https://arxiv.org/abs/2206.13404
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
빠른 추론 속도와 high-quality speech waveform을 만들어내지만 가벼운 network이기 때문에 generative adversarial neural network (GAN) 기반 neural vocoder가 많이 사용되고 있습니다. 인지적으로 중요한 speech 요소는 주로 low-frequency band에 집중되어 있으며, 대부분의 GAN-based vocoder들은 downsampled speech waveform을 평가하는 multi-scale analysis을 사용합니다. 이 multi-scale analysis는 generator가 speech intelligibility를 향상시키는데 도움을 줍니다. 하지만 low-frequency band에 초점을 맞춘 multi-scale analysis는 aliasing과 imaging artifact와 같은 의도하지 않은 artifact를 야기한다는 것을 발견했습니다. 그래서 이 논문에서 저자들은 이러한 artifact와 GAN-based vocoder 사이 관계를 조사하고 Avocodo라 불리는 GAN-based vocoder를 제안합니다. Avocodo는 artifact를 줄이고 high-fidelity speech를 합성할 수 있습니다. 저자들은 다양한 관점에서 speech waveform을 평가하기 위해 2가지 종류의 discriminator를 제안합니다. collaborative multi-band discriminator와 sub-band discriminator입니다. 저자들은 또한 pseudo quadrature mirrror filter bank를 이용하여 aliasing을 피하면서 downsampled multi-band speech waveform을 얻습니다. 실험 결과를 통해, Avocodo가 objective and subjective 모두에서 baseline GAN-based vocoder보다 뛰어난 성능을 보인다는 것을 증명했으며, 더 적은 artifact를 포함한 speech를 생성한다는 것도 보였습니다.
Introduction
speech synthesis는 input text에 대응하는 speech waveform을 생성합니다. acoustic model은 먼저 input text에 대응하는 aocustic feature를 생성합니다. 그 다음 vocoder가 acoustic feature를 speech waveform으로 변환합니다. deep learning의 등장과 함께 neural vocoder는 사람이 녹음한 것과 구분이 안될 정도의 high-fidelity speech waveform을 합성할 수 있게 되었습니다. 최근 non-autoregressive convolutional architecture인 generative adversarial network (GAN) 기반 vocoder들이 등장했습니다. 다른 neural vocoder와 비교했을 때, GAN-based vocoder들은 더 빠르고 더 가벼우면서 high quality speech를 합성할 수 있습니다. 구체적으로 generator는 random noise나 mel-spectrogram과 같은 input feature를 speech waveform으로 변환합니다. discriminator는 generated speech waveform을 평가합니다.
low-frequency band에 있는 speech spectrum은 perceptual quality에서 매우 중요한 역할을 하기 때문에, 대부분의 GAN based vocoder들은 downsample된 speech waveform을 평가하는 multi-scale analysis를 사용합니다. multi-scale analysis는 generator가 low-frequency band의 speech spectrum에 focus 할 수 있도록 만들어줍니다. downsampling은 sampling rate를 줄여서 speech의 frequency 영역을 제한하기 때문에 가능합니다. MelGAN에서는 multi-scale discriminator (MSD)가 average pooling technique을 사용한 downsampled waveform을 평가합니다. HiFi-GAN에서는 multi-period discriminator (MPD)을 사용하여 주기적 성분을 평가합니다. 여러 주기를 사용한 sampling 기법으로 얻은 downsampled waveform을 평가합니다. 그 결과 이러한 GAN-based vocoder들은 합성된 speech의 quality를 성공적으로 향상시킬 수 있었습니다.
하지만 저자들은 GAN-based vocoder가 2가지 주요 문제점을 겪고 있다는 것을 발견했습니다. 첫 번째 문제는 upsampling layer로 인해 발생되는 artifact입니다. 예를 들어 high-frequency band에 있는 artifact들은 noise 때문에 speech의 quality가 떨어지게 됩니다. 두번째 문제는 harmonic 요소들의 reproducibility가 좋지 않다는 점입니다. 합성된 speech의 fundamental frequency (F_0)가 종종 부정확하게 나타나며, 이 원인 중 하나로 average pooling이나 균등 간격 sampling과 같은 단순한 downsampling 때문에 발생하는 aliasing이 있습니다. 이러한 artifact들은 large pitch variation을 갖는 speech를 합성할 때 perceptual quality를 크게 저하시킵니다.
