https://www.isca-archive.org/interspeech_2024/lee24_interspeech.html
ISCA Archive - FVTTS : Face Based Voice Synthesis for Text-to-Speech
FVTTS : Face Based Voice Synthesis for Text-to-Speech Minyoung Lee, Eunil Park, Sungeun Hong A face is expressive of individual identity and used in various studies such as identification, authentication, and personalization. Similarly, a voice is a means
www.isca-archive.org
해당 논문을 보고 작성했습니다.
Abstract
얼굴은 개인의 identity를 표현하고 identification, authentication, personalization과 같은 다양한 연구에서 사용됩니다. 유사하게 목소리도 개인을 표현할 수 있으며, 목소리를 참조로 사용하여 개인의 음성을 합성하는 연구가 활발히 진행되고 있습니다. 하지만 목소리를 기반으로 하여 음성을 합성하는 것은 음성 샘플 의존성이라는 한계가 존재합니다. 저자들은 Face-based Voice synthesis for Text-To-Speech (FVTTS)를 제안합니다. 이는 얼굴 사진을 통해 목소리를 합성하며, 음성 샘플보다 개인의 정체성을 더 잘 표현할 수 있습니다. face-based TTS method의 주요 과제는 얼굴 사진으로부터 목소리와 상당히 연관 있는 뚜렷한 voice feature를 추출하는 것입니다. 저자들이 사용한 face encoder는 global facial attribute를 음성과 관련된 feature와 통합하여 개인 특성을 나타내도록 설계되었습니다. FVTTS는 다양한 metric에서 우수성을 입증하였으며 다른 data domain에서도 적응될 수 있음을 보였습니다.
Introduction
개인의 얼굴은 성별, 나이, 민족 등을 포함한 개인의 정체성을 표현합니다. 얼굴 이미지는 identification, authentication, personalization과 같이 다양한 연구 분야에서 널리 사용되고 있습니다. 목소리도 개인을 표현하는 수단이며, 개인화된 음성 합성이 발전되고 있습니다. 맞춤형 음성 합성에서는 이전 연구들이 짧은 reference voice sample만 가지고도 뛰어난 성능을 달성했습니다. YourTTS는 input sample voice를 기반으로 다국어를 지원하는 multi-speaker TTS입니다. MegaTTS는 inductive bias를 활용한 대규모 TTS model입니다. 이는 prosody large language model을 사용함으로써 콘텐츠, 음색, 억양과 같은 고유한 음성 속성을 유지하며 새로운 목소리를 생성하여 SOTA를 달성했습니다. 하지만 새로운 voice를 합성하기 위해선 target voice의 reference sample을 필요로 합니다. target speaker의 voice를 얻는 것이 어려운 상황이 존재할 수 있으며, 애니메이션 캐릭터나 가상현실의 아바타와 같은 가상의 인물을 위한 음성을 합성해야 하는 경우가 존재할 수 있습니다. 그리고 reference voice-based TTS는 주어진 voice sample에서 나타나는 특성에만 의존하며 다양한 특성을 표현하기에 어려움이 존재하게 됩니다.
그래서 저자들은 기존에 널리 사용되는 음성 샘플 대신, 얼굴 이미지를 condition으로 사용하는 personalization TTS를 제안합니다. 앞서 말했듯이 얼굴 이미지는 voice sample에서 나타내지 못하는 개인의 정체성과 특징을 나타냅니다. 얼굴과 목소리 사이의 상관관계에 착안하여, 저자들은 얼굴 이미지를 활용하여 personalized voice를 생성합니다. 이전 연구들은 성대, 얼굴 근육, 얼굴 뼈와 같은 조음 구조가 개인의 목소리르 만드는 데 중요한 역할을 한다고 말했습니다. 신경과학적 관점에서 사람은 얼굴로부터 목소리를 매칭할 수 있으며, 목소리로부터 얼굴을 매칭할 수도 있습니다. 이러한 voice-face 상관관계는 얼굴 이미지로부터 음성을 합성하는 연구로 이어졌습니다. Face2Speech는 얼굴 사진을 사용하는 TTS sytem에 대한 초기 연구입니다. 이는 face embedding과 speech embedding이 align 되도록 face encoder를 학습시킵니다. 이후 화자의 얼굴 사진으로부터 더 자연스럽고 사실 같은 음성 특징을 추출하고, 추출된 얼굴 특징을 기존의 speech embedding과 align 시키는 것에 대해 초점을 맞춰 연구가 진행되었습니다. 하지만 얼굴 사진에는 비음성 관련 정보를 포함한 다양한 feature들이 존재하기 때문에, 얼굴 사진에서 개인화된 voice feature를 직접적으로 학습하는 데 어려움이 존재합니다. FaceTTS는 voice를 합성하기 위해 화자의 얼굴 사진으로부터 목소리와 관련된 특징을 직접 추출하였습니다. 하지만 FaceTTS는 target voice와 합성된 voice 사이 차이를 최소화하기 위해 추가적인 network를 사용합니다.
