https://www.jmir.org/2023/1/e46216
Prediction of Sleep Stages Via Deep Learning Using Smartphone Audio Recordings in Home Environments: Model Development and Valid
Introduction Growing knowledge that sleep plays a vital role in maintaining well-being and good health, both physical and mental, increases public interest and awareness regarding the importance of sleep to health. Therefore, the demand for knowing and tak
www.jmir.org
해당 논문을 보고 작성했습니다.
Abstract
수면의 중요성에 대한 대중의 관심과 인식이 증가함에 따라 가정 내에서의 수면 모니터링 수요가 높아지고 있습니다. 그리고 다양한 상용 weaerable 및 근거리 장치 외에도, deep learing을 이용한 sound-based 수면 단계 측정이 편리함과 정확도로 주목받고 있습니다. 하지만 sound-based sleep staging은 in-laboratory sound data만 사용하여 연구되며, real-world sleep environments (home)의 경우엔 background noise가 풍부합니다. 가정에서 sound-based sleep staging을 사용하는 것은 실용성을 위해 필수적이지만, 이에 대한 연구는 아직 이루어지지 않았습니다. 충분한 양의 home data를 확보하는 데 드는 비용이 높아 데이터를 확보하기 어려우며, 이를 통한 대규모 신경망 학습이 어렵다는 점이 문제로 남아 있습니다.
이 논문에서는 다양한 uncontrolled home environment에서 녹음된 audio를 사용하여 sound-based sleep staging을 수행하는 deep learning method를 제안합니다. home data가 부족하다는 한계를 극복하기 위해, 저자들은 향상된 학습 technique을 사용하고 home data와 hospital data를 결합합니다. model을 학습하는 것은 3가지 요소로 구성됩니다. 1) 병원에서 수집한 다채널 수면 다원 검사 (PSG)와 audio recording 812쌍을 사용한 기존의 supervised learning; 2) 가정에서 스마트폰으로 녹음한 829개 audio를 추가하여 hospital에서 home으로의 전이 학습; 3) hospital sound data를 augmentation 하여 일관성을 학습하는 것으로 이루어집니다. augmented data는 8225개 home noise data를 hospital audio recording에 추가하는 방식으로 생성되었습니다.
Introduction
수면이 건강을 유지하는 데 중요한 역할을 한다는 사실이 알려지고 나서 많은 대중들이 잠의 중요성을 중요하게 여기기 시작했습니다. 이에 따라 개인의 수면 상태를 알고 관리하려는 수요가 증가되었으며, 그에 따라 수면 모니터링에 대한 수요가 증가되고 있스빈다. 수면을 모니터링하고 정량화하기 위한 가장 표준적인 검사 방법은 polysomnography (PSG, 다채널 수면 다원 검사)로, 일반적으로 수면 센터에서 다양한 생체 신호를 기록하는 1박의 수면을 필요로 합니다. 생체 신호에는 뇌파(EEG), 안구 운동을 기록하는 전안근 활동(EOG), 근육 활동을 기록하는 근전도(EMG), 심박동 활동을 기록하는 심전도(ECG) 그리고 호흡 신호가 포함됩니다. 측정 이후, 수면 데이터는 전문가가 수면 단계, 각성(짧은 각성), 호흡 및 움직임을 평가합니다. PSG는 여전히 가장 정확한 수면 진단 도구이지만, 일반적으로 매일 사용하기엔 비용이 너무 비싸고 불편합니다. 그리고 PSG는 개인이 집에서 수면을 취할 때 나타나는 습관을 반영하지 못합니다.
다양한 상업적 수면 추적기가 있으며(i.e., wearable or nearable device), 대부분은 가속도계를 사용하여 활동과 움직임을 측정하고 심전도나 광혈류측정기를 사용하여 심박동 변동성을 측정하고, 압전 효과 또는 레이더를 사용하여 호흡을 측정하며, EEG를 사용하여 뇌 활동을 측정합니다. 하지만 이러한 방식들은 불편하고 비용이 많이 들기 때문에, 사람들이 적극적으로 사용하지 않습니다. 최근에는 호흡과 신체 움직임의 소리 패턴을 인식하여 소리 기반 수면 단계를 측정하는 방식이 새로운 대안으로 등장하였습니다.
