[논문] Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-shot Speaker Adaptation
https://diff-hiervc.github.io/audio_demo/
Diff-HierVC Demo
Ablation study Results of ablation study on zero-shot VC tasks with unseen speakers from VCTK dataset. For all methods, the number of sampling iterations is 6.
diff-hiervc.github.io
해당 논문을 보고 작성했습니다.
Abstract
voice conversion (VC) system은 voice style을 잘 변환하지만, 여전히 부정확한 pitch와 낮은 speaker adaptation quality 문제를 가지고 있습니다. 이러한 문제를 해결하기 위해, 저자들은 2개 diffusion model을 기반으로 하는 hierarchical VC system을 제안하며, Diff-HierVC라 부릅니다. 저자들은 target voice style의 $F_0$를 생성할 수 있는 DiffPitch를 제안합니다. 이후 생성된 $F_0$를 DiffVoice에 넣어 target voice style의 speech로 변환합니다. source-filter encoder를 사용해 speech를 분리하고, 변환된 Mel-spectrogram을 DiffVoice의 data-driven prior로 사용해 voice style transfer 성능을 향상시켰습니다. 마지막으로 diffusion model에서 masked prior를 사용함으로써, model이 speaker adaptation quality를 향상시켰습니다.
Introduction
Voice conversion (VC) task는 source speaker의 voice를 특정 target speaker의 voice로 변환하며 변환된 target speaker의 언어적 정보는 source speech와 동일하게 유지되어야 합니다. VC의 주요 concept은 speech의 각 component를 분리하여 각 component들을 control 하고 target speaker voice로 변환하는 것입니다. 최근엔 deep learning 방식들을 통해 VC system들이 발전되었으며, 변환된 voice의 명확성과 자연스러움을 향상시켰습니다. 그리고 cross-lingual and emotional VC와 같은 다양한 분야로 확장되고 있습니다. 그럼에도 불구하고, 변환된 voice는 여전히 발음 오류로 인한 부자연스러움이 느껴지며, 좋지 않은 speaker adaptation performance는 해결해야 할 과제로 남아 있습니다.
VC와 TTS의 speech intelligibility와 naturalness를 향상하기 위해선 pitch modeling은 필수적입니다. pitch 특성은 speaker identity와 정확한 발음에서 중요한 역할을 합니다. 모든 speaker로부터 동일한 평균과 분산을 얻기 위해 normalized fundamental frequency $F_0$를 사용하여 model을 학습하기도 합니다. 이 방식들은 pitch 정보를 고려해 표현력을 향상시켰습니다. 하지만 $F_0$는 완벽하게 speaker style과 완전히 분리되지 않아 perceptual unnaturalness가 존재합니다. VQ-VAE을 사용해 speaker와 관련 없는 pitch representation을 학습하는 연구가 등장했습니다. 하지만 speaker-irrelevant pitch가 추출될 수 있지만, vector quantization 과정에서 pitch 정보의 손실로 인해 mispronunciation이 발생하였습니다. 그리고 높은 표현력을 가진 voice의 pitch를 정확하게 예측하는 것은 여전히 어려운 문제로 남아 있습니다.
이러한 문제들을 해결하기 위해, 저자들은 새로운 diffusion-based hierarchical VC system인 Diff-HierVC를 제안합니다. Diff-HierVC는 DiffPitch와 DiffVoice로 구성됩니다. 이는 분리된 speech representation으로부터 계층적으로 voice style을 변환합니다. DiffPitch는 inference 과정에서 target speaker의 pitch information을 생성하며, DiffVoice는 생성된 pitch information과 source-filter representation을 이용해 high-quality Mel-spectrogram을 생성합니다. 저자들은 hierarchical VC architecture가 speech component를 잘 분리하고 speech를 잘 생성할 수 있는 효과적인 구조라는 것을 확인했습니다. 그리고 data-driven prior를 사용하여, 저자들은 diffusion model의 denosing process의 inception을 제어함으로써 변환 성능을 향상시켰습니다. 추가적으로, 저자들은 diffusion model의 더 나은 일반화 성능과 강건한 학습을 위해, context와 condition을 고려할 수 있도록 masked prior를 적용했습니다. 저자들의 main contribution은 다음과 같습니다.
