https://arxiv.org/abs/2211.03089
I Hear Your True Colors: Image Guided Audio Generation
We propose Im2Wav, an image guided open-domain audio generation system. Given an input image or a sequence of images, Im2Wav generates a semantically relevant sound. Im2Wav is based on two Transformer language models, that operate over a hierarchical discr
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 image guided open-domain audio generation system인 IM2WAV를 제안합니다. input image나 image sequence가 주어지면, IM2WAV는 의미적으로 관련 있는 sound를 생성합니다. IM2WAV는 2개 Transformer language model을 기반으로 하며, VQ-VAE 기반 model에서 얻은 계층적 discrete audio representation을 사용합니다. 저자들은 language model을 사용하여 low-level audio representation을 생성합니다. 그다음 추가적인 language model을 사용하여 audio token을 upsample 하여 high-fidelity audio sample을 생성합니다. 저자들은 pre-traiend CLIP (Contrastive Language-Image Pre-training) model embedding의 풍부한 semantic을 language model의 condition인 visual representation으로 사용합니다. 추가적으로 생성 과정을 conditioning image에 맞추기 위해, classifier-free guidance method를 사용했습니다. 결과는 IM2WAV가 baseline보다 fidelity와 relevance evaluation metric에서 훨씬 뛰어나다는 것을 보여줬습니다. image-to-audio model을 더 잘 평가하기 위해, 저자들은 out-of-domain image dataset인 IMAGEHEAR을 제안합니다. IMAGEHEAR는 앞으로 등장할 image-to-audio model의 평가 benchmark로 사용할 수 있습니다.
Introduction
open-domain에서 시각적으로 guide되는 audio를 생성하는 것은 도전적인 task입니다. 대부분의 이전 시도들은 class-aware approach를 사용하여 task를 해결했었습니다. input image가 주어진 audio instance로 class 별 평균 spectrogram represntation에서 delta를 학습하는 방법을 제안하는 연구도 있었습니다. 또 다른 연구에서는 각 clas별로 독립적으로 model을 학습하기도 했었습니다. 비록 이러한 method들이 high-quality generation을 제공하지만, unseen class에 대한 일반화 성능에 제약이 존재하며 labeled data가 있어야 한다는 제약이 존재합니다. 최근에는 SpecVQGAN이라는 model이 제안되었습니다. SpecVQGAN은 pre-determined class set 없이도 여러 class에 대한 visual input을 condition으로 하는 다양한 sound를 생성할 수 있는 단일 model을 기반으로 합니다. pre-trained image classifier로 얻어지는 image representation을 condition으로 사용하여 mel-spectrogram을 생성합니다. 그다음 생성된 mel-spectrogram을 neural vocoder에 넣어 time domain으로 변환합니다.
이 논문에서, natural image로부터 general audio를 생성하는 label-free approahc를 제안합니다. 저자들은 image representation을 condition으로 사용하는 Transformer-based audio Language Model (LM)인 IM2WAV를 제안합니다. input image sequence가 주어지면, IM2WAV는 image sequence에 등장하는 객체와 매우 연관된 audio sample을 생성합니다. IM2WAV는 2가지 main stage로 구성됩니다. 먼저 계층적 VQ-VAE model을 사용하여 raw audio를 discrete sequence token으로 encode 합니다. 두번째 stage에서는 첫번째 stage에서 구한 discrete audi otoken을 가지고 동작하는 autoregressive Transformer language model을 최적화합니다. language model은 pre-trained CLIP model로 얻어진 visual representation을 condition으로 사용합니다. 저자들의 model은 single image 또는 image sequence (video)를 condition으로 사용할 수 있습니다. 추가적으로 classifier free guidance method를 사용하여 더 나은 image adherence를 달성합니다.
저자들은 명시적으로 다양한 metric에서 저자들의 method가 baseline보다 훨씬 뛰어나다는 것을 보였습니다. 저자들은 추가적으로 생성된 audio의 label distribution 분석을 제안하며 제안한 system의 각 구성요소들의 효과를 더 잘 평가했습니다. 저자들의 system은 다음과 같습니다.