이러한 문제를 해결하기 위해, 저자들은 GAN-based vocoder인 Avocodo를 제안합니다. Avocodo는 artifact를 minimize함으로써 high-quality speech를 합성합니다. Avocodo는 디지털 신호 처리에서 고려해야 할 artifact를 고려하고 억제하도록 설계되었습니다. Avocodo는 collaborative multi-band discriminator (CoMBD)와 sub-band discriminator (SBD)라는 2가지 discriminator를 사용합니다. CoMBD는 multi-scale analysis와 upsampling artifact를 위한 새로운 구조로 구성됩니다. CoMBD가 full-resolution waveform과 intermediate output을 평가하기 때문에 2가지 이점이 있습니다. 첫째, generator가 multi-scale analysis에 의해 low-frequency band에 존재하는 spectral feature에 초점을 맞출 수 있도록 도와줍니다. 둘째, generator는 upsampling layer 때문에 발생되는 artifact를 억제하도록 학습됩니다. SBD는 frequency별로 분해된 waveform을 판별함으로써 sound quality를 향상시킵니다. 이를 통해 generator가 low frequency band 뿐만 아니라 high frequency band에서의 speech spectrum을 학습할 수 있게 됩니다. 그리고 sound quality를 더 향상시키기 위해, 저자들은 pseudo quadrature mirror filter bank (PQMF)를 사용합니다. PQMF는 GAN-based vocoder들에서 일반적으로 사용되는 simple downsampling method들에 의해 야기되는 aliasing을 방지하고자, 높은 stopband attenuation을 제공하는 downsampling method입니다.
저자들은 objective and subjective evaluation을 사용하여 Avocodo의 성능을 평가했습니다. subjective evaluation은 Avocodo가 high-quality speech를 합성할 수 있고 unseen speaker synthesis에서도 robust하다는 것을 보여줍니다. 그리고 objective evaluation을 통해 F_0 reconstruction의 정확도와 high-frequency band의 quality들이 증가되었다는 것을 보였습니다.
Artifacts in GAN-based Vocoders
Upsampling artifacts
GAN-based vocoder는 mel-spectrogram과 같은 input feature의 rate를 waveform의 sampling rate까지 증가시키기 위해 upsampling layer을 사용합니다. 하지만 transposed convolution과 같은 upsampling layer는 여러 artifact를 야기하며 tonal artifact는 대표적 예시입니다. tonal artifact는 spectrogram의 수평선으로 나타납니다. 또한 mirrored low frequency가 high-frequency band에서도 등장하기도 하며, 이를 imaging artifact라 부릅니다. 디지털 신호 처리에서 신호는 이웃 sample 사이 0을 삽입함으로써 upsampling 하고 난 후 low-pass filtering을 적용하여 upsample 됩니다.

filtering을 하지 않은 경우 high-frequency band에 low-frequency component들이 나타나는데 (위 그림의 b), spectrum은 sampling rate의 cycle에 따라 반복되기 때문입니다. upsampling layer는 의도되지 않은 frequency component들은 충분히 제거해야 하지만, 실제로는 기준을 충족하지 못합니다. 위 그림 (c)와 같이, 의도되지 않은 frequency component들이 high-frequency band의 왜곡을 만들어 speech quality를 저하시킵니다. 이러한 artifact들은 image 생성 model에서 발생하는 texture sticking 현상과 유사합니다.
GAN-based synthesis에서 이러한 artifact를 해결하기 위해, upsampling layer의 구조를 수정하는 여러 연구들이 등장했습니다. 하지만 이러한 method들은 model 복잡도를 향상시키거나 artifact를 충분히 억제하지 못했습니다. 그래서 이 연구에서는 새로운 discriminator와 loss function을 제안하여 upsampling layer를 수정하지 않은 채로 artifact를 억제했습니다.
Aliasing in downsampling
GAN-based vocoder는 downsample 된 waveform을 평가하여 low frequency band의 spectral information을 학습하기 위해 discriminator를 사용합니다. average pooling이나 equally spaced sampling과 같은 기본적인 downsampling method들은 사용하기 간단하고 band-limited speech waveform을 효과적으로 얻을 수 있습니다. 하지만 이 방식들을 사용하여 얻은 downsampled waveform들에서 aliasing들이 발견되었습니다.