- 저자들은 robust pitch generation과 masked prior를 통해 expressive zero-shot voice conversion을 수행하는 diffusion based hierarchical VC system인 Diff-HierVC를 제안합니다.
- 저자들이 알기론, $F_0$를 생성하기 위해 diffusion process를 사용한 첫 연구입니다. 저자들은 기존의 pitch modeling 방법 대신 denoising diffusion process를 사용해 $F_0$를 생성하여 적용하면, 정확한 발음과 자연스러운 억양을 달성할 수 있음을 보였습니다.
- 저자들은 cross-lingual and expressive real world speech dataset과 같은 다양한 conversion scenario에서 zero-shot style transfer 성능을 크게 향상시켰습니다.
Background: diffusion model
diffusion model은 image, video, audio와 같은 다양한 domain에서의 뛰어난 생성 성능을 보였으며, 최근엔 multi-modal task에서도 상당히 뛰어난 모습을 보이고 있습니다. 특히 음성 분야에서 diffusion model을 이용한 audio generation, speech enhancement, TTS synthesis들이 등장했습니다. stochastic differential equation (SDE)-based continuous-time diffusion process의 기본 concept은 data의 log-density gradient를 추정하여 반복적으로 noise를 제거하는 estimator를 학습시키고 반복적인 denoising process를 통해 sample을 생성하는 것입니다. SDE-based diffusion model을 이용한 VC도 존재합니다.
Diff-HierVC
Speech disentanglement

구조는 위와 같습니다. 먼저 speech를 content, pitch, style representation으로 분석합니다. content와 관련 없는 information을 제거하기 위해 input waveform에 data perturbation을 적용합니다. 그다음 XLS-R의 중간 layer representation으로부터 content feature를 추출합니다. XLS-R는 large-scale cross-lingual speech dataset으로 pretrain된 self-supervised model입니다. 그리고 voice style을 extract하기 위해 style encoder를 이용합니다. 이는 Mel-spectrogram에서 speaker style representation을 나타내는 voice style을 추출합니다. style embedding은 content encoder와 pitch encoder의 guide로 사용됩니다. YAAPT algorithm을 사용해 fundamental frequency ($F_0$)을 추출합니다. 정확한 pitch를 추출하기 위해 Mel-spectrogram보다 4배 더 높은 resolution을 사용해 fundamental frequency를 추출합니다. content encoder는 $log(F_0 + 1)$를 받고 pitch encoder는 normalized $F_0$를 받습니다.
Hierarchical VC
저자들은 two-stage diffusion model인 DiffPitch와 DiffVoice를 제안합니다. 먼저 DiffPitch는 target voice style을 가지고 $F_0$을 변환합니다. 그 다음 변환된 $F_0$를 DiffVoice에 feed 하여 target voice style인 speech를 변환합니다. 이렇게 계층적으로 동작합니다.
- DiffPitch
diffusion process를 기반으로 하는 pitch generator인 DiffPitch를 제안합니다. 연속적인 pitch 정보를 고려하기 위해, 저자들은 conditional diffusion model 기반 WaveNet을 사용했습니다. 이는 single denoiser를 통해 점진적으로 더 넓은 receptive field를 얻을 수 있습니다. pitch encoder는 source speech의 normalized $F_0$를 pitch representation $Z_p$으로 변환합니다. 저자들은 $Z_p$를 DiffPitch의 data-driven prior로 사용하기 위해 pitch reconstruction loss로 pitch representation을 regularize 했습니다. 이를 통해 pitch encoder의 output이 $X_p$와 유사해지도록 pitch encoder를 학습시키며, pitch encoder의 output을 prior로 사용합니다.

loss는 위와 같습니다. DiffPitch의 diffusion 과정은 YAAPT algorithm을 사용해 추출된 log-scale $F_0$를 target ground-truth $X_p$로 사용합니다. DiffPitch의 forward process는 다음 식으로 정의됩니다.

위 식에서 t는 0~1 사이 값이고, $\beta_t$는 process에서 사용되는 stochastic noise의 양을 조절하고, $w_t$는 forward standard Wiener process입니다. DiffPitch는 reverse process에서 original pitch contour를 복원하기 위해 denoising을 수행합니다. pitch denoiser의 reverse process는 다음 식으로 정의됩니다.