이 논문에서 저자들은 Face-based Voice synthesis TTS model을 제안합니다. 이는 end-to-end 구조로 face image로부터 새로운 voice를 합성합니다. 저자들의 model은 voice sample을 사용하지 않고 얼굴 사진으로부터 personal voice 관련 특징을 바로 추출합니다. FVTTS는 추가적인 network 학습 없이도 더 자연스러운 voice를 합성함으로써 상당히 발전된 성능을 기록했습니다. text, speech, face image가 주어지면, model은 각각의 feature를 동시에 추출합니다. 저자들은 face encoder가 2가지 face feature를 추출하도록 설계했습니다. 하나는 global face image feature이고, 또 다른 하나는 vocal-related feature입니다. 이 face encoder를 사용하여 FVTTS는 face image로부터 바로 personalized voice characteristic을 추출합니다. 이러한 multi-modal feature를 통해, 저자들의 model은 주어진 text와 얼굴을 바탕으로 음성의 적절한 분포를 학습하여 음성을 합성할 수 있습니다. 요약하면 contribution이 다음과 같습니다.
- 저자들은 face-based end-to-end TTS model인 FVTTS를 제안합니다. FVTTS는 voice sample 없이 얼굴로부터 특정 feature를 추출하여 사용해 더 자연스러운 voice를 생성합니다.
- 저자들은 face encoder를 TTS에 통합하여 얼굴 이미지의 global 특성과 personalized voice characteristic을 나타내는 특정 facial feature를 결합해 음성을 직접 추출할 수 있도록 설계했습니다.
- 실험을 봍어, 저자들은 face-based zero-shot TTS의 잠재성을 입증하였고 저자들의 model이 face-based TTS system의 새로운 benchmark 역할을 합니다.
Method
FVTTS는 화자의 얼굴 사진을 기반으로 personalized voice를 생성합니다. 얼굴 사진에서 바로 voice feature를 추출하는 것에 대한 어려움을 해결하기 위해, 저자들은 두 가지 image feature를 fuse 하는 face encoder를 사용합니다. fused face feature를 가지고, FVTTS는 VITS를 기반으로 personalized voice를 합성합니다. 전반적 구조는 아래와 같습니다.

Encoder
- Text Encoder
text encoder는 text phoneme에서 text feature를 추출합니다. VITS에서 사용하는 transformer encoder를 그대로 사용했습니다. text encoder의 output은 projection layer를 통해 latent variable의 분포를 계산하는 데 사용됩니다.
- Face Encoder
face encoder는 face image로부터 personalized voice feature를 나타내는 speaker feature h_{sid}를 구하기 위해 사용됩니다. face image를 사용하기 때문에, 학습할 speaker embedding 수를 사전에 정의할 필요가 없습니다. 위 그림의 (b)와 같이, face encoder는 global face feature extraction (ENC_g)와 personalized voice-related feature extraction (ENC_p)로 구성됩니다. ENC_g와 ENC_p에 동일한 face image가 input으로 들어갑니다.
ENC_g는 image의 global feature를 학습하는 network입니다. image embedding emb_{img}를 추출하기 위해 2개 convolution block을 stack한 다음 linear layer을 사용합니다. personalized feature는 ENC_p를 사용하여 구해집니다. 일반적으로 face identification에서 사용되는 pre-trained FaceNet model을 사용하여 individual characteristic을 추출합니다. facial embedding은 frozen FaceNet으로 구해지며, 그다음 linear layer에 들어가 final face embedding emb_{face}를 얻습니다. 추출된 feature들을 섞어 speaker feature h_{sid}를 얻습니다.