위 그림은 여러 방식을 통해 얻은 downsampled waveform 예시들을 보여줍니다. downsampling factor는 8로 설정했습니다. (c)는 equally spaced sampling을 사용하여 얻은 downsampling을 보여줍니다. 제거되어야 할 high-frequency component들이 다시 나타나 low-frequency band에 있는 harmonic frequency component들을 왜곡시키는 것을 볼 수 있습니다. (d)는 average pooling에 대한 결과를 보여줍니다. 이는 간단한 low-pass filtering과 decimation의 조합이며, low frequency band에서는 aliasing이 명확하게 등장하지 않습니다. 하지만 800Hz 이상의 harmonic component들이 왜곡되는 결과를 보여줍니다. downsampling factor가 증가될수록 artifact는 더욱 심해집니다. 이러한 왜곡된 downsampled waveform을 학습할 때 사용하면 model이 정확한 waveform을 생성하도록 학습하기 어렵습니다.
이러한 aliasing을 피하기 위해 high stopband attenuation을 갖춘 band-pass filter을 사용하는 downsampling이 필요합니다. digital filter인 PQMF은 이를 만족하며, 위 그림 (d)를 보면 harmonic을 잘 보존하는 것을 보여줍니다.
Proposed Method
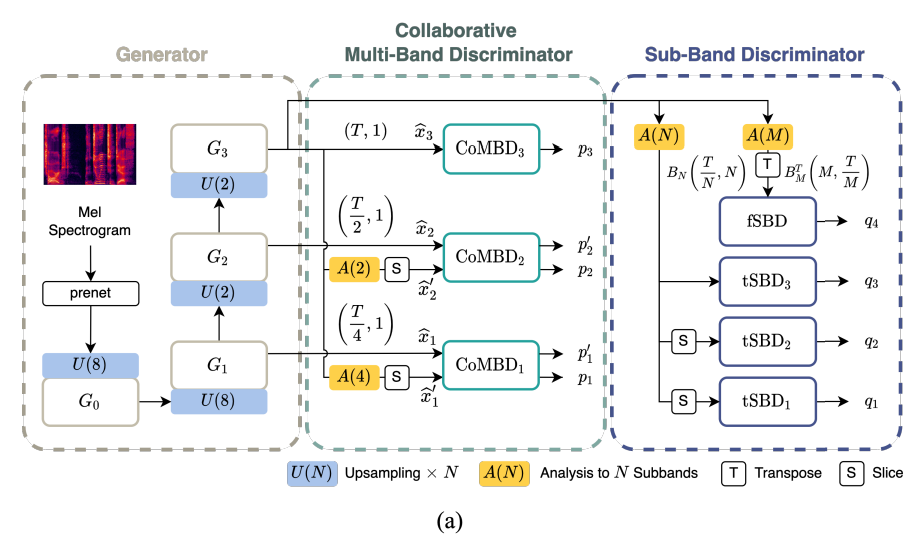
위 구림은 Avocodo의 전반적인 architecture를 보여줍니다. single generator와 2개 discriminator로 구성됩니다. mel-spectrogram을 input으로 사용하고 generator는 full-resolution waveform 뿐만 아니라 intermediate output을 생성합니다. 이후 CoMBD는 full-resolution waveform을 discriminate 하고 downsampled waveform을 discriminate 합니다. full-resolution waveform을 downsample하기 위해 PQMF를 low-pass filter로 사용합니다. 그리고 SBD는 PQMF 분석을 통해 얻어지는 sub-band signal을 discriminate합니다.
Generator
generator는 HiFi_GAN generator와 동일한 구조이지만, high-resolution and intermediate waveform으로 구성된 multi-scale output을 생성합니다. generator는 4개 sub-block을 가지고 있으며, 3개 block G_k (1 <= k <= 3)은 full resolution의 1/2^{3-k} 라는 resolution으로 waveform /hat{x_k}를 생성합니다. /hat{x_3}은 full-resolution waveform이고, /hat{x_1}과 /hat{x_2}는 intermediate output입니다. 각 sub-block은 multi-receptive field fusion (MRF) block과 transposed convolution layer로 구성됩니다. MRF block은 다양한 kernel size와 dilation rate를 가진 multiple residuall block을 포함하여 input의 공간적 feature를 capture 할 수 있습니다. HiFi-GAN과 다르게 각 subblock이 intermediate output을 return 한 다음 추가적인 projection layer가 더해집니다. 저자들의 방식은 upsampling layer를 사용하는 어떠한 GAN-based vocoder든 사용할 수 있습니다. 이 논문에서는 HiFi-GAN generator의 성능이 만족스러워 선택했다고 합니다.
Collaborative Multi-Band Discriminator
CoMBD는 generator의 multi-scale output을 discriminate 합니다. sub-module로 구성되며, 각 submodule을 서로 다른 resolution의 waveform을 평가합니다. 추가적으로, 각 sub-module은 MSD의 discriminator module을 기반으로 합니다. module은 fully convolutional layer와 leaky ReLU로 구성됩니다.