위 식에서 $\bar{w}_t$는 backward standard Wiener process를 의미합니다. forward process에서 noisy pitch의 sample은 다음 분포에서 sampling 됩니다.
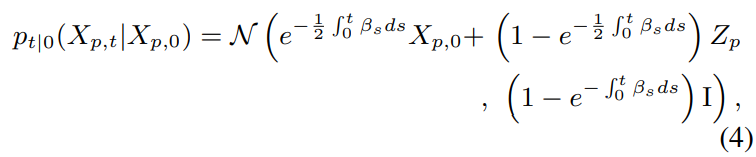
$I$는 identity matrix을 의미합니다. 위 분포는 Gaussian distribution이기 때문에, 미분하면 다음과 같이 정의됩니다.
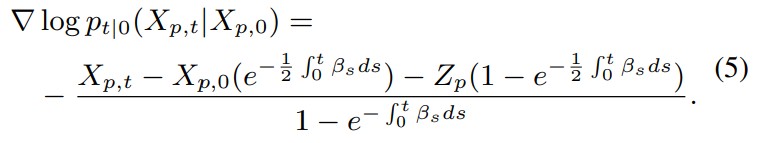
그러므로, DiffPitch는 denoising objective를 score function으로 근사하면 다음과 같습니다.
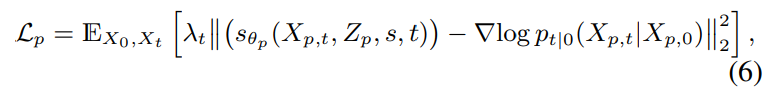
위 식에서 $s_{\theta_p}$는 pitch score estimator이고, $\lambda_t = 1 - e^{-\int_0^t\beta_sds}$입니다.
저자들은 ML-SDE solver를 사용하여 fast sampling을 수행하며, 이는 reverse SDE solver를 통해 forward diffusion의 log-likelihood를 maximize 합니다. inference 과정에서는 pitch encoder로부터 변환된 $F_0$를 DiffPitch의 prior로 사용하며 DiffPitch는 target voice style $s$를 이용해 refined $F_0$ (target speaker의 normalized $F_0$)를 생성합니다. 즉 prior와 $s$를 이용해 target speaker의 $F_0$를 구합니다. 저자들은 zero-shot voice conversion scenario를 위해, 1개 문장만 사용해 $F_0$를 normalize 합니다.
- DiffVoice
content, target $F_0$, target voice style로부터 high quality speech를 합성하는 conditional diffusion model인 DiffVoice를 제안합니다. 저자들은 inception을 guide 하기 위해 data-driven prior를 diffusion model에 적용합니다. source-filter 이론에 따라, 먼저 저자들은 speech component를 pitch와 content representation으로 분리합니다. source encoder $E_{src}$와 filter encoder $E_{ftr}$로 구성된 source-filter encoder가 중간 Mel-spectrogram $Z_m = Z_{src} + Z_{ftr}$을 reconstruct 합니다. 여기서 $Z_{src} = E_{src}(F_0, s)$이고 $Z_{ftr} = E_{ftr}(content, s)$입니다. $s$는 style embedding을 나타냅니다. 이렇게 구한 Mel-spectrogram을 DiffVoice의 prior로 사용합니다. Mel-spectrogram $Z_m$은 다음 식으로 정규화됩니다.
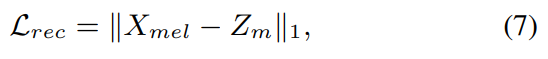
$X_{mel}$은 ground-truth speech의 Mel-spectrogram을 의미합니다. DiffVoice는 source-filter encoder의 output인 $Z_m$을 prior로 사용하고, speaker representation $s$를 condition으로 사용하여 speaker adaptation 성능을 maximize 합니다. DiffVoice의 forward process는 다음 식으로 정의됩니다.
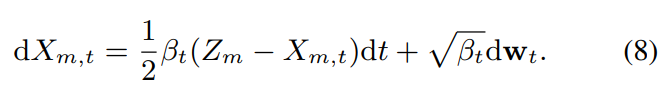
DiffVoice의 reverse process는 다음 식으로 정의됩니다.