식으로 나타내면 위와 같습니다. 각 feature의 weight는 학습 가능한 parameter로 설정했습니다.
- Posterior Encoder
posterior encoder는 spectrogram을 input으로 받아 speech latent representation z를 계산합니다. 이 module은 non-causal WaveNet residual block으로 구성됩니다. individual speaker's characteristic을 condition으로 하는 다양한 voice를 생성하기 위해 face image로부터 얻은 speaker feature h_{sid}를 각 residual block에 더해 global condition으로 사용합니다.
Flow Model
Normalizing flow는 posterior encoder로부터 spectrogram feature를 받고, intermediate representation 없이 voice를 합성하기 위해 latent representation의 분포를 학습합니다. 이를 통해 end-to-end 구조로 사람같은 speech의 rhythm을 생성할 수 있도록 만들어줍니다. 위 그림의 (a)처럼 학습 과정에서 normalizing flow는 redefined Monotonic Alignment Search (MAS)를 이용해 학습되고, input text로부터 다양한 rhythm을 위해 stochastic duration predictor가 사용됩니다. inference 할 때는 MAS를 사용하지 않습니다. text encoder 기반 inverse flow network를 사용하고 stochastic duration predictor를 사용하여 duration을 예측합니다. inference 과정은 위 그림의 (c)와 같습니다.
Vocoder
speech의 latent representation이 주어지면, vocoder는 personalized voice를 합성합니다. HiFi-GAN v1의 generator를 vocoder로 사용했으며, discriminator는 약간의 수정을 진행했습니다. personalized voice를 생성하기 위해, face embedding h_{sid}를 posterior encoder에서 구한 input z에 더합니다.
Experiments
Datasets
가장 큰 english audio-visual dataset인 Lip Reading Sentence 3(LRS3)를 주 training set으로 사용했습니다. shape predictor 68 face landmark model을 사용하여 한 video 당 5개 image를 sample하여 정면 얼굴 image를 얻었습니다. training set으로 3,995명의 speaker의 10,282개 utterance를 사용했습니다.
저자들은 face-based TTS의 다양한 dataset에서의 범용성을 평가하기 위해 두 개의 추가 dataset을 사용하여 실험을 진행했습니다. 첫 번째로, controlled laboratory dataset인 GRID dataset을 사용했습니다. performance를 평가하기 위해 각 video마다 3개 얼굴 image를 추출했습니다. 두 번째, 다양한 publicly available animation movie에서 image를 모아 animated character에서의 face-based TTS를 확인했습니다. 11명의 character가 존재하며, 6명은 여성, 5명은 남성이었습니다.
Implementation Details
학습할 때, 특정 image와 utterance 쌍에 대한 overfitting을 막기 위해, 같은 화자의 다른 얼굴 사진들을 동일한 발화와 매칭하여 매 step마다 무작위로 sampling 하였습니다. performance를 평가하기 위해, publicly available model들과 비교를 진행했습니다. VITS로 구성된 YourTTS를 사용했습니다. YourTTS는 target speaker의 음성 샘플을 기반으로 읍성을 합성하는 데 특화된 모델입니다. 또 다른 비교 모델로 얼굴 기반 diffusion TTS model인 FaceTTS를 사용했습니다.
Evaluation Metric
저자들은 speaker encoder cosine similarity (SECS), word error rate (WER), mel cepstral distortion (MCD), gender accuracy (GA), mean opinion score (MOS)를 evaluation metric으로 사용했습니다. SECS는 서로 다른 얼굴 사진이지만 동일한 speaker의 speech 사이 cosine similarity를 의미합니다. WER을 통해 합성된 speech의 intelligibility를 측정했습니다. MCD는 합성된 speech와 target speech 간의 차이를 측정합니다. GA는 speaker 다양성과 구별 가능성을 확인하기 위해 사용되었습니다.
subjective evaluation의 경우, consistency (MOS-C), intelligibility (MOS-T), naturalness (MOS-N), 합성된 voice와 source voice 간의 유사성 (MOS-S), 목소리와 얼굴 사이 synchronization (MOS-M)을 측정했습니다.
