https://arxiv.org/abs/2211.03019
Hear The Flow: Optical Flow-Based Self-Supervised Visual Sound Source Localization
Learning to localize the sound source in videos without explicit annotations is a novel area of audio-visual research. Existing work in this area focuses on creating attention maps to capture the correlation between the two modalities to localize the sourc
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
명시적인 annotation 없이 video에 있는 sound source를 localizing 하는 걸 학습하는 것은 audio-visual research의 새로운 area입니다. 이 분야를 진행한 연구들은 sound의 source를 localize 하기 위해, 두 modality 사이 연관성을 capture 하도록 attention map을 생성하는데 초점을 맞춥니다. video에서 종종 object의 움직임이 소리를 만들어내기도 합니다. 이 논문에서는 저자들이 video의 optical flow을 prior로 modeling 하여 sound source를 더 잘 localize 하는 데 도움을 주는 방법을 제안합니다. 저자들은 flow-based attention을 추가하는 것이 visual sound source localization 성능을 크게 향상시킨다는 것을 입증합니다.
Introduction
최근 몇 년동안, audio-visual understanding 분야는 매우 활발하게 연구되었습니다. 이는 social media나 기타 platofrm에서 사용자들이 생성한 content video들이 많아졌기 때문입니다. audio-visual understanding에 대한 최근 method는 action recognition, deep-fake detection과 같이 어려운 problem들을 해결하기 위해 유명한 deep learning technique들을 사용하고 있습니다. audio-visual understanding의 한 task는 video가 주어지면 audio content를 생성하는 객체를 visual space에서 찾는 것입니다. 자연스러운 scene을 관측하는 경우, 사람은 소리가 발생하는 영역이나 객체를 localize 하는 것이 종종 쉽습니다. 이러한 주요 이유 중 하나로, 사람의 청각이 binaaaural이라는 점입니다. 하지만 digital media의 대부분 audio-visual data는 monaural이며, audio localization task를 어렵게 만듭니다. 게다가 자연스럽게 생성되는 video들은 image에서 sound source에 대한 location annotation이 명시적으로 존재하지 않습니다. 이러한 이유들이 deep neural network가 audio-visual association을 이해하도록 학습시키는 것을 더욱 어려운 task로 만듭니다.
vision, language, 다른 multi-modal application 분야에서의 self-supervised learning (SSL)의 성공에 힘입어, 최근 sound source localization method들은 annotation이 필요하다는 어려움을 극복하기 위해 SSL based method를 사용하고 있습니다. 어떤 연구에서는 image에서 다양한 공간적 위치에서 audio와 visual representation을 추출하여 둘 사이 cosine similarity를 구하기도 합니다. 이러한 예측된 similarity metric을 기반으로 positive and negative association을 생성하여 self-supervised training을 수행합니다. 이러한 bootstrapping approach는 sound source localization의 성능을 향상시켰습니다.
이 연구 결과를 따라, 최근 대부분의 visual sound source localization approach들은 더 나은 audio-visual association을 위한 robust optimization objective를 생성하는 것에 초점을 맞추고 있습니다. 하지만 상대적으로 작은 주목을 받는 한 가지 흥미로운 측면은 audio와 sound object의 association의 향상을 위한 informative prior를 생성하는 것입니다. prior는 image에서 sound가 생성되었을 수도 있는 잠재적인 영역으로 볼 수 있습니다. 저자들은 이 작업을 two-stage object detection method와 유사하게 볼 수 있다고 말합니다. 여기서 region proposal network가 image space에서 object가 있을 수 있는 region을 식별하는 데 사용됩니다. 하지만 생성된 prior가 multi-modal 관점에서 관련이 있어야 한다는 점에서, sound source localization에 대한 potential candidate region을 생성하는 것은 더 어려운 문제입니다. sound가 발생할 가능성이 있는 지역에 대한 정보가 담긴 prior를 생성하기 위해, 저자들은 optical flow를 사용합니다.
optical flow가 객체의 분명한 움직임에 대한 pattern을 생성할 수 있기 때문에, optical flow를 사용하여 향상된 prior를 생성하려고 시도했습니다. 이는 video에서 움직이는 객체가 sound source인 경우가 많기 때문에 중요합니다. 상대적으로 움직이는 객체를 우선시하는 제약을 적용하면, 더 나은 sound source localization을 생성할 수 있습니다. 이 논문에서는 optical flow-based localization network를 제안하며, 이를 통해 sound source localization을 수행할 때 사용할 수 있는 informative prior를 생성할 수 있습니다. 이 논문의 contribution은 다음과 같습니다.
