[논문] Improving Zero-Shot Voice Style Transfer Via Disentangled Representation Learning
https://openreview.net/forum?id=TgSVWXw22FQ
Improving Zero-Shot Voice Style Transfer via Disentangled...
Voice style transfer, also called voice conversion, seeks to modify one speaker's voice to generate speech as if it came from another (target) speaker. Previous works have made progress on voice...
openreview.net
해당 논문을 보고 작성했습니다.
Abstract
voice conversion이라고도 불리는 voice style transfer는 한 speaker의 음성을 다른 target speaker가 발화한 것처럼 목소리를 변환하여 speech를 생성하는 기술입니다. 이전 연구들은 parallel training data와 pre-known speaker를 활용한 voice conversion에서 성과를 이루어냈습니다. 하지만 non-parallel data를 학습하여 이전에 보지 못한 speaker의 voice로 speech를 합성하는 zero-shot voice style transfer는 여전히 challenge로 남아 있습니다. 저자들은 disentangled representation learning을 이용한 새로운 zero-shot voice transfer method를 제안합니다. 제안한 method는 먼저 각 input voice의 speaker related style과 voice content를 separated low-dimensional embedding space로 encode 합니다. 그다음 source content embedding과 target style embedding을 결합하는 decoder를 사용해 새로운 voice로 변환합니다. 정보 이론 기반 guidance를 이용해 style embedding space와 content embedding space는 각각 독립적이면서도 대표성을 갖도록 설계되었습니다. real-world VCTK dataset에서 저자들의 method는 다른 baseline보다 뛰어난 성능을 보여주며, 변환 정확도와 voice naturalness에서 SOTA를 달성했습니다.
Introduction
Voice Style Transfer (VST)관련 연구가 많이 진행되었음에도 더 general 한 scenario에 대해서는 여전히 challenge가 남아 있습니다. 대부분의 전통적인 VST method들은 parallel training data (i.e., 동일한 sentence를 발화하는 두 speaker pair)을 필요로 합니다. real world에서는 pair-wise data가 존재하지 않는 경우가 많아 한계를 초래하게 됩니다. non-parallel data를 다루는 일부 연구들이 존재하지만, 대부분은 many-to-many transfer를 수행할 수 없습니다. 저자들이 알기론 오직 2가지 model만 re-training 없이 zero-shot transfer을 수행할 수 있다고 합니다.
AUTOVC, AdaIN-VC라는 이 두 모델은 공통된 문제점이 있습니다. 두 method들은 style information을 style embedding으로 추출하고 content information을 content embedding으로 추출하는 encoder와 style embedding과 content embedding을 결합하여 voice sample을 생성하는 decoder를 구축합니다. soruce content embedding과 target style embedding을 결합하면서 model은 source and target voice sample만 가지고 변환된 voice를 생성하게 됩니다. AUTOVC는 GE2E pre-trained style encoder를 사용하여 style embedding에 풍부한 speaker related information이 존재하도록 만듭니다. 하지만 AUTOVC는 content encoder가 style information을 encode 하지 못하도록 보장하는 regularizer가 존재하지 않습니다. AdaIN-VC는 content reprsentation의 feature map에 instance normalization을 적용하여 content embedding에서 style information을 제거하도록 만들었습니다. 하지만 AdaIN-VC은 style embedding에서 content information이 존재하지 않도록 만드는 것은 실패하였습니다. 두 method 모두 style embedding과 content embedding을 분리하지 못했으며, 서로의 정보 누설이 발생하게 됩니다.
정보 이론적(information-theoretic) guidance을 이용해, 저자들은 disentangled reprsentation learning method를 제안합니다. 이는 style and content information의 누설을 막아주어 encoder-decoder zero-shot VST framework의 성능을 향상시켜 줍니다. 저자들은 이 method를 Information-theoretic Disentangled Embedding for Voice Conversion (IDE-VC)라 부릅니다. 저자들의 model은 voice and content embedding 사이 상호 정보를 minimize 함으로써 voice의 style과 content를 성공적으로 독립적인 representation space로 유도했습니다. 그리고 저자들은 2가지 새로운 multi-group mutual information lower bounds를 고안했습니다. 이를 통해 latent embedding의 representativeness를 향상시켜주었습니다. 실험들을 통해 저자들의 method가 이전 연구들보다 더 뛰어난 many-to-many & zero-shot transfer 성능을 보여준다는 것을 입증했습니다.