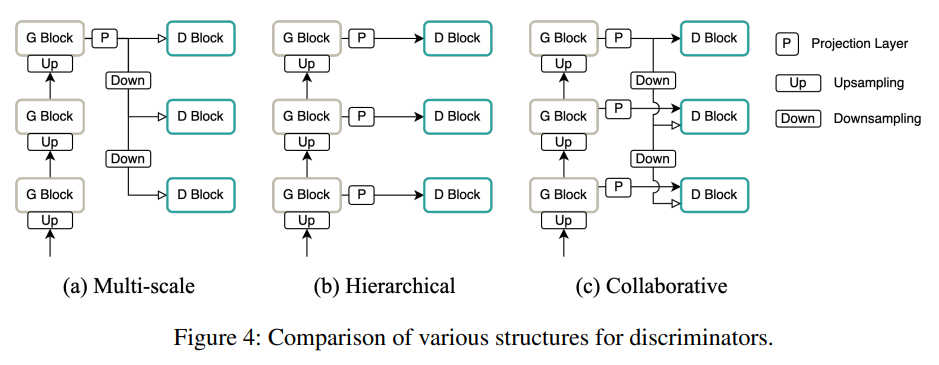
multi-scale structure (위 그림의 a) 또는 계층적 구조 (위 그림의 b)는 일반적으로 GAN-based neural vocoder에서 사용되지만, 이 논문에서는 각 구조의 이점을 결합하기 위해 두 구조 모두 (위 그림의 c) 사용했습니다. 이러한 collaborative structure는 generator가 artifact를 줄이고 high-quality waveform을 합성할 수 있도록 도와줍니다.
multi-scale structure는 full-resolution waveform 뿐만 아니라 downsampled waveform을 discriminate 하여 speech quality를 향상시킵니다. 특히 multiple scale로 downsample 된 waveform을 판별하는 것은 generator가 low-frequency band에 존재하는 spectral feature에 focusing 할 수 있도록 도와줍니다. 반면에 계층적 구조는 generator의 각 sub-block의 중간 output waveform을 사용하며, generator가 다양한 level의 acoustic 특성을 균형 있게 학습하도록 도와줍니다. 특히, generator sub-block은 band-limited waveform을 생성하도록 유도되어 expansion과 filtering을 균형있게 학습합니다. 따라서, 계층적 구조를 채택하면 upsampling artifact가 억제될 것으로 예상됩니다.
proposed collaborative structure에서 low resolution에 있는 sub-module (CoMBD_1, CoMBD_2)이 intermediate output /hat{x}와 downsampled waveform /hat{x'}을 input으로 받습니다. 각 resolution에서 두 input은 동일한 sub-module을 사용합니다. 예를 들어 Figure 3처럼 intermediate output /hat{x_2}와 downsampled waveform /hat{x'_2}은 CoMBD_2의 weight를 공유하여 output p_2, p_2'를 생성합니다. intermediate output과 downsampled waveform은 collaboration 이후 서로 match 되도록 학습됩니다. weight-sharing proccess를 사용하기 때문에 두 구조를 collaborate 할 때 추가적인 parameter를 필요로 하지 않습니다.
artifact를 줄여 speech quality를 더욱 향상시키기 위해, 미분 가능한 PQMF을 사용하여 aliasing이 제한된 downsampled waveform을 얻었습니다. 먼저 full-resolution speech waveform을 PQMF analysis를 사용하여 K개 sub-band signal B_K로 분해합니다. B_K는 single band signal b_1, ... , b_k로 구성됩니다. 각 single band signal의 length는 T/K이며, T는 full-resolution waveform의 length입니다. 그다음 첫 sub-band signal b_1이 lowest frequency band로 선택됩니다.
Sub-Band Discriminator
SBD는 PQMF analysis에 의해 얻어진 multiple sub-band signal을 discrimiate 하기 위해 제안되었습니다. PQMF는 n번째 sub-band signal b_n이 (n-1)f_s /2N에서 nf_s/2N 영역의 frequency information을 포함하도록 만들어줍니다. 여기서 f_s는 sampling frequency를 나타내고 N은 sub-band의 수를 나타냅니다. 이러한 sub-band signal의 특성에 영감을 받아, SBD sub-module은 서로 다른 sub-band signal 영역을 사용하여 다양한 discriminative feature를 학습합니다.
