[논문] Seen and Unseen Emotional Style Transfer for Voice Conversion with a New Emotional Speech Dataset
https://arxiv.org/abs/2010.14794
Seen and Unseen emotional style transfer for voice conversion with a new emotional speech dataset
Emotional voice conversion aims to transform emotional prosody in speech while preserving the linguistic content and speaker identity. Prior studies show that it is possible to disentangle emotional prosody using an encoder-decoder network conditioned on d
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
emotional voice conversion은 linguistic content와 speaker identity를 유지한 채로 speech의 emotional prosody를 변환하는 것을 목표로 합니다. 이전 연구들은 one-hot emotion label과 같은 discrete representation을 condition으로 사용하는 encoder-decoder network를 사용해 emotional prosody를 분리할 수 있었습니다. 이러한 network는 고정된 emotion style의 set을 기억하도록 학습합니다. 이 논문에서 저자들은 variation auto-encoding Wasserstein generative adversarial network (VAW-GAN) 기반의 새로운 framework를 제안합니다. 이는 학습과 inference 과정에서 emotional style을 변환하기 위해 pre-trained speech emotion recognition (SER) model을 사용합니다. 이러면 network는 seen and unseen emotional style을 변환할 수 있습니다.
Introduction
이 논문에서 저자들은 어떠한 input utterance에도 emotional style을 변환할 수 있는 emotional style transfer (EST)라 불리는 새로운 기술을 제안합니다. emotion style은 control condition으로 network에 들어갑니다. network는 unseen emotion에 대한 one-to-many emotion conversion을 수행할 수 있습니다.
Auto-encoder는 latent variable을 통해 output을 control 할 수 있는 적절한 computation model입니다. VAW-GAN을 이용해 speech에서 emotional element를 분리하고 재구성하는 연구가 성공적으로 이뤄졌습니다. 하지만 emotional prosody는 다양한 signal 속성들의 상호작용 결과로 나타나므로, 간단한 labeling scheme으로 정의하기 어렵습니다.
본 논문에서는 VAW-GAN 기반의 emotional style transfer framework를 제안합니다. encoder-decoder가 seen and unseen emotion generation을 수행할 수 있도록 deep emotional feature를 condition으로 사용합니다. 그리고 저자들은 multi-speaker and multi-lingual emotional speech datset인 EVC dataset을 공개합니다. 저자들은 voice conversion 연구에 open-source emotional speech data가 부족하다는 문제를 해결합니다. 이 논문의 main contribution은 다음과 같습니다.
- parallel training data 없이도 one-to-many emotional style transfer framework를 설계하는 것을 제안합니다.
- pre-trained SER을 사용해 emotional style을 표현하는 것을 제안합니다.
- 저자들은 deep emotional feature를 통해 emotional element를 분해하고 재구성합니다.
- 저자들은 ESD라 불리는 multi-lingual and multi-speaker emotional speech corpus를 공개합니다.
저자들이 알기론, 이 논문이 unseen emotion에 대해서도 emotional style transfer를 수행하는 첫 연구입니다.
Analysis of Deep Emotional Features
최근 deep learning의 발전으로 acoustic feature에 대한 traditional human-crafted representation들이 neural network를 이용하여 장으로 학습된 deep feature로 변하고 있습니다. Deep feature들은 data-driven이며, 사람의 지식에 덜 의존적이며 emotional style transfer에 더 적합합니다.
emotional prosody는 emotional speech database에서 뚜렷하게 존재하며, Ekmans's six basic emotion과 같이 discrete category로 characterize 할 수 있으며, Russell's circumplex model처럼 continuous representation으로 characterize 할 수도 있습니다. 최근 연구들은 유한한 discrete categorical label set을 사용하는 대신 continuous space에서 deep neural network를 학습시켜 얻은 continuous feature representation으로 emotion을 characterize 합니다. speech style transfer에서 사용되는 style embedding을 생성하는 emotion recognizer가 연구되었습니다. 한 연구에서는 emotional expressiveness의 intensity를 control 하는 것을 목표로 Tacotron system을 사용하여 style embedding을 구하기도 하였습니다. 이러한 시도들을 통해 deep emotional feature를 prosody ddescriptor로 사용하기 좋다는 것이 밝혀졌습니다.
저자들은 continuous space에서 emotional prosody를 표현하는 voice conversion을 연구합니다. reference speech의 deep emotional feature를 사용하여 emotional style을 output target speech로 변환하는 것이 idea입니다. 그래서 저자들은 2명의 남성과 2명의 여성의 deep emotional feature를 t-SNE algorithm으로 2-dim space에서 표현했습니다. 결과는 다음과 같습니다.