하지만 등장했던 sound-based sleep staging model들은 병원과 같은 환경에서 학습되고 실험되었으며, 병원과 같이 통제된 환경이 아닌 가정환경에서는 동작할 지에 대한 의문점이 존재합니다. 그래서 가정 환경에서도 동작할 수 있는 모델을 도출하기 위한 학습이 필요합니다. 하지만 deep learning model은 수천 개의 ground-trith를 필요로 하며, 이를 얻는 것이 어렵습니다. 그래서 대규모 home PSG data를 얻는 것을 우회하는 데 도움을 줄 수 있는 향상된 기술을 도입합니다. 유용할 수 있는 한 가지 기법은 transfer learning입니다. 이는 hospital sound를 가지고 sleep stage를 예측하도록 학습된 model이 home sound에서도 동작하도록 만들어 줍니다. 또 다른 유용한 기술은 consistency training입니다. 이는 hospital sound에 home noise를 추가하여 model을 학습시키는 데 사용하는 방식입니다. 이는 model이 home noise에 상관없이 수면 단계를 예측하도록 학습할 수 있게 만들어줍니다.
이 논문에서 저자들은 가정에서의 sound-based sleep staging을 위한 advanced training technique을 사용하는 deep learning model을 제안합니다.
Methods
Sleep Sound Datasets
- Overview of the Datasets
이 연구에서는 3가지 dataset을 사용합니다: 학습에서 사용될 hospital PSG dataset (level 1 PSG and audio recording for 812 nights)와 home smartphone dataset (smartphone audio recording without PSG for 829 night) 그리고 실험에서 사용될 home PSG dataset (level 2 PSG and matched smartphone audio recordings for 45 nights) 입니다. 여기서 level 1은 병원에서 측정한 PSG dataset을 의미하고, level 2은 가정에서 측정한 PSG dataset을 의미합니다.
- Hospital PSG Datasets
서울대학교 분당병원 수면 센터에서 2019, 2020년동안 PSG와 그에 일치하는 audio data를 수집하였습니다.
- Home Smarthphone Datasets
성인 참가자들을 채용하여 audio recording을 수집하였습니다. 참가자들은 가정에서 스마트폰을 이용해 야간 오디오 녹음을 자체적으로 수행했습니다. Android (version 8.0 이상)와 IOS (version 15 이상)을 포함한 다양한 smartphone model들이 사용되었습니다. 참가자들은 핸드폰을 머리에서 0.5~1m 떨어진 곳에 놔두고 참여했습니다.
- Home PSG Datasets
성인 참가자들을 채용하여 home PSG test를 수행했습니다. 휴대용 PSG 장비를 가지고 측정했습니다.
- Polysomnography (PSG)
PSG는 6-channel EEG, 2-channel EOG, chin EMG, ECG, 2-leg EMGs, respiratory effort, airflow, oxygen saturation을 측정합니다. Level 1 PSG는 병원에서 수행되며, level 2 PSG는 home PSG입니다.
Deep Neural Network Architecture
- Training Overview
이 논문에서 제안한 학습 기법의 효과를 공정하게 입증하기 위해, 저자들은 SoundSleepNet model을 사용했습니다. network는 sound data의 40 input Mel spectrogram (각각 30초 sleep epoch)을 input으로 처리하고, 중앙의 20개 epoch에 대한 sleep stage를 예측하여 출력합니다. 잘 학습된 model을 사용함으로써 network architecture가 아닌 추가적인 학습 기법에 의해서만 성능 차이가 발생함을 보장할 수 있습니다.

- Training Components
제안된 model인 HomeSleepNet은 3가지 학습 구성 요소로 학습되었습니다. 위 그림의 A와 같습니다. 첫 component는 supervised learning입니다. 대규모 hospital PSG dataset을 사용하여 HomeSleepNet model을 학습시켜 hospital environment input Mel spectrogram의 sleep stage를 정확하게 예측하도록 만듭니다.
