[논문] Self-Supervised Learning for Speech Enhancement Through Synthesis
https://arxiv.org/abs/2211.02542
Self-Supervised Learning for Speech Enhancement through Synthesis
Modern speech enhancement (SE) networks typically implement noise suppression through time-frequency masking, latent representation masking, or discriminative signal prediction. In contrast, some recent works explore SE via generative speech synthesis, whe
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
현대 speech enhancement (SE) network는 일반적으로 time-frequency masking, latent representation masking, discriminative signal prediction 등을 통해 noise suppression을 진행합니다. 반면에 몇몇 최신 연구들은 generative speech synthesis를 통해 SE를 진행하기도 하며, system의 output은 neural vocoder를 통해 합성됩니다. 이 논문에서는 denoising vocoder (DeVo) approach를 제안합니다. 이는 vocoder가 noisy representation을 받아 바로 clean speech를 합성하도록 학습됩니다. 저자들은 관련 있는 feature를 발견하기 위해 self-supervised learning (SSL) speech model로부터 rich representation을 추출해 사용합니다. 저자들은 15개의 후보 SSL front-end model을 비교한 뒤, 가장 성능이 좋은 SSL을 이용해 vocoder를 학습시켰습니다. 추가적으로 저자들은 10ms 지연으로 streaming audio를 처리할 수 있는 causal version을 제안했습니다. 성능 저하를 최소화했습니다.
Introduction
SSL representation을 사용하면 mask-based SE 성능이 향상될 수 있지만, 저자들은 바로 audio를 합성하는 데 있어 latent embedding을 사용하는 것이 더 적합하다고 가정하였습니다. deep SSL model은 input을 short-time Fourier transform (STFT) representation과 관련 없는 feature들로 분해하기 때문입니다. 따라서 STFT mask를 계산할 때 SSL feature를 사용하는 것은 SE의 성능을 제한할 수 있습니다.
WaveNet이나 HiFiGAN과 같은 neural vocoder들은 mel-spectrogram과 같은 feature를 가지고 high-quality speech를 잘 합성합니다. 다양한 method들을 통해, model들은 original time-domain signal을 사용하지 않은 채로 자연스럽게 들리는 audio를 생성할 수 있습니다. phase reconstruction이 SE 분야에서 중요한 문제로 자주 언급되며, neural vocoder가 좋은 해결책이 될 수 있습니다. 실제로 여려 연구들은 이러한 방식으로 합성을 진행해 SE를 수행하기도 하였습니다. 하지만 이러한 system들은 resynthesis 이전에 denoising module을 적용하였습니다. 이를 pre-denoising이라 부릅니다. 저자들은 pre-denoising module의 잠재적인 한계들이 존재한다고 생각합니다. cascading module은 error를 유발하기 쉽습니다. 만약 pre-denoiser와 vocoder가 따로따로 학습되었다면, mismatch 문제가 발생할 수도 있습니다. vocoder는 perfect feature를 받을 것으로 기대하지만, prediction model이 불가피하에 mistake를 생성할 수 있고, 결국 speech quality가 크게 저하될 수 있습니다.
동시에 학습하는 것이 error를 줄일 수 있지만, pre-denoising 과정 자체에 loss가 발생합니다. noisy와 speech를 분리하기 위해 pre-denoising 과정에서 speech-noise separation과 speech intelligibility preservation에 도움이 될 수 있는 다른 acoustic cue들을 corrupt 할 수 있습니다. 그리고 pre-denoising module은 복잡성을 향상시킬 수 있습니다. 저자들은 noisy representation에서 바로 speech enhancement를 수행할 수 있을 만큼 neural vocoder가 powerful 하다고 가정합니다.
이 논문에서 저자들은 pre-trained SSL representation model을 SE에 적용하는 것에 대한 연구를 진행합니다. SE에 SSL model을 사용하는 이전 연구들과 다르게, 저자들은 noisy input의 SSL model embedidng으로부터 바로 clean output을 생성함으로써 mask-based subtractive noise suppression을 사용하지 않았습니다. 그리고 저자들은 pre-denoising step을 사용하지 않는 대신 denoising vocoder (DeVo) approach를 사용하였습니다. 먼저 저자들은 large dataset으로 pretrain된 후보 SSL model과 trainable noising vocoder를 사용해 noise-free speech를 합성하는 데 가장 적합한 model을 선택했습니다. 그다음 가장 성능이 좋은 후보로 adversarial training을 진행한 후, performance and generalization에 학습 방식의 영향력을 확인하였습니다. 저자들은 objective perceptual metric 뿐만 아니라 subjective listening study를 통해 성능을 평가했습니다.
Method

