[논문] Towards Realistic Emotional Voice Conversion using Controllable Emotional Intensity
https://arxiv.org/abs/2407.14800
Towards Realistic Emotional Voice Conversion using Controllable Emotional Intensity
Realistic emotional voice conversion (EVC) aims to enhance emotional diversity of converted audios, making the synthesized voices more authentic and natural. To this end, we propose Emotional Intensity-aware Network (EINet), dynamically adjusting intonatio
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
realistic emotional voice conversion (EVC)는 변환된 audio의 감정적 다양성을 높여 더욱 진짜 같고 자연스러운 음성을 합성하는 것입니다. 이를 위해, 저자들은 controllabel emotional intensity를 통합하여 억양과 리듬을 dynamic 하게 조절할 수 있는 Emotional Intensity-aware Network (EINet)을 제안합니다. emotional intensity의 뉘앙스를 더 잘 capture 하기 위해, 저자들은 단순히 acoustic feature 간의 거리 측정에 의존하지 않습니다. 대신 emotion evaluator를 이용해 사람의 감정 상태를 정밀하게 정량화합니다. intensity mapper를 이용함으로써, emotional speech intensity modeling과 run-time conversion 사이 gap을 연결하는 intensity pseudo-label을 얻습니다. controllability를 유지한 채로 high speech quality를 보장하기 위해, emotion renderer를 사용해 frame level에서 linguistic feature와 조작된 emotional feature를 smooth 하게 결합합니다. 나아가 duration predictor를 사용해 특정 감정 강도 값에 따라 리듬 변화를 adaptive 하게 예측할 수 있도록 만들었습니다.
Introduction
현재 대부분의 EVC system들은 autoencoder 기반 sequence-to-sequence framework로 구성되며, 음성 품질에 상당한 발전을 이루었습니다. 하지만 실제 같은 speech를 합성하기 위해선 감정적 다양성이 매우 중요한데, 변환된 audios는 감정적 다양성이 부족하다는 문제가 존재합니다. 그러므로 감정적 표현을 조작하기 위해 intensity control module를 EVC framework에 통합하는 것이 주요 연구 과제로 떠올랐습니다. 이를 통해 감정 표현을 제어 가능하게 만들어 one-to-many 문제를 해결할 수 있습니다.
EVC에서 감정적 강도를 조절하는 것을 성공적으로 수행할 수 있음에도 불구하고, 변환된 vocal의 감정 표현은 여전이 사람의 지각적 기대와는 차이가 있으며, 특히 자연스러움과 다양성 측면에서는 더욱 부족함이 드러납니다. 이러한 부족함은 일반적으로 사용되는 intensity modeling method가 acoustic feature 간 차이에만 의존하기 때문에 발생할 수 있습니다. 이는 화자의 내재적 감정 변동을 간과하기 때문에, emotional intensity modeling과 run-time conversion 사이 불일치가 발생하고 실제 같은 voice를 합성하는 데 큰 장애물이 됩니다.
dimensional representation method는 감정 상태 사이 차이를 더 정확하게 묘사할 수 있습니다. 한 연구에서는 valence와 arousal이라는 2차원 VA space 내에서 wedge area를 통해 감정 강도 값을 측정했었습니다. 따라서 valence-arousal-dominance (VAD) value를 emotional intensity control module에 적용하는 것이 emotional intensity pseudo-label을 정확하게 생성할 수 있을 뿐만 아니라, 감정 표현에 대한 세밀한 제어를 가능하게 만들어줍니다.
위를 기반으로, 저자들은 Emotional Intensity-aware Network (EINet)을 제안합니다. 이는 변환된 audio의 자연스러움과 다양성을 향상시키기 위해 조절 가능한 감정적 intensity를 이용하며, 궁극적으로 emotion conversion이 더 사실 같은 음성을 합성하도록 만들어 줍니다. acoustic feature만 사용하여 측정하는 것과 다르게, 저자들은 emotional intensity에 대한 pseudo-label을 생성하기 위해 emotional feature들 사이 거리에 초점을 맞추며, 이를 통해 emotional intensity modeling과 run-time conversion 사이 불일치를 효과적으로 다룰 수 있습니다. utterance level에서 emotional expression의 뉘앙스를 파악하기 위해, emotion evaluator를 사용해 VAD value를 예측합니다. intensity mapper에 의해 얻어지는 VAD value 간 거리를 평가하여 pseudo-label을 구하고, 이는 인간이 지각하는 감정 강도에 더 잘 맞춰져 변환된 audio의 감정적 다양성을 크게 향상시킵니다. 감정 강도 조절 때문에 speech quality가 저하되지 않도록 만들기 위해, emotion renderer를 사용해 frame level에서 linguistic feature와 조작된 emotional feature를 통합합니다. 추가적으로 저자들은 duration predictor를 사용해 speech duration을 수정하고 emotional intensity value에 맞춰 리듬 변화를 adpative 하게 예측합니다.