Background
정보 이론에서, mutual information (MI)은 두 random variable 사이 dependence를 측정하는 데 중요한 개념입니다. 수학적으로 두 변수 x, y 사이 MI는 다음 식과 같습니다.

$p(x)$는 x에 대한 marginal distribution이고 $p(y)$는 y에 대한 marginal distribution이고 $p(x, y)$는 joint distribution 입니다. 최근 MI는 machine learning에서 model의 서로 다른 part의 dependency를 minimize 하거나 maximize 하기 위해 상당히 많은 관심을 받고 있습니다. 하지만 일반적으로 joint distribution $p(x, y)$는 알지 못하기 때문에 정확한 MI를 계산하는 건 어렵습니다. 이 문제를 해결하기 위해 여러 MI estimator들이 제안되었습니다. MI maximization task에서 Nguyen, Wainwright and Jordan (NWJ)은 MI를 f-divergence로 나타내어 lower bound를 제안합니다.

위와 같고, score function $f(x, y)$를 사용하는 방식입니다. 두번째 항은 두 변수가 독립적이라는 가정에 따라 계산되며, MI의 lower bound 역할을 하도록 만들어 줍니다.
널리 사용되는 또 다른 sample-based MI lower bound는 InfoNCE입니다. 이는 Noise Contrastive Estimation (NCE)를 사용해 고안되었습니다. sample pairs ${(x_y, y_i)}_{i=1}^N$가 joint distribution $p(x,y)$에서 sample 되었을 때, InfoNCE lower bound는 다음과 같습니다.

분자는 positive pair에 대한 값이고, 분모는 negative pair를 포함한 모든 pair에 대한 값을 나타냅니다.
MI minimization task에서 제안된 또 다른 방식은 다음과 같습니다. conditional distribution $p(x|y)$를 사용하는 contrastively learned upper bound를 다음과 같이 정의합니다.

여기서 MI는 positive sample pair와 negative sample pair 사이 log-ratio of conditional distribution $p(x|y)$로 bound를 만드는 방식입니다. 두번째 term은 negative pair에 대한 내용이고, 서로 독립이라는 가정하에 계산됩니다. 이 값은 실제 $p(x_j | y_i)$ 보다 작아질 수 없기 때문에 upper bound로 사용될 수 있습니다.
저자들은 MI estimator를 기반으로 voice style transfer를 수행하도록 information-theoretic disentangled representation learning을 고안했습니다.
Proposed Model
저자들은 M명 speaker로부터 N개 audio (voice) recording 을 수집했다고 가정했습니다. 여기서 특정 화자 $u$가 $N_c$개 voice sample $X_U = {x_{ui}}_{i=1}^{N_u}$을 가지고 있다고 하겠습니다. 저자들이 제안한 방식은 각 voice input x를 각각 speaker-related (style) embedding $s = E_s(x)$와 content-related embedding $c=E_c(x)$로 encode 합니다. 이때 style encoder $E_s()$와 content encoder $E_c()$를 사용합니다. $u$라는 speaker로부터 얻은 source $x_{ui}$를 speaker $v$의 voice의 target style $x_{vj}$로 변환하기 위해, 저자들은 decoder $D(s,c)$를 사용하여 content embedding $c_{ui} = E_c(x_{ui})$과 style embedding $s_{vj} = E_s(x_{vj})$을 결합하여 변환된 voice를 생성합니다. 이 two-step transfer process를 실행하기 위해, 저자들은 새로운 mutual information (MI)-based learning objective를 제안합니다. 이는 style embedding $s$와 content embedding $c$가 독립적인 representation space (i.e. 이상적으로 $s$는 x에 대해서 풍부한 style embedding을 포함하면서 content information은 없길 원하며, 역으로도 마찬가지입니다)으로 유도합니다.
MI-Based Disentangling Objective
정보 이론 관점에서 representative latent embedding (s, c)를 학습하려면 embedding pair (s, c)와 input x 사이 mutual information은 maximize하는 것이 바람직합니다. 반면에 style embedding s와 content embedding c는 독립적이어야 하며, 이를 통해 서로 다른 style과 content attribute를 조합하여 style transfer를 제어할 수 있게 됩니다. 그러므로 style embedding과 content embedding space를 분리하기 위해 mutual information $I(s;c)$를 minimize 합니다. 결과적으로 전체 disentangled-representation-learning objective는 다음 식을 mimize 하는 것입니다.

