[논문] VoiceMixer: Adversarial Voice Style Mixup
https://proceedings.neurips.cc/paper/2021/hash/0266e33d3f546cb5436a10798e657d97-Abstract.html
VoiceMixer: Adversarial Voice Style Mixup
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
proceedings.neurips.cc
해당 논문을 보고 작성했습니다.
Abstract
최근 voice conversion이 상당히 많이 발전되었지만, 여전히 target voice와 converted voice 사이엔 gap이 존재합니다. 이 gap의 주요 원인은 source speech에서 content와 voice style을 충분히 분해하지 못하기 때문입니다. 이는 converted speech에 source speech style가 남아 있게 만들거나 source speech content가 손실되게 만듭니다. 이 논문에서 VoiceMixer라는 새로운 information bottleneck과 adversarial feedback을 사용하여 효과적으로 voice style을 분리하고 변환하는 기술을 제안합니다. self-supervised representation learning을 이용해, information bottleneck은 content information을 거의 잃지 않으면서 content와 style을 분리할 수 있습니다. 각 정보들에 adversarial feedback을 적용하기 위해, content discriminator와 style discriminator를 따로 적용합니다. 이를 통해 model이 converted speech의 voice style에 대한 더 나은 일반화 성능을 보여줍니다.
Introduction
최근, speech representation learning task에서는 self-supervised representation learning을 이용해 중요한 정보를 추출합니다. latent representation을 예측함으로써 model이 labeled data 없이도 유용한 정보를 학습할 수 있습니다. 하지만 이러한 self-supervised representation learning은 아직 voice conversion task에서는 주목을 받고 있지 않습니다.
이 논문에서 저자들은 새로운 similarity-based information bottleneck과 adversarial feedback을 사용하여 voice style을 분리하고 변환할 수 있는 VoiceMixer를 제안합니다. 저자들은 self-supervised representation learning을 적용해 어떠한 text transcription나 추가적인 feature extractor를 사용해 추가적인 정보를 추출할 필요 없이 voice style을 분리하고 변환할 수 있습니다. 또한 변환된 speech의 latent representation을 학습하기 위해 adversarial voice style mixup을 제안합니다. 저자들은 먼저 content discriminator와 style discriminator로 discriminator를 분리합니다. generator의 hidden representation은 각 discriminator의 condition information으로 discriminator를 guide 합니다. 분리된 discriminator의 adversarial feedback을 통해, generator는 더 나은 일반화 성능을 보여줍니다. main contribution은 다음과 같습니다.
- 저자들은 content information의 손실이 거의 없이 content와 style을 분리할 수 있는 similarity-based information bottleneck을 제안하며, 이는 self-supervised representation learning을 사용합니다. 이 preservation은 이전 method보다 더 나은 converted speech quality를 보여줍니다.
- converted speech의 더 나은 일반화 성능을 의해, 저자들은 adversarial voice style mixup을 제안합니다. 이는 converted speech가 ground-truth audio가 없는 상태에서도 self-supervised guidance를 이용해 adversarial feedback을 제공함으로써 speech를 학습합니다.
- 다양한 subjective and objective evaluation을 통해, 저자들은 VoiceMixer가 many-to-many and zero-shot voice style transfer scenario에서 다른 baseline model보다 더 뛰어난 성능을 보인다는 것을 증명했습니다.
Background
AutoVC는 source speech에서 content information과 style information을 분리하며, information bottleneck을 이용해 target speech의 voice style로 변환합니다. AUTOVC의 간단한 autoencoder framework는 3가지 module로 구성됩니다. speaker encoder $f_s()$와 content encoder $f_c()$, decoder $g()$입니다. 학습 과정에서 model은 content와 style information을 분리하기 위해 고정된 길이의 information bottleneck을 이용해 self-reconstruction 합니다.

위 식에서 $X_{1, A}$는 source speaker "1"의 utterance $A$를 의미합니다. $S_1$은 speaker "1"의 speaker information을 의미하고, $C_A$는 utterance $A$의 content information을 의미합니다. 그리고 $\hat{X}_{1\rightarrow 1, A}$는 content information $C_A$를 포함하고 speaker character가 $S_1$인 speech를 self-reconstruct 한 결과를 의미합니다. 이는 각 information을 분리하는 가장 간단한 방법이지만, 적절한 information bottleneck size τ를 필요로 합니다. 식으로 나타내면 다음과 같습니다.