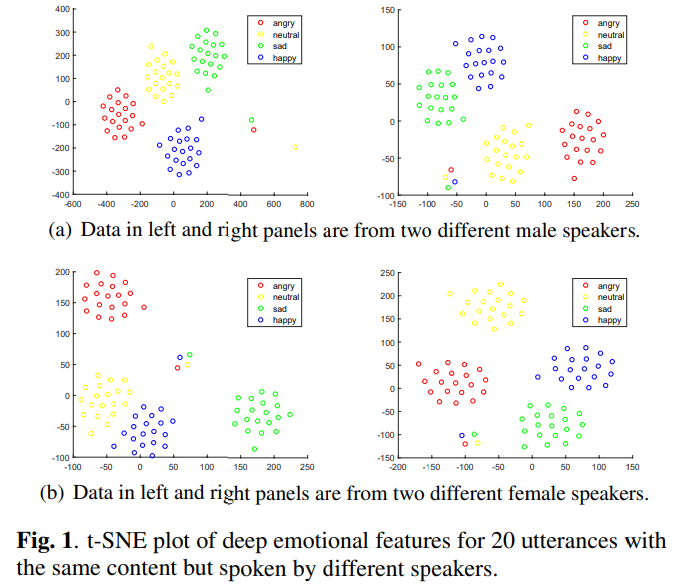
위 그림을 보면 deep emotional feature들이 명확하게 emotion group을 형성하는 것을 알 수 있습니다. 이를 통해 emotion class를 encode하기 위해 deep emotional feature를 style embedding으로 사용할 수 있음을 보였습니다. 이를 통해 저자들은 deep emotional feature를 통해 one-to-many emotional style transfer framework를 제안합니다.
One-to-Many Emotional Style Transfer
저자들은 VAW-GAN이라 불리는 one-to-many emotional style transfer를 제안합니다. 이는 deep emotional feature를 condition으로 사용하는 decoder를 사용합니다. 저자들은 one-to-many EST framework인 DeepEST를 제안합니다. DeepEST는 emotion descirptor training, encoder-decoder training with VAW-GAN, run-time conversion interface라는 3가지 단계로 나눠집니다. stage 1에서 auxiliary SER network를 학습해 input utterance의 emotion descriptor로 사용합니다. stage 2에서는 emotional element를 분리하고 다시 재구성하기 위해 encoder-decoder를 학습하는 것을 제안합니다. stasge 3에서는 DeepEST가 input utterance와 target deep emotion feature를 받아 target emotion style을 나타내는 utterance를 생성합니다.
Stage 1: Emotion Descriptor Training
emotional prosody는 여러 acoustic attribute로 구성되어 있으며 modeling하기 어려울 정도로 복잡합니다. one-hot emotion label처럼 label emotion을 discrete category로 나타내는 연구들이 존재합니다. emotional prosody는 연속적인 스펙트럼 상에서 표현되며, 이를 few category로 나누는 것은 어렵습니다. 그래서 저자들은 large animated and emotive speech data로 학습된 deep emotional feature를 사용합니다.
저자들은 SER model을 emotion descriptor $D$로 사용하는 것을 제안합니다. 이는 input utterance $X$에서 deep emotional feature $\Phi$를 추출합니다. $\Phi = D(X)$ 형태입니다. SER architecture는 3D CNN layer, BLSTM layer, attention layer, fully connected layer로 구성됩니다. 3D CNN layer는 input Mel-spectrogram과 delta and delta-delta feature를 고정된 크기의 latent representation로 project 합니다. 이를 통해 emotion과 관련 없는 factor를 제거하여 효율적으로 emotional information을 보존할 수 있습니다. 그다음 BLSTM과 attention layer가 이전 layer으로부터 시간적 정보를 summarize 하고 emotion prediction을 위한 discriminative utterance-level feature $\Phi$를 생성합니다. visualize 하면 위와 같습니다.
Stage 2: Encoder-Decoder Training with VAW-GAN
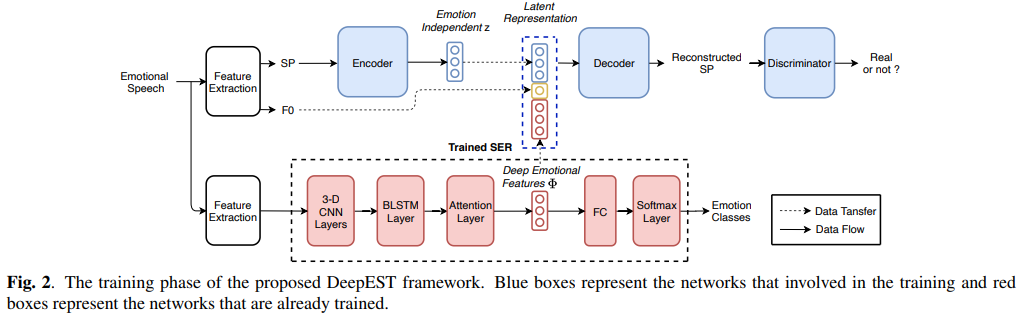
disentangled representation을 효과적으로 학습하기 위해 encoder-decoder 구조를 사용합니다. 저자들은 위와 같은 encoder-decoder 학습 과정을 제안합니다. encoder ($E$)는 input feature로부터 emotional element를 분리하고 latent representation $z$를 생성하도록 학습됩니다. 생성된 representation $z$는 phonetic and speaker information이 존재할 것으로 예측되지만 emotion과는 독립적일 것입니다. decoder/generator ($G$)는 emotion independent representation $z$와 다른 controllable emotion-related attribute들과 함께 input feature를 reconstruct하도록 학습됩니다.
