[논문] Identity Conversion for Emotional Speakers: A Study for Disentanglement of Emotion Style and Speaker Identity
해당 논문을 보고 작성했습니다.
Abstract
expressive voice conversion은 speaker identity와 speaker-dependent emotion style을 동시에 변환합니다. speech emotion의 계층적 구조 때문에, speaker-dependent emotional style을 분리하는 것은 어렵습니다. variational autoencoder (VAE)를 이용한 speaker disentanglement의 성공에서 동기를 얻어, 저자들은 linguistic content, speaker identity, pitch, emotional style information을 분리할 수 있는 expressive voice conversion framework를 제안합니다. 저자들은 emotional style을 명시적으로 modeling 하기 위해 emotion encoder를 사용하고 mutual information (MI) loss를 사용해 분리된 emotion representation에서 관련 없는 정보를 reduce 하였습니다. run-time에서 저자들의 framework는 parallel data 없이도 speaker identity와 speaker-dependent emotion style을 변환합니다.
Introduction
traditional voice conversion은 parallel training data가 필요합니다. non-parallel training이 가능하기 위해 CycleGAN, StarGAN과 같은 domain translation model이 제안되었습니다. 이 model들은 cycle-consistency mechanism에 의존하며 strict pixel-level constraint를 사용합니다. 결과적으로 source speech style이 유지된 converted voice가 생성되며, 이는 expressive voice conversion에 적합하지 않습니다.
또 다른 non-parallel VC는 VAE을 이용하여 disentangled speech representation을 학습합니다. VAE는 speaker identity conversion 또는 emotion conversion을 수행할 수 있도록 분리된 feature들을 따로따로 조작할 수 있도록 도와줍니다. better disentangled representation을 얻기 위한 다른 technique으로 information bottleneck, instasnce normalization, vector quantization이 있습니다. 그중 vector quantization and mutual information based voice conversion (VQMIVC)의 경우, 서로 다른 representation 사이의 의존성을 줄이는 데 있어 mutual information (MI)가 효과적임을 보였으며 이 연구는 해당 결과에서 영감을 받았습니다.
emotional voice conversion은 speaker identity는 유지한 채로 speaker의 emotional state만 변경하는 것을 목표로 합니다. 하지만, 각 화자마다 unique 한 방식으로 emotion을 표현합니다. 즉 utterance의 emotional style은 speaker-dependent 합니다. emotional voice converison과 다르게 expressive voice conversion은 speaker identity와 speaker dependent emotional speech style을 동시에 변환하는 것을 목표로 합니다. speaker-dependent emotional style은 speech content, speaker identity, speaking style, pitch와 같은 다양한 speech element와 상호작용하며, expressive voice conversion을 위해선 이 element들을 분리하는 것이 중요합니다. 이러한 disentanglement는 content는 유지하지만, target speaker의 identity와 speaker-dependent speaking style을 이용해 음성을 합성할 수 있게 만들어 줍니다.
저자들의 main contribution은 다음과 같습니다. 1) expressive voice conversion을 수행하기 위해, speaker identity와 speaker-dependent emotion style을 분리하는 연구를 진행하였습니다. 2) 저자들은 style encoder를 도입하여 명시적으로 speaker마다 다른 emotional speech style을 modeling 합니다. 나아가 speaker embedding과 emotion style embedding 사이 MI loss를 적용하여 speaker-dependent feature들 간의 상호 의존성을 줄였습니다. 3) 화자마다 다른 pitch variation을 고려하여, 저자들은 pitch information을 frame-level condition으로 활용하여 더 나은 disentanglement를 달성하였습니다. 4) 저자들이 제안한 framework는 run-time 할 때도, multi-speaker emotional speech data에 대해서 speaker identity와 speaker-dependent emotional style을 효과적으로 변환할 수 있습니다.
Proposed Framework

저자들이 제안하는 expressive voice conversion framework는 speaker encoder, style encoder, content encoder, decoder로 구성됩니다. 학습할 때, speaker identity, emotional style, content and pitch information을 분리하는 것을 효과적으로 학습합니다. run-time에서는 disentangled speech representation을 조작함으로써 speaker identity와 emotional style 둘 다 변환할 수 있습니다.
