[논문] SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
https://arxiv.org/abs/2203.12937
SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot suffi
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 paired speech corpora 없이도 가능한 self-supervised speech restoration method를 제안합니다. 이전의 일반적인 speech restoration method들은 high-quality speech corpora에 다양한 distortion을 적용해 artificial paired data를 만들어 사용했기 때문에, real data의 acoustic distortion을 충분히 표현하지 못해 제한적이라는 문제가 존재했습니다. 저자들의 model은 analysis, synthesis, channel module로 구성되며 degraded speech의 recording 과정을 simulate 하고 self-supervised 방식으로 real degraded speech data로 학습을 진행합니다. analysis module은 degraded speech로부터 distortionless speech feature와 distortion feature를 추출하며 synthesis module은 restored speech waveform을 synthesize 하고, channel module은 speech waveform에 distortion을 더해줍니다. 저자들의 model은 degraded speech에서 acoustic distortion만 추출한 다음 임의의 high-quality audio에 더해 audio effect transfer를 수행할 수도 있습니다. simulated and real data에서의 실험 결과를 통해 저자들의 method가 이전 method보다 higher-quality speech resotration이 가능하다는 것을 보였습니다.
Introduction
현대 speech processing 연구에서 사용되는 speech data들은 주로 정교한 digital recording 장비와 잘 설계된 환경에서 녹음됩니다. 하지만 대부분의 audio data는 acoustic distortion을 포함하며 high-quality audio data와는 다른 특성을 지닙니다. speech processing의 application 범위를 확장하기 위해선, 다양한 quality의 speech data를 사용해야 합니다. 하지만 degraded audio를 복원하고 분석하는 것은 degraded speech data와 그에 대응하는 high quality data가 존재하지 않기 때문에 어렵습니다. 일반적이 이전의 speech restoration method들은 supervised learning을 통한 artificial paired corpora에 의존했으며, 실제 data의 acoustic distortion을 표현하기 충분하지 않습니다.
저자들은 paired speech data 없이 가능한 self-supervised speech restoration method를 제안합니다. 저자들의 model은 analysis, synthesis, channel module로 구성되며 degraded speech의 recording process를 기반으로 합니다. analysis module은 degraded speech에서 time-variant distortionless speech feature와 time-invariant acooustic distortion feature를 추출합니다. synthesis module을 distortionless speech (i.e., restored speech)를 합성하고, channel module은 acoustic distortion을 더합니다. model은 degraded input과 reconstructed speech 사이 reconstruction loss를 minimize하여 self-supervised 방식으로 학습됩니다. 저자들은 또한 self-supervised learning의 안정성을 위한 dual-learning method를 제안합니다. backward process는 임의의 high-quality speech corpora를 가지고 distortionless speech feature loss를 정의하며, forward process는 reconstruction loss를 계산합니다. 저자들의 contribution은 다음과 같이 정리할 수 있습니다.
- 저자들은 self-supervised speech reconstruction을 제안합니다. 이는 paired speech corpora 없이도 다양한 acoustic distortion을 학습할 수 있으며 real degraded speech data에도 적용 가능합니다.
- 저자들의 method는 이전 supervised method보다 더 뛰어난 higher-quality speech restoration이 가능합니다.
- 저자들의 model은 degraded speech에서 channel feature만 추출하고 다른 high-quality speech에 적용하는 audio effect transfer도 가능합니다.
Related Work
Speech restoration
많은 이전 연구들은 bandwidth extension, dereverberation, denoising, declipping과 같은 특정 speech restoration에 초점을 맞췄습니다. 저자들의 연구들과 비슷하게, 몇몇 연구들은 동시에 multiple speech restoration task를 수행할 수 있으며 speech restoration을 위해 waveform syntehsis method를 사용했습니다. 이러한 연구들과 다르게, 저자들의 연구는 더해지는 noise를 제거하는 것에 국한되지 않으며, self-training이 가능합니다. 이전 연구들도 일반적으로 저자들의 방식과 유사하게 neural vocoder를 사용해 speech restoration을 수행했습니다. 하지만 저자들의 방식은 paired data가 필요하지 않으며, 생성된 degraded speech data 대신 self-supervised 방식으로 real audio를 사용해 학습할 수 있습니다. 나아가 이러한 방식은 channel feature를 추출할 수 있으며, 임의의 audio에 원하는 channel distortion을 추가하는 방식으로 audio effect를 추가할 수 있습니다.