두 번째 component는 transfer learning입니다. hospital 뿐만 아니라 home Mel spectrogram도 사용합니다. domain discriminator를 사용하여 feature extractor를 hospital domain sleep staging knowledge를 home domain sleep staging으로 transfer 합니다.
세 번째 component는 2가지 augmented hospital sound input을 사용하는 consistency training입니다. consistency training은 HomeSleepNet model이 가정 소음이 있는 환경에서도 신뢰성 있게 sleep staging을 수행할 수 있도록 만들어줍니다.
세 가지 학습 요소는 각 구성 요소의 효과를 유지하기 위해 동시에 실행됩니다.
- Supervised Learning for Sleep Staging in Hospital Environments
HomeSleepNet의 supervised learning의 목적은 preprocessed Mel spectrogram과 hospital PSG로 얻은 sleep-stage ground-truth를 가지고 network가 hospital environment input Mel-spectrogram data를 사용해 sleep stage를 예측하도록 만드는 것입니다.
supervised learning component는 2가지 subnetwork를 학습하는 데 사용됩니다: feature extractor와 classifier입니다. feature extractor는 hospital sound data의 Mel-spectrogram을 input으로 사용하여 호흡 pattern과 수면 활동 pattern에 관련 있는 temporal and frequency feature를 추출합니다. classifier는 feature를 받아 각 Mel spectrogram의 sleep stage를 예측합니다. 결과적으로, 저자들은 sleep stage ground-truth와 network prediction 사이 차이를 측정하는 cross-entropy loss를 minimize 하는 방식으로 feature extractor와 classifier를 학습합니다.
- Transfer Learning via Unsupervised Domain Adaptation
HomeSleepNet의 Transfer Learning은 unsupervised domain adpatation (UDA)을 통해 수행됩니다. UDA의 목표는 원래 source domain (hospital environment)으로 학습된 model이 target domain (home environment)에서도 비슷하게 동작하도록 만드는 것입니다. UDA의 일반적인 방법 중 하나로 source domain과 target domain에서 추출한 data 사이에 common feature (i.e., domain-invariant features)를 추출하여 model이 input data의 domain의 상관 없이 잘 동작하도록 만드는 것입니다.
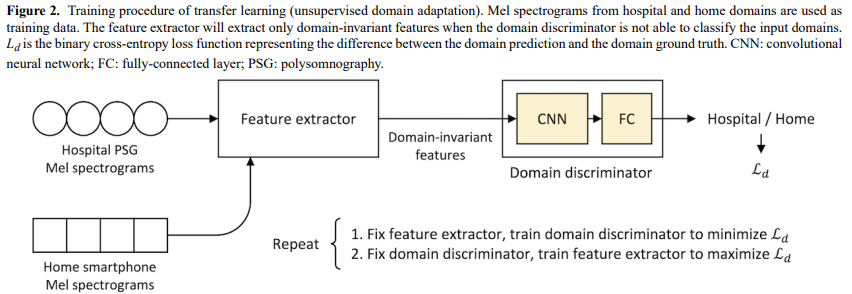
저자들은 위 그림과 같은 simple convolution layer와 여러 fully connected ayer로 구성된 domain discriminator를 추가했습니다. feature extractor는 input Mel spectrogram으로부터 feature를 생성하고 domain discriminator는 feature의 original domain (hospital domain or home domain)을 예측합니다. Hospital PSG sound data와 home smartphone sound data가 input으로 사용됩니다. 하지만 학습할 때는 sleep-stage label을 필요로 하지 않고 각 input data의 domain ground-truth만 있으면 됩니다. domain prediction과 domain ground-truth 사이 차이를 나타내는 binary cross-entropy lsos를 사용하여 두 subnetwork를 학습시킵니다. 저자들은 adversarial training algorithm을 사용했으며, 여기에서 domain discriminator는 더 정확해지도록(binary cross-entropy loss를 minimize) 학습되고 feature extractor는 domain discriminator가 덜 정확해지도록 (binary cross-entropy loss를 maximize) 학습됩니다. feature extractor는 domain discriminator를 혼란스럽게 만드는 feature를 추출하도록 학습됩니다. 결과적으로 domain discriminator가 추출된 feature로부터 input domain을 더 이상 인지하지 못하게 되며, 추출된 feature는 domain invariant feature가 됩니다. 따라서 well-trained classifier가 original domain의 상관없이 sleep stage를 정확하게 예측할 수 있습니다.