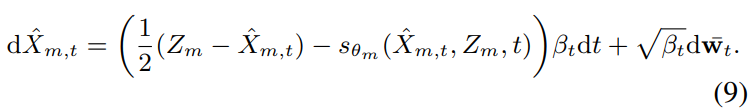
최종 Mel-spectrogram noise estimation network $S_{\theta m}$을 학습시키기 위한 objective는 score matching loss를 optimize 하는 것으로 다음과 같이 정의됩니다.
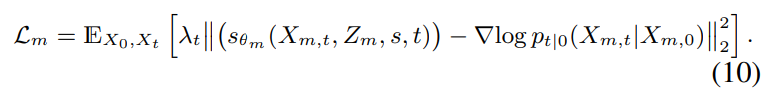
inference 과정에서, source-filter encoder는 source speech, target voice style $s$, target voice style을 사용한 DiffPitch로부터 변환된 $F_0$로부터 content representation을 받습니다. source-filter encoder로부터 변환된 Mel-spectrogram $Z_m$은 data-driven prior로 사용되며, DiffVoice는 target voice style을 condition으로 사용하여 converted speech를 생성합니다.
Denoising models with masked prior
data-driven prior가 conversion 성능을 크게 향상하는데 도움을 주지만, DiffVoice는 source-filter encoder의 reconstructed Mel-spectrogram에 의존할 가능성이 존재합니다. 즉, data-driven prior에 지나치게 의존할 수 있게 되며, 일반화 성능이 저하될 수 있습니다. DiffVoice의 일반화 성능을 향상시키기 위해, 저자들은 masked prior를 denoising diffusion model에 적용합니다. DiffVoice에 feed 하기 전에, prior $Z_m$을 masking 합니다. 그다음 diffusion network가 reconstruction과 denoising process를 동시에 학습합니다. 결과적으로 model은 주변 content를 기반으로 masked 영역을 reconstruct 할 수 있게 됩니다. 구체적으로, 저자들은 frequency masking을 적용하였으며, model은 주변의 pitch information을 이용해 masking된 부분을 복원하도록 학습됩니다. 즉 prior를 복사하는 대신, 주변 context를 고려하는 방법을 배우게 됩니다.
Experiment and result
Experimental setup
- Dataset and preprocessing
저자들은 LibriTTS라는 large-scale multi speaker dataset을 사용하여 model을 학습시켰습니다. 저자들은 LibriTTS의 train-clean-360과 train-clean-100 subset을 이용하였으며, 1151명 speaker로부터 110 시간 speech로 구성되어 있습니다. 그리고 LibriTTS의 dev-clean-other subset을 이용해 평가를 진행했습니다. 그 다음 VCTK dataset을 이용해 zero-shot VC performance를 평가했습니다. 저자들은 VCTK dataset의 paired speech로부터 random 하게 sentence를 선택했습니다. 저자들은 16kHz로 audio를 downsample 하였고, short-time Fourier transform (STFT)와 Mel-filter를 사용해 80 bin log-scale Mel-spectrogram으로 변환하였습니다.
- Training
모든 encoder는 128차원 non-causal dilated WaveNet을 사용하며, DiffPitch는 64차원 DiffWave에 pitch representation과 style representation을 위해 추가적인 conditional layer를 붙여서 사용합니다. DiffVoice는 64, 128, 256 dimension을 사용하는 2D-UNet 구조로 구성됩니다. masked prior를 만들 땐 masking ratio를 30%으로 설정했습니다. Vocoder로는 HiFi-GAN을 사용했으며, discriminator를 EnCodec의 multi-scale STFT discriminator로 대체했습니다.
Analysis on $F_0$ prediction
대부분의 이전 VC system들은 normalized or quantized $F_0$를 사용해 speaker irrelevant pitch modeling을 수행했습니다. 하지만 저자들은 raw $F_0$을 추정하여 target voice style에 맞춰 더 나은 speaker adaptation을 수행했습니다. 저자들은 3가지 $F_0$ prediction method를 비교했습니다: 통계 기반 $F_0$ transformation, WaveNet을 이용한 simple $F_0$ prediction, DiffPitch를 이용한 diffusion-based $F_0$입니다.
