https://arxiv.org/abs/2010.01057
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entiti
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Entity representation은 entity가 포함된 자연어 처리 task에서 유용합니다. 이 논문에서는 bi-directional transformer를 기반으로 하는 단어와 entity에 대한 새로운 pre-trained contextualized representation을 제안합니다. model은 주어진 text에 있는 word와 entity를 독립적인 token으로 다루고, 문맥화된 representation을 output 합니다. 저자들의 model은 BERT의 masked language model을 기반으로 하는 새로운 pretraining task를 사용하여 학습됩니다. 해당 task는 random 하게 masking 된 단어와 entity를 예측하는 것을 포함합니다. 이때 Wikipedia에서 구한 large entity-annotated corpus를 사용합니다. 그리고 저자들은 entity-aware self-attention mechanism을 제안합니다. 이는 transformer의 self-attention mechanism을 attention score를 계산할 때 token의 type (word or entity)도 고려하도록 확장된 version입니다. 제안된 model은 광범위한 entity-related task에서 명시적으로 눈에 띄는 성능을 보여주었습니다.
Introduction
많은 자연어 처리 task들은 entity를 포함합니다. 이러한 entity 관련 task를 해결하기 위한 key는 entity의 효과적인 representation을 학습하는 model입니다. 기존의 entity representation은 각 entity를 고정된 embedding vector로 할당하여 knowledge base의 정보를 저장하는 방식입니다. 이러한 model들은 KB에 있는 풍부한 정보를 저장하지만, text에 있는 entity를 나타내기 위해 entity linking을 필요로 하며 KB에 존재하지 않는 entity를 나타내지 못합니다.
대조적으로 BERT와 ROBERTa와 같은 trasnformer 기반 contextualized word representation (CWRs)은 language modeling 기반 unsupervised pretraining task로 학습된 효과적인 general-purpose word representation을 제공합니다. 많은 연구들은 CWRs기반으로 entity의 contextualized representation을 사용하여 entity 관련 task를 해결했습니다. 하짐나 CWRs의 구조는 다음 2가지 원인으로 entity를 표현하기 적합하지 않습니다: 1) CWRs span-level entity representation을 output 하지 않기 때문에, 일반적으로 크기가 작은 downstream dataset에 의존하여 representation을 학습합니다. 2) 많은 entity 관련 task들(e.g., relation classification, QA, ...)은 entity 간의 관계를 추론하는 것을 포함합니다. transformer은 self-attention mechanism을 여러 번 사용하여 각 단어 사이 복잡한 관계를 capture 할 수 있지만, entity가 다양한 token으로 나눠지기 때문에 entity 사이 관계를 추론하기엔 어렵습니다. 게다가 CWR에 대한 word-based pretraining task는 entity representation을 학습하기에 적합하지 않습니다. 왜냐하면 pretraining task는 entity에서 다른 단어들을 가지고 masked word를 예측하도록 학습되며, 이는 전체 entity를 예측하는 것보다 쉽습니다.
이 논문에서 저자들은 LUKE (Language Understanding with Knowledge-based Embeddings)를 개발하여 단어와 entity의 새로운 pretrained contextualized representation을 제안합니다. LUKE는 Wikipedia로부터 대규모 entity-annotated corpus를 가져와 사용하여 학습된 transformer 기반 입니다. LUKE와 존재하는 CWRs 사이 중요한 차이점으로, LUKE는 단어뿐만 아니라 entity도 독립적인 token으로 다루며 transformer를 사용하여 중간과 마지막 representation을 계산합니다. entity를 token으로 다루기 때문에, LUKE는 entity 사이 관계를 직접적으로 modeling 할 수 있습니다.
LUKE는 BERT's masked language model을 간단하게 확장하여 새로운 pretraining task를 사용해 학습됩니다. task는 random하게 masking 된 entity를 [MASK]로 대체하고, model이 해당 masked entity를 예측하도록 학습됩니다. 저자들은 RoBERTa를 base pre-trained model로 사용하고, MLM objective와 저자들이 제안한 task를 동시에 최적화하여 model을 pretrain 합니다. downstream task에 사용되면, model은 [MASK] entity를 input으로 사용해 text에 있는 임의의 entity에 대한 representation을 계산할 수 있습니다. 그리고 만약 entity annotation을 task에서 사용할 수 있다면, model은 풍부한 entity-centric information을 기반으로 entity representation을 구할 수 있습니다.