Proposed Method

위 그림처럼 EINet 은 conditional variational autoencoder (CVAE) 기반이며, posterior network, intensity mapper, prior network, decoder로 구성됩니다.
posterior network (PosNet)은 VAD value라는 inherent emotional state를 capture합니다. 특정 emotion category $e$와 source audio $y$로부터 $y_v$라는 emotional state를 capture 합니다. 이는 posterior distribution $q(z_q | c_q)$를 생성하기 위한 condition factor로 사용됩니다. 또한 identity loss 문제를 완화하기 위해 speaker characteristic $h_{speaker}$를 추출합니다.

위 식에서 $c_q$는 emotion category $e$와 source audio $y$를 포함합니다.
학습 과정에서 intensity mapper (IM)는 inherent emotional state $y_v$를 기반으로 intensity pseudo label $\hat{e}_i$를 생성합니다. inference 할 때는 특정 intensity $e_i$와 target emotion category $e$를 가지고 그에 대응하는 VAD value $\hat{y}_v$를 생성합니다.

prior network (PriorNet)은 linguistic content $y_t$와 intensity information을 포함하고 있는 VAD value $y_v$를 기반으로 prior distribtuion $p(z_p | c_p)$를 예측합니다.

위 식에서 $c_p$는 linguistic content $y_t$와 emotional descriptor $y_v$를 포함합니다.
학습할 때는 $z_q$에서 $z$를 구하고, inference할 때는 $z_p$에서 $z$를 구하며, 이 latent representation $z$에 따라 decoder가 waveform을 reconstruct 합니다. 둘 다 speaker information $h_{speaker}$를 사용합니다. 추가적으로, adversarial learning을 이용해 content랑 emotion 측면에서 자연스러움을 점진적으로 향상시킵니다.

Posterior network
source audio $y$와 emotion category $e$를 포함하고 있는 $c_q$가 주어지면, posterior network가 CVAE의 posterior distribution $q(z_q | c_q)$를 제공합니다. emotion evaluator는 utterance level에서 VAD value를 추출하며, 이 VAD value는 세밀한 emotional acoustic feature로 변환됩니다. 이때 normalizing flow $f_{\theta}$를 이용해 fine-grained normal distribution으로 표현됩니다. speaker characteristic $h_{speaker}$는 identity maintainer에 의해 추출됩니다.

- Emotion evaluator
speech emotion은 본질적으로 supra-segmental 하기 때문에, emotional latent representation을 학습하기 어려우며 적절한 상태로 emotional state를 정량화하는 것은 어렵습니다. 이러한 문제를 해결하기 위해, circumplex theory 기반 speech emotion recognition (SER) model을 이용해 각 utterance의 valence-arousal-dominance value $\hat{y}_t$를 예측합니다. 이를 통해 화자의 내면 상태의 유쾌함, 활성도, 영향력을 평가합니다. 이 prior knowledge를 이용하여, 2개 1x1 convolution layer와 Wavenet residual block, linear projection layer를 이용해 frame-level의 감정적으로 세밀한 acoustic feature를 추출할 수 있습니다.
- Identity maintainer
controllable EVC은 acoustic feature의 합성에 대한 조작이 많아지기 때문에, speaker identity를 손실하는 것에 매우 취약합니다. speaker characteristic을 modeling 할 때 fundamental frequency ($f_0$), voicing flag ($v$)와 억양의 중요성을 알기 때문에, 저자들은 1x1 convolutional layer와 linear layer를 결합하여 F0 predictor를 강화하여 이 문제를 해결했습니다. 여기서 voicing flag는 voiced/unvoiced를 나타내는 값입니다.
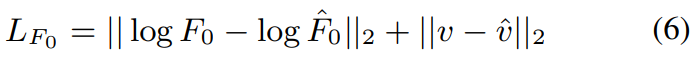
Intensity mapper
거리 측정 method만 사용하여 acoustic feature 사이 차이를 정량화하는 것과 다르게, 저자들은 emotion category $e$와 VAD value $y_v$ 기반 intensity pseudo-label의 분포를 생성합니다. 이때 supervised training을 사용합니다. intensity distribution과 VAD value 사이 mapping 관계를 만들기 위해, 저자들은 reversible normalizing flow 기반으로 설계하였습니다.