위 식에서 $H$는 time index에 맞는 downsampled feature를 나타냅니다. 고정된 길이의 information bottleneck size τ가 "too narrow" 한 경우, model은 더 좋은 reconstruction quality를 보여주지만 voice style transfer 성능이 좋지 않게 됩니다. 반대로 "too wide"하다면, model은 voice style transfer 성능이 좋지만, reconstruction quality가 좋지 않게 됩니다. content and style information을 분리하는 과정에서, 적절한 bottleneck size여도 몇몇 정보들은 사라지게 됩니다. 그러므로 변환된 voice에서 content 정보 손실은 불가피합니다.
VoiceMixer
이 논문에서 저자들은 similarity-based information bottleneck을 제안합니다. adversarial feedback을 위해, 저자들은 self-supervised guidance를 이용해 content와 style을 따로 학습하도록 discriminator를 분리하였습니다. 각 정보들에 맞춰 discriminator를 분리함으로써, 변환된 speech가 ground-truth audio 없이 학습이 가능하게 됩니다.

Generator
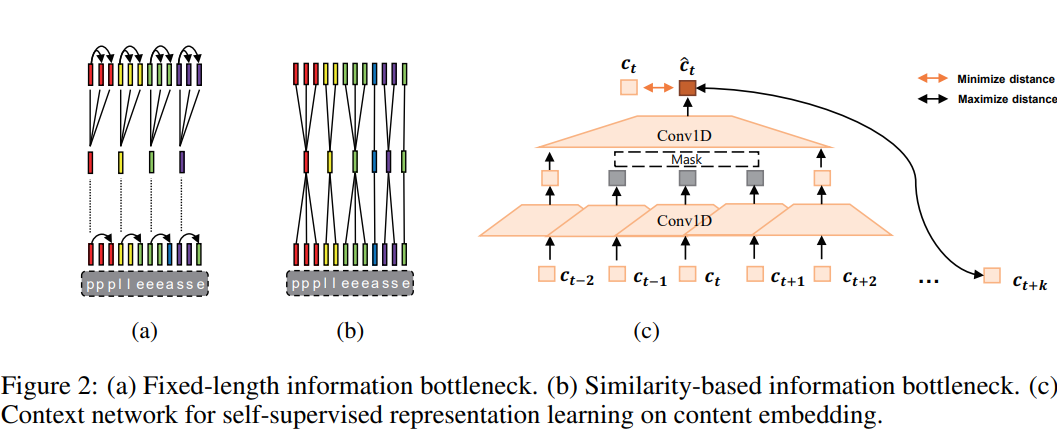
generator의 경우, 저자들은 AUTOVC의 autoencoder framework를 따릅니다. 위 그림의 (a)처럼, generator G는 content encoder $f_c()$와 speaker encoder $f_s()$로 구성됩니다. content encoder는 speech에서 content embedding을 추출하고, speaker encoder는 speech에서 speaker embedding을 추출합니다. 그리고 decoder $g()$는 content embedding과 speaker embedding을 이용해 speech를 생성합니다. 식 (1)과 같습니다.
Similarity-based information bottleneck
위 식의 information bottleneck과 다르게, 저자들은 content embedding을 similarity에 따라 downsample 합니다. 저자들은 content encoder가 비슷한 phoneme들은 유사한 content embedding을 생성할 것으로 가정했으며, 저자들은 인접한 phonetic information을 함께 mapping 하도록 downsampling 하였습니다. 저자들은 content embedding sequence $C = (c_1, ... , c_T)$와 shifted content embedding sequence $C_{shift} = (c_2, ... , c_{T+1})$ 사이 similarity $Q = (q_1, ... , q_T)$를 계산합니다. 식으로 나타내면 다음과 같습니다.

위 식에서 $sig$는 sigmoid function을 나타내고, $\rho$는 temperature parameter를 나타냅니다. 그다음 similarity based duration $D = (d_1, ... , d_N)$을 추출합니다. 여기서 $d_n$은 similarity $q_t$가 average similarity보다 작아질 때까지의 은 누적 합입니다. $q_t$에 대한 연산이 끝났다면, $q_{t+1}$부터 이어서 다시 계산합니다.
- Gaussian down/up-sampling
해당 content의 가장 많은 정보를 가지고 있는 부분이 same content의 center라고 가정합니다. 이를 기반으로 center에 attention을 focus 하는 gaussian downsampling을 사용합니다. content embedding C, duration D, 학습 가능한 range parameter $\sigma = (\sigma_1, ... \sigma_N)$이 주어졌을 때, 다음 식으로 downsampled sequence $H = (h_1, ... , h_N)$을 구합니다.