이 논문의 또 다른 key contribution은 entity-aware self-attention mechanism을 사용하여 transformer를 확장한 것입니다. CWRs와 다르게, 저자들의 model은 단어와 entity라는 두 가지 종류의 token을 다룹니다. 그래서 저자들은 token의 종류를 쉽게 선택할 수 있도록 mechansim을 만드는 것이 좋을 것이라고 생각했습니다. 이를 위해 저자들은 다른 query mechanism을 채택하여 self-attention mechanism을 향상시켰습니다.
저자들은 5가지 standard entity-related task (entity typing, relation classification, NER, cloze-style QA, extractive QA)에 대한 실험을 진행하여 model의 효율성을 입증했습니다. 저자들의 model은 모든 baseline model보다 뛰어난 성능을 보였습니다. main contribution은 다음과 같이 요약할 수 있습니다.
- entity 관련 task를 해결하기 위해 설계된 새로운 contextualized representation인 LUKE를 제안합니다. LUKE는 Wikipedia에서 얻은 대규모 entity-annotated corpus를 사용하여 random 하게 masking 된 단어와 entity를 예측하도록 학습됩니다.
- 저자들은 entity-aware self-attention mechanism을 제안하며, 이는 transformer의 original mechanism을 효과적으로 확장한 방식입니다. 이는 token의 종류(단어 또는 entity)를 고려하여 attention score를 계산합니다.
- LUKE는 명시적으로 뛰어난 성능을 달성했으며 5가지 유명한 dataset (Open Entity, TACRED, CoNLL-2003, ReCoRD, SQuAD 1.1)에서 SOTA를 달성했습니다.
Related Work
Static Entity Representation
conventional entity representation은 KB에 있는 각 entity를 고정된 embedding으로 할당합니다. knowledge graph로 학습된 knowledge embedding과 KB에서 할당된 textual context 또는 description을 사용해 학습된 embedding이 포함됩니다. 저자들의 pretraining task와 유사하게, NTEE와 RELIC은 KB로부터 얻어진 entity의 textual context에 맞춰 entity를 예측하는 방식으로 entity embedding을 학습합니다. 이러한 학습 방식의 주요 단점은 text에서 entity를 표현하기 위해 entity를 KB에 있는 항목으로 연결해야 한다는 점과 KB에 없는 entity는 표현할 수 없다는 점입니다.
LUKE

위 그림은 LUKE의 구조입니다. model은 multi-layer bidirectional transformer를 사용합니다. document에 있는 단어와 entity를 input token으로 다루며, 각 token의 representation을 계산합니다. m개 단어 w_1, ... , w_m와 n개 entity e_1, ... , e_n가 주어지면, 저자들의 model이 D차원 단어 representation h_{w1}, ... , h_{wm}, h_w ∈ R^D과 entity representation h_{e1}, ... , h_{en}, h_e ∈ R^D를 계산합니다. entity는 Wikipedia entity나 special entity가 될 수 있습니다.
Input Representation
token (단어나 entity)의 input representation은 다음 3가지 embedding을 사용하여 구해집니다.
- Token Embedding
token embedding은 대응하는 token을 표현합니다. word token embedding A ∈ R^{V_w x D}, V_w는 vocabulary에 있는 단어 수를 나타냅니다. 연산 효율성을 위해, 저자들은 B와 U라는 작은 matric으로 분해하여 entity token embedding을 표현했습니다. B ∈ R^{V_e x H}, U ∈ R^{H x D}이고, V_e는 vocabulary에 있는 entity 수를 나타냅니다. BU 연산을 수행하여 full entity token embedding을 구할 수 있습니다.
- Position embedding
position embedding은 word sequence에서의 token 위치를 나타냅니다. C_i ∈ R^D는 i번째 단어를 나타내고, D_i ∈ R^D는 i번째 entity를 나타냅니다. 만약 entity name이 여러 단어를 포함하고 있다면, position에 맞춰 averaging embedding을 구해 position embedding으로 사용합니다.
- Entity type embedding
entity type embedding은 token이 entity입니다. embedding은 single vector e ∈ R^D입니다.
단어 input representation은 token embedding과 position embedding을 더해 구해지며, entity input representation은 entity type embedding, token embedding, position embedding을 더해 구해집니다. 저자들은 과거 연구와 같이, special token인 [CLS]를 word sequence의 첫 부분에 넣고, [SEP]를 마지막 단어에 넣습니다.
Entity-aware Self-attention
self-attention mechanism은 transformer의 기초이며, 각 token pair 사이 attention score를 기반으로 각 token을 relate 합니다. D차원 input vector x_1, ... , x_k가 주어지면, 각각에 대한 L차원 output vector y_1, ... , y_k가 계산되는데, 이는 변환된 input vector의 weighted sum을 기반으로 구해집니다. 단어나 entity를 token으로 나타내며 각 input and output vector는 해당 token에 대응하는 vector입니다. 저자들의 model의 경우, k = m + n이며, i번째 output vector y_i는 다음과 같이 구해집니다.