저자들은 SSL model을 basis로 사용하여 후보 representation들을 가지고 바로 합성하여 enhancement를 수행하기 적합한지 확인합니다. 저자들은 wav2vec 2.0, WavLM, UniSpeech-SAT, HuBERT, Modified Contrastive Predictive Coding (CPC), BYOL-A를 사용하였습니다. 여러 model들은 Base, Large size로 구성되며, 저자들은 Base-sized model을 사용하였습니다. 대부분의 model들은 convolutional feature encoder와 Transformer layer 또는 LSTM layer로 구성됩니다. 저자들은 full model을 사용하거나 feature encoder만 사용하는 것 중 어떤 것이 더 좋은지 확인합니다. 몇몇 model들은 "+" configuration으로 더 큰 data로 학습된 model입니다. 저자들은 이러한 model들은 나눠서 평가했습니다. log mel-spectrogram (LMS) with frame length 1024, hop length 160, 128 mel bins을 사용해 hand-crafted representation baseline으로 사용하였습니다. 모든 encoder는 16kHz sampled input audio를 사용합니다.
저자들은 high-quality clean speech를 합성할 수 있는 neural vocoder인 HiFiGAN을 이용하였습니다. HiFiGAN architecture는 input representation을 time-domain waveform으로 점진적으로 upsampling 하는 transposed convolution과 다양한 receptive field의 convolution으로 구성됩니다. 필요하다면 저자들은 HiFiGAN resolution에 맞춰 upsampled representation에 nearest neighbor interpolation을 수행하였습니다.
이전 연구들은 transformer를 사용하는 SSL model의 last layer가 항상 가장 유용한 정보를 가지고 있는 것은 아니라는 것을 보였기 때문에, 저자들은 SUPERB처럼 weighted sum approach를 사용하였습니다. 이를 통해 model이 서로 다른 Transformer layer들에서 강조할 부분은 강조하고 강조하지 않을 부분들은 강조하지 않도록 하였습니다. SSL model의 parameter는 fix 하고 feature weight와 vocoder parameter들만 학습 과정에서 최적화되었습니다.
추가적으로, log-mel spectrogram에서 clean speech를 합성하도록 pre-train된 weight로 HiFiGAN을 초기화하였습니다. 다른 feature dimension인 representation을 사용할 수 있도록, HiFiGAN의 첫 layer를 수정하였습니다. 저자들은 pre-trained first layer의 weight를 average 하고, 이를 new input layer의 초기화 value로 사용하였습니다. 저자들은 이 방식이 feature weighting과 학습 안정성에 있어 무시할 수 있을 정도의 작은 영향을 끼친다는 것을 발견했으며, output audio quality가 더 좋아진다는 것을 발견하였습니다. 저자들은 모든 candidate들에 동일한 방식으로 학습을 진행했습니다.
Experimental Setup
Losses
HiFiGAN은 adversarial하게 학습되며, 이러한 학습은 느리고 복잡할 수 있습니다. 그래서 저자들은 non-adversarial criterion을 사용해 학습을 진행했습니다. Phase-Constrained Magnitude Loss (PCM)을 사용하였습니다.

식은 위와 같습니다. $s$는 speech를 의미하고 $n$은 noise를 의미하며, $L_{SM}$은 spectral magnitude loss를 의미합니다. $L_{SM}$은 다음과 같습니다.

위 식에서 $S_r$은 STFT의 실수를 의미하고 $S_i$는 허수를 의미합니다. 저자들은 SFTP의 frame length를 1024, hop length를 160으로 설정하였습니다.
적절한 candidate를 찾기 위해, 저자들은 HiFiGAN의 original loss를 사용하여 candidate들을 학습했습니다. original loss는 adversarial 하기 때문에 generator (G)와 discriminator (D)를 사용합니다.

위 식에서 $L_{Adv}$는 adversarial loss, $L_{FM}$은 feature matching loss, $L_{Mel}(G)$는 log mel-spectrogram loss를 의미합니다. 약간 차이가 있다면, $L_{Mel}(G)$에 L1 noise estimation을 추가합니다.
Metrics
가장 적절한 SSL front-end를 찾기 위해, 저자들은 Perceptual Evaluation of Speech Quality (PESQ)를 사용하여 조사하였습니다. 보통 SE model들이 PESQ를 사용해 평가를 진행합니다. 그리고 저자들은 $\Delta PESQ = PESQ(processed) - PESQ(noisy)$가 model 성능의 차이를 내기 때문에 평가 지표로 사용하였습니다.
저자들의 adversariallay trained model의 평가를 위해, NISQAv2, DNSMOS P.835, Composite objective measure를 metric으로 사용하였습니다. NISQAv2와 DNSMOS P.835는 deep learning-basd non-intrusive perceptual quality predictor입니다. NISQAv2는 single MOS score를 예측하고 DNSMO P.835는 speech quality (SIQ), background noise quality (BAK), overall quality (OVRL)에 대한 score를 측정합니다. Composite scores (CSIG, CBAK, COVRL)는 DNSMOS P.835와 유사하지만 deep learning 대신 regression-based analysis를 사용합니다. 그리고 Short-Time Objective Intelligibility (STOI)를 사용해 SE system의 성능을 평가하였습니다.
소리에 대한 human perception은 subjective 하고 non-linear 하기 때문에, perceptual 평가가 여전히 speech quality를 평가할 때 중요합니다. 그래서, 저자들은 model의 output에 다양한 listening study를 적용하였습니다. 참여자들은 다른 method를 이용해 얻은 audio sample을 듣고 전반적인 audio quality에 대한 점수를 5-point로 평가하였습니다.
Results
Candidate Search