그다음 $H$를 upscale 하여 $\tilde{C} = (\tilde{c}_1, ... , \tilde{c}_T)$을 구하기 위해 Gaussian upsampling을 사용합니다. upsampled content sequence는 duration $D$와 range parameter $\sigma' = (\sigma'_1 , ... , \sigma'_N)$ 을 사용해 구해지며, generator에 feed 하여 mel-spectrogram을 생성합니다.
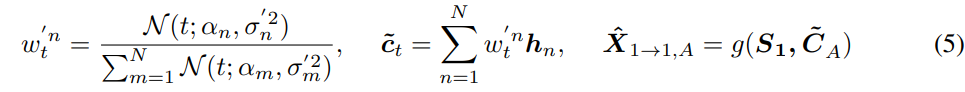
Auxiliary losses for similarity
- Contrastive loss
인접한 content embedding 사이 similarity를 향상시키기 위해, 저자들은 self-supervised representation learning을 시용해 content encoder를 학습했습니다. content embedding은 context network $f_r$에 feed 되어 위 그림 (c)에 해당하는 content representation을 학습합니다. non-autoregressive 방식으로 학습하기 위해, 저자들은 masked convolutional block을 사용해 인접한 content embedding으로부터 content embedding을 예측하도록 학습시켰습니다. 그리고 positive sample을 위해 contrastive loss를 정의하여 예측된 content embedding $\hat{C} = (\hat{c}_1, ... , \hat{c}_T)$와 content embedding $C$ 사이 distance를 줄였습니다. 식으로 나타내면 다음과 같습니다.
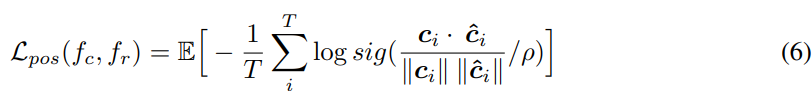
위 식에서 $sig$는 sigmoid function을 의미하고 $\rho $는 temperature parameter를 의미합니다.
unsupervised 방식으로 content embedding에서 style information을 제거하기 위해, 저자들은 context network가 content embedding의 future representation을 예측하는 것을 막았습니다. 동일한 utterance에서 negative sample들은 균등하게 sample 되지만, k번째 future content embedding만 negative sample로 사용합니다. 이를 통해 비슷한 content 사이 distance가 너무 멀어지는 것을 막을 수 있습니다. content embedding의 k번째 future representation과 predicted content embedding 사이 cosine distance를 maximize 하였으며, negative sample에 대한 contrastive loss는 다음과 같습니다.
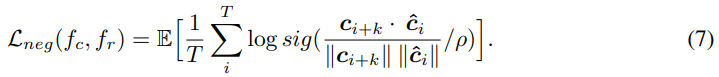
- Adversarial speaker classification
content embedding과 speaker를 분리하도록 만들기 위해, 저자들은 supervised 방식으로 adversarial speakr classification을 이용하였습니다. 식은 다음과 같습니다.
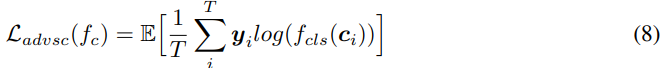
$f_{cls}$는 speaker classifier를 의미합니다. 전체 model을 $f_{cls}$와 동시에 학습하기 위해, 저자들은 content embedding이 $f_{cls}$에 feed 되기 전에 gradient reversal layer를 사용하였습니다.
Disentangled discriminator with self-supervised guidance
linguistic information을 보존하기 위해 cycle-consistency training을 사용하는 이전의 GAN-based VC model과 다르게, 저자들은 autoencoder 기반의 reconstruction method를 이용해 학습을 수행합니다. adversarial feedback의 경우, 저자들은 discriminator $D$를 content discriminator $D^c(\cdot,\cdot)$와 style discriminator $D^s(\cdot,\cdot)$로 나누어 content와 style을 분리하였습니다. 각 특성에 맞춰 각 dsicriminator를 guide 하기 위해, 저자들은 content embedding을 content discriminator의 condition으로 사용하고 style embedding을 style discriminator의 condition으로 사용하며, 위 Figure 1의 (c), (d)와 같은 모습입니다. 학습에서는 LSGAN을 사용하였으며, 식으로 나타내면 다음과 같습니다.
