https://arxiv.org/abs/2208.09266
Diverse Video Captioning by Adaptive Spatio-temporal Attention
To generate proper captions for videos, the inference needs to identify relevant concepts and pay attention to the spatial relationships between them as well as to the temporal development in the clip. Our end-to-end encoder-decoder video captioning framew
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
video에 맞는 적절한 caption을 생성하기 위해, inference 할 때 관련 concept을 알아야 하고 clip의 spatial relationship 뿐만 아니라 temporal development도 신경 써야 합니다. 저자들의 end-to-end encoder-decoder video captioning framework는 두 가지 transformer 기반 구조를 통합합니다. 하나는 단일 joint spatio-temporal video 분석을 위한 transformer이고, 다른 하나는 향상된 text generation을 위한 self-attention 기반 decoder입니다. 그리고 저자들은 두 transformer를 훈련할 때 필요한 input frame 수를 줄이면서도 관련 content를 유지하기 위한 adaptive frame selection 방식을 제안합니다. 추가적으로 저자들은 모든 sample의 ground truth caption을 모아 video captioning에 관련된 semantic concept을 추정합니다. 저자들의 방식은 MSVD 뿐만 아니라 대규모 MRS-VTT 및 VATEX benchmark dataset에서 가장 좋은 성능을 달성했습니다.
Introduction
시각적 정보와 텍스트 정보 사이 상호 작용은 최근 computer vision 분야에서 많은 관심을 받고 있습니다. 짧은 video에 대한 caption을 생성하는 것은 대부분의 사람들에게 간단한 task이지만 기계에게는 쉽지 않습니다. 특히 video captioning은 기계 번역과 유사한 sequence-to-sequence task로 볼 수 있습니다. video captioning framework는 video에 대한 high-level 이해를 학습하고 text로 변환하는 것을 목표로 합니다.
일반적으로 video description generation의 경우, visual content를 분석하는 encoder와 text를 생성하는 decoder로 구성됩니다. 여기서 사용되는 network는 주로 다양한 형태의 2D-CNN과 3D-CNN을 사용합니다. 연속적인 frame 사이 visual feature와 local motion information을 추출합니다. 또한 세밀한 spatial information을 얻기 위해 Faster RCNN object recognition (FCRNN)을 사용할 수도 있습니다.
model이 local and global temporal and spatio-temporal information을 build하도록 만들기 위해 Attention mechanism을 사용합니다. 하지만 temporal processing은 어느 정도 제한이 있으며, 이는 시간 해상도가 없는 global aggregation이나 짧은 temporal footprint를 사용하는 3D-CNN을 사용합니다. 하지만 Transformer 기반 encoder-decoder 구조는 위치에 상관없이 sequence 내 모든 구성 요소 간의 관계를 구축할 수 있습니다.
이 논문에서 VASTA라는 end-to-end encoder-decoder framework를 제안합니다. 이는 input에 대해 detail하게 spatio-temporal 분석을 수행할 뿐만 아니라 caption output을 생성하는 transformer를 사용하여 video captioning을 수행합니다.
저자들의 encoder 구조로 Video Swin Transformer를 사용합니다. 이는 video-based action recognition을 수행할 때 non-local temporal dependency를 해석할 수 있습니다. 하지만 video captioning task는 spatio-temporal analysis 보다 더 많은 것을 필요로 합니다. 의미적으로 관련 있는 모든 concept을 추출해야 합니다.
두 transformer를 end-to-end training을 하기 때문에, 저자들은 caption 생성을 위한 keyframe을 식별하는 adaptive frame sampling (AFS)를 제안합니다. 그리고 저자들의 transformer based encoder-decoder 구조는 visual 분석뿐만 하니라 language 생성에서도 효과적입니다. 저자들의 contribution은 다음과 같습니다.
- 간단한 transformer 기반 video captioning 방식을 제안합니다. 이는 single encoder를 활용하여 필수적인 spatio-temporal information을 추출합니다. 다른 연구들과 다르게, 저자들은 disjoint 2D analysis & 3D analysis를 사용하지 않습니다.
- 더 정보가 많은 frame을 선택할 수 있는 adaptive frame sampling을 제안합니다.
- 각 sample의 모든 caption에서 얻어진 visually grounded semantic context vector는 high-quality semantic guidance를 decoder에게 제공합니다.
- MSVD, MSR-VTT, VATEX라는 3가지 dataset에서 가장 좋은 성능을 보였습니다.