Proposed Method
Basic framework
high-quality speech (i.e., distortionless speech)는 human production procees 과정을 통해 입에서 발생하며, traditional source-filter vocoder feature나 mel spectrogram과 같은 time-variant speech feature로 parameterize 될 수 있습니다. acoustic distortions (e.g., non-linear response of recording equipment and lossy audio coding)이 high-quality speech에 더해져 최종 recorded audio가 생성됩니다. 저자들은 녹음 장비나 audio coding이 각 audio sample마다 변하지 않기 때문에 distortion (i.e., channel feature)를 time-invariant로 가정합니다.

저자들이 제안하는 speech restoration model은 analysis, synthesis, channel module로 구성됩니다. 그럼으로 보면 위와 같습니다. 모든 module들은 neural network고 구성되며 end-to-end 방식으로 학습될 수 있습니다. 저자들은 degraded-speech waveform을 $x_{low}$, degraded-speech feature를 $y_{low}$로 말합니다. analysis module은 restored speech $y_{low}$로부터 speech feature $\hat{z}_{res}$를 추정합니다. 동시에, analysis module의 중간 feature는 다른 layer의 input으로 들어가 time-invariant channel feature $c$를 추정합니다. 저자들은 $y_{low}$에는 mel-spectrogram을 사용합니다. synthesis module은 human speech production을 simulate 합니다. $\hat{y}_{low}$를 input으로 받아서 restored speech $\hat{x}_{res}$의 speech waveform을 추정합니다. HiFi-GAN을 사용해 synthesis module을 구현했으며, 임의의 hihg-quality speech corpus로 학습시킨 후 frozen 하여 사용했습니다. channel module은 acoustic distortion을 simulate 합니다. 이는 channel feature $c$를 condition으로 사용하고 degraded speech $\hat{x}_{low}$를 추정하기 위해 restored speech $\hat{x}_{res}$에 distort를 적용합니다. model은 frame-level reconstruction loss를 minimize 하도록 학습되며, multi-scale spectral loss로 정의될 수 있습니다.

위 식에서 $s_i$는 $x_{low}$의 amplitude spectrogram을 나타내고, $\hat{s}_i$는 $\hat{x}_{low}$의 amplitude spectrogram을 나타냅니다. $i$는 Fourier transform의 window length를 의미하고 $\alpha$는 log term의 weight를 의미합니다. 저자들은 $i = (2048, 1024, 512, 256, 128, 64)$와 $\alpha = 1.0$으로 설정하고 실험을 진행했습니다. speech restoration은 학습된 analysis and syntehsis module을 이용해 수행됩니다. analysis module은 degraded speech의 acoustic feature $y_{low}$를 받고, synthesis module은 restored-speech waveform $\hat{x}_{res}$를 합성합니다.
학습된 model은 "audio effect transfer"도 수행할 수 있습니다. audio effect는 synthesis module 없이 수행 가능합니다. 먼저 학습된 analysis module을 사용해 degraded speech $x_{low}$에서 channel feature $c$를 추출합니다. 학습된 channel module은 해당 $c$를 condition으로 사용해 임의의 high-quality audio에 distortion을 적용해 degraded speech를 합성합니다.