- Intensity label construction
학습할 때, intensity mapper는 각 sample의 pseudo-labels $\hat{e}_i \in (0, 1)$를 계산하고 emotional category $\hat{e}$를 예측하기 위해, emotion evaluator로 추출한 VAD value를 사용합니다.
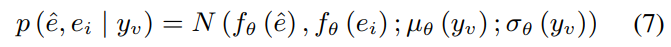
정교한 mapping과 세밀한 control을 보장하기 위해, cross entropy loss와 feature mapping loss 둘 다 사용하여 cateogrical level과 feature level에서의 예측 정확도를 평가합니다. 그리고 학습 초기부터 중기, 중기부터 후기를 구분하여 두 loss를 조정하기 위해 2가지 coefficient를 사용합니다.
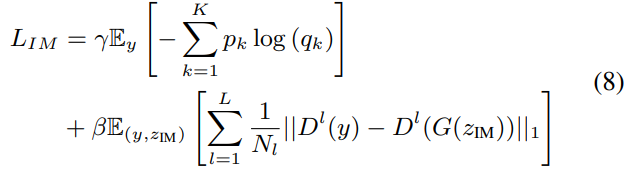
$K$는 emotion category 수를 나타내고, $p$는 emotion label을 나타내며, $q$는 classification distribution을 나타내고, $L$은 discriminator의 총 layer 수를 나타내고, discriminator의 $D^l$는 $l$-th layer의 feature map을 나타냅니다. 이 feature map은 $N_l$개 feature로 구성됩니다.
- Emotional intensity control
inference할 때는 특정 target emotion category $e$와 intensity value $e_i \in (0, 1)$를 가지고 intensity mapper는 VAD value $\hat{y}_v$를 예측합니다. 이를 통해 reference audio 없이 emotional expression을 바로 조절할 수 있습니다.

Prior network
prior network는 linguistic content $y_t$와 emotion descriptor $y_v$를 기반으로 CVAE의 prior distribution $p(z_p | c_p)$를 제공합니다. content encoder는 phoneme sequence를 input으로 받아 detail 한 linguistic feature $h_{text}$를 추출합니다. 감정에 대한 정확한 control을 얻기 위해, emotion renderer는 VAD value 기반 frame-level acoustic feature를 생성합니다. duration predictor는 emotional intensity, linguistic feature, speech duration 간의 관계를 분석하기 위해 emotional and textual feature를 통합합니다. 이를 통해 emotional intensity 기반으로 다양한 duration을 예측할 수 있게 되며, 궁극적으로는 전반적 emotional diversity를 풍부하게 만듭니다.
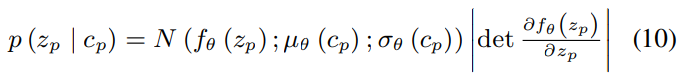
- Content encoder
사람의 perception에 상당한 영향을 주는 mispronunciation 뿐만 아니라 skipping-word를 피하기 위해, content encoder는 phoneme sequence에서 linguistic feature를 추출합니다. 이는 intensity control를 수행하는 emotion conversion에서 textual content를 보존하는데 중요한 역할을 합니다. 이는 fully connected layer, Feed-Forward Transformer (FFT) block, linear projection layer로 구성됩니다.
- Emotion renderer
균일하게 emotional state를 linguistic content와 결합하기 위해, emotion renderer는 generalized VAD value를 nuanced emotional acoustic feature로 확장합니다. 이는 1x1 dilated convolution layer, Wavenet residual block, linear projection layer로 구성됩니다.
- Duration predictor
같은 textual content라도 다양한 emotional intensity에 따라, voicing duration, pause location가 달라질 수 있습니다. 이를 고려하여 emotional feature와 linguistic feature를 통합하여 duration predictor을 설계하였습니다. phoneme level에서의 logarithm of duration을 계산하며, 이를 통해 emotional speech를 rhythmic modeling 하는 성능을 크게 향상시켰습니다. 이는 5개 1x1 convolution layer와 2개 1x1 dilated convolution layer, 그리고 linear projection layer로 구성됩니다.
Final loss
CVAE에 adversarial training을 적용하기 위해, 저자들은 다음과 같이 전체 loss를 정의했습니다.