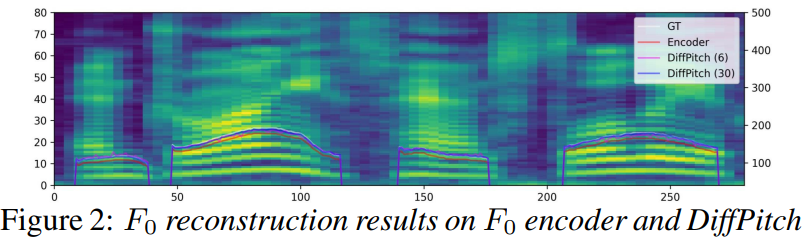
위 figure는 DiffPitch의 30 iteration step의 결과를 보여줍니다. 이는 ground-truth $F_0$와 유사한 $F_0$ contour를 보입니다.
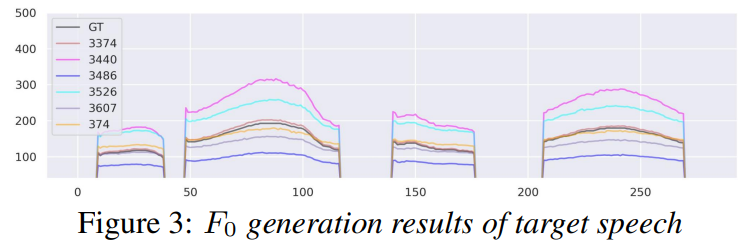
위 그림은 다양한 target voice style에 맞춰 다양한 pitch contour를 보여줍니다. 저자들은 DiffVoice와 DiffPitch를 사용해 VC를 수행합니다.
Zero-shot VC
저자들은 zero-shot VC scenario에서 다양한 subjective and objective evaluation을 진행했습니다. baseline model로 autoencoder 기반 VC model인 AutoVC, GAN 기반 VC model인 VoiceMixer, unit based end-to-end speech model인 Speech Resynthesis (SR), diffusion 기반 VC model인 DiffVC입니다. 저자들은 naturalness와 similarity에 대한 MOS를 수행했습니다. 결과는 다음과 같습니다.
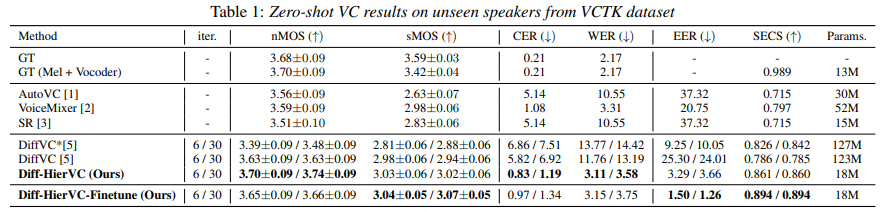
저자들의 model이 더 나은 nMOS와 sMOS를 보여줍니다. 구체적으로, 저자들의 model이 상당히 향상된 content consistency와 speaker adaptation performance를 보여줍니다. 그리고 cross-lingual VC를 수행하여 unseen language에 대한 zero-shot conversion performance를 입증했습니다.
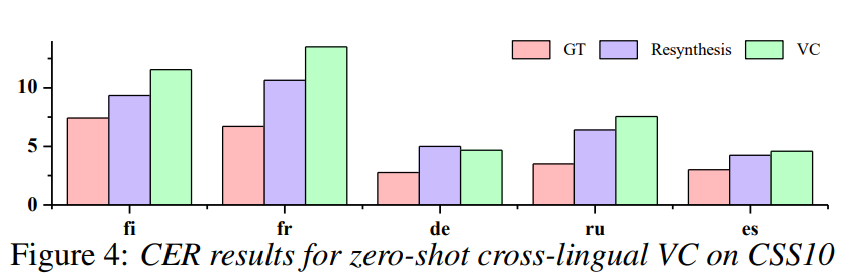
결과는 위와 같습니다. 저자들의 model이 unseen language에서도 resynthesis and VC scenario 모두에서 강건한 일반화 성능을 보여주고 있습니다.