위 그림은 저자들이 제안한 method로 만들어낸 spectrogram입니다. input low-quality speech는 ground-truth high-quality speech에 존재하는 high-frequencyh band를 missing하고 low-frequency band를 distortion 하는 것을 볼 수 있습니다. restored speech에서 missing and distorted band가 복원된 것을 볼 수 있습니다. 그리고 channel module로 만든 reconstructed speech output은 input speech를 잘 reproduce 한 것을 볼 수 있습니다.
basic self-supervised training process는 각 module이 high expressive power를 가지고 있기 때문에 불안정하며, degraded waveform과 reconstructed waveform 사이 reconstruction loss만 이용해 학습되기 때문에 불안정합니다. 구체적으로 analysis module은 channel module의 영향을 표현할 수 있기 때문에 analysis module이 high-quality speech의 speech feature를 output 한다고 보장할 수 없습니다. 그래서 저자들은 dual-learning method를 제안합니다. 또한 저자들은 매우 제한된 양의 data만 가능할 때, 성능 향상을 할 수 있는 supervised pre-training method를 제안합니다.
Dual Learning for stable self-supervised learning
Figure 1은 dual-learning method를 보여줍니다. 저자들은 backward 방향에서 정보를 propagate하는 training task를 제안합니다. forward direction을 $\tau_{forward}$, backward direction을 $\tau_{backward}$로 표기합니다. $\tau_{forward}$는 basic learning framework입니다. degraded speech를 analysis module에 넣어 degraded waveform을 reconstruct 합니다. 반면에 $\tau_{backward}$는 high-quality speech를 channel module에 input 하여 high-quality speech의 feature를 추정합니다. 저자들의 method는 machine translation에서의 두 domain 사이 forward and backward learning과 유사합니다.
여기서 저자들은 degraded speech와 align하지 않고 다른 speaker의 utterance로 구성된 임의의 high-quality speech를 사용합니다. high-quality speech waveform $X_{high}$는 먼저 channel module로 들어가 channel feature가 존재하는 degraded speech waveform $\hat{X}_{low}$를 생성합니다. 그다음 degraded speech의 speech feature $\hat{Y}_{low}$를 analysis module에 input 하여 restored speech의 speech feature $\hat{Z}_{res}$를 추정합니다. feature loss는 mean square error를 사용해 정의되며 다음 식으로 표현됩니다.
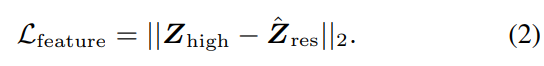
최종 loss function은 다음과 같이 weighted sum 형태로 표현됩니다.
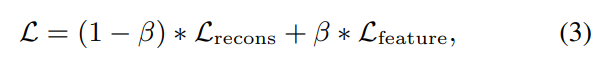
위 식에서 $\beta$는 feature loss에 대한 weight입니다. feature loss의 graidnet는 channel module로 propagate 되지 않으며, channel module은 reconstruction loss로만 학습됩니다. 직관적으로 forward, backward는 다음과 같이 해석될 수 있습니다.
- $\tau_{forward}$는 degraded speech에 적응하는 analysis module과 acoustic distortion을 표현하는 channel module을 얻습니다.
- $\tau_{backward}$는 high-quality speech feature를 추정하는 analysis module을 얻습니다.
이러한 dual learning method는 analysis module과 channel module을 paired data 없이 self-supervised learning이 가능하게 합니다.
Supervised pretraining for low-resource settings
데이터 부족 문제가 존재합니다. 그러므로, 저자들은 supervised pre-training method를 사용해 low data resource condition에서의 initial weight를 얻는 방법을 제안합니다.
- 임의의 high-quality speech data로부터 paired data를 생성해 analysis and channel module을 supervise 방식으로 학습합니다.
- supervised pre-training을 통해 얻은 초기화를 가지고 위에서 언급한 방식대로 real degraded speech data로 self-supervised learning을 수행합니다.
supervised pretraining에서, 저자들은 random 하게 original high-quality speech에 distortion을 적용하여 pseudo-degraded speech waveform $X_{pseudo-low}$를 생성합니다. pseudo-degraded speech feature $Y_{pseudo-low}$로부터 추정된 restored speech feature $\hat{Z}_{res}$가 있을 때, feature loss $L_{feature} = ||Z_{high} - \hat{Z}_{res}||_2$로 정의됩니다. synthesis module의 output을 사용하는 대신 channel module에 high-quality speech waveform을 input 합니다. 그다음 model은 weighted sum을 minimize 하도록 학습됩니다.
