https://arxiv.org/abs/2301.08237
LoCoNet: Long-Short Context Network for Active Speaker Detection
Active Speaker Detection (ASD) aims to identify who is speaking in each frame of a video. ASD reasons from audio and visual information from two contexts: long-term intra-speaker context and short-term inter-speaker context. Long-term intra-speaker context
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Active Speaker Detection (ASD)는 video의 각 frame에서 누가 말을 하고 있는지 식별하는 것을 목표로 합니다. ASD를 해결하기 위해서는 audio와 video information을 두 가지 상호 보완적인 맥락에서 사용하는 것이 필요합니다: long-term intra-speaker context는 동일한 화자의 시간적 의존성을 modeling 하고, short-term inter-speaker context는 동일한 장면 내에서 화자 간 상호작용을 modeling 합니다. 이를 바탕으로, 저자들은 LoCoNet을 제안합니다. 이는 Long-term Intra-speaker Modeling (LIM)과 Short-term Inter-Speaker Modeling (SIM)을 교차적으로 활용하며, 간단하지만 효과적인 Long-Short Context Network입니다. LIM은 long-range temporal dependency modeling을 위해 self-attention을 사용하고, audio-visual interaction modeling을 위해 cross-attention을 사용합니다. SIM은 short-term interspeaker context를 위해 local pattern을 capture 하는 convolutional block을 통합합니다. 실험은 LoCoNet이 다양한 dataset에서 SOTA를 달성했다고 보여줍니다.
Introduction
실제 상호작용이 필요한 computer vision system은 물체나 사람과 같이 scene의 물리적 특성 뿐만 아니라 어떻게 사람이 다른 사람들과 상호작용 하는지와 같은 social 특성도 인식할 수 있어야 합니다. 여러 사람이 상호작용하는 복잡한 장면에서 어느 순간 누가 말을 하고 있는지를 식별하는 것이 중요한 task 중 하나입니다. 이러한 Active Speaker Detection (ASD) 문제는 human-robot interaction, speech diarization, multimodal learning 등과 같은 다양한 real-world application에서 매우 중요합니다.
입과 눈의 움직임과 같은 시각적 단서는 audio signal과 일치할 때, 직접적이고 주요한 증거로 사용됩니다. 긴 audio-visual segment에서의 inter-modality synchronization은 추가적인 정보를 제공합니다.

위 그림의 첫번째 행은 Long-term Intra-speaker Modeling이 한 사람을 긴 시간 동안 관측함으로써 주요 지표를 파악하는 방법을 보여줍니다.
하지만 복잡한 video에서는 사람의 얼굴이 가려지거나 돌아있거나 frame 밖에 있거나 매우 작게 나타나므로, 시각적 단서만으로 speaking activity를 바로 추론하는 데 어려움이 있습니다. 다행히도 target speaker에 대한 valuable evidence는 scene에서 다른 사람들의 행동을 통해 얻어질 수 있습니다. 위 그림의 두 번째 행을 보면, 왼쪽 m개 frame에서 오른쪽 사람의 얼굴 일부분만 보이지만, 중간에 있는 여성이 (T_{i+1} → T_{i+m})에서 고개를 돌리고 T_{i+m}에서 두 사람이 입을 벌리고 있지 않기 때문에 해당 남성이 말을 하고 있다는 것을 쉽게 알 수 있습니다. T_{i+m}에서 여자가 오른쪽 남성을 바라보는 것이 먼 시간인 T_{j+1}에도 말을 하고 있는지에 대한 정보를 제공하지 못한다는 사실에 주목해야 합니다. 그러므로 저자들은 Inter-speaker Modeling이 짧은 시간 범위에서 충분하다고 주장합니다. 왜냐하면 짧은 시간 동안의 speaker의 행동이 더 강하게 상관되기 때문입니다. Cognitive research도 speaker-listener coupling이 가까운 frame에서 더 조화롭게 이루어진다는 것을 보여줍니다.
이러한 frame 별 video classification task를 해결하기 위해, 존재하는 ASD method는 2가지 category로 나눌 수 있습니다: 1) parallel-inference method는 input으로 모든 frame을 받은 후 모든 frame을 한번에 pass 하는 방식이고, 2) sequential-inference method는 short clip을 input으로 받고 center frame에 대한 예측 결과를 output 하는 방식입니다. 따라서 sliding window strategy를 사용하여 모든 frame에 대한 결과를 얻습니다.