Method
이전 연구들에서 영감을 받아, 제안된 system은 3가지 main component로 구성됩니다: 1) audio를 encode하고 discrete representation을 decode하는 audio encoder-decoder, 2) pre-trained image encoder, 3) discrete audio token으로 동작하는 audio language model 입니다.
audio sample x^i와 그에 대응하는 image sequence인 y^i로 구성된 audio-image dataset {x^i, y^i}이 주어졌을 때, 주어진 y^i에 맞춰 audio file을 생성하는 것이 목표입니다. 이를 위해, 저자들은 audio를 lower frequency로 sample 하는 discrete sequence token으로 나타내는 VQ-VAE model을 먼저 학습합니다. 그다음 image representation을 condition으로 사용하고 discrete token으로 동작하는 Transformer decoder language model을 학습합니다. inference time에서 저자들은 Transformer-decoder에서 sampling 하여 input image sequence와 의미적으로 연관된 새로운 token set을 생성합니다.
Audio Encoder & Decoder
저자들은 1차원 hierarchical VQ-VAE architecture를 사용했으며 audio를 discrete space Z로 encode 합니다. VQ-VAE는 encoder E: A → H가 있습니다. encoder E는 x ∈ A를 latent vector h로 encode합니다. bottleneck Q: H → Z은 각각의 h_s를 가장 가까운 vector c_j로 mapping 합니다. 이때 codebook C를 사용합니다. 결과적으로 discrete sequence Z를 얻게 됩니다. 그다음 decoder D: Z → A는 codebook look-up table을 사용하여 latent vector를 다시 time domain signal로 decode 합니다. VQ-VAE는 VQ-VAE loss와 STFT spectral loss를 사용하여 학습됩니다. 저자들은 single encoder와 decoder를 학습하지만, latent sequence h를 multi-level representation으로 나누며, 각각의 codebook을 따로 구현합니다.
Image Encoder
pre-trained CLIP model을 image encoder로 사용했습니다. CLIP model은 대응하는 text-image input 사이의 유사도를 maximize 하도록 학습되었습니다. multi-modal learning에서 얻어지는 의미적 정보를 사용하기 위해서 pre-trained image classification model 대신 CLIP embedding을 사용했습니다. 저자들은 이중 언어를 사용하는 사람이 단일 언어를 사용하는 사람들보다 새로운 언어를 습득할 때 이점이 있다는 가설과 유사하게, multi-modal data를 사용하여 최적화된 encoder를 통해 얻어지는 representation 사용하는 것이 추가적인 modality (audio token)을 modelling 하는 것이 더 쉬울 것이라고 가정합니다. image sequence를 single vector representation으로 변환하기 위해서, 저자들은 시간 축에 따라 추출된 image feature들의 평균을 구하고 3개 MLP layer with ReLU activation에 pass 했습니다.
Sequence Modeling
저자들은 2개 auto-regressive model을 학습합니다. 저자들은 Low와 Up으로 표기하며, 두 가지 다른 time resolution에서 discrete space prior p(z)를 학습합니다. 저자들은 averaged image feature를 condition으로 사용하여 future audio token을 예측하는 auto-regressive Sparse Transformer Decoder causal language model을 사용합니다. 각 time step마다, 현재 token의 positional embedding과 함께 동일한 temporal position에 해당하는 image representation을 Low model의 condition으로 사용합니다. Up model의 경우, 동일한 Transformer 구조를 사용하여 higher resolution Up level token을 reconstruct 합니다. 이때 Low level generated token을 condition으로 사용합니다.
저자들의 objective는 다음과 같이 정의됩니다.

위 식처럼 discrete space에 대한 likelihood를 maximize 하도록 학습됩니다. 위 식에서 \hat{z}는 Low level token이고 f_m은 image representation입니다. 둘 모두 input space와 동일한 temporal position을 갖도록 mapping 됩니다. θ_Low, θ_Up은 Low auto-regressive model과 Up auto-regressive model의 parameter입니다. 직관적으로 Low level은 token마다 더 긴 audio를 encode 하기 때문에, 생성되는 audio의 추상적인 semantic foundation을 결정하지만, Up level은 higher resolution에서 더 세밀한 detail을 완료합니다. 저자들은 임의의 image 수를 input으로 지원하기 위해, 균등 간격의 frame을 가정합니다.
Classifier Free Guidance
생성 성능을 향상시키고 생성 과정을 input image로 조절하기 위해, 저자들은 Classifier-Free Guidance (CFG) method를 사용합니다. 최근에 CFG method를 사용하는 것이 sample quality와 diversity 사이 trade-off를 잘 control 할 수 있는 효과적인 mechanism으로 등장했습니다. 저자들은 CFG를 Low model에만 적용해도 성능이 크게 향상된다는 것을 실험적으로 발견했습니다. inference 할 때, 저자들은 visual condition을 사용한 token과 condition을 사용하지 않은 token을 생성합니다.