이전 연구에 따르면, inductive bias 없이 학습된 representation은 의미가 없을 수 있습니다. 즉 제약 조건이나 supervision 없이 학습된 경우, model은 data의 어떤 특성을 나타내야 하는지에 대한 방향성을 가지지 않을 수 있게 됩니다. 이렇게 되면 style embedding에 speaker의 style 정보가 없을 수도 있게 됩니다. 이러한 문제를 해결하기 위해, 저자들은 speaker identity $u$를 1~M 까지 value를 가진 변수로 표현하여 representative style embedding s가 speaker 관련 특성을 학습하도록 만들었습니다. speaker $u$가 본인의 voice $x_{ui}$와 style embedding $s_{ui}$에 영향을 미치는 과정을 Markov Chain $u → x → s$로 표현될 수 있습니다. MI data-processing 부등식에 따라 $I(s;x)≥I(s;u)$가 성립합니다. 따라서 $L$에 있는 $I(s;x)$를 $I(s;u)$로 대체하고 upper bound를 minimize 합니다.

대체한 식은 위와 같고, 이는 upper bound가 됩니다. 실제로 MI를 계산하는 것은 어렵기 때문에, 일반적으로 sample을 사용하거나 요구되는 distribution에 제약을 걸어 문제를 해결합니다. 이러한 문제를 해결하기 위해 저자들은 $I(s;c),I(x;c|s),I(u;s)$를 구하기 위해 여러 MI estimate를 수행합니다.
MI Lower Bound Estimate
$I(u;s)$를 maximize 하기 위해, NWJ bound를 기반으로 multi-group MI lower bound를 구했습니다. ${\mu}_{v}^{-ui} = \mu _v$을 group $X_v$에 있는 모든 style embedding의 평균으로 정의하고, 이는 speaker v의 style centroid를 나타냅니다. ${\mu}_{u}^{-ui}$는 group $X_u$에서 data point $x_{ui}$를 제외한 모든 style embedding들의 평균으로 정의합니다. 직관적으로 $||s_{ui} - {\mu}_{u}^{-ui}||$을 minimize하여 voice $x_{ui}$의 style embedding이 speaker $u$의 style controid와 더 유사하게 만듭니다. 반대로 $||s_{ui} - {\mu}_{u}^{-ui}||$를 maximize하여 $s_{ui}$와 다른 speaker들의 style centroid $\mu_v$ 사이 margin을 키웁니다.
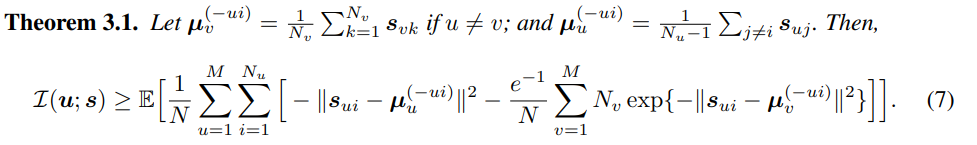
$I(x; c|s)$를 maximize하기 위해, 저자들은 conditional mutual information lower bound를 정의했습니다.
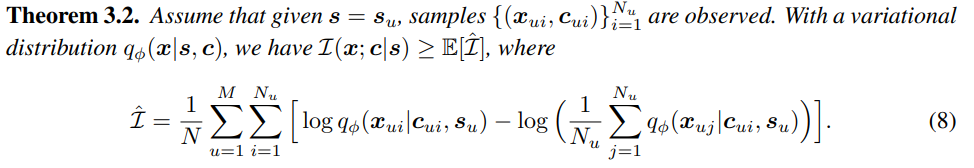
잘 학습된 style encoder $E_s()$는 speaker $u$로부터 구한 모든 style emedding $s_{ui}$는 근처에 모이게 만들어 줍니다. $s_u$가 set $X_u$의 style embedding을 잘 표현한다고 가정하겠습니다. 만약 distribution $q_{\phi}(x|s,c)∝\exp{(-||x-D(s,c)||^2)}$을 decoder $D(s, c)$를 사용하여 parameterize 했다고 하면, $I(x; c|s)$에 대한 lower bound는 다음과 같은 식으로 추정할 수 있습니다.
