을 생성하는 불안정성을 보여주었습니다. 그리고 몇몇 단어에서는 잘못 발음되기도 했으며 특히 Portuguese에서 심한 모습을 보였습니다. 저자들은 phonetic transcription을 사용하지 않았기 때문에 이러한 문제에 더욱 취약할 수 있습니다. Protuguese voice conversion의 경우, 여성 voice의 부족함이 문제가 되었습니다. 저자들의 model이 20초 speech만 가지고도 speaker의 speech characteristic을 잘 copy 하는 모습을 보여주지만, 45초보다 더 긴 speech를 사용하는 것이 더 높은 quality를 보장하는 데 적합한 모습을 보였습니다.