[논문] Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
https://arxiv.org/abs/2306.03509
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
Scaling text-to-speech to a large and wild dataset has been proven to be highly effective in achieving timbre and speech style generalization, particularly in zero-shot TTS. However, previous works usually encode speech into latent using audio codec and us
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
대규모 및 다양한 dataset으로 TTS를 확장하는 것이 특히 zero-shot TTS에서 timbre와 speech style의 일반화를 달성하는 데 매우 효과적인 것으로 입증되었습니다. 하지만 이전 연구들은 주로 audio codec을 사용하여 speech를 latent로 encode 하고 autoregressive language model이나 diffusion model을 사용하여 해당 latent를 만들도록 하고 있습니다. 이는 speech의 내재된 특성을 무시하며 낮은 성능이나 제어 불가능한 결과로 이어질 수 있습니다. 저자들은 speech를 여러 특성들 (e.g., content, timbre, prosody, phase)로 분해할 수 있으며, 적절한 inductive bias을 가진 module을 통해 각각을 modeling 할 수 있다고 합니다. 이러한 관점에서 저자들은 새로운 large zero-shot TTS system인 Mega-TTS를 design 하였습니다. 이 model은 large-scale wild data로 학습되며 각 attribute들을 각각 다른 방식으로 modeling 합니다. 1) audio codec으로 encode 된 latent를 intermediate feature로 사용하는 대신, 저자들은 spectrogram을 사용하여 phase와 다른 특성들을 잘 분리합니다. 위상은 GAN 기반의 vocoder로 적절하게 구성될 수 있으며, language model에 의해 modeling 될 필요가 없습니다. 2) 음색은 시간에 따라 천천히 변하는 global 특성이기 때문에, 음색을 global vector로 modeling 합니다. 3) 그리고 VQGAN 기반 acoustic model을 사용하여 spectrogram을 생성하고 prosody의 분포를 fit 하기 위해 latent code language model을 사용합니다. prosody는 문장 내에서 빠르게 변화하며, language model은 local and long-range dependency 모두 capture 할 수 있기 때문에 이러한 방식을 사용했습니다. 저자들은 Mega-TTS를 20K 시간 multi-domain speech dataset으로 scaling 하였으며, unseen speaker에 대해 성능을 평가했습니다. 실험 결과를 통해 Mega-TTS가 zero-shot TTS, speech editing, cross-lingual TTS task에서 SOTA를 달성했으며, 매우 자연스럽고 robust 한 speech를 생성할 수 있습니다.
Introduction
large-scale TTS system들은 수십만 시간의 speech data를 활용하여 학습되며, zero-shot 성능이 상당히 향상됩니다. 최근 large-scale TTS system은 일반적으로 neural codec model을 사용하여 speech waveform을 latent로 encode하여 intermediate representation으로 사용합니다. 그리고 autoregressive language model (LM)이나 diffusion model을 사용하여 latent를 modeling 합니다.

위 표에서 알 수 있듯이, 사람의 speech는 여러 attribute (content, timbre, prosody, phase, etc)로 분해될 수 있습니다. 하지만 최근 large-scale TTS system들은 neural audio codec model을 사용하여 전체 speech를 latent로 encode 하고 speech의 내재된 특성을 무시합니다. 특성은 다음과 같습니다. 1) phase의 경우 매우 dynamic 하고 의미와 연관이 없으며, 사람들이 특히 monaural audio에서 음색과 운율에 비해 phase에는 덜 민감하다는 것을 의미합니다. 그러므로 waveform을 복원할 때 오직 1개 합리적인 phase만 있으면 되고, 모든 가능한 phase를 modeling 할 필요가 없습니다. LM이나 diffusion model을 가지고 phase를 modeling 하는 것은 model이 phase의 전체 분포를 modeling 하기 때문에 많은 model의 parameter를 낭비할 수 있게 됩니다. 2) 음색은 문장 내에서 안정적으로 유지되는 global attribute이며, 시간에 따라 변화하는 latent space로 modeling 하는 것은 비용이 많이 듭니다. 3) 운율은 보통 local and long-term dependency 모두 가지고 있으며 text와 약한 관계를 보이며 시간에 따라 빠르게 변합니다. 따라서 conditional phoneme-level LLM이 phoneme sequence를 생성하는 데 본질적으로 이상적입니다. 4) content는 speech와 monotonic alignment 하지만, autoregressive language model은 잘못된 반복이나 단어를 잃는 모습을 보일 수 있으며, 이를 보장하지 않습니다.