sub-module의 두 type은 다음과 같이 design 됩니다. 하나는 시간축에 따라 spectral feature의 변화를 capture 하고 또 다른 하나는 sub-band signal 사이 relationship을 capture 합니다. 이러한 두 sub-module은 tSBD와 fSBD로 언급됩니다. tSBD는 B_N을 input으로 받아 time-domain convolution을 수행합니다. sub-band range를 다양화함으로써, 각 sub-module은 특정 frequency 영역의 특성을 학습하도록 design 될 수 있습니다. 즉, tSBD_k은 특정 범위의 sub-band signal b_{i_k:j_k}을 input으로 받습니다. 대조적으로 fSBD는 M개의 channel sub-bands B_M에 transpose를 적용한 B_M^T을 받습니다. fSBD의 구성은 harmonic, formant와 같은 spectral feature에서 영감을 받았습니다.
SBD의 각 sub-module은 stacked multi-scale dilated convolution bank로 구성되어 sub-band signal을 평가합니다. dilated convolution bank는 다양한 receptive field를 cover 하기 위해 다른 dilation rate를 가진 convolution layer를 포함합니다. 그리고 SBD architecture는 speech waveform의 정확히 분석하기 위해, 각 frequency range에 대한 다양한 receptive field를 요구하는 inductive bias를 따릅니다. 그래서 각 sub-module마다 다른 dilation factor가 준비됩니다.
여러 neural vocoder들은 filter-bank를 사용하여 speech waveform을 분해하고 discriminator를 사용하여 sub-band signal을 점검합니다. 특히 SBD는 StyleMelGAN의 filter-bank random window discriminator (FB-RWDs)와 유사하게 PQMF을 사용하여 sub-band signal을 얻습니다. 하지만 SBD와 FB-RWDs는 상당히 다릅니다. 각 SBD의 각 sub-module은 서로 다른 범위의 sub-band singal에 대해 평가를 진행하지만, FB-RWD는 각 discriminator마다 sub-band signal 수가 다릅니다. 또한 SBD는 여러 종류의 block을 사용합니다. lower frequency band를 관측하기 위한 block, 전체 frequency band를 보기 위한 block, frequency band 별 관계를 보기 위한 block으로 구성됩니다. 그래서 SBD는 FB-RWDs보다 더 효율적으로 signal을 평가할 수 있습니다.
Tranining Objectives
- GAN Loss
GAN network를 학습하기 위해, least square adversarial objective를 사용합니다. GAN training objective의 sigmoid cross-entropy term을 least square로 대체하여 사용하여 학습 안정성을 향상시킵니다.
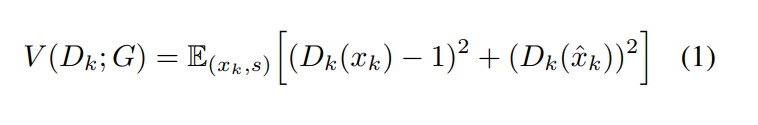
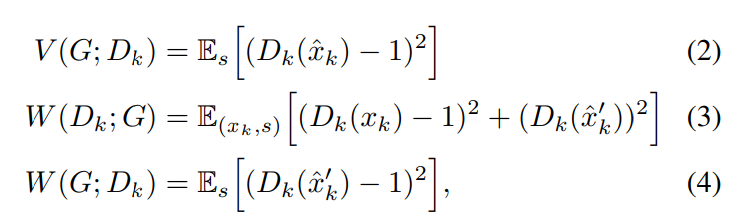
V는 multi-scale output에 대한 GAN loss, W는 downsampled waveform에 대한 GAN loss입니다. x_k는 k번째 downsampled ground-truth waveform을 나타내고, s는 speech representation을 나타냅니다. 이 논문에서는 mel-spectrogram을 사용합니다.
- Feature Matching Loss
Feature matching loss는 GAN 학습을 위한 perceptual loss이며, 이는 GAN-based vocoder system에서 사용되고 있습니다. discriminator에 있는 sub-module의 feature matching loss는 ground-truth의 intermediate feature map과 predicted waveform의 intermediate feature map 사이 L1 difference로 구성됩니다. 식은 다음과 같습니다.
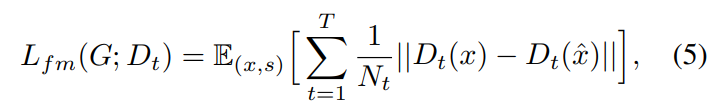
T는 sub-module의 layer 수를 나타냅니다. D_t는 t번째 feature map을 나타내고 N_T는 feautre map의 element 수를 나타냅니다.