adversarial training 외에도, domain adaptation 이후 분류 성능을 유지하기 위해 conditional entropy와 virtual adversarial training으로 구성된 auxiliary loss를 사용합니다.
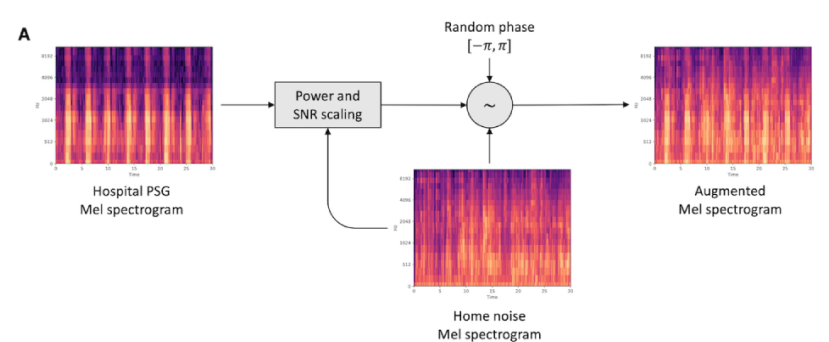
- Consistency Training Using Augmented Data
이 논문에서 저자들은 consistency training을 통해 model이 home noise가 있든 없든 hospital data에 대한 일관성 있는 예측을 output하도록 model을 학습시킵니다. original hospital data에 인공적으로 home noise를 추가함으로써 Data augmentation을 수행했습니다. feature extractor와 classifier를 consistency training을 통해 original data와 동일한 sleep stage를 예측하도록 학습시킵니다.
detail 하게, augmented data를 만들기 위해, home noise audio를 Mel spectrogram으로 변환한 후 hospital data의 Mel spectrogram에 더합니다. 이때 random 하게 phase를 생성하고 -10dB에서 10dB 범위의 signal-to-noise ratio value를 적용하여 hospital data의 Mel-spectrogram에 추가했습니다. 위 그림과 같습니다. 총 8,255개 sound clip을 사용하였습니다.
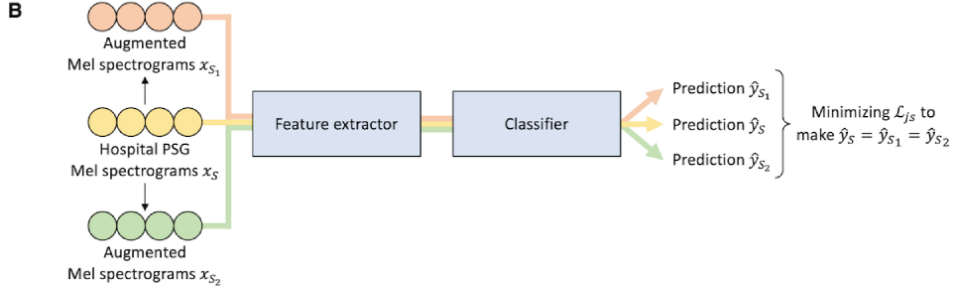
consistency training의 경우, 저자들은 original hospital data x_s에 2가지 다른 home noise data를 사용하는 noise adding process를 통해 2개 augmented noisy sample을 생성합니다. hospital data x_s와 2가지 augmented sample을 feature extractor와 classifier에 feed 하여 3가지 prediction을 얻습니다. 그다음 3가지 예측 사이 차이를 측정하는 Jensen-Shannon divergence loss을 통해 consistency loss를 구합니다. 이 consistency loss를 minimize 함으로써, 최종 model은 home noise가 있더라도 robust 하고 일관된 예측을 생성할 수 있게 됩니다.