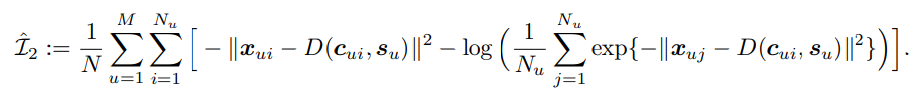
voice style $s_u$가 주어진 speaker $u$에 대해 $\hat{I_2}$를 maximize 할 때, 저자들은 content embedding $c_{ui}$가 original voice $x_{ui}$를 잘 복원하도록 $||x_{ui} - D(c_{ui}, s_u)||^2$을 최소화합니다. 추가적으로 distance $||x_{uj} - D(c_{ui}, s_u)||^2$가 minimize 된다면, $c_{ui}$가 speaker $u$의 다른 voice $x_{uj}$를 reconstruct 하는 information을 담고 있지 않도록 만들 수 있습니다(minimize가 맞나..? paper에는 minimize라는데). $\hat{I_2}$을 사용해 $x_{ui}$와 $c_{ui}$ 사이 correlation을 증폭하면서 $c_{ui}$가 content 정보를 더 잘 보존할 수 있도록 합니다.
MI Upper Bound Estimation
저자들의 framework에서 중요한 part는 style and content embedding space를 분리하는 것입니다. 이상적으로 style embedding $s$가 어떠한 content information을 배제하는 형태이며, content embedding 또한 style information을 배제하는 형태가 됩니다. 그래서 $s$와 $c$ 사이 mutual information은 minimize 하게 됩니다. $I(s;c)$를 추정하기 위해, 저자들은 sample-based MI upper bound를 고안했습니다.
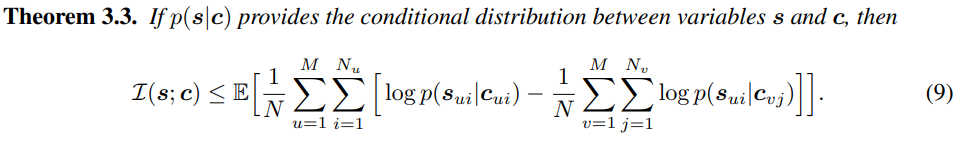
위 upper bound는 ground-truth conditional distribution $p(s|c)$를 필요로 하지만, 이 분포의 closed form은 알지 못합니다. 그러므로 저자들은 probabilistic neural network $q_\theta (s|c)$를 사용하여 $p(s|c)$를 근사합니다. 이때 log-likelihood $F(\theta) = \sum_{u=1}^{M}{\sum_{u=1}^{N_{u}}{\log {q_{\theta}(s_{ui}|c_{ui})}}}$를 maximize 하여 $q_\theta (s|c)$를 학습합니다. 학습된 ${q_{\theta}(s|c)}$을 이용해 $I(s;c)$를 minimize 하는 objective는 다음과 같습니다.
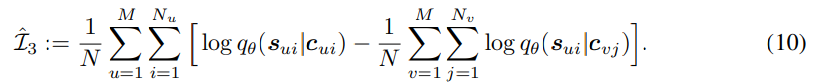
encoder $E_c, E_s$의 weight가 update 될 때, embedding space s, c는 변하며 conditional distribution $p(s|c)$를 바꿔야 합니다. 그렇기 때문에 neural approximation $q_\theta (s|c)$ 은 update 되어야만 합니다. 결과적으로 학습 과정에서 encoder $E_s, E_c$와 approximation $q_\theta (s|c)$ 는 번갈아가면서 update 됩니다.
Encoder-Decoder Framework
앞서 언급한 MI estimate $\hat{I}_1, \hat{I}_2, \hat{I}_3$을 사용하여 최종 training loss는 다음과 같습니다.
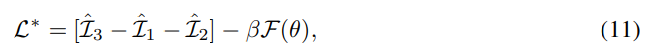
여기서 $\beta$는 weight를 조절하는 positive value입니다. $\hat{I}_3 - \hat{I}_2 - \hat{I}_1$ 은 encoder $E_c, E_s$와 decoder $D$의 parameter에 대해 최소화됩니다. $F(\theta)$는 parameter $\theta$에 대해 $q_{\theta}(s|c)$의 likelihood function을 maximize 합니다. 두 term은 gradient descent에 의해 번갈아 가면서 update 됩니다.