model의 inductive bias를 speech의 내재된 특성과 matching 하면서 large and wild training dataset을 사용하기 위해, 저자들은 Mega-TTS라 불리는 zero-shot text-to-speech model을 제안합니다. 구체적으로, 1)neural audio codec model의 한계점을 고려하여, 저자들은 mel-spectrogram을 intermediate representation으로 사용하여 phase와 다른 attribute를 분리합니다. 저자들은 GAN-based vocoder를 사용하여 phase information을 reconstruction 하며 model의 성능을 향상시킵니다. 2) 음색 정보를 modeling 하기 위해, 저자들은 global vector를 사용합니다. 음색은 시간에 따라 느리게 변하는 global attribute이기 때문에 global vector를 사용하여 음색 정보를 modeling 합니다. 저자들은 global speaker encoder를 사용하여 동일한 화자의 다른 speech로부터 global information을 추출하여 음색과 content information을 분해합니다. 3) 문장에서 운율 정보를 capture 하기 위해, 저자들은 VQGAN-based acoustic model을 사용하여 mel-spectrogram을 생성하고 P-LLM이라 불리는 latent code language model을 사용하여 운율의 분포를 fit 합니다. P-LLM은 local and long-rage dependency를 capture 할 수 있습니다.
Mega-TTS의 zero-shot performance를 평가하기 위해, 저자들은 VCTK, AISHELL-3, LibreSpeech test-clean dataset을 사용해 평가를 진행했습니다. 모든 test speaker들은 학습 때 보지 못합니다. 저자들의 Mega-TTS가 speaker similarity, speech naturalness, generation robustness에서 SOTA를 달성했으며, 적절한 indcutive bias를 사용하는 것의 우수성을 입증했습니다. 그리고 Mega-TTS가 speech editing, cross-lingual TTS task에서도 SOTA를 달성했다고 합니다. main contribution은 다음과 같습니다.
- 저자들은 Mega-TTS라는 zero-shot TTS system을 제안합니다. 이는 내재된 inductive bias를 고려하는 model입니다. audio code으로 encode된 latent를 intermediate representation으로 사용하는 대신, mel-spectrogram을 content, timbre, prosody, phase attribute로 분해하고 각각을 내재된 특성으로 modeling 합니다.
- 저자들은 Mega-TTS를 20k 시간의 speech data로 구성된 multi-domain and muilti-lingual dataset으로 학습시켰습니다. 기존의 large-scale TTS system들은 일반적으로 audiobook으로부터 얻어진 speech corpora로 학습되지만, 저자들의 system은 multi-domain speech corpora로 학습된다는 점이 주목할 부분입니다.
- 저자들은 Mega-TTS를 3가지 down-stream speech generation task로 평가했습니다(zero-shot TTS, speech editing, cross-lingual TTS). Mega-TTS가 다양한 speech generation task에 이용될 수 있다는 것을 입증했습니다. 그리고 Mega-TTS로 추출된 discrete prosody token을 통해 speech editing을 진행하는 새로운 sampling strategy를 제안했습니다.
Method
적절한 inductive bias를 large-scale TTS system에 적용하기 위해, 저자들은 Mega-TTS라는 zero-shot TTS system을 제안합니다. 이는 다양한 scenario (i.e., zero-shot prompt-based TTS, speech editing, cross-lingual TTS)에서 자연스럽고 robust한 speech를 생성할 수 있습니다.