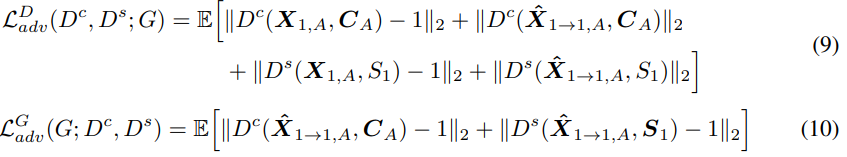
- Feature Matching for reconstruction
저자들은 feature matching loss를 사용해 generator를 학습시켰습니다. feature matching loss는 ground truth에 대한 discriminator의 feature와 generated speech에 대한 discriminator의 feature 사이 distance를 minimize 하는 loss입니다. content discriminator에서 content feature matching loss $L_{content}^G$를 구하고, style discriminator에서 style feature matching loss $L_{style}^G$를 구합니다. 식으로 나타내면 다음과 같습니다.
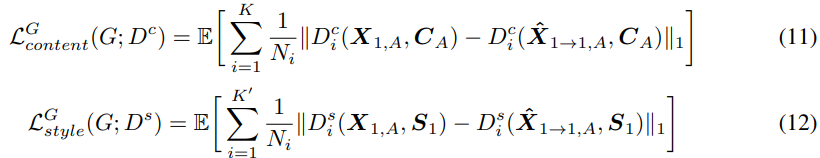
위 식에서 $K$와 $K'$는 각 discriminator의 block 수를 나타내며, $N_i$는 $i-th$ discriminator block의 feature 수를 나타냅니다. reconstructed mel-spectrogram에 대한 total loss는 다음과 같이 정의됩니다.
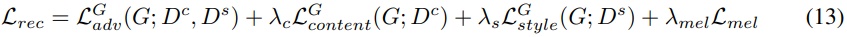
위 식에서 $L_{mel}$는 $X_{1,A}$와 $\hat{X}_{1\rightarrow 1, A}$ 사이 mean absolute error를 나타냅니다.
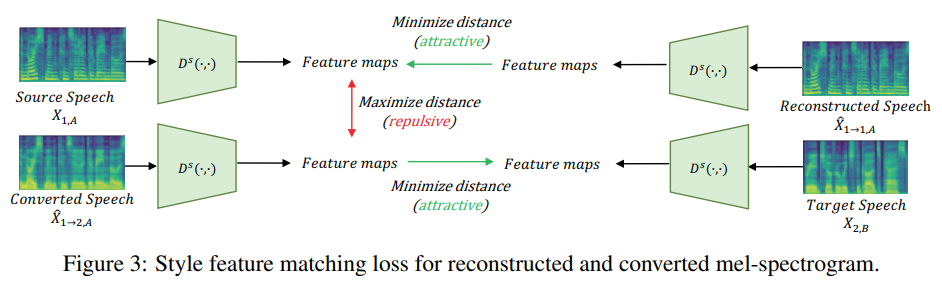
Adversarial Voice Style Mixup
disentangled discriminator를 사용함으로써, 각 disentangled feature를 가지고 reconstructed speech를 학습할 수 있습니다. 하지만 source style을 분해하고 target style로 변환하여 voice를 convert 하는 것이 목표입니다. converted speech의 latent representation을 학습하기 위해, 저자들은 adversarial voice style mixup을 제안합니다. 이는 self-supervised condition을 사용하는 disentangled discriminator를 사용하여 converted speech를 학습할 수 있습니다. 변환된 voice의 ground-truth sample이 존재하지 않더라도, discriminator를 이용한 adversarial feedback으로 converted mel-spectrogram을 학습할 수 있습니다. 이를 통해 추가적인 feature extractor 없이 generator의 self-supervised hidden representation을 conditional feature로 사용하면 됩니다. converted mel-spectrogram의 GAN loss는 다음과 같습니다.
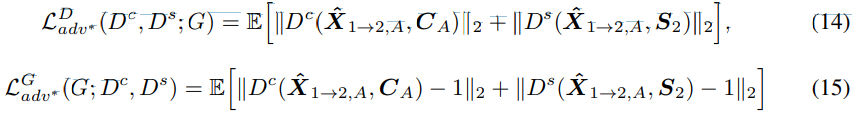
- Feature Matching for Mixup
converted speech에도 feature matching loss를 적용하였습니다. content representation의 경우, converted speech와 source speech의 content discriminator의 feature distance를 minimize 합니다.