- 예측되는 caption의 다양성이 크게 증가되었습니다.
Model Architecture
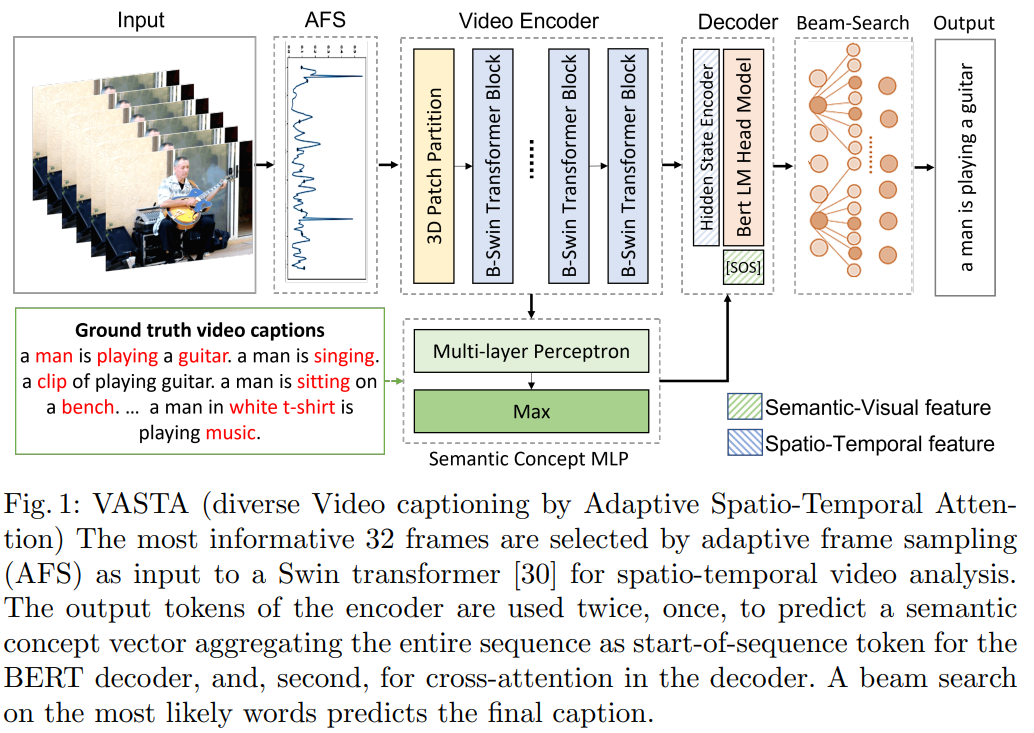
VASTA model의 구조는 위와 같이 encoder-decoder transformer 기반입니다. 전체 video length에서 informative frame을 찾기 위해 adaptive selection method를 사용합니다. 그 다음 model은 선택된 video frame을 encode 합니다. 저자들은 action recognition과 classification task에서 사용하려고 설계된 Swin Transformer block을 사용하여 input video를 interpret 합니다. encoder의 last hidden layer는 decoder로 전달됩니다. encoder의 output이 압축되었음에도 불구하고 temporal sequence는 포함한 상태입니다. 그렇기 때문에 BERT decoder가 cross-attention method를 사용할 수 있게 됩니다. encoder-decoder의 direct 한 connection 이외에도, encoder output을 globally aggregated semantic context vector를 예측하는 데 사용할 수 있습니다. 그리고 이 context vector를 language generator의 condition으로 사용합니다.
Adaptive Frame Selection
video에서 모든 frame이 마지막 caption에 동일한 정보를 기여하는 것은 아닙니다. 몇몇 frame들은 이전 frame과 상당히 유사할 수도 있지만, 다른 frame들은 dynamic하거나 새로운 object를 보여주기도 합니다. 대부분의 video captioning 방식들은 frame을 고정된 균일 간격으로 선택합니다.
저자들의 adaptive frame selection (AFS)는 local frame similarity를 기반으로 input frame에서 importance sampling을 수행합니다. 먼저, 연속된 두 frame의 pair에 대한 유사도를 LPIPS score로 계산합니다. LPIPS는 이미지 유사도 평가에서 많이 사용되고 있는 이미지 간의 시각적 유사도를 측정하는 지표입니다.

위 그래프에서 나타나는 것과 같이, 저자들은 유사도를 probability density function (PDF) f로 간주하고 모든 frame에 대해 normalize합니다. 그다음 cumulative density function (CDF) F의 역을 계산합니다.