구조는 위 그림과 같습니다. Mega-TTS는 VQGAN-based TTS model과 prosody large language model (P-LLM)으로 구성됩니다. 각각의 speech attribute를 각각 다른 방식으로 modeling 했습니다. 먼저 mel-spectrogram을 intermediate representation으로 사용합니다. 이를 통해 phase를 다른 특성들과 잘 나눌 수 있습니다. 그다음 global timbre encoder를 사용하여 동일한 화자의 random previous sentence로부터 global vector를 추출합니다. 이를 통해 음색과 content 정보를 분리하게 됩니다. 마지막으로, VQGAN-based acoustic model을 사용하여 mel-spectrogram을 생성하고 prosody의 분포를 fit 하기 위해 P-LLM이라 불리는 latent code language model을 사용합니다. language model은 local and long-rage dependency를 capture 할 수 있기 때문에 사용합니다. inference 할 때 주어진 text sequence의 content를 사용하고 prompt speech에서 추출된 timbre를 사용하고 P-LLM으로 예측한 prosody를 사용하여 target speech를 생성하기 위해, prosody-oriented speech decoding이라 불리는 새로운 TTS decoding mechanism을 제안합니다. 마지막으로 저자들의 model이 다양한 scenario에서 이용될 수 있음을 증명하기 위해, 저자들은 downstream task를 위한 inference strategy도 design 하였습니다.
Disentangling speech into different components
각 speech attribute마다 적절한 inductive bias를 적용하기 위해, 저자들은 이 attribute들을 따로따로 표현해야 하며 서로 다른 architecture를 design 하여야 합니다. content, prosody, timbre representation을 따로따로 encode하기 위해 3가지 encoder를 사용합니다. 그다음 GAN-based mel-spectrogram decoder를 사용하여 이 representation들로 mel-spectrogram을 생성합니다.
- Disentangling strategy
저자들은 autoencoder의 reconstruction loss와 bottleneck을 이용하여 mel-spectrogram을 content, prosody, timbre representation으로 분리합니다.
1) mel-spectrogram을 prosody encoder에 feed하고, 잘 조정된 차원 감소 및 phoneme-level downsampling을 prosody encoder에 적용하여 information flow를 제약했습니다.
2) content encoder는 phoneme sequence를 content representation으로 encode 합니다.
3) 동일한 화자의 서로 다른 speech로부터 얻은 reference mel-spectrogram을 timbre encoder에 feed 하여 timbre와 content information을 분리하고, timbre encoder의 output을 시간에 따라 average 하여 1차원 global timbre vector를 얻습니다. 올바르게 설계된 bottleneck은 prosody encoder의 output에서 content information과 global timbre information을 제거하도록 학습하며, 이를 통해 분해를 수행하게 됩니다.
- Architecture design of encoders
1) prosody encoder는 two convolution stacks, phoneme-level pooling layer, vector quantization (VQ) bottleneck으로 구성됩니다. 첫 convolution stack은 phoneme boundary에 따라 mel-spectrogram을 phoneme-level hidden state로 compress 합니다. 두 번째 convolution stack은 phoneme-level correlation을 capture 합니다. vector quantization layer는 phoneme-level prosody codes u = {u_1, ... , u_T}와 hidden state H_{prosody}를 얻기 위해 이 hidden state을 이용합니다. 분리의 어려움을 완화하기 위해, mel-spectrogram의 low -frequency band (각 mel-spectrogram frame의 첫 20 bins)을 input으로 사용합니다. 해당 영역은 거의 완벽하게 prosody 정보를 담고 있으며, full band를 사용했을 때보다 훨씬 더 적은 timbre/content information을 얻을 수 있게 됩니다.
2) content encoder는 여러 feed-forward Transformer layer로 구성됩니다. speech content와 생성된 speech 사이 monotonic alignment를 달성하기 위해, 저자들은 duration predictor와 length regulator를 사용합니다. 저자들은 prosody encoder로 구헌 prosody information을 duration predictor에 feed 하여 one-to-many mapping 문제를 쉽게 만들었습니다.
3) timbre encoder는 주어진 speech의 speaker identity를 담고 있는 global vector H_{timbre}를 추출하도록 design 되었습니다. timbre encoder는 여러 convolution layer의 stack으로 구성됩니다. 시간 축에 따른 timbre information의 안정성을 위해, timbre encoder의 output을 시간에 따라 평균 내어 1차원 timbre vector H_{timbre}를 얻습니다.
perceptual quality를 좋게 유지하기 위해, 저자들은 GAN-based mel-spectrogram decoder를 사용합니다. 서로 다른 길이의 random window를 사용하는 multi-length discriminator를 사용합니다. Mega-TTS의 first-stage training loss L은 다음과 같습니다.