Q ∈ R^{L x D}는 query, K ∈ R^{L x D}는 vector, V ∈ R^{L x D}는 value matrix을 나타냅니다.
LUKE는 단어와 entity라는 두 가지 종류의 token을 다루기 때문에, 저자들은 attention score (e_{ij})를 계산할 때, target token type에 대한 정보를 사용하는 것이 긍정적인 영향을 끼칠 것이라고 생각했습니다. 그래서 저자들은 entity-aware query mechanism을 적용한 발전된 mechanism을 제안합니다. 이는 x_i, x_j의 가능한 token type pair에 맞춰 다른 query matrix를 사용합니다. attention score e_{ij}를 나타내면 다음과 같습니다.
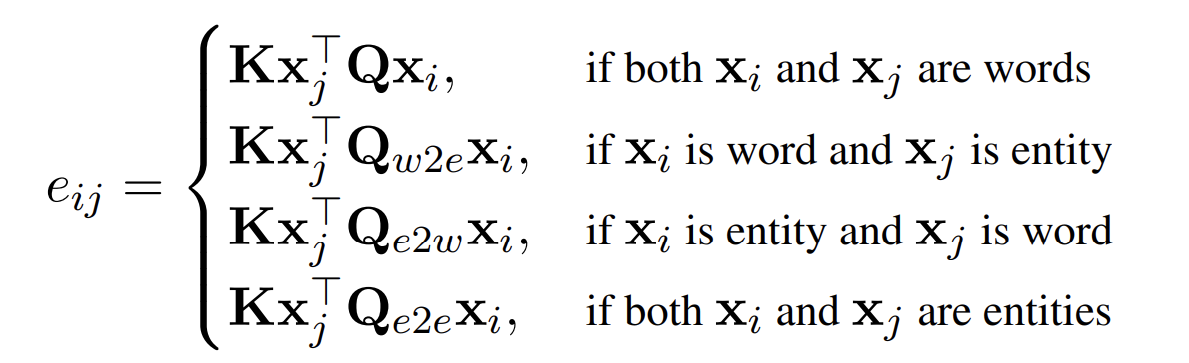
Q_{w2e}, Q_{e2w}, Q_{e2e} ∈ R^{L x D}는 query matrix입니다. 학습 과정에서 original mechanism과 저자들의 mechanism의 연산량은 동일하지만, 학습 과정에서 추가된 query의 기울기 계산 및 parameter update로 인한 추가적인 cost가 발생합니다.
Pretraining Task
LUKE을 pretrain 하기 위해, 저자들은 conventional MLM을 사용하고 entity representation도 학습할 수 있도록 MLM을 확장한 새로운 pretraining task를 사용합니다. 특히 Wikipedia에 있는 hyperlink를 entity annotation으로 다루고 Wikipedia에서 수집한 대규모 entity annotated corpus를 사용하여 model을 학습합니다. 즉 예를 들어 "steve jobs"라는 단어에 hyperlink가 걸려있다면, 이를 entity annotation으로 사용한다는 뜻입니다. 특정 비율로 special [MASK] entity를 사용하여 entity를 random 하게 masking 하고, model이 해당 masked entity를 예측할 수 있도록 학습시킵니다. 기존 masked entity의 corresponding은 vocabulary에 있는 모든 entity에 대해 softmax function을 적용하여 예측하는 방식이었습니다.

h_e는 masked entity에 대응하는 representation이고, T ∈ R^{H x D}와 W_h ∈ R^{D x D}는 weight matrix이고, b_o ∈ R^{V_e}와 b_h ∈ R^D는 bias vector를 나타내며, gelu는 activation function이고, layer_norm은 layer normalization function을 의미합니다. final loss는 MLM loss와 cross-entropy loss를 더해 구성됩니다.