Training Phase
utterance가 주어졌을 때, 먼저 mel-spectrogram $X = \{x_1, ... , x_T\}$을 추출하고 T frame에서 fundamental frequency $F_0$를 추출합니다. style encoder $E^s$는 Mel-spectrogram을 fixed representation $Z^s = E^s(X)$으로 encode 하는 것을 학습합니다. $Z^s$는 utterance level의 emotional style을 나타냅니다. content encoder $E^c$는 X에서 $Z^c = \{z_1^c, ... , z_{T/2}^c \}$을 추출합니다. speaker encoder $E^p$는 Mel-spectrogram을 고정된 길이의 speaker embedding $Z^p = E^p(X)$로 embed 하는 것을 학습합니다. 억양을 표현하기 위해, speech waveform에서 $F_0$를 추출하고 zero mean and unit variance로 log normalize 합니다. 화자마다 $F_0$가 다르기 때문에, normalized $F_0$를 pitch embedding $Z^f$로 사용하며, 따로 학습합니다.
speaker embedding $Z^p$은 speaker identity를 나타내고 emotional style embedding $Z^s$는 utterance level의 emotional style information을 나타냅니다. pitch embedding $Z^f$와 align 하기 위해, 저자들은 speaker embedding, emotional style embedding, content embedding을 T frame까지 upsample 하였습니다. decoder D는 pitch embedding과 upsampled speech embedding을 가지고 acoustic feature $\hat{X}$을 reconstruct 하는 것을 목표로 합니다. reconstruction loss는 reconstructed Mel-spectrogram과 ground-truth를 가지고 계산됩니다.
더 나은 disentanglement를 수행하기 위해, 저자들은 mutual information minimization을 학습 과정에서 도입하였습니다. different speech representation 사이 correlation은 MI loss를 minimize 하여 감소될 수 있습니다.

위 식에서 $\hat{I}$는 unbiased estimation vCLUB을 나타냅니다. 위 식의 λ들은 different speech representation 사이 trade-off factor를 나타냅니다.
저자들이 제안한 framework는 학습과정에서 content, pitch, speaker identity, emotional style을 분리하는 것을 효과적으로 학습합니다. MI loss를 통해 framework가 서로 다른 speech representation 사이 공유되는 mutual information을 줄이도록 학습됩니다.
Run-time Conversion
run-time에서, content encoder는 source utterance에서 source content embedding을 생성합니다. target speaker의 emotional reference utterance가 주어지면, speaker encoder를 사용해 speaker embedding을 생성하고 style encoder를 사용해 emotional style embedding을 생성합니다. 저자들은 emotional style embedding은 target speaker과 관련된 speaker-dependent emotional style을 capture 할 수 있다고 생각합니다. 그다음 저자들은 validation set에 존재하는 target speaker의 F0 평균과 표준편차로 F0를 변환합니다. decoder는 source content embedding, reference에서 추출한 speaker embedding, emotional style embedding, converted F0를 이용해 converted Mel-spectrogram을 생성합니다. Parallel WaveGAN을 이용해 speech waveform을 reconstruct 합니다.
Discussion

저자들이 제안한 framework가 representation learning에 있어 얼마나 효과적인지 입증하기 위해, 저자들은 T-SNE로 generated speaker embedding을 visualize 하였으며 결과는 위와 같습니다. 각 emotion마다 각 화자들이 잘 분리된 cluster를 형성하는 것을 볼 수 있습니다. 이는 저자들이 제안한 framework가 speaker embedding을 잘 생성할 수 있으며 expressive voice conversion에 있어 중요한 역할을 한다는 것을 보여줍니다.
Experiments
저자들은 objective and subjective evaluation을 진행해 speaker identity, emotional style conversion에 대한 평가를 진행하였습니다. ESD라는 multi-speaker emotional speech database을 이용하였으며, 여기에는 neutral, happy, sad, angry, surprise라는 5가지 감정이 존재합니다. 저자들은 8명 화자(남성 4, 여성 4)를 선택하여 실험을 진행하였습니다. 각 화자나 각 감정에 대해, 300개의 utterance는 학습 때 사용하고 30개는 validation으로 사용하고 20개는 evaluation으로 사용하였습니다. VQMIVC를 baseline으로 사용하였습니다.