- 기존 방법에 대한 보완 연구 방향으로서, visual sound source localization을 위한 informative prior 생성의 필요성을 탐구합니다.
- informative prior를 생성하기 위한 추가 information source로서 optical flow의 사용을 제안합니다.
- visual sound source localization을 위해, strong audio-visual association을 형성하는 cross-attention을 사용한 optical flow-based localization network를 design 하였습니다.
- 저자들은 2가지 benchmark dataset인 VGGSound, Flicker Soundnet을 가지고 광범위한 실험을 수행하여 저자들의 method의 효과를 입증합니다. 저자들의 method는 일관성있게 최신 model들보다 뛰어난 모습을 보여줍니다. 엄격한 ablation study를 수행하고 정량적, 질적 결과를 제공하여 저자들의 localization network의 우수성을 보였습니다.
Related Work
joint audio-visual learning을 통해 robust multi-modal representation을 생성하는 것은 활발한 연구 분야입니다. joint audio-visual learning에 대한 초기 연구는 확률적 approach에 중점을 맞췄습니다. 한 연구에서는 audio-visual signal을 multivariate Guassian process로부터 sample 하고 audio-visual 동기화를 두 modality 사이 mutual information으로 정의했습니다. 또 다른 연구에서는 두 modality 사이 mutual information을 maximize 하는 lower-dimensional subspace를 학습하는 것에 초점을 맞췄습니다. 그리고 non-parametric density estimator를 사용하여 audio-visual signal 사이 relationship을 탐구했었습니다. 또 다른 연구에서는 객체의 움직임에 대한 속도와 가속도를 visual feature로 사용하여 audio를 관련된 visual feature과 연관시키는 spatio-temporal segmentation mechanism을 제안했습니다. 최근 몇 년 동안, deep learning based method들이 더 나은 bimodal representation을 생성하기 위한 연구에 사용되었습니다. 주로 각 modality를 각각 encode 하는 two-stream network를 사용하고 contrastive loss-based supervision을 사용하여 두 representation을 align 하였습니다. 이러한 연구 분야에서 보완적인 방향은 audio-visual association을 위한 더 정보가 있는 prior를 생성하는 것을 탐구하는 것입니다. 이 논문에서는 optical flow를 사용하여 정보가 있는 prior를 생성합니다. audio-visual task에서 optical flow를 사용하는 연구가 있었습니다.
optical flow는 연이은 frame 사이 pixel-wise motion을 추정하는 수단을 제공합니다. 초기 연구에서는 energy minimization problem으로 optical flow prediction을 제시했습니다. optical flow maps은 sparse and dense라는 2가지 type으로 나눌 수 있습니다. sparse optical flow는 frame에서 salient feature의 motion을 나타내고, dense optical flow는 전체 frame에 대한 motion flow vector를 나타냅니다. 초기 sparse optical flow estimation method는 Lucas-Kanade algorithm을 포함합니다. 이는 brightness constasncy equation을 활용하여 flow가 locally smooth하고 인접 pixel의 상대적 displacement가 일정하다는 가정하에 진행됩니다. Farneback은 dense optical flow estimation technique을 제안했으며, 이는 이차 다항식을 사용하여 두 frame의 pixel neighborhood를 근사하고, 이 다항식을 사용하여 global displacement를 계산합니다. FlowNet은 연속적인 frame의 중간 convolutional feature map 간의 statistic cross-correlation을 계산하고, optical flow map을 추출하기 위해 up-scale 하는 첫 CNN based approach입니다.
Method
Problem Statement
audio와 visual modality로 구성된 video가 주어졌을 때, visual sound source localization는 visual modality에서 audio를 생성한 spatial region을 찾는 것을 목표로 합니다. video가 N개 frame으로 구성되어 있다고 하겠습니다. video frame에 해당하는 image를 I∈R^{W_i x H_i x 3}라 표현하고, 해당 video의 audio에 대한 spectrogram을 A∈R^{W_a x H_a x 1}라 표현하겠습니다. 이 상황에서 audio localization은 I에서 A와 매우 연관되고 관련 있는 region을 찾는 것으로 생각할 수 있습니다.