위 그림에서 볼 수 있듯이, 한 face crop의 speaking activity를 예측하는 parallel-inference method의 average-FLOPs이 sequence-inference method보다 좋지 않은 모습을 보여준다는 걸 알 수 있습니다. 하지만 긴 video clip을 input으로 받는 대부분의 parallel-inference method는 multi-speaker context를 고려하지 않으며 ASD task의 중요한 speaker 간 상호작용을 무시함으로써 성능 저하를 일으킵니다.
이러한 문제를 해결하기 위해, 저자들은 end-to-end Long-Short Context Network인 LoCoNet을 제안합니다. long-term Intra speaker Modeling (LIM)은 long-range dependency modeling을 위해 self-attention mechanism을 사용하고, audio-visual interaction을 위해 cross-attention mechanism을 사용합니다. Short-term Inter-speaker Modeling (SIM)은 local conversation pattern을 capture 하기 위해 convolution block을 통합합니다. 그리고 대부분 ASD method들이 high temporal downsampling을 위해 vision backbone을 사용하여 audio encoding을 구현하지만, 저자들은 frame 별 audio feature를 추출하기 위해 pretraiend AUdioSet weight를 사용하는 VGGFrame을 제안합니다. 저자들은 video processing의 효율성을 위해 parallel inference strategy를 사용합니다.
Related Work
대부분 최신 ASD 기술들은 3가지 중요한 차원으로 설명될 수 있습니다: method의 inference speed를 결정하는 frame-level processing strategy, 예측을 위한 feature representation을 강화하는 context information의 추출, 학습 mechanism 입니다.
Frame-level processing strategy
긴 video가 주어졌을 때, ASD method들은 frame 별 예측을 위해 2가지 main strategy를 사용합니다. 1) parallel-inference는 video의 모든 frame을 input으로 받고 한 번에 frame 별 output을 생성합니다. 이러한 방식은 빠릅니다. 하지만 일반적으로 multiple speaker의 interaction을 고려하지 않습니다. 2) sequential inference는 특정 frame을 중심으로 짧은 clip을 sampling 하여 해당 frame만 예측합니다. 이는 모든 frame의 예측 결과를 구하기 위해 sliding window strategy를 사용해야 하며, inference speed가 느립니다. 저자들이 제안하는 LoCoNet은 parallel inference strategy를 채택했으며, 빠른 inference speed를 보여주면서도 speaker 간 상호작용을 효과적으로 고려합니다.
Context Modeling
ASD는 intra-speaker와 inter-speaker context 모두 활용할 수 있습니다. TalkNet은 speaking과 non-speaking을 구분하기 위해 long-term temporal intra-speaker context를 modeling 합니다. ASC는 long-term inter-\intra-speaker modeling을 위해 self-attention을 사용하고, long-term temporal refinement를 위해 LSTM을 사용합니다. ASDNet은 target speaker의 short-term feature와 근처 frame의 background speaker를 aggregate 하고, Bidirectional GRU을 사용하여 long-term temporal modeling을 수행합니다. Light-ASD는 temporal modeling을 위해 Bidirectional GRU을 사용합니다. MAAS, EASEE, SPELL은 visual node와 audio node 사이 관계를 modeling 하기 위해 Graph Convolutiional Network를 사용합니다.
