https://arxiv.org/abs/2104.08860
CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
Video-text retrieval plays an essential role in multi-modal research and has been widely used in many real-world web applications. The CLIP (Contrastive Language-Image Pre-training), an image-language pre-training model, has demonstrated the power of visua
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Video-text retrieval은 multi-modal 연구에서 중요한 역할을 하며 많은 real-world web application에서 사용되어 왔습니다. image-language pre-training model인 CLIP (Contrastive Language-Image Pre-training)은 web collected image-text dataset으로부터 시각적 concept을 학습하는 power를 입증했습니다. 이 논문에서 저자들은 CLIP model의 knowledge를 video-language retrieval로 transfer 하는 end-to-end 방식 CLIP4Clip model을 제안합니다. 저자들은 다양한 실험을 수행하여 다음과 같은 질문에 대한 조사를 진행합니다. 1) image feature는 video-text retrieval을 수행하기에 충분한가? 2) CLIP 기반 대규모 video-text dataset으로 post-pretraining을 하는 것이 성능에 어떤 영향을 주는가? 3) video frame 사이 시간적 의존성을 modelling 하는 실용적인 방식은 무엇인가? 4) video-text retrieval task의 hyper-parameter에 대한 민감성은 어떠한가? 입니다. 저자들의 실험적 결과는 CLIP에서 transfer 된 CLIP4Clip model이 다양한 video-text retrieval dataset에서 SOTA 성능을 달성했습니다.
Introduction
매일마다 online에 upload 되는 video수가 증가함에 따라, video-text retrieval은 관련 비디오를 효율적으로 찾기 위한 연구들이 중요해지고 있습니다. 실제 web application을 넘어, video-text retrieval은 multi-modal visual 및 language 이해를 위한 기본적인 연구 과제입니다.
보통 pre-train model들은 대규모 video-text dataset을 가지고 학습되기 때문에 feature-level model입니다. input은 feature extractor를 가지고 얻어낸 video feature를 input으로 사용합니다. input이 raw video라면, pretrain 하는데 상당히 오리 걸리거나 불가능해질 수 있습니다. 그럼에도 불구하고 대규모 dataset의 이점을 바탕으로 pretrain 된 model들은 video-text retrieval에서 상당한 성능 향상을 보여줍니다.
pixel-level 방식은 raw video를 input으로 바로 사용하여 model을 학습합니다. 초기 연구들은 대부분 이 방식을 따랐습니다. 이 방식은 video feature extractor와 paired text feature extractor를 동시에 학습시킵니다. 반면, feature-level approach는 적절한 feature extractor에 크기 의존합니다.
몇몇 최신 연구들은 pixel-level 방식으로 model을 pretrain하기 시작했으며, raw video로부터 pre-train model을 학습했습니다. 여기서 생기는 큰 도전과제는 dense video input으로 인한 높은 연산 부담을 줄이는 것입니다. ClipBERT는 end-to-end pretrain 방식이 가능해지도록 sparse sampling 전략을 사용했습니다. 구체적으로 model은 각 training step에서 video로부터 single or few short clip을 sparsely sample 합니다. 이러한 end-to-end 학습이 low-level feature extraction에 이점이 있음을 보였습니다. 몇 개의 sparsely sampled clip만 가지고도 video-text retrieval task를 충분히 해결할 수 있었습니다.
저자들의 target은 video-text retrieval에 맞춰 새로운 model을 pretrain 하는 것이 아닙니다. 저자들은 image-text pretrained model인 CLIP의 knowledge를 video-text retrieval로 어떻게 transfer 하는지 조사하는 것입니다.
저자들은 pre-trained CLIP을 사용하여 CLIP4Clip (CLIP For video Clip retrieval)이라 불리는 video-text retrieval을 수행하는 model을 제안합니다. 구체적으로 CLIP4Clip은 CLIP을 기반으로 구현되었으며, parameter-free type, sequential type, tight type이라는 3가지 유사도 계산 방법을 조사하기 위해 유사도 calculator를 design 하였습니다. 저자들과 유사한 연구가 있는데, 해당 연구도 CLIP을 이용하여 video-text retrieval을 수행합니다. 해당 연구는 다른 유사성 mechanism을 고려하지 않고 zero-shot prediction으로 CLIP을 바로 사용했습니다. 하지만, 저자들은 성능을 향상시키고 model을 end-to-end 방식으로 학습하기 위해 몇몇 유사도 게산 방식을 design 했습니다. 저자들의 contribution은 다음과 같습니다.
