[논문] Converting Anyone's Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model
https://arxiv.org/abs/2405.01730
Converting Anyone's Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model
Expressive voice conversion (VC) conducts speaker identity conversion for emotional speakers by jointly converting speaker identity and emotional style. Emotional style modeling for arbitrary speakers in expressive VC has not been extensively explored. Pre
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Expressive voice conversion (VC)는 speaker indentity와 emotional style을 동시에 변환함으로써 감정이 담긴 음성을 reconstruct 하는 작업입니다. 임의의 speaker로의 emotional style modeling은 많이 연구되지 않았습니다. 이전 방식들은 vocoder에 speech reconstruction을 의존했으며, vocoder의 성능에 따라 speech quality가 많은 영향을 받았습니다. expressive VC의 주요 문제는 emotion prosody modeling입니다. 이러한 문제를 해결하기 위해, 이 논문에서는 conditional denoising diffusion probabilistic model (DDPM) 기반 fully end-to-end expressive VC framework를 제안합니다. 저자들은 self-supervised speech model에서 얻어지는 speech unit을 content condition으로 사용하고 speech emotion recognition에서 deep feature를 추출하고, speaker verification system에서도 deep feature를 추출해 emotional style과 speaker indentity를 modeling 합니다.
Introduction
감정은 자연스러운 speech에서 중요한 요소로, 화자의 감정, 기분, 성격을 전달합니다. speech expressiveness는 다양한 범위의 감정을 포함합니다. expressive voice conversion은 speaker identity와 화자의 감정 style을 동시에 변환하는 것을 목표로 합니다.
많은 voice conversion 연구들이 등장했지만 여전히 감정 style을 변환하는 VC는 어려운 과제로 남아있습니다. 감정이 담긴 음성의 계층적 구조, 복잡성, 주관적 특성, 변동성 때문에 emotion style을 modeling 하기 어렵기 때문입니다. 그리고 emotional style은 speaker-independent and speaker-dependent feature를 포함하고 있습니다. speaker-independent emotional feature는 다른 화자들 사이에서도 동일한 감정이라면 일관된 연관성을 보이지만, speaker-dependent feature는 speaker characteristic을 나타내고 각 화자마다 unique 합니다. 이전 연구들에서는 speaker-dependent emotional feature를 간과하는 경향을 보였습니다. 이 논문에서 저자들은 speaker-dependent and speaker-independent emotional feature를 고려하여 converted speech의 표현력을 향상시키는 것을 목표로 합니다.
또 다른 한계로, 이전 연구들은 vocoder에 의존해 acoustic feature로부터 speech waveform을 reconstruct 하였습니다. 결과적으로 합성된 speech의 quality는 vocoder의 성능에 상당히 영향을 받으며, vocoder는 학습을 위해 상당히 많은 양의 high-quality speech data를 필요로 합니다. 이러한 문제를 해결하기 위해, 저자들은 expresssive VC를 수행할 수 있는 fully-end-to-end diffusion based framework를 제안합니다. 저자들의 model의 flexibility를 any-to-any conversion으로 입증합니다.
이 논문에서 저자들은 DEVC라 불리는 expressive voice conversion을 제안합니다. 이는 emotionally expressive speaker를 위한 효과적인 spekaer identity conversion이 가능합니다. 이를 위해, 저자들은 content representation, speaker-dependent emotional cue를 포함하는 speaker representation, speaker-indenpendent emotion representation을 다루기 위해 3가지 encoder를 사용합니다. content embedding은 speech unit을 통해 얻어지며, speaker verification (SV) system에서 speaker-dependent emotional informtation을 담고 있는 deep feature를 추출하고, speech emotion recognition (SER) system에서 spekaer-independent emotional information을 담고 있는 deep feature를 추출합니다. 또한 conditional denoising diffusion probabilistic model (DDPM)을 이용해 반복적으로 Gaussian noise에서 content, speaker, emotion representation을 condition으로 하는 waveform을 reconstruct 합니다. 저자들의 main contribution은 다음과 같이 정리됩니다.
- 저자들은 large-scale training data랑 manual annotation 없이도 사용할 수 있는 conditional diffusion model 기반 fully end-to-end expressive voice conversion framework를 제안합니다.
- 저자들은 neutral data로 pre-train 된 SV model에서 얻어낸 speaker embedding이 효과적으로 speaker-dependent emotional cue를 capture 할 수 있고, 이를 통해 expressive voice conversion 성능 향상을 이끌어 낼 수 있음을 발견했습니다.