저자들이 제안한 LoCoNet은 Long-Short Context Modeling (LSCM)을 사용하는데, 이는 Long-term Intra-speaker Modeling (LIM)과 Short-term Inter-speaker Modeling (SIM)을 교차적으로 결합합니다. LIM은 self-attention을 사용하여 long-term temporal dependency를 capture 하고, cross-attention을 사용하여 audio-visual interaction을 capture 합니다. SIM은 speaker의 interaction을 학습하기 위해 inter-speaker convolutional block을 통합합니다.
Training mechanisms
긴 video로 학습하는 것은 memory를 많이 사용하므로, 일부 이전 연구들에서는 multi-stage training mechanism을 사용했었습니다. short-term feature extractor를 먼저 학습한 후, 순차적으로 long-term context modeling network가 pre-trained feature extractor으로 추출된 feature를 추출할 수 있도록 학습합니다. TalkNet, EASEE, UniCon, light-ASD, ASD-transformer, ADENet은 end-to-end training을 사용하여 model의 학습 능력을 최대한 활용합니다. 비슷하게 저자들의 LoCoNet도 end-to-end 방식으로 학습되며, audio visual feature representation learninig과 context modeling을 동시에 최적화합니다.
LoCoNet
stacked visual face track V ∈ R^{S x T x H x W x 1}과 audio mel-spectrogram A ∈ R^{4T x M}이 주어지면, LoCoNet은 각 frame에서의 target persion의 speaking activity R^ ∈ R^{T}를 예측하는 것을 목표로 합니다. S는 target speaker를 포함한 speaker의 수를 나타내고, S - 1은 동일한 scene의 context speaker 수를 나타냅니다. T는 face track의 temporal length입니다. H는 각 visual face crop의 height, W는 visual face crop의 width를 나타냅니다. M은 audio Mel-spectrogram의 frequency bin입니다.
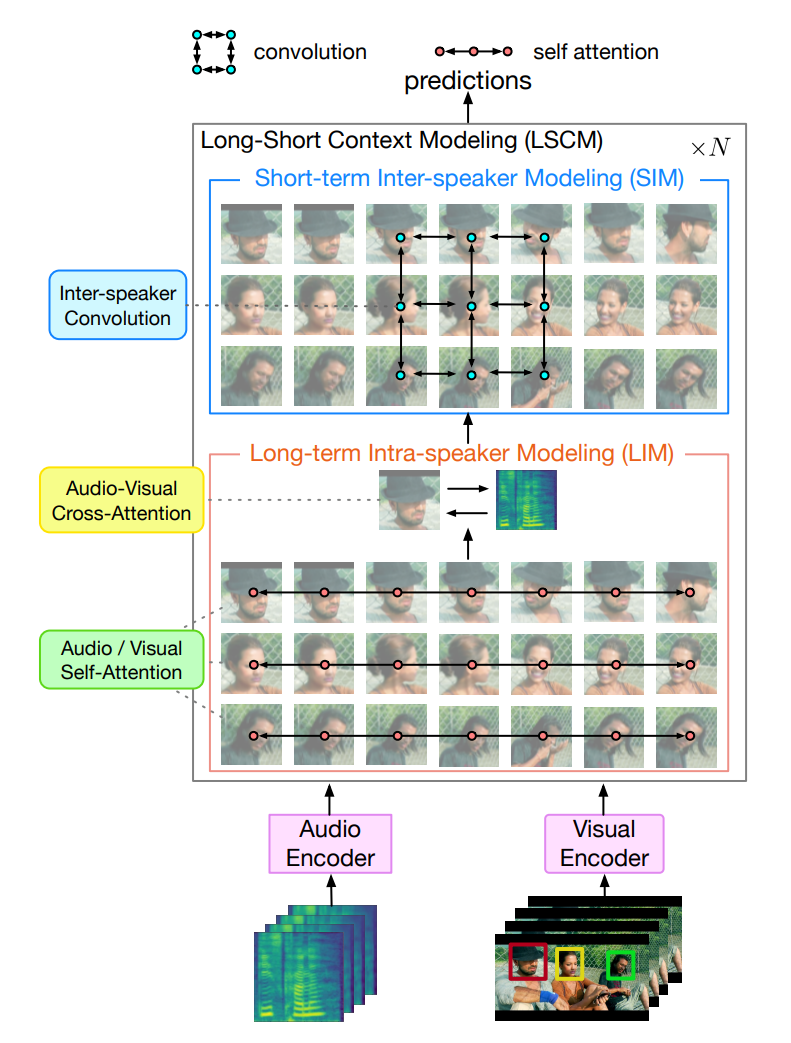
위 그림과 같이, LoCoNet은 visual encoder, audio encoder, N개 LSCM block으로 구성된 Long-Short Context Modeling (LSCM) module로 구성됩니다.
Encoder
- Visual Encoder
speaker v_i에 대한 face crop tack V_i ∈ R^{T x H x W x 1}이 주어지면, visual embedding의 time sequence f_{v_i} ∈ R^{T x C}, i = 1, ... , S를 만듭니다. target speaker의 stacked visual embedding과 모든 sampled context speakers f_v ∈ R^{S x T x C}는 각 speaker의 temporal context를 나타냅니다.
- Audio Encoder
audio encoder는 audio Mel-spectrogram A ∈ R^{4T x M}을 input으로 받습니다. 각 frame의 classification을 위해, frame-level audio feaeture를 필요로 하지만, audio classification을 위해 설계되어 있어 temporal downsampling이 많이 이루어집니다. 이러한 문제를 해결하기 위해, 저자들은 audio encoder로 pretrained VGGish를 사용하는 VGGFrame을 제안합니다. VGGFrame의 구조는 다음과 같습니다.