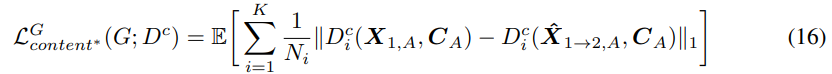
style representation의 경우, converted speech와 target speech의 feature distance를 minimize 합니다.
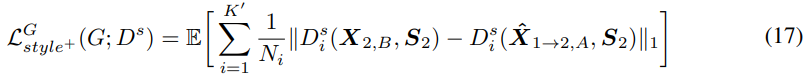
저자들은 이를 "Attractive style loss"라 부릅니다. 동일한 speaker의 style 사이 style feature를 minimize 합니다. 위 Figure 3처럼, "Repulsive style loss"를 적용해 converted speech와 source speech의 서로 다른 style 사이 style feature를 maximize 합니다.
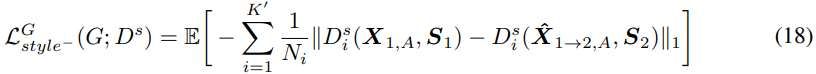
content encoder가 source speaker를 분리하지 못하는 경우, converted speech는 source speaker의 style를 contain 할 수 있습니다. 그러므로 이 repulsive style loss는 converted speech에 source speaker의 style이 존재하지 않도록 만들어 줍니다. converted mel-spectrogram의 total loss는 다음과 같이 정의됩니다.
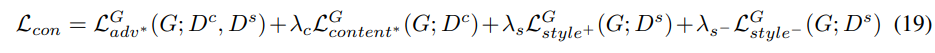
저자들의 최종 discriminator and generator objective는 다음과 같습니다.
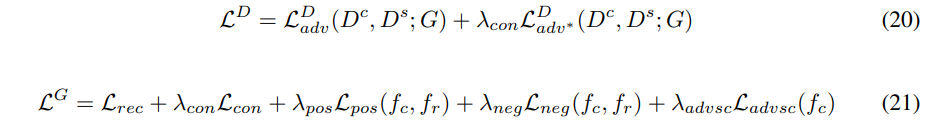
Experiment and result
저자들은 다양한 실험을 보였으며, 디테일한 내용은 해당 논문을 찾아보시면 될 것 같습니다.
Information bottleneck alignment
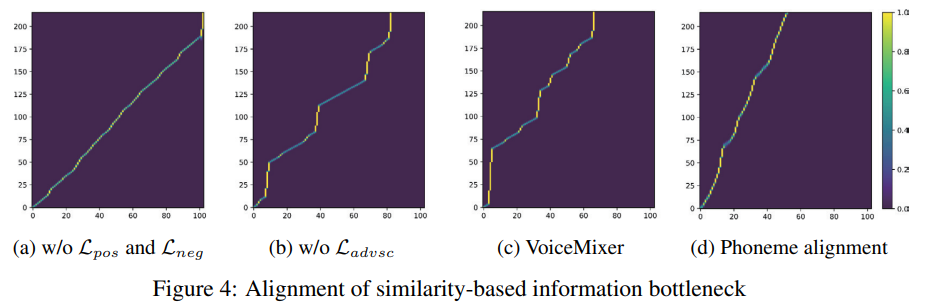
다양한 auxiliary loss의 combination을 사용하여 similarity-based information bottleneck을 비교하였습니다. 실험 결과는 위와 같습니다. source speech와 downsampled content embedding 사이 alignment를 보여줍니다. contrastive loss ($L_{pos}, L_{neg}$)를 사용하지 않은 model은 거의 diagonal alignment 하며, 이는 content embedding이 content information만 표현하는 것은 아님을 의미합니다. $L_{advsc}$을 사용하지 않은 model은 Tacotron2의 attention alignment와 유사한 alignment를 보여줍니다. 이 결과는 contrastive loss가 content information과 speaker information을 분리하는 데 있어 $L_{advsc}$보다 더 중요하다는 것을 의미합니다. text transcript와 target duration을 사용하지 않고 auxiliary loss를 사용한 저자들의 model이 phonetic alignment와 비슷한 alignment를 보여줍니다.