- 저자들의 framework는 unseen emotional speaker를 포함한 any-to-any emotional voice conversion을 수행할 수 있으며, flexible 하다는 것을 보였습니다.
Emotion and Speaker Representations: A Novel Analysis for Expressive VC
expressive speech는 acoustic feature의 변화를 발생시키며, speaker identity의 복잡성을 증가시킵니다. expressive voice conversion에서는 speaker identity가 speaker-dependent emotional cues와 다른 speaker-related information 모두 포함하고 있다고 기대합니다. speaker-dependent emotional cues는 화자 개인의 특정 emotional information을 나타냅니다. 이러한 speaker-dependent cues는 speaker's emotional state를 반영하는 억양, 리듬의 변화를 포함합니다.
이러한 speaker-dependent emotional cues를 expressive voice conversion model에 적용하기 위해, 저자들은 pre-trained SV model에서 speaker representation을 추출했습니다. 이러한 speaker representation은 expressive voice conversion model의 condition information으로 동작하며, target speaker identity와 emotion 뉘앙스를 보존한 converted speech를 생성하도록 도와줍니다.
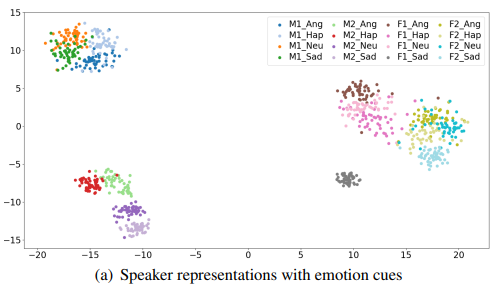
t-SNE algorithm을 사용하여 저자들은 2명의 여성 화자와 2명의 남성 화자의 speaker representation을 visualize 했습니다. 결과는 위와 같습니다. 저자들은 각 speaker별로 별도의 cluster가 형성되었음을 보이며, 이는 speaker identity를 성공적으로 구분하여 나타낸 모습입니다. 또한 저자들은 동일한 화자 내에서 감정 상태별로 작은 cluster가 형성되는 모습을 확인했으며, spekaer-dependent emotional information의 존재를 나타내는 모습이라고 합니다.

speaker representation의 유사도를 더 평가하였습니다. 저자들은 ESD dataset에서 240개 emotional speech utterance를 random 하게 선택하였으며, 이를 2가지 group으로 나눴습니다. 이 두 group에서 utterance pair 간의 euclidean distance를 계산하여 emotion pair 간의 평균 거리를 측정했으며 결과는 위와 같습니다. 일관성 있게 동일한 감정 상태의 거리는 다른 감정 상태보다 더 가깝다는 것을 알 수 있습니다. 이러한 일정한 pattern을 통해 speaker representation은 speaker-related information 뿐만 아니라 speaker-dependent emotional cues도 포함하고 있음을 알 수 있습니다.

저자들이 제안한 method에서 저자들은 pre-trained speaker-independent SER model로부터 spekaer-independent emotion representation으로 deep feature를 추출하는 방식을 사용했습니다. speaker-independent emotion representation을 시각적으로 분석하기 위해 t-SNE algorithm을 사용했으며, 결과는 위와 같습니다. 위 결과를 통해 다른 감정들은 잘 분리된 cluster를 형성하는 것을 볼 수 있습니다. 각 cluster 내에서 동일한 감정이지만 다른 speaker의 representation들이 섞여 있는 모습을 보입니다. 이를 통해 저자들의 emotion representation이 speaker-independent emotional style information을 포함하며, 다양한 화자 간의 generalization이 가능하게 함을 보여줍니다.
이러한 분석들을 통해, 저자들의 emotion and speaker representation의 특성을 확인했습니다. 이러한 representation을 사용하여, 저자들의 single DDPM이 각 감정 상태의 공통적 특성과 개별 화자의 연관된 감정적 뉘앙스를 효과적으로 modeling 하여 어떠한 화자에 대해서도 효과적으로 expressive speech를 합성할 수 있습니다.