공식으로 나타내면 위와 같습니다. Φ(I;θ_i)는 visual modality에 대한 convolution neural network-based feature extractor를 의미하고, ψ(A;θ_j)는 audio modality에 대한 convolution neural network-based feature extractor를 의미하며, f_v∈R^{m x n x c}는 그에 대응하는 더 낮은 차원의 visual feature map이고 f_a∈R^{m x n x c}는 audio feature map입니다. w는 두 modality 사이 연관성을 찾는 함수이고, P(I, A)는 original image space에서 audio를 생성한 source를 나타내는 region 입니다. feature space에서 original image space의 해당 영역으로 연관성을 추정하는 것(i.e., P(I, A))은 간단합니다. 위에서 언급한 것처럼 feature map이 주어졌을 때, feature representation 사이 연관성을 찾는 방법 중 하나는 다음과 같습니다.

위 식에서 GAP(f_a)는 audio feature map의 global-average-pooled representation을 의미합니다. S는 audio representation과 visual feature map의 각 spatial location 사이 cosine similarity를 나타냅니다. 여기서 m은 feature map의 width, n은 feature map의 heigth를 나타냅니다. 만약 audio-visual correspondence에 대한 positive and negative region을 나타내는 ground-truth로부터 생성된 binary mask M∈R^{m x n x 1}를 사용할 수 있다면, learning objective를 supervised setting으로 다음과 같이 설정할 수 있습니다:
frame I_k, audio A_k로 이루어진 sample k가 주어진다면, positive and negative는 다음과 같이 정의할 수 있습니다.

S_{k→k}는 I_k와 A_k에 대한 cosine similarity를 나타냅니다. S_{k→j}는 image와 audio가 동일한 video에서 추출된 것이 아닐 때의 cosine similarity를 나타냅니다. <>는 내적을 의미합니다. 최종 learning objective는 다음과 같이 됩니다.

Self-Supervised Localization
대부분의 real-world scenario에서는 binary mask M을 생성할 때 필요한 ground truth는 존재하지 않습니다. 그렇기 때문에 명시적인 ground truth annotation에 의존하지 않는 training objective가 필요합니다. 이러한 objective를 위해, 생성된 pseudo mask를 가지고 ground truth mask를 대체하는 방법이 있습니다. pseudo mask는 threshold를 기반으로 similarity matrix S를 binarizing하여 생성할 수 있습니다. 더 구체적으로, S_{k→k}가 주어지면 pseudo mask는 다음과 같이 작성할 수 있습니다.

위 식에서 ε는 scalar threshold를 나타냅니다. σ는 sigmoid function을 의미하고, 이를 통해 threshold보다 작거나 같은 값은 0으로 만들어주고 그 외의 경우엔 1으로 만들어 줍니다. τ는 sharpness를 control 할 수 있는 temperature입니다. 추가적으로 잠재적인 noisy association을 제거함으로써 pseudo mask를 refine 합니다. positive threshold와 negative threshold를 나누어서 고려하여 수행하면 됩니다. 만약 이 threshold 사이에 값이 존재한다면, 이는 noisy association으로 고려하여 무시하면 됩니다.

위 식에서 ε_p는 positive threshold를 나타내고 ε_n은 negative threshold를 나타냅니다. positive와 negative가 구해지면, 전체 training objective는 식 (4)처럼 됩니다.
만약 학습 초기에 생성된 pseudo mask가 ground truth와 비슷하다면, 예측을 bootstrap하여 self-supervision learning을 수행하는 것이 논리적입니다. 하지만 각 modality에 대한 feature extractor가 random 하게 초기화되기 때문에 위처럼 논리적인 것을 보장하지 못합니다. feature extractor라 학습되지 않았기 때문에 self-supervised training 초기에 similarity matrix S_{k→k}의 high or low value가 informative positive or negative region을 나타내지 않을 수 있습니다. 만약 feature extractor나 classificiation task에 맞춰 pretrained weight로 초기화한다면, network는 image의 object에 반응할 것입니다. 이러한 특성을 object-centric prior로 고려할 때, frame에서 가장 눈에 띄는 객체가 소리를 생성하는 경우가 많기 때문에, self-supervised sound localization에 유용할 수 있습니다. 하지만 audio의 source가 frame에서 가장 눈에 띄는 객체가 아닌 경우가 있습니다. 이는 최적화되지 않은 similarity S_{k→k}을 생성할 것이며, self-supervised training의 최적화되지 않은 성능으로 이어질 것입니다. 결과적으로 self-supervised learning을 향상시키기 위해 audio-visual assolication을 개선하고 더 의미가 있는 prior를 구성할 필요가 있습니다.
Optical-Flow Based Localization Network
저자들은 object detection viewpoint로 이 문제를 접근했습니다. R-CNN, Fast R-CNN과 같이 초기 object detection은 selective search를 region proposal을 생성하기 위한 method로 사용했습니다. selective search는 관심 객체가 있을 가능성이 있는 위치 집합을 제공합니다. selective searech 기반 approach의 대안으로 two-stage approach가 있으며, 이는 region proposal network를 사용합니다. 대부분의 region proposal network는 잠재적인 object가 포함될 영역을 생성하기 위해 auxiliary training objective를 사용합니다. self-supervised setting에 potential region을 생성하기 위한 objective를 사용하는 것은 어렵습니다. 그리고 visual modality만 의존하여 selective search나 regular region proposal network를 사용하여 후보 region을 생성하는 것은 visual sound source localization과 같은 cross-modal task의 prior에 적합하지 않을 수 있습니다.
더 나은 대안으로, 저자들은 informative localization proposal을 생성하는 optical flow를 사용합니다. video의 frame을 사용하는 optical flow는 움직이는 객체를 효과적으로 capture 할 수 있습니다. 대부분의 경우, 이러한 객체들이 sound의 source입니다. pixel space에서 optical flow를 capture하는 것은 audio-visual association을 향상시키기 좋은 prior가 될 수 있습니다. 그리고 optical flow는 두드러진 object보단 객체의 상대적 움직임에 초점을 맞추는 경향이 있기 때문에, 두드러진 object에 초점을 맞추는 pre-trained vision model의 prior를 상호보완할 수 있습니다. 저자들의 network는 다음과 같습니다.