위 식을 통해 구한 값들을 반올림하여 frame i를 선택합니다. 즉, 유사도가 낮은 구간(새로운 정보가 많이 포함될 가능성이 높은 frame pair)을 선택할 확률이 높고, 이렇게 구한 sequence를 encoder의 3D patch partition에 input으로 사용합니다.
Encoder
Swin 구조는 계층적 transformer로 computer vision task에서 일반적인 backbone입니다. 시각적 input을 먼저 non-overlapping patch로 분할되고, 그다음 self-attention step에서 window를 patch 크기의 절반만큼 shifting하여 discrete partitioning에서 발생할 수 있는 artifact를 피합니다. 따라서 swin video transformer는 shift 된 3D partition에서 연산을 수행하여 spatial and temporal domain 모두 cover 합니다. encoder bockbone은 Swin-B variant이며, last hidden layer size를 (BS x 16 x 1024)로 설정하여 사용했습니다.
Semantic Concept Network
저자들의 pipeline의 두번째 step은 전체 video의 semantic concept vector를 예측하는 것을 포함하며, 이 semantic concept vector를 decoder의 token sequence의 첫 부분으로 사용하여 생성의 condition으로 사용됩니다. 이 concept vector에 대한 training signal은 video의 모든 ground truth caption을 aggregate 하여 caption 생성을 위한 고품질의 signal을 제공합니다. concept은 dataset에 존재하는 모든 caption들 중 가장 자주 등장하는 K개 단어로 정의됩니다. video의 semantic concept vector를 예측하는 것은 video를 설명하는 데 관련 있는 자주 등장하는 단어들에 대한 binary multi-class classification task로 학습됩니다. ground truth classification vector를 생성하기 위해, 저자들은 먼저 학습 video에 있는 모든 caption의 명사, 동사, 부사를 선택합니다. 각 video를 K 차원 vector L로 labeling 합니다.

위와 같이 정의합니다. MLP는 encoder output의 각 항목에 대해 shared weight로 별도로 동작합니다. single max-pooling layer가 하나의 token으로 병합시켜 줍니다. 그 다음 2개 MLP with ReLU layer가 K개 concept을 예측합니다. binary cross-entropy loss를 minimize 하면서 학습됩니다. 본질적으로, concept dictionary에 있는 각 단어들의 확률은 semantic feature로 사용됩니다. semantic concept vector를 도입함으로써 각 video에 대해 aggregated constant signal을 제공하는 동시에, decoder는 각 caption을 생성함으로써 학습됩니다.
Decoder
저자들의 decoder는 이미 생성된 token들을 기반으로 self-attention을 사용하여 단어 단위로 language output을 생성합니다. 학습 과정에서 masking을 하는 것은 BERT가 future token에 접근하지 못하도록 만들어줍니다.
저자들의 구조에서 semantic feature vector를 token sequence의 시작으로 사용하여 decoder가 첫번째 output word를 생성합니다. first input token에 대한 self-attention을 통해 예측된 caption은 semantic MLP에 의해 식별된 semantic concept에 조건화됩니다. decoder의 hidden state과 encoder의 output을 연결하기 위해, cross-modal fusion은 필수적입니다. decoder를 multi-head cross-attention으로 확장함으로써 구현됩니다. 13개의 layer에서 이 구조는 language token에 대한 multi-head self-attention, language token과 Swin output token에 대한 cross-attention, feed-forward layer와 normalization를 번갈아 수행합니다. 그리고 각 step은 residual connection으로 연결됩니다. 마지막 linear layer는 decoder의 hidden state를 BERT vocabulary의 크기로 project 하고, 각 token에 대한 단어의 확률들을 구하기 위해 softmax를 수행합니다. sentence는 beam search를 수행하여 생성되고, 이를 통해 가장 좋은 word combination을 얻습니다.
Conclusion
저자들은 video captioning encoder-decoder approach인 VASTA를 제안합니다. 이는 처리된 visual token을 multi-layer multi-head cross attention을 사용하여 통합합니다. Swin token이 분리된 spatio-temporal information을 추출하지만, 저자들은 globally aggregating semantic concept vector를 BERT module이 setence를 생성할 때 초기화로 사용합니다. content-based adaptive frame selection sampling을 제안함으로써, 저자들은 가장 정보가 많은 frame을 선택하여 학습의 효율성을 높일 수 있도록 만들었습니다.