- Evaluation Methods
HomeSleepNet을 4가지 방식으로 home PSG dataset에 대해 평가했습니다.
먼저, main outcome은 3-stage classification (wake, REM and NREM)에 대한 sleep staging 성능입니다. 정확도, Cohen k, macro F_1-score, mean per-class sensitivity를 사용하여 측정했습니다. 또한 4-stage (wake, light sleep, deep sleep and REM)과 2-stage (wake and sleep) classification 또한 수행했습니다. 4-stage에서 N1과 N2는 light sleep으로 분류하고 N3는 deep sleep으로 분류했습니다. HomeSleepNet의 마지막 hidden layer의 output에 PCA를 적용하여 2D format으로 각 input data의 most representative feature를 표현했습니다. 이 평면에서 sleep stage cluster가 나타나면 HomeSleepNet의 예측이 신뢰할 수 있음을 의미합니다.
둘째, HomeSleepNet의 예측과 PSG의 annotation을 비교하여 다양한 sleep metric을 평가했습니다. 총 수면 시간, 수면 시작 지연 시간, 수면 효율성, 수면 중 각성 시간, REM 지연을 평가했습니다.
세번째, 인구통계학적 특성에 따른 성능을 조사하기 위해, test dataset을 연령, 성별, BMI 그리고 무호흡-저호흡 지수(AHI)와 관련된 그룹으로 나누어 HomeSleepNet의 성능을 조사했습니다.
마지막으로, HomeSleepNet의 각 학습 요소들의 기여도를 보이기 위해 ablation study를 수행했습니다.
Results
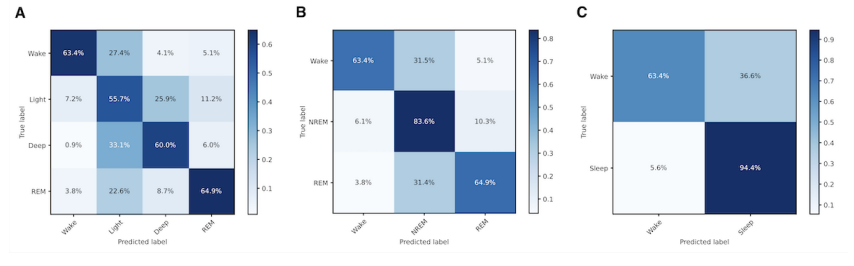
Sleep Staging Performance
HomeSleepNet은 3-stage classification에서 overall accuracy 76.2%를 달성했습니다. 구체적으로 wake는 63.4%, NREM sleep은 83.6%, REM sleep은 64.9% 달성했습니다. 2-stage classification에서는 모든 metric 성능을 향상했습니다. sleep-wake prediction accuracy를 88.5%까지 향상시켰습니다. 4-stage classification에서는 59.4%라는 상대적으로 저조한 정확도를 보였습니다.