Audio quality and style transfer performance
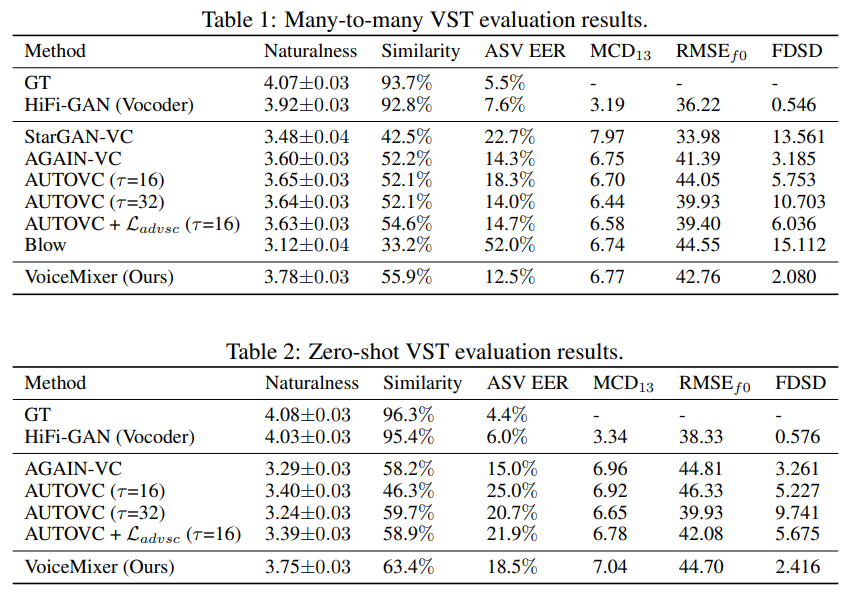
many-to-many VST evaluation의 경우, 저자들은 4가지 VC model (StarGAN-VC, AGAIN-VC, Blow, AUTOVC)와 비교하였습니다. 모든 model들을 VoiceMixer와 동일한 dataset으로 학습했습니다. AUTOVC를 다양한 setting으로 학습을 진행했습니다. 그리고 AUTOVC에 adversarial speaker classifier를 적용하였습니다. 위 Table 1을 통해, 저자들의 model이 naturalness와 FDSD metric에서 더 나은 결과를 보인다는 것을 확인할 수 있습니다. 또한, 저자들의 mdoel이 similarity와 ASV EER에서 더 나은 모습을 보여주고 있습니다. content와 style information을 분리할 때, AGAIN-VC와 AUTOVC model들은 많은 양의 content information을 잃어버리며, converted speech의 naturalness가 낮고 높은 FDSD score를 보여줍니다. content embedding에 adversarial speaker classifier를 사용하는 것이 model의 disentanglement performance에 도움이 되지만, naturalness는 감소될 수 있습니다.
zero-shto VST evaluation의 경우, 저자들은 2가지 VC model인 AGAIN-VC와 AUTOVC를 사용했습니다. 저자들은 AUTOVC를 다양한 bottleneck size와 adversarial speaker classification loss의 유무에 따라 여러 version을 준비하였습니다. 저자들의 model이 FDSD와 naturalness가 더 좋은 모습을 보여줌을 알 수 있습니다. AGAIN-VC가 ASV EER에서 더 나은 모습을 보여주지만, 저자들의 model이 더 나은 similarity를 보여줌을 알 수 있습니다. AUTOVC의 경우, 적절한 down-sampling factor를 선택하는 것이 어려우며, 이를 통한 naturalness와 similarity 사이 trade-off가 발생합니다. 그러므로 저자들이 제안한 similarity-based information bottleneck은 factor를 찾을 필요가 없으며 적은 양의 content information 손실만 사용하기 때문에 더 우수하다는 것을 알 수 있습니다.
Conclusion
저자들은 similarity-based information bottleneck과 adversarial feedback을 사용하여 voice style을 분해하고 변환할 수 있는 VoiceMixer를 제안합니다. 적절한 information bottleneck size를 선택해야 할 필요가 없으며, 저자들의 model이 self-supervised representation learning을 통해 downsampling factor를 잘 학습할 수 있습니다. 저자들의 새로운 information bottleneck이 content와 style information을 분해하는 데 효과적임을 입증했습니다. 그리고 text transcript과 target phoneme duration 없이도 information bottleneck의 alignment가 phonetic alignment와 비슷하다는 것을 보였습니다. 저자들은 adversarial voice style mixup이 ground-truth speech 없이도 converted speech의 latent representation을 학습할 수 있도록 만들어 준다는 것을 보였습니다.