- Reconstruction Loss
mel-spectrogram based reconstruction loss는 waveform generation 학습의 안정성과 효율성을 향상시킵니다. ground-truth의 mel-spectrogram과 predicted x^ speech waveform의 mel-spectrogram 사이 L1 differences를 통해 구해집니다. reconstruction loss는 다음과 같습니다.
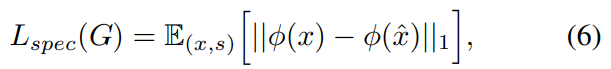
Φ(·)는 mel-spectrogram으로의 transform function을 의미합니다.
- Final Loss
전체 system 학습을 위한 final loss는 다음과 같이 정의됩니다.
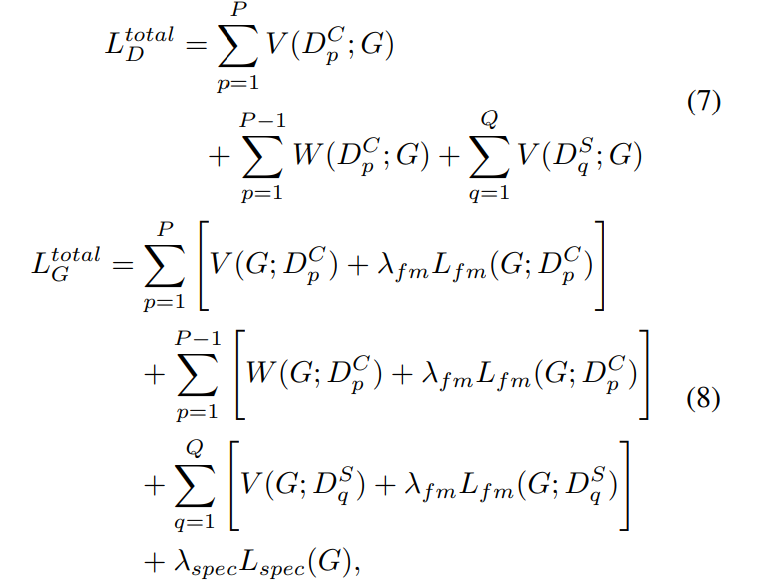
D_p^C는 CoMBD의 p번째 submodule을 나타내고 D_q^S는 SBD의 q번째 sub-module을 의미합니다. 저자들은 λ_{fm}을 2로, λ_{spec}을 45로 설정했다고 합니다.
Experimental Setup
Training Setup
저자들은 baseline model로 HiFi-GAN, Voc-GAN, StyleMelGAN을 선택했습니다. HiFi-GAN은 multi-scale structure 기반 discriminator를 사용합니다. 이때 downsampling을 average pooling과 equally spaced sampling을 사용합니다. VocGAN은 계층적 구조 기반 discriminator를 사용하며 이때 average pooling을 사용하여 downsampling 합니다. StyleMelGAN은 PQMF analysis로 얻어진 singal에서 random window select을 수행하여 sub-band signal을 얻고 discrimniate 했습니다. single speaker speech synthesis의 경우, Avocodo와 HiFi-GAN은 3M step 학습을 진행했으며, VocGAN은 2.5M step 진행했으며, StyleMelGAN은 1.5M step 진행했습니다. unseen speaker synthesis의 경우엔 모든 model을 1M step 진행했습니다.
Avocodo의 generator와 HiFi-GAN의 generator의 hyperparameter는 동일하게 설정했습니다. HiFi-GAN generator는 parameter 수를 다르게 설정하여 V1, V2를 구현했으며, V1이 더 큰 version입니다. Avocodo 역시 이와 같이 2가지를 준비했습니다. sub-band 수를 나타내는 N을 16으로 설정하여 tSBD에 적용했으며, M은 64로 설정하여 fSBD에 적용했습니다.
Experimental Results
Audio Quality & Comparison
- Subjective evaluation
5-scale mean opinion socre (MOS) test를 수행하여 single and unseen speaker snythesis를 평가했습니다. 영어 dataset의 경우, 15명 native English speaker가 참여하고 korean dataset의 경우, 19명 native Korean speaker가 참여하였습니다.