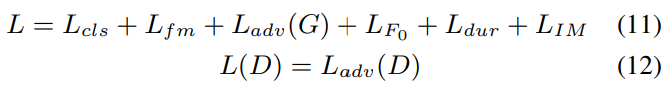
$L_{cls}$는 generated spectrogram과 target spectrogram 사이 L1 distance를 minimize 하고, $L_{fm}$은 각 discriminator의 중간 layer에서 추출한 feature map 사이 L1 distance를 minimize 하며 학습의 안정성을 향상시켜줍니다. $L_{adv}(G)$와 $L_{adv}(D)$는 각각 Generator adversarial loss와 Discriminator adversarial loss를 나타냅니다. $L_{dur}$는 추정된 alignment를 통해 얻어진 predicted duration과 ground truth 사이 L2 distance를 minimize 합니다.
Experiments
Experimental setup
저자들은 ESD에 있는 Mandarin corpus를 사용하여 emotion conversion을 수행하였습니다. 이는 neutral to angry, happy, sad, surprise로 구성됩니다. 각 emotional category마다 utterance의 평균 duration은 3.23s, 2.68s, 2.84s, 4.04s, 3.32s입니다.
Models for comparison
저자들은 다음 model들을 학습시켜 비교를 진행했습니다.
- Seq2Seq-EVC (baseline): seq2seq-based EVC model로, basic emotion conversion을 수행할 수 있지만, controllability가 부족합니다.
- Emovox (baseline): seq2seq-based EVC model로, RAR를 이용하여 acoustic feature 사이 distance를 계산하고 control을 수행하기 위해 intensity pseudo-label을 생성합니다.
- VITS-EVC (baseline): original VITS를 기반으로 설계된 EVC model로, basic emotion conversion만 수행 가능합니다.
- EINet (proposed): VAD value를 통해 distance를 계산하는 intensity mapper를 사용하는 model로, emotional intensity pseudo-label을 통해 control을 수행할 수 있습니다.
Model performance

위 표와 같이, 저자들은 mel-cepstral distortion (MCD), root mean squared error of log $F_0$ ($RMSE_{F_0}$), average difference of duration (DDUR), pretrained SER model을 이용한 classification accuracy ($ACC_{cls}$)를 측정하였습니다. subjective evaluation의 대해선, mean opinion score (MOS) test를 수행했습니다. 25명의 참가자에게 각 125개 utterance를 들려주었으며 자연스러움과 감정 유사도를 평가받았습니다.
EINet이 objective와 subjective 모두에서 좋은 성능을 보여주었습니다. Seq2seq-EVC와 비교하여, Emovox는 대부분의 metric에서 개선이 미미했으며, 특히 자연스러움은 0.11 감소한 결과를 보였습니다. 이는 acoustic feature 간 거리만 사용하여 pseudo label을 측정하면 speaker의 내재적 감정 변동을 간과할 수 있어 변환된 음성의 표현이 제한될 수 있음을 의미합니다. 반대로 EINet은 VAD value를 guidance로 사용하여 더 사실적은 억양과 rhythm 변화를 달성했으며, RMSE, DDUR을 감소시켰습니다. 그리고 자연스러움과 유사도에 있어 큰 향상을 보였는데, 이는 emotional intensity control module이 basic EVC model에 존재하는 emotion contrl과 speech synthesis 사이 mismatch를 적절히 완화시켰다는 것을 의미합니다. 기본 성능을 저하시키기 않으면서 세밀한 감정 표현을 더욱 향상시켰습니다.
Ablation study
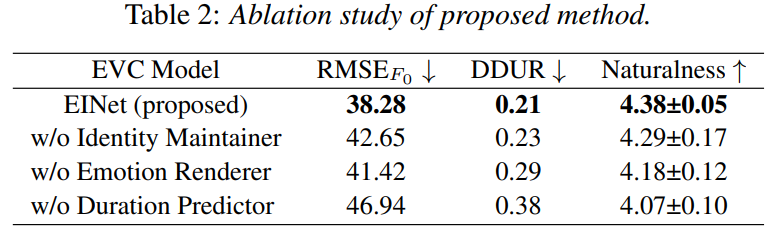
저자들은 기여도를 평가하기 위해 ablation study를 수행했습니다. identity maintainer, emotion renderer, duration predictor를 각각 제거하면서 audio의 naturalness를 평가했습니다. 결과는 위와 같습니다. 모든 component가 각각 제거되었을 때 성능이 저하되는 것을 볼 수 있습니다. identity maintainer를 제거했을 때, RMSE가 상당히 증가되는 것을 볼 수 있습니다. speaker characteristic이 posterior netowrk에서 $L_{F_0}$에 의해 constrain 되지 않았다는 것을 의미하며 부자연스러운 억양을 이끌어냅니다. emotion renderer를 단순한 concatenation으로 대체했을 때 DDUR이 증가되었습니다. linguistic content와 emotional information의 feature fusion이 없기 때문에, prior network가 리듬 변화를 modeling 하는 성능이 부족해집니다. 추가적으로 duration predictor를 제거하면 모든 metric에 영향을 주는 모습을 보입니다. EINet은 target emotion category와 controllable emtional intensity를 기반으로 speech duration을 바로 조절할 수 있으며, 이에 대한 중요성을 확인할 수 있었습니다.