저자들은 두 인접한 두 video frame 사이에서 계산된 optical flow를 받고 audio-visual association을 개선하는 데 prior로 동작하는 feature map f_v에서의 region을 생성하는 network를 설계했습니다. localization network는 image와 flow modality에서 추출된 feature representation 사이 cross-attention으로 구성됩니다. flow feature representation f_f와 visual feature representation f_v가 주어지면, 이 feature representation을 분리된 projection layer를 사용하여 K_v, Q_f를 생성합니다. β는 두 vector K_v, Q_f의 channel dimension에 따라 외적으로 구해집니다.

softmax function은 attention matrix를 정규화하기 위해 최종 dimension에 적용됩니다. 목표는 각 공간적 위치에 적용될 attention을 계산하여 각 공간적 위치에 대해 d x d 크기 cross attention matrix를 생성하는 것입니다. 저자들은 visual modality에서 또 다른 V_v라는 tensor를 계산합니다. V_v에 있는 각 spatial location에 대해, β의 d x d attention matrix와 곱해서 d차원 representation을 얻습니다.

마지막으로 E를 final cross-attented proposal prior E_p로 다시 project합니다. audio-visual association을 위해 이 prior를 impose 하기 위해, 저자들은 E_p를 visual feature map f_v에 더합니다. 향상된 audio-visual association은 다음과 같이 다시 작성할 수 있습니다.

위 식에서 ⊕는 element-wise addition을 나타냅니다. 향상된 audio-visual association을 얻은 후, positive and negative를 게산합니다. 저자들은 전체 network (feature extractor and localization network)를 end-to-end방식으로 식 (4)를 가지고 학습합니다.
Experiments
Evaluation Metrics
이전 연구들과 적절하게 비교하기 위해, 저자들은 정량적 audio localization performance를 평가하기 위해 2가지 metric을 사용합니다: Consensus Intersection Over Union (cIoU)와 Area Under Curve of cIoU scores (AUC). cIoU는 ground-truth annotation과 localization map 간의 교차 영역을 측정하여 성능을 정량화합니다. 여기서 ground-truth는 여러 annotation을 통합한 consensus입니다. AUC는 0에서 1까지의 threshold를 다양하게 설정하여 생성된 cIoU의 curve 아래 면적으로 계산됩니다.
Implementation Details
저자들이 사용한 두 dataset Flickr SoundNet과 VGGSound에 있는 video의 중간 frame과 그 중간 frame을 중심으로 한 3초의 audio를 추출하고 계산된 dense optical flow field를 추출하여 image-flow-audio pair를 구성합니다. image frame의 경우, image를 224 x 224로 resize 하고 random cropping과 horizontal flipping을 수행하여 data augmentation 합니다. middle frame에 대응하는 optical flow field를 계산하기 위해, 저자들은 video V의 middel frame과 그다음 frame (V_t, V_{t+1})을 가져와 Gunnar Farneback algorith을 사용해 수평 및 수직 flow vector를 나타내는 2-channel flow field를 생성합니다. 저자들은 image augmentation과 일관되게 flow field의 random cropping and horizontal flipping을 사용하여 data augmentation 합니다. audio의 경우, 저자들은 3초 길이 video에서 16kHz를 생성하고 log-scaled spectrogram을 구합니다. 그래서 shape는 257 x 300이 됩니다.
ResNet18을 optical flow feature extractor로 사용합니다. 저자들은 visual and flow feature extractor를 ImageNet으로 pretrain하고 audio network은 random으로 초기화합니다. 학습 과정에서는 visual feature extractor parameter를 frozen 합니다.
Qualitative Evaluation