저자들은 block-4 뒤에 있는 temporal downsampling layer를 제거했으며 deconvolutional layer를 추가하여 temporal dimension까지 upsample 했습니다. 저자들은 중간 feature를 upsampled feature와 concatenate 하여 계층적 표현을 추출합니다. VGGFrame은 audio embedding f_{a_i} ∈ R^{T x C}를 output 합니다. S명의 speaker와 align을 위해, f_{a_i}를 S번 반복하여 audio embedding f_a ∈ R^{S x T x C}를 생성합니다.
Long-Short Context Modeling
visual embedding과 audio embedding은 각각 visual encoder와 audio encoder를 이용하여 따로 구해지며, intra/inter-speaker context에 대한 고려가 부족합니다. 저자들의 Long-Short Cotext Modeling (LSCM)은 long-term intra-speaker와 short-term inter speaker context를 번갈아가며 학습함으로써 embedding들을 향상시키도록 design 되었습니다.

위 그림과 같이, LSCM은 Long-term Intra-speaker Modeling (LIM) module과 Short-term Inter-speaker Modeling (SIM) module을 통합하는 N개 block으로 구성됩니다. LIM은 model이 모든 frame에 걸쳐 동일한 speaker를 보도록 제한을 두며 audio and visual interaction으로부터 speaker-independent pattern을 학습하도록 만듭니다. 대조적으로, SIM은 model이 가까운 frame에 있는 모든 speaker에 대해 조사하도록 제한하고 local interaction을 capture 하도록 제한합니다. 이러한 inductive bias는 이러한 contextual dimension으로부터 valuable insight를 얻을 수 있는 model의 capacity를 향상시키는데 중요한 역할을 합니다.
LSCM은 audio embeding f_a와 visual embedding f_v를 input 하며 context-aware embedding u_a^N, u_v^N ∈ R^{S x T x C}를 생성합니다. 이러한 embedding들을 concatenate 하여 최종 embedding u^N = concat(u_a^N, u_v^N)을 생성합니다. linear layer를 통해 u^N은 target person의 speaking activity를 예측하는 데 사용됩니다. 각 LSCM block의 연산 과정은 다음과 같습니다.
- Long-term Intra-speaker Modeling (LIM)
LIM은 두 가지 submodule로 구성됩니다. 1) Audio/Visual Self-Attention은 더 긴 시간 동안 개인의 행동을 modeling 합니다. 2) Audio-Visual Cross-Attention은 audio and visual embedding 사이 interaction을 학습합니다.
- Audio/Visual Self-Attention
model은 long-term dependency를 학습하기 위해 large capacity를 필요로 하기 때문에, 저자들은 long-term modeling을 수행하기 위해 temporal dimension에 Transformer layer를 사용하는 attention mechanism을 사용했습니다.