Experimental evaluations
Experimental condition
- Speech feature analysis
저자들은 speech feature $\hat{z}_{res}$를 2가지 종류인 mel spectrogram과 source-filter vocoder feature로 표현했습니다. frame size를 1024로 설정하고 frame shift를 256으로 하여 80차원 mel-spectrogram을 추출했습니다. WORLD vocoder를 이용해 5-ms frame shift로 F0와 41-dimensional mel ceptrum coefficient로 구성된 vocoder feature를 추출했습니다.
- Model details
저자들은 analysis and channel module로 U-Net 구조를 사용했습니다. U-Net의 각 down sampling에서 temporal resolution이 감소됩니다. up-sampling 과정에서는 temporal resolution이 2배로 증가되어 input feature와 동일한 temporal resolution이 됩니다. synthesis module의 경우, Mel spectrogram에서는 pretrained multi-speaker model을 사용했으며, vocoder feature에서는 JVS corpus로 학습된 model을 사용했습니다.
Evaluation on speech restoration with simulated data
저자들은 high-quality speech corpus에 다양한 artificial distortion을 더하여 proposed method를 평가했습니다. 이전의 supervised speech restoration model들과 비슷한 setting으로 실험을 진행해 성능을 비교했습니다.
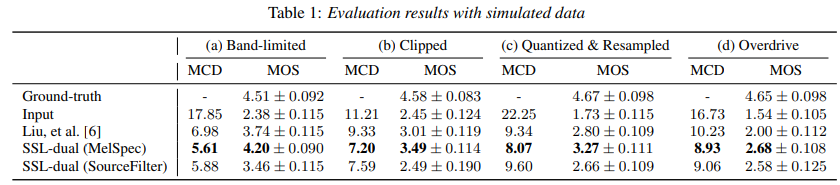
실험 결과는 위와 같습니다. 저자들은 mel cepstral distortion (MCD)를 통해 objective evaluation을 진행했습니다. 그리고 MOS를 통해 subjective evaluation을 수행했습니다. 저자들의 SSL-dual (MelSpec)이 상당히 뛰어난 성능을 보이는 것을 볼 수 있습니다. 저자들은 SourceFilter의 MOS가 더 낮게 나오는 이유로, SourceFilter의 neural vocoder의 자연스러움이 떨어지기 때문이라고 봤습니다.
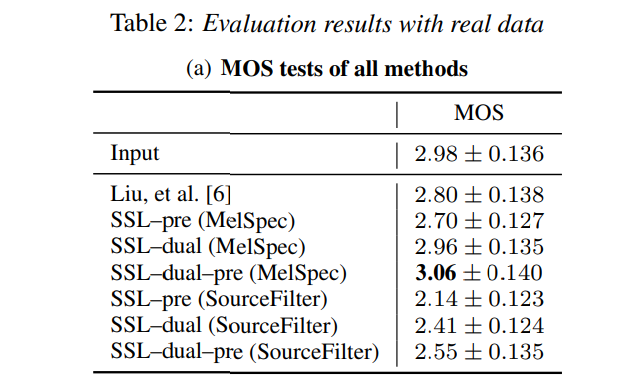
위 실험을 통해, 저자들이 제안한 model에 dual, pre-training을 수행하는 것이 좋은 성능을 보인다는 것을 보였습니다.
Conclusion
저자들은 analysis, synthesis, channel module로 구성되는 self-supervised speech restoration method를 제안합니다. 이는 상당히 뛰어난 quality의 speech restoration을 수행하며, 적은 수의 real data로도 학습이 가능합니다.