Objective Evaluation
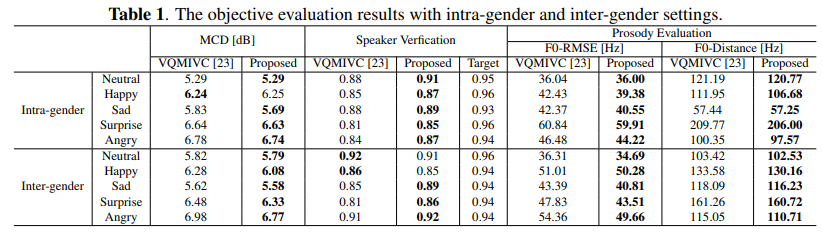
Mel-cepstral distortion (MCD)를 이용해 spectral distortion을 평가하였으며, 결과는 위와 같습니다. 저자들의 method가 baseline보다 일관성 있게 좋은 모습을 보여주고 있습니다.
F0-RMSE와 F0-Distance를 이용해 prosody conversion performance도 측정하였습니다. 저자들이 제안한 framework가 항상 더 나은 성능을 보여줍니다. 그리고 저자들은 pre-trained speaker verification model을 이용해 speaker verification experiment도 진행하였습니다. 저자들의 model이 baseline보다 뛰어난 모습을 보여줍니다. 이를 통해 speaker identity conversion에 있어 좋은 성능을 보인다는 것을 알 수 있습니다.
Subjective Evaluation
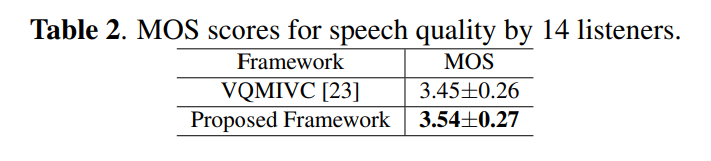
speech quality, speaker-similarity, emotional style similarity에 대한 실험을 진행하였습니다. MOS 결과는 위와 같습니다.
저자들의 method가 높은 점수를 달성하는 것을 볼 수 있습니다.
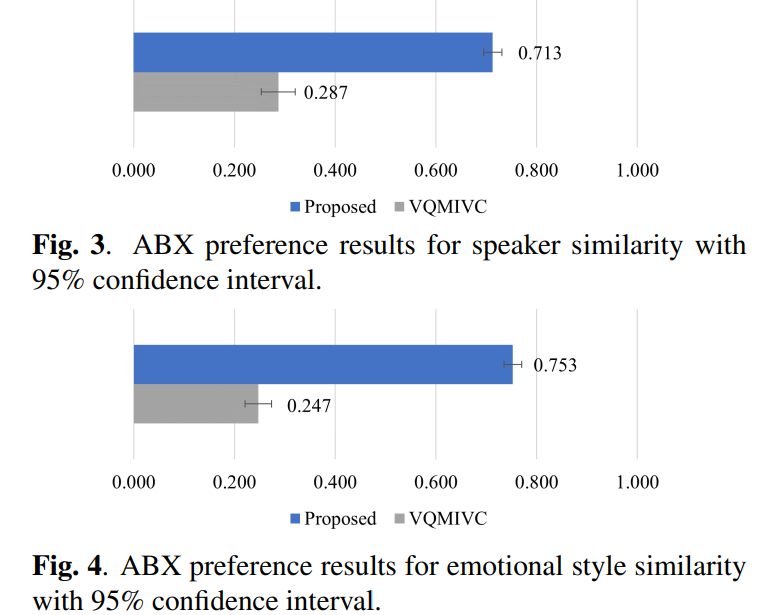
ABX 실험 결과는 위와 같습니다.
Conclusion
이 논문에서, 저자들은 expressive voice conversion을 수행하기 위해 speaker identity, emotional speech style을 분리하는 것에 대한 연구를 진행했습니다. 저자들은 speaker identity와 speaker-dependent emotional style을 동시에 변환하는 VQMIVC 기반 framework를 제안합니다. 저자들은 style encoder를 이용해 emotional style을 명시적으로 modeling 하고 MI loss를 이용해 서로 다른 speech representation 사이 공유되는 정보를 제거하였습니다.