u_v^0 = f_v, u_a^0 = f_a, u_v^{l-1} ∈ R^{S x T x C}는 이번 LSCM block의 visual embedding output이고, LN()은 Layer Normalization을 나타내며, MHA(q, k, v)는 query q, key k, value v를 사용하는 multi=head attention이고 MLP는 multi-layer perceptron입니다. Audio Self-Attention은 동일한 방식으로 audio output을 생성합니다.
- Audio-Visual Cross-Attention
visual and audio stream은 완전히 분리되어 처리됩니다. audio를 사용하여 visual feaeture를 향상시키고, visual를 사용하여 audio feature를 향상시키기 위해, 저자들은 Audio-Visual dual Cross-Attention을 사용합니다.

위 식에서 u_v는 audio-enhanced visual embedding입니다. visual enhanced audio embedding u_a는 Audio-Visual Cross-Attention을 사용하여 동일한 방식으로 구해집니다.
- Short-term Inter-speaker Modeling (SIM)
video에 대해 주어진 moment에 대해, target person의 speaking activity는 인접한 frame에 있는 다른 speaker와 더 밀접하게 조정됩니다. 그렇기 때문에 model은 local temporal inter-speaker relationship을 capture 해야 합니다. 이를 위해, 저자들은 small Inter-speaker Convolution Network를 사용합니다.

visual embedding u_v, audio embedding u_a는 l번째 LSCM block의 output이며, 이는 다음 block으로 pass 됩니다. k는 receptive field의 temporal length를 나타내고, s는 고려해야 하는 speaker 수를 나타냅니다. 인접한 frame에서 명시적으로 inter-speaker context를 modeling 함으로써, cross-frame inter-speaker information exchange가 가능해집니다. short temporal receptive field를 사용하는 저자들의 SIM module은 interaction에서 local dynamic pattern을 capture 하는데 도움을 줄 수 있습니다.
Training and Inference
저자들은 multiple supervision u^N ∈ R^{S x T x 2C}와 LSCM의 각 중간 block에서 얻어진 u^i를 사용하여 model을 학습합니다. 각 u^i는 fully-connected (FC) layer를 통해 얻어지며, 각 frame에서의 target speaker의 prediction resutl를 얻는 데 사용됩니다. 전체 loss function은 cross entropy입니다. inference 할 때는 visual encoder에서 추출된 speaker feature를 다시 사용하여 연산량을 줄일 수 있습니다.
Implementation details
저자들의 visual encoder는 3D convolutional layer, ResNet-18, visual temporal convolution network (V-TCN)으로 구성됩니다. 저자들의 audio encoder는 AudioSet으로 pretrain 된 weight를 가지는 VGGish로 초기화된 VGGFrame으로 구성됩니다. 저자들은 S = 3, T = 200 frame으로 sample을 수행했습니다. SIM의 s = 3이며, k는 7개 frame입니다. face crop은 112 x 112로 resize 됩니다. visual augmentation은 randomly resized cropping, horizontal flipping, rotation을 사용합니다. audio augmentation의 경우, training set에서 random 하게 audio signal을 선택하고 target audio에 대한 noise로 더했습니다.
Results and Analysis
저자들은 LoCoNet을 이전 SOTA method들과 여러 dataset에서 비교를 수행했습니다. 그리고 저자들의 가설인 long-term intra-speaker and short-term inter-speaker modeling을 입증했습니다.
Comparison with State-of-the-Art
- AVA-ActiveSpeaker

위 표를 보면, end-to-end method가 multi-stage method보다 더 적인 FLOPs을 사용하지만 경쟁력 있는 mAP를 유지합니다. LoCoNet은 95.2% mAP를 달성했으며, 이는 가장 좋은 성능의 end-to-end ASD method입니다. 그리고 SPELL+보다 0.3% 더 나은 성능을 보여주며 32% 더 적은 parameter를 사용하고 32배 더 적은 average-FLOPs으로 동작합니다.
Challenging Scenario Evaluation
- Quantitative analysis
저자들은 서로 다른 얼굴 크기를 가진 AVA-ActiveSpeaker에 대한 LoCoNet의 성능을 평가했습니다: 1) Small: face width가 64 pixel보다 작음, 2) Medium: face width가 64~128 pixel 사이, 3) Large: face width가 128 pixel보다 큼. 저자들은 video frame에서 볼 수 있는 face 수에 대한 영향에 대해서도 연구를 진행했습니다 (1, 2 or 3).