Modeling Details
저자들의 model은 RoBERT_A_{LARGE}를 따르며, bi-directional transformer와 BERT의 variant를 기반으로 한 pretrained CWRs을 사용합니다. D = 1024 hidden dimension, 24 hidden layer, L = 64 attention head dimension, 16 self-attention head로 구성된 bi-directional transformer를 기반으로 합니다. entity token embedding의 dimension H = 256으로 설정했습니다. 총 parameter 수는 약 483M 개이고, 355M는 RoBERTa의 parameter, 128M은 entity embedding에서 사용됩니다. input text는 RoBERTa's tokenizer를 사용하여 tokenize 됩니다. 이때 vocabulary V_w = 50k 개 단어로 구성됩니다. 연산 효율성을 위해, 저자들의 entity vocabulary는 모든 entity를 포함하지 않으며, 가장 자주 등장하는 entity annotation들만 사용하여 V_e = 500k vocabulary를 구성했습니다. entity vocabulary는 2가지 special token [MASK], [UNK]도 포함합니다.
model은 random 한 순서로 Wikipedia page를 200K 번 반복하여 학습됩니다. 학습 시간을 줄이기 위해, RoBERTa를 사용하여 LUKE의 transformer parameter와 word embedding을 초기화했습니다. 과거 연구를 기반으로 저자들은 15%를 masking 했습니다. 만약 entity가 vocabulary에 존재하지 않는다면, [UNK] entity를 사용하여 대체했습니다.
Experiments
Relation Classification
문장에서 head entity와 tail entity 사이의 올바른 관계를 결정하는 task입니다. 106,264개 문장과 42개 관계 유형을 포함하는 대규모 dataset인 TACRED dataset을 사용했습니다. 실험 결과는 다음과 같습니다.
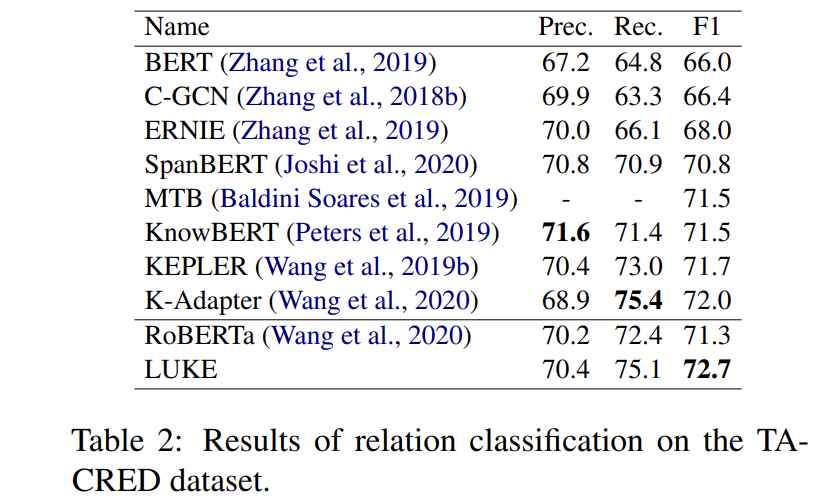
LUKE가 확실히 다른 주요 baseline보다 뛰어난 성능을 보여줍니다.
Named Entity Recognition
저자들은 CoNLL-2003 dataset을 사용하여 NER task에 대한 실험을 진행했습니다.
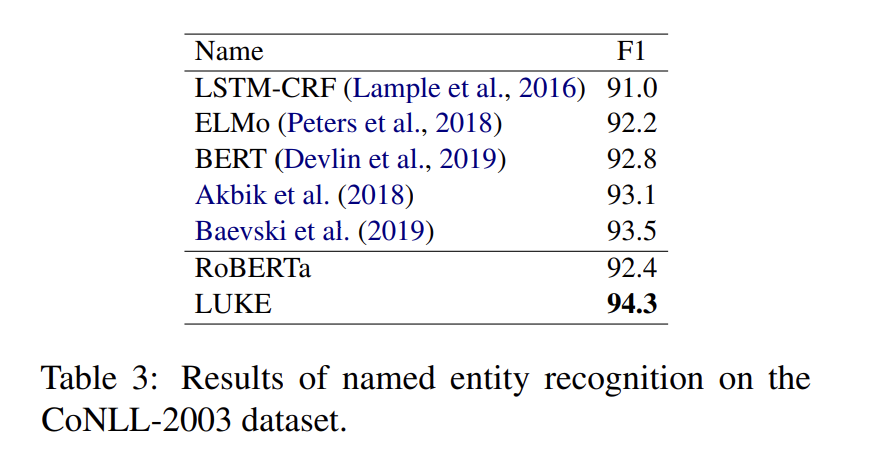
저자들의 mdoel이 새로운 SOTA를 기록했습니다.
Conclusion
이 논문에서는 transformer 기반의 LUKE라는 새로운 pretrained contextualized representation을 제안합니다. LUKE는 발전된 transformer 구조를 사용하여 단어와 entity에 대한 contextualized representation을 output 합니다. 이때 entity-aware self-attention mechanism을 사용합니다. 다양한 dataset에 대한 실험 결과를 통해 저자들의 model 성능을 입증했습니다.