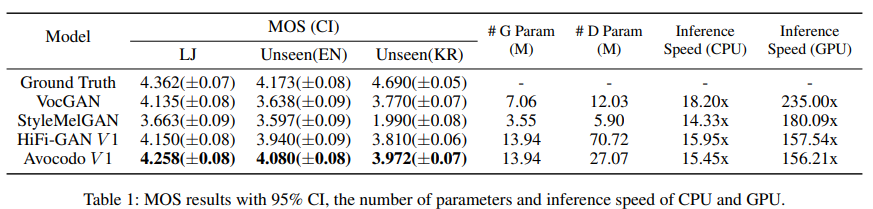
위 표는 subjective evaluation result입니다. Avocodo V1이 single and unseen speaker synthesis task 모두에서 가장 좋은 성능을 달성했습니다. unseen speaker에 대한 high quality speech waveform을 합성하기 위해선 speech signal의 일반화된 특성을 학습하는 것이 중요합니다. Avocodo가 baseline model보다 artifact에 있어 더 robust 하다는 것을 의미합니다. 특히 Unseen(KR)의 경우, 매우 다양한 speech style이 있기 때문에 더 어려운데 StyleMelGAN은 실패하고 다른 model보다 뛰어난 모습을 보여주는 것을 볼 수 있습니다.
- Objective evaluation
Objective evaluation은 vocoder를 정량적으로 평가합니다. F_0의 reproducibility를 평가하기 위해, 저자들은 F_0 root mean square error를 수행했습니다. artifact는 매우 짧은 영역에 존재하기 때문에, voiced frame에서 mean square error를 수행했습니다. 하지만 F_0 RMSE의 average value로 artifact를 나타내기엔 불충분합니다. 그래서 저자들은 F_0 absolute error의 표준편차(F_0 AE-STD)를 계산했습니다. F_0 AE-STD의 값이 낮다면 왜곡이 덜 존재한다는 것을 의미합니다. voiced/unvoiced (VUV) frame의 정확성을 평가하기 위해, VUV classification의 false positive and negative rate (VUV_fpr, VUV_fnr)를 측정했습니다. 합성된 speech의 인지된 quality를 측정하기 위해, mel-cepstral distortion (MCD)와 perceptual evaluation을 구했습니다. 추가적으로 0Hz ~ 5.5kHz라는 low-frequency band에서 log-spectral distance를 계산하고, 5.5kHz ~ 11.02kHz라는 high-frequency band에서 log-spectral distance를 계산했습니다.

위 표는 Avocodo V1가 다른 model보다 더 뛰어난 성능을 보인다는 것을 보여줍니다. 특히 upsampling artifact를 억제하는 방식 덕분에, LSD-HF에서 Avocodo가 좋은 결과를 보여주고 있습니다. 이는 Avocodo가 high-frequency band에서 reproducibility가 좋다는 것을 의미합니다. 그리고 Avocodo가 학습을 하면서 aliasing을 감소시킨다는 것을 의미합니다. discriminator의 parameter 수가 HiFi-GAN보다 적지만 더 나은 성능을 보여줍니다. 그리고 inference time도 유사했다고 합니다.
Discriminator-wise Comparison
single speaker synthesis task에 대한 MOS test는 저자들의 discriminator, MelGAN의 MSD, HiFi-GAN의 MPD를 비교하기 위해 진행했습니다. 모든 discriminator들은 Avocodo의 generator V2와 함께 학습되었습니다.
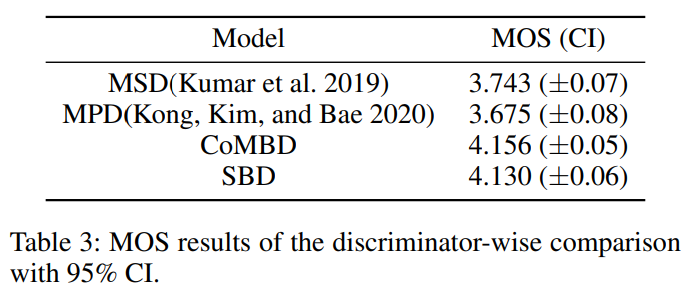
실험 결과는 위와 같습니다. λ_fm과 λ_spec이 학습 중에 영향을 미치는 것으로 관찰되었기 때문에 각각 2, 10으로 조절했다고 합니다.
Analysis on artifacts
- Upsampling Artifacts
artifact를 억제하는 Avocodo의 능력은 generator의 intermediate upsampling layer에서 발생하는 upsampling artifact를 관측하여 설명할 수 있습니다. HiFi-GAN과 Avocodo를 사용하여 생성된 audio sample들을 linear-sacle spectrogram으로 변환한 결과가 다음과 같습니다.