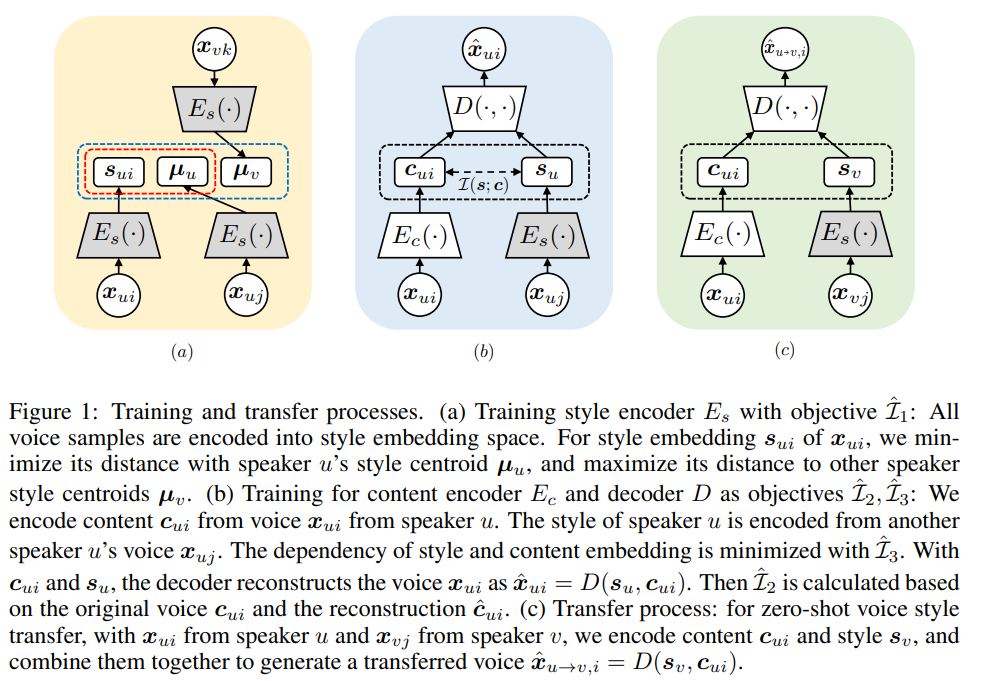
학습과 transfer process는 위와 같습니다. 저자들은 이 MI-guided learning framework를 Information-theoretic Disentangled Embedding for Voice Conversion (IDE-VC)라 부릅니다.
Experiments
저자들은 IDE-VC를 many-to-many and zero-shot VST setup에서 real-world voice dataset으로 실험을 진행했습니다. CSTR Voice Cloning Toolkit (VCTK)라는 109명 speaker로부터 46시간 audio를 녹음한 dataset을 선택했습니다. 각 speaker들은 서로 다른 발화를 읽으며, training voice는 non-parallel manner로 제공됩니다. audio는 16kHz로 downsample 됩니다.
Evaluation Metrics
- Objective Metrics
저자들은 2가지 objective metric을 수행했습니다: speaker verification accuracy (Verification), Mel-Cepstral Distance (Distsance). speaker verification accuracy는 변환된 voice가 target speaker에 속하는지 아닌지 측정합니다. pre-trained speaker encoder Resemblyzer을 사용하여 speaker identity를 분류하였습니다. 구체적으로 변환된 음성을 pre-trained speaker encoder를 통해 embedding 하여 가장 가까운 style centroid를 찾고 이를 speaker로 예측합니다. distance의 경우, generation과 ground truth 사이 합리적인 비교를 위해, 저자들은 Dynamic Time Warping (DTW) algorithm을 수행합니다. 이를 통해 MCD를 계산학기 전에 자동적으로 time-evolving sequence를 align 합니다. 이 DTW-MCD distance는 변환된 voice와 target speaker의 real voice의 유사도를 측정합니다. DTW-MCD는 parallel data를 필요로 하기 때문에, 저자들은 VCTK dataset의 test pair로부터 parallel data를 준비하였습니다.
- Subjective Metrics
저자들은 speech의 자연스러움, 변환된 speech와 target identity가 얼마나 유사한 지 subjective metric으로 사용했습니다. 자연스러움의 경우, 참가자들이 1-5 scale로 측정을 진행했습니다. similarity의 경우, 평가자들에게 변환된 audio와 reference audio를 들려준 후 두 음성 간의 유사성을 1-4 scale로 측정했습니다. 두 점수 모두 높을수록 좋은 결과를 의미합니다.
Implementation Details
저자들은 AutoVC를 따라 mel-spectrogram으로 input 음성을 표현했습니다. mel-frequency bin은 80으로 설정했습니다. voice가 생성되면, VCTK corpus로 pretrain 된 WaveNet vocoder를 사용하여 spectrogram signal을 waveform으로 변환했습니다. spectrogram에 deconvolutional layer를 사용하여 sampling rate와 동일해지도록 upsample 합니다. 그다음 standard 40-layer WaveNet을 사용하여 speech waveform을 생성합니다.