위 식에서 η >= 1은 guidance scale을 나타내고 diversity와 quality 사이 tradeoff를 결정해 줍니다. η=3을 사용했습니다.
Experiments
저자들은 out-of-distribution sample에 대한 성능을 평가하기 위해, 추가적으로 인터넷에서 30개 class가 있고, 각 class마다 2~8장 image가 있으며 총 100장 image를 포함하는 IMAGEHEAR를 생성했습니다.
Evaluation Functions
저자들은 생성된 sound를 fidelity (FAD)와 visual condition (KL, Accuracy and Clip-score) 연관성에 대해 평가합니다.
generative image model fidelity를 평가하기 위해 audio domain에서 Frechet Inception Distance (FAD) metric을 사용했으며, 이를 Frechet Audio Distance (FAD)라 부릅니다. FAD는 생성된 분포와 real 분포 사이 distance를 측정합니다. AudioSet으로 pre-train 된 audio classifier를 사용하여 생성된 data와 real data에서 feature를 추출합니다. real extracted feature 분포와 generated extracted feature 분포를 multi-variate normal distribution으로 modelling 합니다. FAD는 두 분포 사이 Frechet distance를 구합니다.

위 식에서 r은 real data distribution, g는 generated distribution입니다.
다음 저자들은 Clip-Score (CS)를 채택합니다. 이는 image-caption 연관성을 평가하는데 매우 효과적입니다. 저자들은 CLIP text encoder를 Wav2Clip model로 대체하며, 이 model은 frozen CLIP image encoder 위에 image-audio contrastive loss를 사용하여 train 된 audio encoder입니다. image와 generated sound를 각 feature extractor에 pass 합니다. 그다음 구해진 feature vector의 cosine similarity 유사성의 기댓값을 scaling factor로 곱합니다. 저자들은 scaling factor를 100으로 사용합니다.
video는 image sequence이기 때문에, 각 image CS는 전체 audio와 독립적으로 계산한 후 CS를 평균화합니다. 더 길거나 의미적으로 복잡한 video를 다룰 때는 모든 image와 audio에 의해 공유되는 의미를 기대할 수 있는 short window에 이 metric을 적용합니다. 평균 대신 median을 사용해 실험했습니다.
마지막으로 저자들은 AudioSet으로 학습된 PaSST audio classifier를 사용하여 527개 class에 대한 분포를 얻습니다. classifier output으로 저자들은 original sample과 generated sample 사이 class distribution에 대한 KL divergence를 구했습니다.
Results
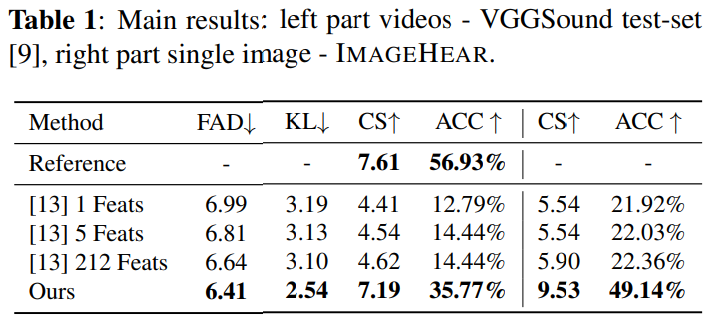
저자들이 제안한 method와 baseline 사이 결과는 위와 같습니다. 저자들이 제안한 method가 baseline보다 fidelity & relevance 측면에서 더 뛰어난 결과를 보여줍니다. 모든 평가 model들은 VGGSound video를 사용했을 때보다 IMAGEHEAR single image를 condition으로 사용할 때 더 좋은 성능을 보여줍니다.

위 결과를 통해 저자들의 model이 SpecVQGAN보다 더 다양한 sound를 생성할 수 있음을 보여줍니다.
Ablation Study

실험 결과는 위와 같습니다. 구체적으로 CFG의 효과, Up model의 효과, 모든 token에서 temporally-corresponding frame을 condition으로 했을 때의 효과를 보여줍니다.
Conclusion
이 논문에서는 IM2WAV이라는 open-domain image-to-audio generation method를 제안합니다. 저자들은 IM2WAV이 fidelity and relevance metric에서 뛰어난 성능을 보인다는 것을 입증했습니다. 그리고 저자들은 IMAGEHEAR라는 image-to-audio model을 평가할 때 사용할 수 있는 out-of-domain benchmark를 제안했습니다.