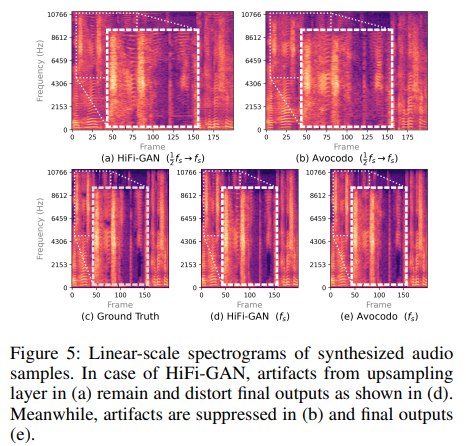
위 그림의 첫 번째 행의 audio sample은 마지막 MRF block을 건너뛰고 1/2f_s에서 f_s로 upsampling 한 output입니다. transpose convolution 때문에 HiFi-GAN의 audio sample에 tonal and imaging artifact가 존재하는 것을 볼 수 있습니다.
하지만 Avocodo's generator는 CoMBD를 통해 intermediate upsampling layer에서 발생하는 artifact를 제거하도록 학습되었습니다. 그래서 artifact가 없는 것을 볼 수 있습니다.
- Aliasing
aliasing 때문에 생기는 F_0의 왜곡을 관측하기 위해, 저자들은 single voice dataset을 가지고 GAN-based vocoder를 학습시켰습니다. low-frequency component를 적절하게 modelling 하기 위한 large-scale downsampling은 불완전한 F_0를 reconstruction을 초래합니다. 예를 들어 HiFi-GAN과 VocGAN은 11배, 16배 downsample 됩니다.
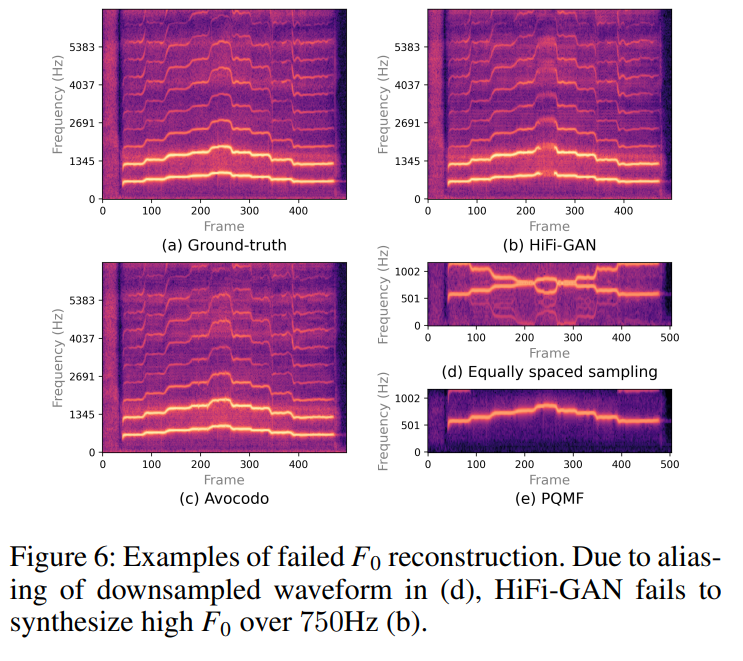
그 결과 위와 같습니다. (d)를 보면 downsampled waveform의 harmonic component들이 aliasing 때문에 왜곡된 것을 볼 수 있습니다. (e)는 PQMF의 결과이며 anti-aliasing 하여 F_0가 보존된 것을 볼 수 있습니다. (b)를 보면 HiFi-GAN에 대한 결과를 나타내며, F_0를 reconstruction 하지 못해 왜곡이 발생하는 것을 볼 수 있습니다. Avocodo는 F_0를 잘 보존하는 것을 볼 수 있습니다.
Conclusion
이 논문에서는 artifact-free GAN-based vocoder인 Avocodo를 제안합니다. upsampling artifact나 aliasing과 같은 artifact들은 upsampling layer의 한계와 단순한 downsampling 방법으로 얻은 low-frequency band에 objective function이 치우쳐져 있기 때문에 발생하는 것으로 관측되었습니다. 이러한 문제를 해결하기 위해, 두 가지 새로운 discriminator인 CoMBD와 SBD를 설계했습니다. CoMBD는 multi-scale과 계층적 구조를 결합한 collaborative 구조로 multi-scale 분석을 수행합니다. SBD는 PQMF 분석을 통해 분해된 sub-band singal을 시간적 측면과 주파수 측면에서 구별합니다. 또한 PQMF는 downsampling과 PQMF 분석에 사용합니다. 다양한 실험을 통해 PQMF가 합성된 음성에서 artifact를 효과적으로 줄인다는 것을 입증했습니다.