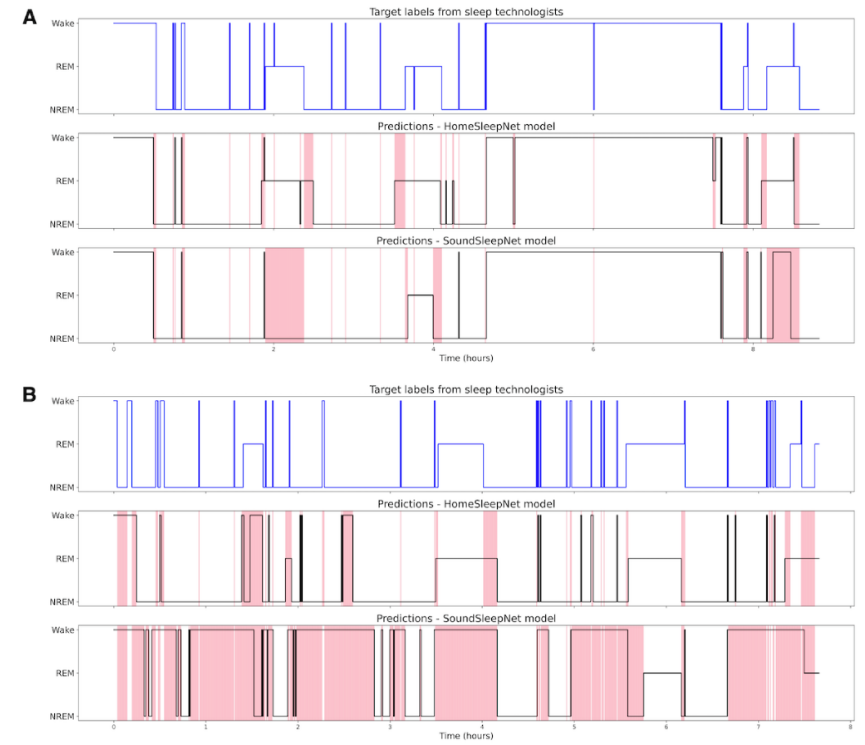
위 그림은 전체 밤 동안의 sleep-stage prediction을 보여줍니다. baseline model인 SoundSleepNet과 HomeSleepNet의 결과입니다. SoundSleepNet이 첫번째 사람에서 좋은 성능을 보여줬지만, 수면의 중반부와 후반부에서 misclassified 2REM block이 등장합니다. 하지만 두 번째 참여자에서는 SoundSleepNet이 동작을 제대로 못합니다(대부분 깨어있다고 예측하는 error를 보임). 하지만 HomeSleepNet은 두 참여자에서 대부분의 sleep stage에서 성공적으로 예측했으며, sleep transition을 잘 capture 했습니다.
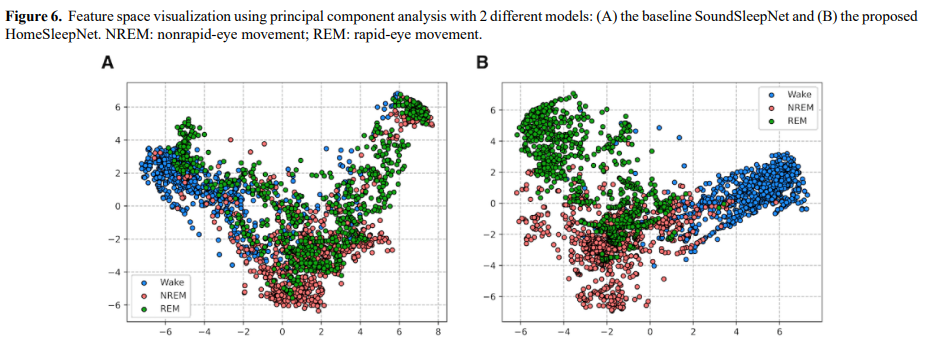
위 그림은 저자들의 HomeSleepNet과 baseline SoundSleepNet model의 마지막 hidden layer의 output을 가지고 PCA를 수행한 결과입니다. 저자들은 random 하게 800개 sleep epoch을 선택하여 visualization 하였습니다. HomeSleepNet의 feature space가 SoundSleepNet의 feature space보다 더 잘 구성되어 있고, cluster가 명확하게 구분되는 것을 볼 수 있습니다. SoundSleepNet에서는 REM 단계의 datapoint들이 넓게 흩어져 있는 반면, HomeSleepNet에서는 더 명확하게 구분된 cluster를 보여줍니다. 이 결과는 가정환경에서 녹음된 소리를 사용한 수면 단계 예측에 있어 HomeSleepNet이 SoundSleepNet보다 뛰어나다는 것을 보여줍니다.
Conclusion
저자들이 알기론, 개인의 집에서 녹음된 sound를 이용한 첫 sound-based sleep staging study입니다. 집에서 측정한 PSG와 model 성능을 비교하여 평가를 진행했습니다. hospital data에서 home audio로의 transfer learning과 consistency learning을 수행하여 성능을 향상시켰습니다. 저자들의 model이 home sound를 사용하여 정확하게 sleep stage를 예측할 수 있습니다.