위 그림과 같이, 저자들은 LVS의 sound localizaiton과 저자들의 method를 비교했습니다. 저자들의 method가 정확하게 다양한 sound source type에서 정확하게 localize 되는 것을 볼 수 있습니다. 첫 번째 열을 보면, LVS는 sounding vehicle의 작은 부분만 localize 하지만 저자들의 method는 vehicle 전체를 높은 강도의 flow로 localize 합니다. 다섯번째 열을 보면, 저자들의 method가 경기장의 두 군중을 정확하게 localize합니다.
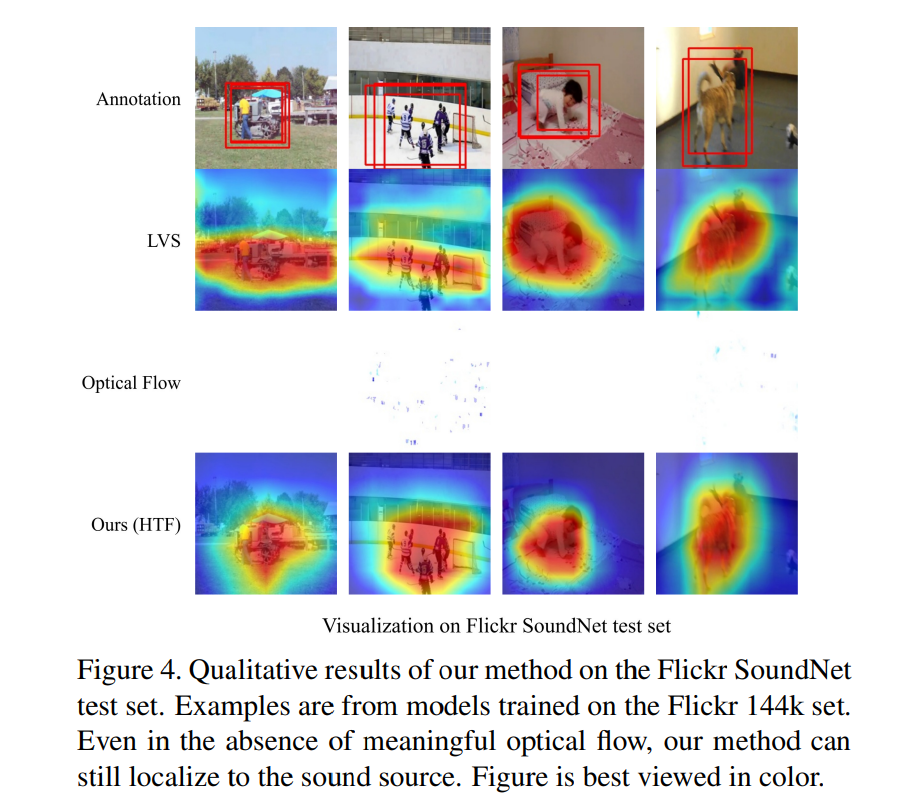
하지만 적은 optical flow가 존재하는 sample을 조사하는 것도 중요합니다. video의 frame에 움직임이 적은 경우도 가능하며, 예를 들어 정지된 차량이나 사람이 소음을 내는 video입니다. 이러한 경우, localize 할 의미 있는 optical flow가 없습니다. 위 그림을 보면, 의미 있는 optical flow가 없더라도 저자들의 method가 LVS와 비교했을 때, 비슷하거나 더 나은 localize를 수행하는 것을 확인할 수 있습니다. 이는 optical flow가 선택적 prior information으로 사용된다는 것을 강화하며, 높은 움직임이 있을 때 이를 사용하여 더 나은 localize를 할 수 있지만, 반드시 필요하지는 않다는 것을 의미합니다.
Conclusion
이 논문에서 저자들은 optical flow를 사용하여 video의 frame에 있는 sound object을 localization 하는 것을 목표로 하는 새로운 self-supervised sound source localization method를 제안합니다. video에서 움직이는 객체는 종종 소리를 만듭니다. optical flow를 prior로 사용하여 self-supervised learning setting에 이점이 있다는 것을 보여줍니다. 저자들은 self-supervised objective를 formulate 하고 video frame에 대응하는 optical flow의 cross-attention mechanism을 설명합니다.