Results on LRS3 Dataset

위 표는 LRS3 dataset에 대한 결과를 보여줍니다. FVTTS가 face-based TTS에서 거의 대부분의 지표에서 성능이 향상된 것을 볼 수 있습니다. 저자들의 model은 SECS와 MOS-C score가 voice-based TTS와 유사한 결과를 달성했으며, 이를 통해 FVTTS가 동일한 화자이지만 다른 얼굴 사진이어도 유사한 personalized feature를 추출할 수 있다는 것을 보였습니다. intelligibility의 경우, FVTTS가 MOS-T에서는 가장 좋은 성능을 달성했지만, FaceTTS보다 WER score는 좋지 않은 모습을 보여줍니다. 이러한 결과는 사람과 기계의 intelligibility 간의 차이 때문이지만, 저자들의 goal은 사람에게 더 알맞은 intelligibility를 제공하는 것이라고 합니다. MOS-N score에서 저자들의 model이 가장 좋은 성능을 달성했습니다. MOS-S결과와 MCD 결과를 보면, 저자들의 model이 face image를 가지고 target speaker의 voice와 유사한 목소리를 합성할 수 있는 능력이 있다는 것을 보여줍니다. 그리고 저자들의 model이 가장 좋은 MOS-M result를 보여줌으로써 face iamge와 합성된 voice의 synchronization을 보여준다는 것을 확인할 수 있었습니다.
voice-based TTS model보다 더 좋은 GA score를 달성함으로써, FVTTS가 face image에서 gender feature를 잘 catch 할 수 있다는 것을 확인했습니다. 그리고 Resemblyzer를 사용하여 합성된 speech를 speaker embedding으로 변환하여 visualize 하면 다음과 같습니다.
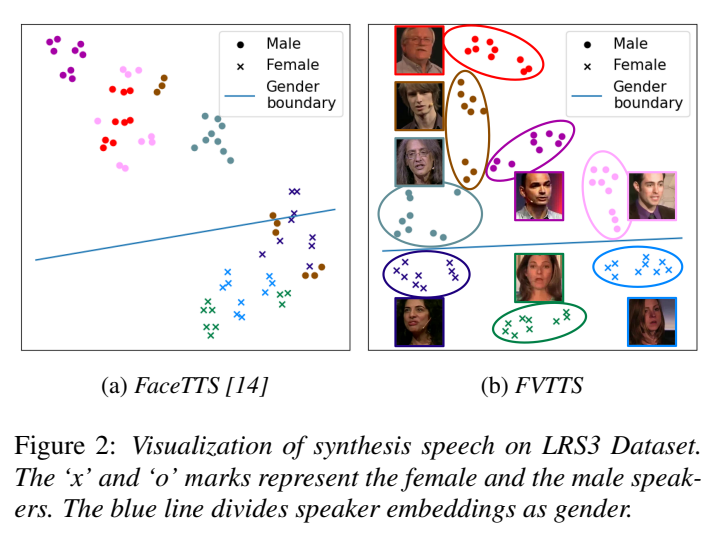
저자들의 model이 다양한 목소리를 생성할 수 있을 뿐만 아니라, personalized feature를 잘 capture 할 수 있고 speaker마다 구분된 voice를 합성할 수 있음을 보여줍니다.
ablation study의 경우, full model이 ENC_p를 사용하지 않는 baseline보다 더 높은 SECS를 달성했음을 볼 수 있습니다. 사람이 평가할 때, 제안된 구조가 더 자연스럽고 얼굴에 일치하는 결과를 만들 수 있다는 것을 보였습니다.
Efficiency of Face Encoder
- Visualization of Face Encoder

저자들은 face encoder의 효율성을 보이기 위해, personalized feature를 나타내는 과정에서 encoder의 focal area가 어디인지 visualize 했습니다. 결과는 위와 같습니다. 전반적인 facial feature를 추출하도록 design 된 ENC_g는 face outline에 집중하고 사진 내의 얼굴 요소들을 식별하는 역할을 합니다. 반면에 ENC_p는 더 개인적은 feature를 capture 하는 것을 볼 수 있습니다. ENC_p가 주로 중앙 얼굴 영역, 특히 코와 입술 부분을 강조하는 것을 볼 수 있습니다. 이러한 결과는 ENC_g가 global image feature를 capture 하고 ENC_p가 personalized voice characteristic을 추출할 때 중요한 역할을 한다는 가설을 입증합니다.