Proposed Method -DEVC
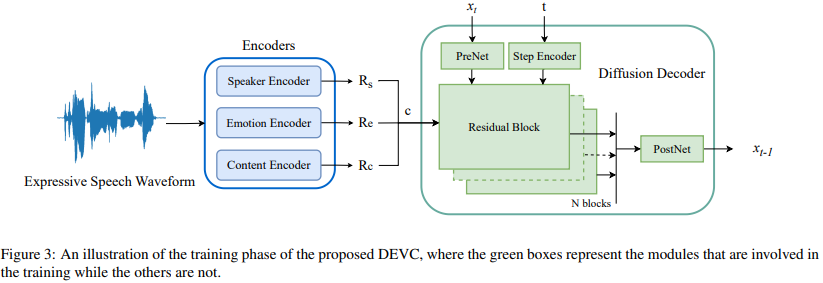
Diffusion-based Expressive Voice Conversion (DEVC)는 content encoder, speaker encoder, speaker-independent emotion encoder, diffusion-based decoder로 구성됩니다. 구조는 위와 같습니다. 이 3가지 encoder들은 input expressive speech에서 content representation, speaker representation with emotional cues, speaker-independent emotion representation을 추출합니다. 이러한 auxiliary representation을 condition으로 사용하여 diffusion-based decoder는 Gaussian noise에 시작해 converted expressive speech를 반복적으로 생성합니다.
Training Stage
S개 audio segment로 expressive speech utterance가 주어졌을 때, content encoder는 waveform으로부터 256-dimensional content representation $R_c \in R^{S \times 256}$을 추출합니다. speaker encoder는 emotional cues가 존재하는 256-dimension utterance-level speaker representation $R_s$를 추출합니다. emotion encoder는 utterance level의 128-dimension speaker-independent emotional style representation $R_e$를 추출합니다. $R_c$f를 align 하기 위해, 저자들은 2개 utterance-level $R_s$와 $R_e$를 반복하여 upsampling 해 $R_s' \in R^{S \times 256}$와 $R_e' \in R^{S \times 256}$를 구했습니다. 저자들은 segment-wise concatenate를 수행해 condition $c$를 구했습니다. 식으로 나타내면 다음과 같습니다.
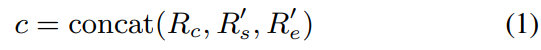
conditional DDPM-based decoder는 diffusion process and reverse process라는 2가지 subprocess가 존재합니다. waveform의 segment $x_0$가 주어졌을 때, diffusion process는 gaussian noise를 점진적으로 T번 추가해 최종적으로 gaussian nosie $x_T$를 생성합니다. $x_{T-1}$에 noise를 추가해 $x_{T}$를 구하며, 이 과정을 각 time step $t \in[1,T]$에서 진행해 구한 sequence of latent variable $(x_1, ... , x_{T-1})$이라 하겠습니다. 식으로 나타내면 아래와 같습니다.
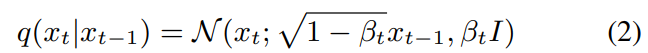
$(\beta_1, ... , \beta_T)$가 고정된 variance schedule입니다. clean data $x_0$가 주어졌을 때, $x_t$의 sampling은 다음과 같은 형태로 작성할 수 있습니다.
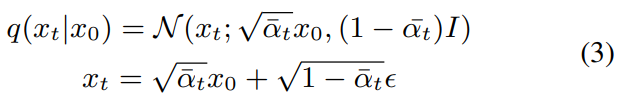
위 식에서 $\alpha_t = 1 - \beta_t$이고 $\bar{\alpha_t} = \Pi_{s=1}^t \alpha_s$ 입니다. Noise $\epsilon \sim N(0,I)$은 data $x_0$와 latent variable $x_1, ... , x_T$와 같은 dimension입니다.
reverse process는 Gaussian noise asmple $x_T$에서 시작해 posterior $q(x_{t-1} | x_t)$를 sampling 하면서 reverse sequence를 생성합니다. 하지만 $q(x_{t-1} | x_t)$가 intractable 하기 때문에, decoder는 학습된 mean $\mu_{\theta}(x_t, t, c)$와 고정된 variance $\sigma_t^2I$를 가지고 parameterized Gaussin transition $p_{\theta}(x_{t-1}|x_t)$을 학습합니다.
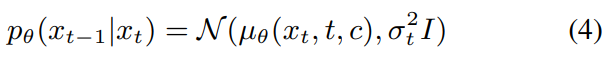
위 식에서 $\mu_{\theta}(x_t, t, c)$는 function of noise approximator $\epsilon_{\theta}(x_t, t, c)$입니다.
speech-conditioning pair를 기반으로, conditional diffusion-based decoder를 다음 loss를 이용해 학습합니다.