후보 SSL model들에 대한 실험 결과는 위와 같습니다. $\Delta$PESQ score는 convolutional feature encoder만 사용했을 때의 결과가 transformer layer까지 사용했을 때보다 더 좋다고 평가하는 경향을 보여줍니다.

위 그림은 transformer layer를 사용하는 SSL model의 feature weighting에 대한 결과입니다. 저자들은 first layer output이 다른 output보다 더 높은 weight를 받는다는 것을 볼 수 있었습니다. 이러한 결과로 earlier transformer layer가 speech enhancement를 위한 detail 한 acoustic information을 가지고 있다는 것을 알 수 있습니다.
저자들은 학습 과정에서 noise를 경험한 SSL model이 아닌 model보다 확실한 이점을 보이지 않는다는 것을 발견하였습니다. 4가지 경우 중 3가지 경우에서 noise를 경험하지 않은 model이 더 우수한 성능을 보였습니다. 저자들은 모든 후보 model들 중, Modified CPC의 feature encoder를 사용하였습니다. 이 model이 가장 좋은 $\Delta$PESQ를 달성했을 뿐만 아니라 가장 적은 수의 parameter를 사용하기 때문에 사용하였다고 합니다.
Adversarial Training
저자들의 final stage에서 Modified CPC의 feature encoder로 adversarial training을 수행하였습니다. 저자들은 frozen encoder (modified CPC)와 trainable encoder (modified CPC FT)에 대한 실험을 진행했습니다. 저자들은 finetuning encoder의 성능이 더 좋다는 것을 발견했습니다. 그리고 저자들은 model의 모든 연산을 causal 하게 만들어 real-time 환경에서 동작할 수 있는지에 대한 가능성을 평가하였습니다 (modified CPC FT-S). causal model은 전체 10ms latency를 보여줍니다.
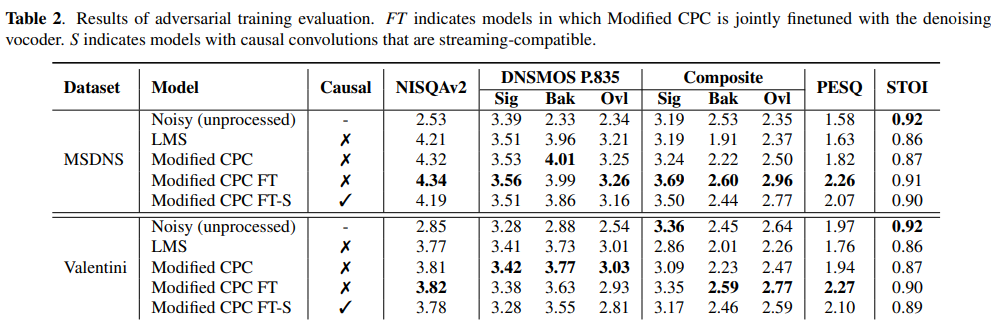
결과는 위와 같습니다. MSDNS test set과 Valentini test set으로 평가를 진행했습니다. fine-tuned model이 두 dataset 모두에서 더 뛰어난 결과를 보여주는 것을 알 수 있습니다.
Conclusion
이 논문에서 저자들은 pre-denoising speech or speech feature 없이도 rich input feature를 가지고 speech enhancement를 수행할 수 있을 정도로 powerful한 neural vocoding을 제안합니다. 저자들은 여러 SSL model을 사용하여 어떤 input feature가 적절한 지 확인하였습니다. 그리고 약간의 degradation으로도 synthesis-based model이 causal configuration으로 동작할 수 있음을 확인하였습니다. 저자들의 결과를 통해 denoising vocoder는 speech enhancement에 적절하다는 것을 알 수 있었으며, SSL의 초기 layer를 이용한다면 더 나은 합성 task를 수행할 수 있음을 알아냈습니다.