- Encoder Architecture
speaker encoder는 2-layer long short-term memory (LSTM) with cell size 768, fully-connected layer with output dim 256으로 구성됩니다. speaker encoder는 pretraiend GE2E encoder를 사용하여 초기화됩니다. content encoder의 input은 mel-spectrogram signal과 그에 대응하는 speaker embedding이 concatenate 된 결과입니다. content encoder는 3개 convolutional layer with 512 channel, 2-layer bidirectional LSTM with cell dim 32로 구성됩니다.
- Decoder Architecture
AUTOVC에 따라, decoder는 3-layer CNN with 512 channel, 3 LSTM layer with cell dim 1024, LSTM의 output을 80차원으로 project 하는 CNN layer로 구성됩니다. spectrogram의 quality를 향상시키기 위해, 저자들은 뒤에 5 convolution layer with 512 channel로 구성된 post-net을 사용했습니다.
- Approximation Network Architecture
style and contnet embedding 사이 mutual information을 minimizing 하는 것은 auxiliary variational approximation $q_{\theta}(s|c)$가 필요합니다. 저자들은 variational gaussian distribution $q_{\theta}(s|c) = N(\mu_{\theta}(c), {\sigma}_{\theta}^{2}(c)I)$을 근사하였습니다. 여기서 평균과 분산은 2-layer fully-connected networks with tanh로 구성됩니다.
Style Transfer Performance
many-to-many VST task의 경우, dataset의 10%는 validation, 10%는 test로 사용했으며, 나머지는 non-parallel method로 학습하는 데 사용했습니다. evaluation의 경우, 저자들은 testing set에서 같은 내용을 가진 음성 pair를 선택하되, speaker는 다르게 설정하였습니다. 각 test pair에서 한 음성을 다른 음성의 style로 변환하고, 변환된 음성과 reference 음성을 비교하여 model 성능을 평가했습니다. 실험 결과는 아래와 같습니다.
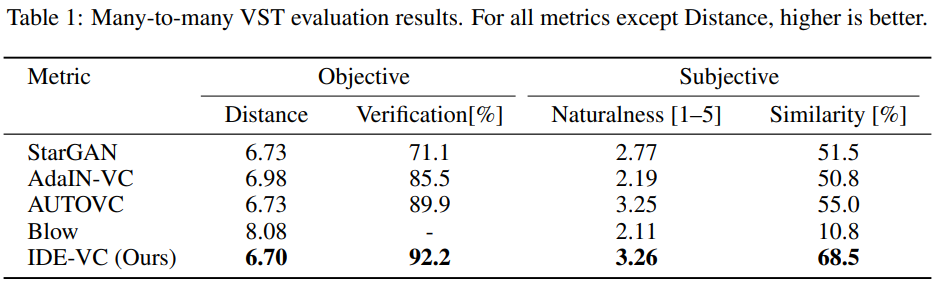
AdaIN-VC와 AUTOVC와 같은 encoder-decoder framework는 경쟁력 있는 결과를 보여주었습니다. 하지만 저자들의 IDE-VC가 다른 baseline보다 모든 metric에서 뛰어난 성능을 보여주며, latent space에서 style-content disentanglement 하는 것이 encoder-decoder framework의 성능 향상에 효과가 있음을 입증하였습니다.
zero-shot VST task의 경우, 결과는 다음과 같습니다.

저자들의 model이 두 baseline보다 뛰어난 성능을 보여줍니다. 모든 3가지 tested model은 encoder-decoder transfer framework이며, 저자들의 disentangled learning scheme의 효과를 입증하였습니다.
Conclusion
저자들은 disentangled latent representation learning을 통해 encoder-decoder voice style transfer framework 성능을 향상시켰습니다. speech의 style information과 conent information을 독립적인 embedding latent space로 효과적으로 유도하기 위해, 저자들은 style embedding과 content embedding 사이 sample-based mutual information upper bound를 minimize 하였습니다. 두 embedding space의 분리는 voice transfer 정확도를 향상시켜주고 서로 정보의 노출이 없도록 만들어줍니다. 그리고 저자들은 2가지 새로운 multi-group mutual information lower bound를 고안했습니다. 이는 latent embedding의 표현력을 향상시키기 위해 학습 과정에서 maximize 됩니다. real-world VCTK dataset에서, 저자들의 mdoel은 이전 model보다 뛰어난 성능을 보였습니다.