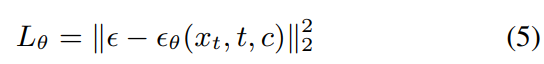
$\epsilon \sim N(0,I)$은 noise이고, $\epsilon_{\theta}$는 learnable parameter $\theta$를 사용하는 decoder를 의미합니다.
Run-time Conversion
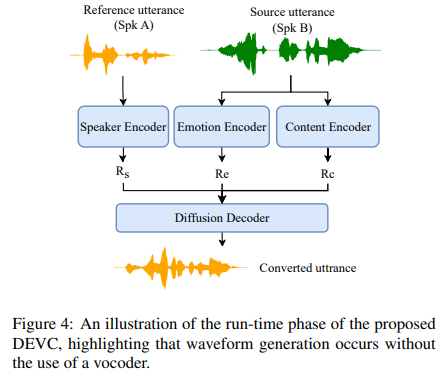
run time에서, DEVC는 한 speaker에서 source utterance를 받고 target speaker에서 reference utterance를 받습니다. 위 그림과 같은 구조입니다. 이는 학습 때 보았던, 또는 보지 못했던 speaker가 됩니다. encoder는 source utterance에서 content representation과 speaker-independent emotional style representation을 추출하고, reference utterance에서 emotional cues를 포함하는 speaker representation을 추출합니다. 그리고 diffusion-based decoder는 gaussian noise와 timestep, representation을 condition으로 하여 converted expressive speech를 생성합니다.
Experiments
Experimental Setup
DEVC는 content encoder, speaker encoder, emotion encoder, diffusion-based decoder로 구성됩니다. content encoder는 HuBERT-Base backbone network 기반으로, linear layer를 추가하고 LibriSpeech-960 dataset으로 pre-train 했습니다. emotion encoder는 three-dimensional CNN layer, BLSTM layer, attention layer, fully-connected (FC) layer로 구성됩니다. 이는 먼저 IEMOCAP dataset으로 pre-train 되며 ESD dataset으로 fine-tuning 하였습니다. speaker encoder는 "Generalized end-to-end loss for speaker verification"의 model을 따르며, 3-layer LSTM with projection to 256을 이용했습니다.
Ablation study
저자들은 emotion cues가 존재하는 speaker representation과 speaker independent emotion representation의 영향을 분석하기 위해 ablation study를 진행했습니다. 구체적으로, 저자들은 동일한 diffusion based decoder 구조를 공유하는 3가지 model을 조사했습니다. 첫 번째 model은 cotent representation과 speaker representation을 포함합니다. 두 번째 model은 content representation과 speaker-independent emotional style representation, one-hot speaker label을 사용했습니다. 마지막 model은 저자들이 제안한 model과 동일한 구조로 이루어집니다. 실험 결과는 다음과 같습니다.
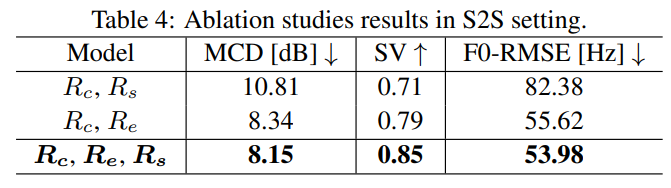
one-hot speaker label 대신 speaker representation을 사용하는 것이 더 뛰어난 모습을 보인다는 것을 알 수 있으며, 이를 통해 speaker representation이 speaker-dependent emotion cues를 효율적으로 capture 한다는 것을 알 수 있습니다.
Conclusion
이 논문에서 저자들은 diffusion-based approach를 사용하여 expressive voice conversion을 수행하는 새로운 framework를 제안합니다. 이는 any-to-any conversion도 수행할 수 있습니다. 저자들의 framework는 speech unit을 content representation으로 사용하고 speech emotion recognition system에서 deep feature를 추출하고 speaker verification system에서 deep feature를 추출하여 emotion and speaker characteristic을 capture 합니다. 저자들의 연구를 통해 pre-trained SV model로부터 얻은 speaker embedding에는 내재된 spekaer dependent emotional feature가 존재한다는 것을 발견했으며, 이를 통해 expressive voice converison task를 잘 수행할 수 있었습니다. 저자들의 framework는 seen and unseen speaker에 대해서도 잘 변환을 수행할 수 있는 flexibility를 보이며, 이는 저자들이 알기론 첫 end-to-end diffusion model-based expressive voice conversion framework입니다.