Controllability of emotional intensity
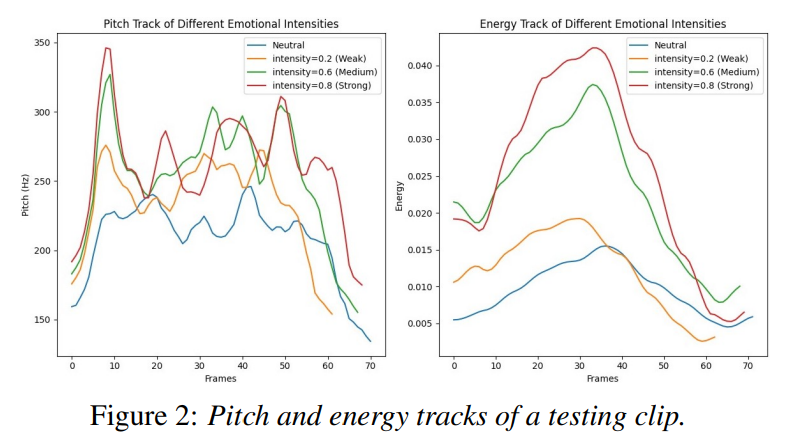
emotional intensity를 control 할 수 있는 능력을 보이기 위해, 저자들은 neutral to happy인 testing clip에서 voicing part의 pitch와 energy track을 visualize 했습니다. 결과는 위와 같습니다. emotion state가 weak에서 strong으로 증가됨에 따라 emotional intensity가 점진적으로 향상됩니다. 그에 따라 pitch variation 폭이 넓어지고 energy의 최대치가 증가됩니다.
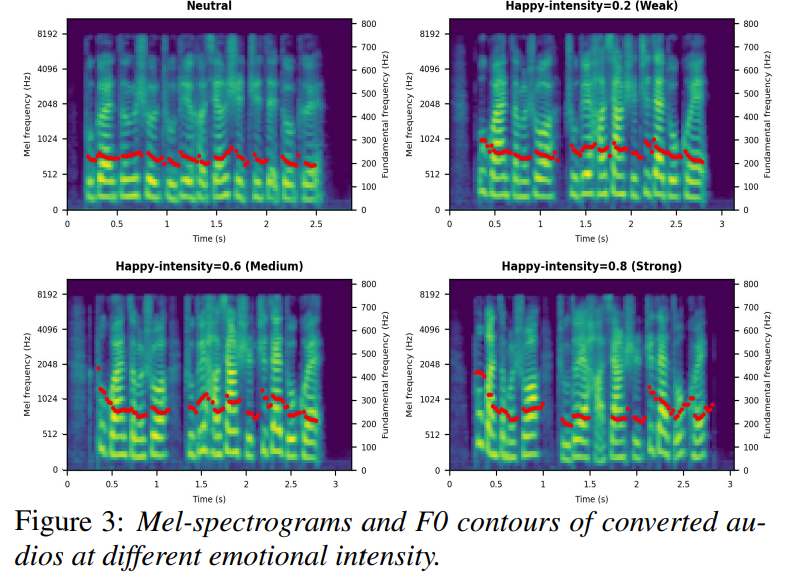
그리고 위 그림은 합성된 Mel-spectrogram의 F0 contour를 보여줍니다. 이를 통해 emotional intensity가 증가됨에 따라 acoustic variation이 더 두드러지며, 짧은 pause가 더 많이 등장합니다. 이는 EINet이 controllable emotional intensity를 기반으로 내재된 감정적 상태를 적응적으로 전달할 수 있음을 의미하며, 억양과 리듬 합성 모두에서 최적의 결과를 달성했습니다.
Conclusion
이 논문에서, 저자들은 Emotional Intensity-aware Network (EINet)을 제안합니다. controllable emotional intensity를 이용함으로써 사실 같은 emotional voice conversion (EVC)를 달성했습니다. ESD corpus에 대한 실험 결과를 통해 이 method의 뛰어난 성능을 입증했습니다.