위 표를 통해 실험 결과를 확인할 수 있습니다. LoCoNet은 일관성 있게 모든 scenario에 대해 가장 좋은 성능을 달성했으며, multi-speaker case라는 어려운 상황에서도 상당한 성능 향상을 이끌었습니다. 이를 통해 저자들의 method가 효과적으로 target speaker의 speaking pattern과 context speaker의 interaction을 modelling 할 수 있다는 것을 보였으며, target person의 speaking activity에 대한 inference 정확도를 향상시킬 수 있습니다.
- Qualitative analysis

위 그림은 AVA-ActiveSpeaker에 대한 LoCoNet 결과, TalkNet 결과와 ground-truth를 비교했습니다. 왼쪽 video의 경우, 4명 speaker talking이며, active speaker를 구분하는 데 어려운 case입니다. LoCoNet은 정확하게 active speaker를 locate 할 수 있었지만, TalkNet은 recognize 하는데 실패했습니다. 오른쪽 video의 첫 2개 열은 매우 작은 얼굴 크기의 여성 speaker이며, 더 큰 face를 가진 남성은 speaking 하지 않습니다. TalkNet은 active speaker를 locate 하지 못하지만, LoCoNet은 성공했습니다. 저자들의 model이 각 개인의 speaking pattern을 비교하기 위한 long-term intra-speaker context와 대화를 검사하기 위한 short-term inter-speaker context를 결합함으로써, 저자들의 approach가 어려운 speaking scenario를 잘 극복한 것을 볼 수 있습니다. 하지만 마지막 열에서는 두 method 모두 뒤에 있는 speaker를 인식하지 못했습니다. 두 speaker 가 서로 다른 대화를 하고 있고, 한 명의 speaker가 상대적으로 덜 눈에 띄는 상황이에서 덜 눈에 띄는 speaker의 발화를 추론하기 어렵기 때문에 이와 같은 결과가 발생되었습니다.
Attention visualizations of LIM and SIM

Long-term Intra-speaker Modeling (LIM)과 Short-term Inter-Speaker Modeling (SIM)의 효과를 visualize 한 결과는 위와 같습니다. LIM에서 single speaker의 다른 frame들에 대한 attention weight를 visualize 한 결과는 왼쪽과 같습니다. 이를 통해 speaking and non-speaking activity는 잘 구분되며, 명확한 경계가 생긴다는 것을 알 수 있습니다. 이를 통해 LIM이 speaking activity detection의 정확성에 기여한다는 것을 입증합니다. 오른쪽 부분은 target speaker가 있는 target frame에서 인접한 frame의 모든 sepaker로부터 얻은 information을 시각화한 것입니다. 왼쪽 여성은 그녀의 얼굴을 점차 target speaker로 돌리며, 이는 target speaker가 speaking을 시작했다는 가장 명백한 sign입니다. 이러한 정보 flow의 분포는 context speaker의 행동으로부터 SIM은 추론을 수행하며, 왼쪽 여성에게 더 많이 attention을 하는 것을 알 수 있습니다.
Conclusion
이 논문에서 저자들은 long-term intra-speaker context와 short-term inter-speaker context로부터 추론하는 것이 더 효율적이라는 것을 입증했습니다. 그래서 저자들은 self-attention과 cross-attention mechanism을 사용하여 long-term intra-speaker context을 modeling 하고, convolution network를 사용하여 short-term inter-speaker context를 modeling 하는 end-to-end long-short context ASD framework를 구현했습니다.