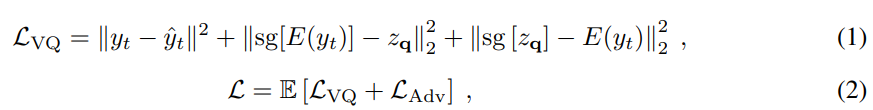
y_t는 target speech를 의미하고 y^_t는 generated speech를 의미합니다. L_{rec} = ||y_t - y^_y||^2는 reconstruction loss를 의미하고, sg[]는 stop gradient operation을 의미합니다. z_q는 codebook entry의 temporal collection입니다. L_{VQ}는 VQVAE loss function을 의미하고 L_{adv}은 LSGAN-styled adversarial loss를 의미합니다. 이는 예측된 mel-spectrogram과 ground-truth mel-spectrogram의 분포 사이 distance를 minimize 하는 objective입니다.
P-LLM
P-LLM은 prosody modeling을 위해 local and long-range dependency를 capture 하는 latent code language model입니다.
- Prosody-oriented speech decoding
(y_p, x_p)는 prompt speech-transcription pair를 나타내고 (y_t, x_t)는 target speech-transcription pair를 나타냅니다. 저자들의 목표는 주어진 unseen speech prompt y_p를 가지고 high-quality target speech y_t를 합성하는 것입니다. inference 할 때 target speech의 timbre H^_{timbre}는 prompt speech와 동일해야 합니다. 그러므로 target speech y_t를 생성하기 위해 target speech의 prosody information y^만 필요로 합니다. 그래서 prosody-oriented speech decoding 과정을 다음과 같이 공식화할 수 있습니다.

E_{prosody}는 prosody encoder, E_{timbre}는 timbre encoder, E_{content}는 content encoder, D는 mel decoder를 나타냅니다. u는 prompt speech의 prosody token을 의미하고 u^는 target speech의 predicted prosody token을 나타냅니다. f는 prosody prediction function이고, θsms P-LLM의 parameter입니다. y^_t는 generated speech입니다.
- Generating prosody codes
제안된 prosody -oriented speech decoding mechanism은 target speech에 대한 predicted prosody code u^을 필요로 합니다. LLMs의 문맥을 학습할 수 있는 능력을 사용하여 P-LLM module이 u^를 예측할 수 있습니다. P-LLM은 prosody modeling을 수행하는 decoder-only transformer-based architecture입니다. 이는 y_p라는 prompt에서 prosody code u를 구해 사용하고 H_{content}, H^_{content}, H^_{timbre}를 condition으로 사용합니다. P-LLM의 autoregressive prosody prediction process는 다음과 같습니다.
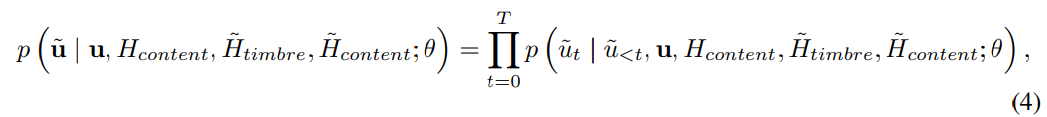
discrete prosody sequence u가 phoneme-level이기 때문에, 저자들은 u를 H_{content}와 H^_{content}와 H^_{timbre}를 concatenate 하여 input으로 사용합니다. P-LLM은 cross-etnropy loss를 통해 teacher-forcing mode로 학습됩니다(예측한 값을 사용하는 것이 아닌 정답을 사용하여 그다음 step을 predict 하는 방식을 의미).
Speech prompting for inference
다양한 speech generation task에서 in-context learning을 촉진하기 위해, 저자들은 Mega-TTS가 speech prompt에 있는 information을 따르도록 유도하는 다양한 speech prompting mechanism을 design 했습니다.
- Inference for TTS
zero-shot TTS의 경우, P-LLM은 u, H_{content}, H^_{content}, H^_{timbre}를 사용하여 target prosody code u^를 생성합니다. 저자들은 sampling based method가 생성된 speech의 다양성을 향상시킬 수 있다는 것을 알아냈기 때문에, top-k random sampling scheme을 사용하여 결과를 sample 합니다. 그다음 content H^_{content}와 timbre H^_{timbre}, prosody information u^를 concatenate 하여 target speech y_t를 생성합니다. 적절한 inductive bias와 P-LLM의 powerful in-context learning capability를 이용하여 생성된 speech는 prompt speech와 비슷한 음색뿐만 아니라 리듬 패턴도 유사하게 유지할 수 있습니다. cross-lingual TTS의 경우, u, H_{content}, H^_{timbre}, H^_{content}는 foreign language로 구성된 prompt speech로부터 추출되고, 이후 과정은 zero-shot TTS와 동일합니다.