Ablation study
- Pitch modeling
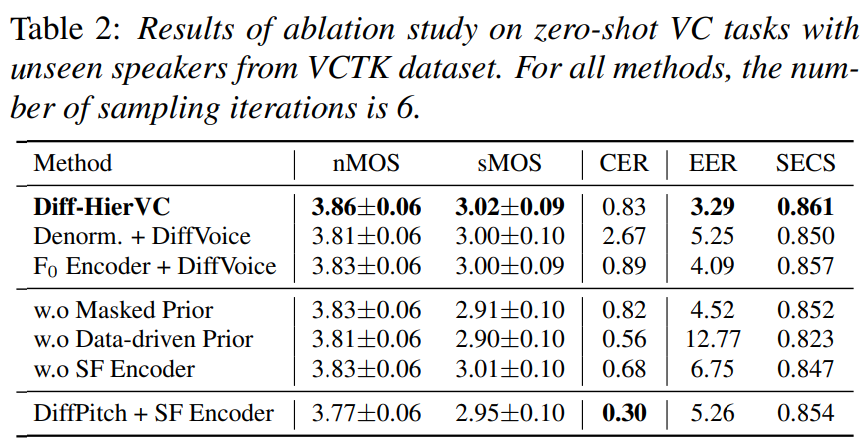
저자들은 DiffPitch, denormalization (Denorm)를 이용한 $F_0$ 변환, $F_0$ encoder를 사용한 simple $F_0$ prediction입니다. 모든 method들은 동일한 source speech의 normalized $F_0$를 사용해 target voice style의 $F_0$로 변환합니다. Denorm이 normalized $F_0$을 target speech의 평균과 분산을 통해 변환할 수 있지만, target speech로부터 추출된 부정확한 $F_0$가 voice style transfer performance를 감소시킵니다. 그리고 $F_0$ encoder만 사용하면 voice style transfer 성능이 저하됩니다.
- Data-driven prior and masked prior
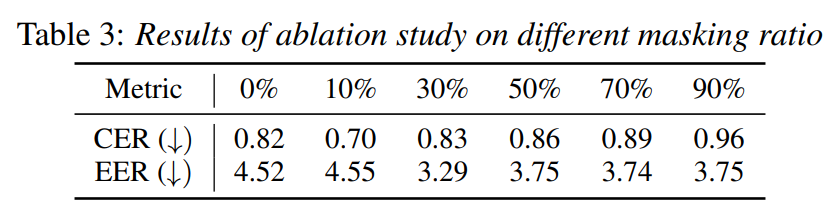
data-driven prior가 voice style transfer 성능을 크게 향상시켰습니다. 그러나 diffusion model이 source-filter encoder의 성능에 의존할 가능성이 있었으며, 변환된 speech를 생성할 때 conditional information을 약간만 반영한다는 점이 확인되었습니다. 그리고 YAAPT algorithm을 통해 추출한 부정확한 ground-truth $F_0$가 사용되는 경우도 있었습니다. masked prior를 사용하면 data-driven prior의 이점도 활용하면서도 diffusion model의 일반화 성능도 향상시켰습니다. 위 표는 masked ratio에 대한 실험 결과를 보여줍니다.
- Source-filter encoder
speech represntation을 control 하기 위해선 speech를 분리하는 것이 중요한 역할을 합니다. 이 논문에서 source-filter (SF) encoder를 이용해 speech component를 분리하고 diffusion model의 starting point를 regulate 하였습니다. source-filter encoder의 효과를 입증하기 위해, 저자들은 source-filter encoder를 single encoder로 대체했습니다. single encoder를 사용하면 전체 model의 voice conversion 성능을 감소시키며, speech representation을 적절히 분리하지 못하는 모습을 보입니다. 그 결과 DiffVoice의 prior로 사용된 변환된 음성이 target 음성과의 speaker similarity가 낮아지게 되었습니다.
Conclusion
이 논문에서 저자들은 diffusion-based hierarchical VC system인 Diff-HierVC를 제안합니다. DiffPitch는 speaker similarity와 phonetic intelligibility 성능을 향상시켰습니다. DiffVoice는 denoising 과정을 통해 high-quality speech를 복원했습니다. diffusion model의 더 나은 일반화 성능을 위해, 저자들은 context와 diffusion condition을 고려하여 변환하도록 masked prior를 사용했습니다. 결과적으로 저자들의 model이 모든 metric에서 SOTA보다 더 좋은 모습을 보이며 6.8배 더 작은 parameter를 사용합니다. 그리고 zero-shot cross lingual도 가능하다는 것을 입증하였습니다. 저자들의 model이 speaker adaptation 성능을 향상시켰지만, input data에 noise가 존재하면 이 또한 style로 인식하여 변환을 한다는 단점이 존재합니다.