저자들은 WORLD vocoder를 사용해 waveform에서 spectral feature (SP)와 fundamental frequency ($F_0$)를 추출합니다. $\theta$를 parameter set으로 사용하는 encoder ($E_{\theta}$)는 다양한 emotion type의 input spectral frame들을 input으로 받으며, emotion-independent representation $z: z = E_{\theta}(x)$를 학습합니다. source spectrum에서 추출된 latent representation $z$가 여전히 source $F_0$ information을 포함하고 있기 때문에, 변환 성능에 악영향을 미칠 수 있습니다. 그래서 $\psi$를 parameter로 사용하는 decoder/generator ($G_{\psi}$)가 emotion-independent representation $z$와 emotion-related feature를 받고 그에 대응하는 $F_0$를 받아 spectrum의 emotional element를 recompose 합니다. 여기서 emotion-related feature는 stage 1에서 얻어진 deep emotional feature $\Phi$입니다.
reconstructed feature $\bar{x}$는 다음 식으로 나타낼 수 있습니다.
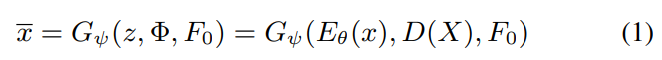
그다음 adversarial training을 통해 spectrum을 생성하는 generative model을 학습시킵니다. $\mu$를 parameter로 사용하는 discriminator ($Y_{\mu}$)는 real featuer $x$와 reconstructed feature $\bar{x}$ 사이 loss를 maximize 하며, generator는 loss를 minimize합니다. parameter set $\theta. \psi, \mu$는 min-max game를 통해 최적화되며, high-quality sample을 생성할 수 있게 됩니다.
Stage 3: Run-time Conversion
run-time conversion에서 저자들은 reference utterance로부터 reference emotion style을 얻어 그에 해당하는 target emotion으로 neutral emotion인 source utterance를 변환하길 원합니다. reference utterance $X_t$들의 set이 있다고 하겠습니다. pre-trained SER을 사용해 모든 deep emotional feature $\Phi_t = mean(D(X_t))$를 생성합니다. 그 다음 source utterance에서 converted $F_0(\hat{F}_0)$와 emotion-independent $z$을 구한 다음 $\Phi_t$와 concatenate합니다. 이렇게 target utterance의 latent representation $SP$를 구성합니다. converted $SP$는 다음과 같습니다.
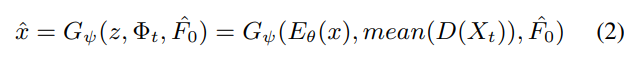
최종적으로 WORLD vocoder를 이용해 converted spectral feature와 converted $F_0$와 target emotion을 이용해 converted speech를 합성합니다.
Experiments
Experimental Setup
저자들은 objective and subjective evaluation을 수행하여 DeepEST model의 seen and unseen emotional style transer 성능을 평가했습니다. 저자들은 4명 speaker에 대해 평가를 진행했습니다. neutral-to-sad와 neutral-to-happy에 대해서는 seen emotion, angry는 unseen emotion으로 설정하여 neutral-to-angry 평가를 수행해 unseen emotion style transfer 성능을 확인했습니다. SER은 IEMOCAP의 subset을 이용해 학습했습니다. 동일한 감정 category에 해당하는 SER module의 deep feature를 구해 평균을 계산해 feature를 만들었습니다.
Objective Evaluation

Mel-cepstral distortion (MCD)를 수행해 converted and reference Mel-spectrogram 사이 spectral distortion을 측정했습니다. 결과는 위와 같습니다. 저자들이 제안한 DeepEST가 모든 seen emotion에서 baseline model보다 뛰어난 성능을 보여줍니다. unseen emotion (angry)에 대해선 DeepEST가 baseline과 비슷한 성능을 보였으며, 여기서 baseline model은 angry라는 감정에 대해서도 학습을 진행했다는 점이 중요합니다. 이러한 결과를 통해 저자들의 model이 seen and unseen emotion에 대한 변환 성능이 효과적임을 볼 수 있습니다. 그리고 3가지 VAW-GAN-EVC을 이용해야 모든 pair에 대한 학습이 진행되는데, 저자들의 DeepEST는 1가지 model로도 전부 수행할 수 있습니다.
Conclusion
이 논문에서 저자들은 VAW-GAN 기반 one-to-many emotional style transfer framework를 제안합니다. 이는 parallel data가 필요 없습니다. 저자들은 SER에서 deep emotional feature를 얻어 이용하여 continuous space에서 emotional prosody를 describe합니다. deep emotional feature와 F0 value와 같은 controllable attribute를 condition으로 두어 seen and unseen emotion에 대한 좋은 변환 성능을 달성했습니다. 그리고 저자들은 ESD 라는 새로운 emotional speech dataset을 제안하며, speech synthesis and voice conversion에서 사용될 수 있습니다.