- Inference for speech editing
speech editing에서 예측된 prosody code는 masked region의 left and right boundary의 부드러운 변환이 이루어져야만 합니다. EditSpeech와 같인 이전 연구들은 left and right autoregressive inference를 따로따로 진행한 다음 L2-norm difference가 가장 작은 fusion point로 mel-spectrogram을 concatenate 할 것을 제안했습니다. 하지만 mel-spectrogram의 L2-norm difference은 human perception과 차이가 있으며 audio의 자연스러움을 해치게 됩니다. Mega-TTS의 prosody representation은 discrete이기 때문에, discrete prosody representation에서 연산을 진행함으로써 transition problem을 해결할 수 있습니다. 먼저, mask의 left side 영역을 prompt로 사용하여 top-k random sampling으로 N개의 후보 경로를 생성합니다. 그다음 생성된 N개 path를 mask의 right side 영역의 확률 matrix을 생성하기 위한 새로운 prompt로 사용합니다. 그 다음 각 후보 path의 decoding 단계에 대한 log probability를 합산합니다. 마지막으로 두 번째 단계에서 최대 확률을 달성한 경로를 예측 결과로 선택합니다. speech editing을 위한 decoding strategy는 다음과 같습니다.
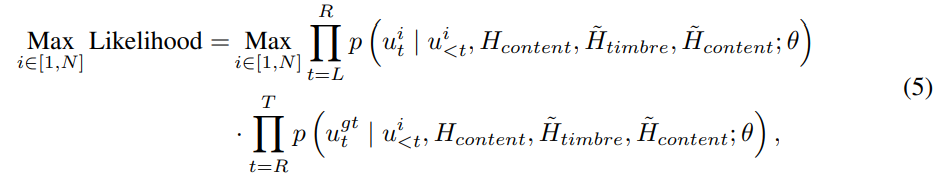
L은 mask의 left boundary, R은 mask의 right boundary입니다. T는 mel-spectrogram의 length입니다. u^i는 i번째 후보 path의 prosody code입니다. u_i^{gt}는 ground-truth prosody code입니다. 저자들의 decoding 방식은 양쪽 boundary의 prosody information을 고려하기 때문에 edited region은 부드럽게 변환될 수 있습니다.
Experiments
Experimental setup
- training datasets
저자들은 GigaSpeech와 WenetSpeech를 training corpora로 사용했습니다. 이를 통해 20k 시간의 영어 및 중국어 multi-domain speech를 얻었습니다. dataset에 있는 speech가 speaker identity를 나타내지 않고, 한 speech clip에서 여러 speaker가 등장할 수 있기 때문에, 저자들은 open-source automatic speaker diarization model을 사용하여 전처리했습니다. 저자들은 최부 alignment tool을 사용하여 phoneme-level alignment를 추출했습니다.
- Evaluation datasets
저자들은 VCTK dataset과 LibriSpeech test-clean을 사용하여 evaluation dataset을 만들었습니다. 저자들은 동일한 화자의 다른 utterance를 random 하게 선택해서 speech prompt를 만들고 음성을 합성했습니다. evaluation dataset에 등장하는 모든 화자들은 학습 과정에서 보지 못한 speaker들입니다.
- Model configuration
저자들의 Mega-TTS는 prosody large language model, mel decoder, discriminator로 구성됩니다. prosody encoder, timbre encoder, mel generator는 5 convolutional blockws with 320 hidden size, 5 convolution 1D kernel size로 구성됩니다. content encoder는 4-layer Transformer with 2 attention head, 320 embedding dimensions, 1280 1D convolution filter size, and 5 convolution 1D kernel size로 구성됩니다. duration predictor는 3-layer 1D convolution with ReLU activation and layer normalization으로 구성됩니다. discriminator는 SyntaSpeech 구조 그대로 사용합니다. P-LLM model은 8 Transformer layer with 8 attention head, 512 embedding dimensions, 2048 1D convolution filter size, and 5 convolution 1D kernel size이 존재하는 decoder-only architecture입니다.