- The effectiveness of the learnable weights
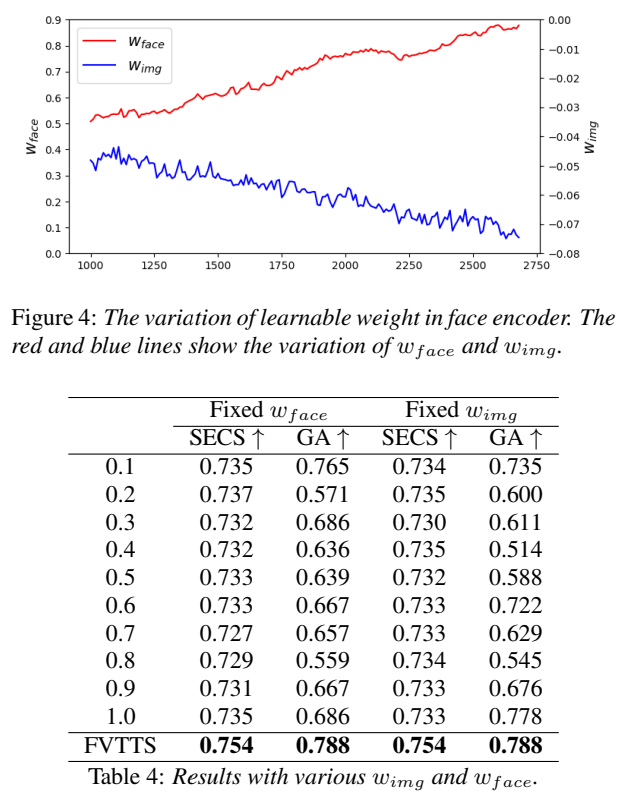
위 그래프는 500,000 iteration 이후의 learnable weight의 변화를 보여줍니다. 주황색 선이 w_{face}의 value를 나타내며 각 interation마다 커지는 것을 볼 수 있지만, w_{img}의 값을 나타내는 파란 선은 계속 감소되는 것을 볼 수 있습니다. 이러한 경향은 personalized voice feature를 나타내는 데 있어 ENC_p에서 유도된 facial feature의 중요성을 보여줍니다. 저자들은 w_{img}로 -0.0735를 사용하고 w_{face}로 0.8746을 사용했다고 합니다.
weight의 유효성을 평가하기 위해 실험을 진행했습니다. 한쪽 weight를 학습된 값에 고정한 상태에서 다른 가중치를 0.1에서 1.0까지 변경하며 그 영향을 조사했습니다. 결과는 위 표와 같습니다. 저자들이 사용한 weight보다 더 좋은 결과를 보이는 경우는 없었습니다. 학습하는 과정에서 Face Encoder의 learnable weight가 FVTTS의 성능에 상당한 영향을 준다는 것을 볼 수 있습니다.
Conclusion
personalized voice를 생성하기 위해 facial image를 사용하는 face-based voice synthesis model인 FVTTS를 제안합니다. 실험 결과들을 통해 FVTTS가 consistency, intelligibility, diversity를 보이면서 눈에 띄는 성능의 voice를 생성하는 데 효과적임을 보였습니다. 저자들의 unique face encoder의 효과도 ablation study를 통해 입증했습니다. FVTTS가 유망한 결과를 보였지만, 여전히 발전할 요소가 있습니다. 저자들의 model은 특히 독특한 헤어 스타일을 가진 사람들에 대해 더 넓은 성별 스펙트럼에 걸쳐 정확하게 음성을 생성하는 능력을 향상시키는 것을 목표로 합니다. 그리고 얼굴 표정에 반영된 감정을 포착할 수 있도록 만들 수도 있습니다. 앞으로 gender-aware and emotion-aware module을 통합하는 방향으로 발전시킬 수 있습니다.