- Objective metrics
저자들은 zero-shot TTS에 대한 pitch distance와 speaker similarity를 평가했습니다. ground-truth speech의 pitch contour와 합성된 speech의 pitch contour 사이 dynamic time warping (DTW) distance를 사용하여 pitch distance를 측정했습니다. 그리고 speaker verification으로 finetuning 된 WavLM model을 사용하여 ground-truth speech와 합성된 speech 사이 cosine speaker similarity score를 계산했습니다. 그리고 cross-lingual TTS의 경우엔 word error rate를 계산했습니다. HuBERT-Large model을 사용하여 생성된 speech를 text로 변환하였습니다.
- Subjective metrics
저자들은 MOS (mean opinion score)와 CMOS (comparative mean opinion score) evaluation을 수행하여 audio naturalness를 평가했습니다. text content와 prompt speech는 model 간 동일하게 유지하여 다른 요소들의 간섭은 제거하였습니다. MOS는 3가지 관점에 대해 진행되었습니다: MOS-Q (Quality: clarity, high-frequency and original timbre reconstructioN), MOS-P (Prosody: naturalness of pitch, energy and duration), MOS-S (Speaker similarity). 그리고 audio quality와 speech prosody에 대해 CMOS를 진행했습니다.
Results of zero-shot synthesis
저자들은 Mega-TTS를 YourTTS, VALL-E라는 baseline system들과 zero-shot 성능 비교를 진행했습니다.
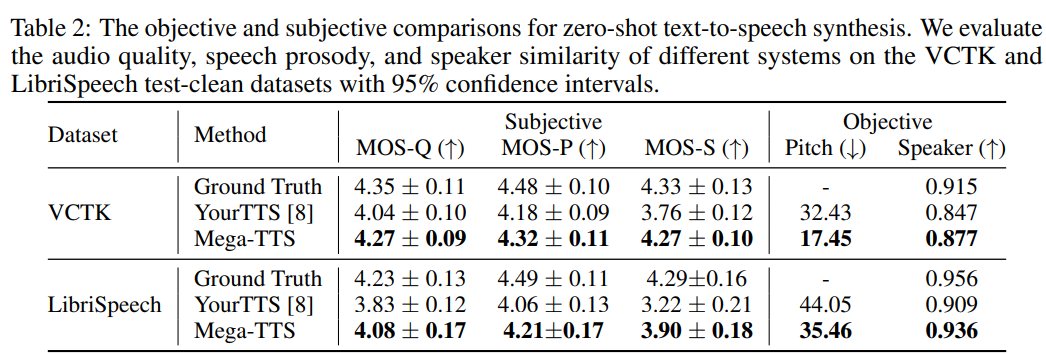
결과는 위와 같습니다. Mega-TTS가 YourTTS보다 audio quality와 speech prosody 관점에서 훨씬 뛰어난 모습을 보여줍니다. speaker similarity의 경우, Mega_TTS가 YourTTS보다 MOS-S가 0.51, 0.68 더 높은 모습을 보여줍니다.
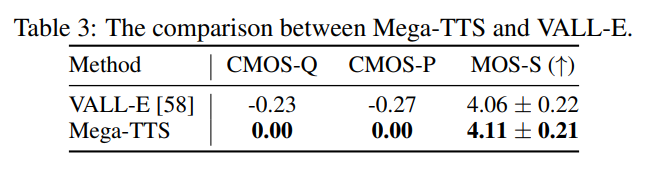
그리고 위 결과와 같이 Mega-TTS가 VALL-E보다 모든 metric에서 뛰어난 모습을 보여줍니다. 이를 통해 Mega-TTS가 VALL-E보다 더 자연스러운 speech를 생성할 수 있다는 것으로 볼 수 있으며, 내재된 inductive bias를 적용하는 것이 효과적이라는 것을 입증하였습니다.
Conclusion
이 논문에서 저자들은 적절한 inductive bias를 large-scale zero-shot TTS system에 적용하는 Mega-TTS를 제안합니다. 저자들은 speech를 다른 attribute들 (content, timbre, prosody, phase)로 분해하고, 각각 다른 방식으로 modelling 합니다. Mega-TTS가 SOTA zero-shot TTS보다 audio quality, speech, prosody, speaker similarity, robustness에서 더 뛰어난 모습을 보여줍니다.