- pretrained CLIP 기반 3가지 유사도 계산 mechanism을 조사했습니다.
- 더 나은 retrieval space를 학습하기 위해 noisy large-scale video-language dataset을 기반으로 CLIP을 추가로 pretrain하였습니다.
광범위한 실험 결과는 저자들의 model이 MSR-VTT, MSVC, LSMDC, ActivityNet, DiDeMo dataset에서 새로운 SOTA를 달성했음을 보여줍니다. 실험을 통해 저자들은 다음과 같은 insight를 결론 내릴 수 있었습니다.
- video-text retrieval에 있어, 단일 image는 video를 encoding 하기엔 충분하지 않습니다.
- 대규모 video-text dataset으로 CLIP4Clip model을 추가적인 pre-training 하는 것이 필수적이며, 특히 zero-shot prediction에서는 더욱 성능 향상을 이끌어 낼 수 있습니다.
- powerful pre-trained CLIP을 사용할 때, small dataset에서는 새로운 parameter를 사용하지 않고 video frame에 대해 mean pooling mechanism을 사용하는 것이 더 좋습니다. 동시에, large dataset에서는 시간적 종속성을 학습하기 위해 slef-attention layer와 같이 추가적인 parameter를 사용하는 것이 좋습니다.
- 저자들은 hyper-parameter에 대해 신중하게 연구하고 가장 좋은 setting을 보여줍니다.
Related Work
Visual Representation Learning from Text Supervision
visual representation learning은 어려운 task이며 supervised method나 self-supervised method로 많이 연구되어 왔습니다. 대규모 unlabeled data로부터 semantic supervision을 고려할 때, text representation으로부터 visual representation을 학습하는 것은 떠오르는 연구 주제가 되었습니다. 대규모 visual and linguistic pair가 internet에 존재하기 때문에 이점이 있었습니다. CLIP의 성공으로 linguistic supervision으로부터 image representation을 학습할 수 있다는 것이 입증되었습니다. pre-trained model은 image에 대한 세밀한 visual concept을 학습할 수 있으며, retrieval task로 knowledge transfer를 할 수 있습니다. ClipBERT는 sparse sampling을 통한 효율적인 end-to-end method를 제안했으며, image-language dataset에서 pre-train 된 video-text retrieval의 더 나은 초기화가 가능함을 보였습니다. ClipBERT와 다르게, 저자들은 transformer 기반 visual 구조를 사용하는 CLIP을 사용하고, 이 image-language pre-trained model을 video-language pre-training으로 확장하여 video-text retrieval을 수행했습니다. video의 temporal sequence를 고려하여, 2D/3D linear embedding과 similarity calculator를 visual transformer에 붙였으며, 이를 통해 temporal sequence feature를 capture 할 수 있었습니다.
Framework
video 또는 video clip V가 주어지고 그에 대한 caption T가 주어졌을 때, video와 caption 사이 유사도를 계산하는 함수 s(v_i, t_j)를 학습하는 것이 목표입니다. text-to-video retrieval에서는 주어진 query caption에 맞춰 모든 video를 유사도 점수에 맞춰 rank를 만드는 것이 목표고, video-to-text retreival에서는 주어진 query video에 맞춰 모든 caption을 유사도 점수에 맞춰 rank를 만드는 것이 목표입니다. s(v_i, t_j)의 objective는 관련된 video-text pair에 대해서는 높은 유사도 점수를, 관련 없는 pair에 대해서는 낮은 유사도 점수를 부여합니다.
저자들은 video v_i ∈ V를 frame sequence로 나타냅니다. video v_i는 |v_i|개 sample 된 frame으로 구성됩니다. 저자들의 model은 end-to-end 방식으로 frame을 input으로 받아 pixel에서 학습됩니다. text encoder, video encoder , similarity calculator로 구성된 저자들의 framework는 다음과 같습니다.
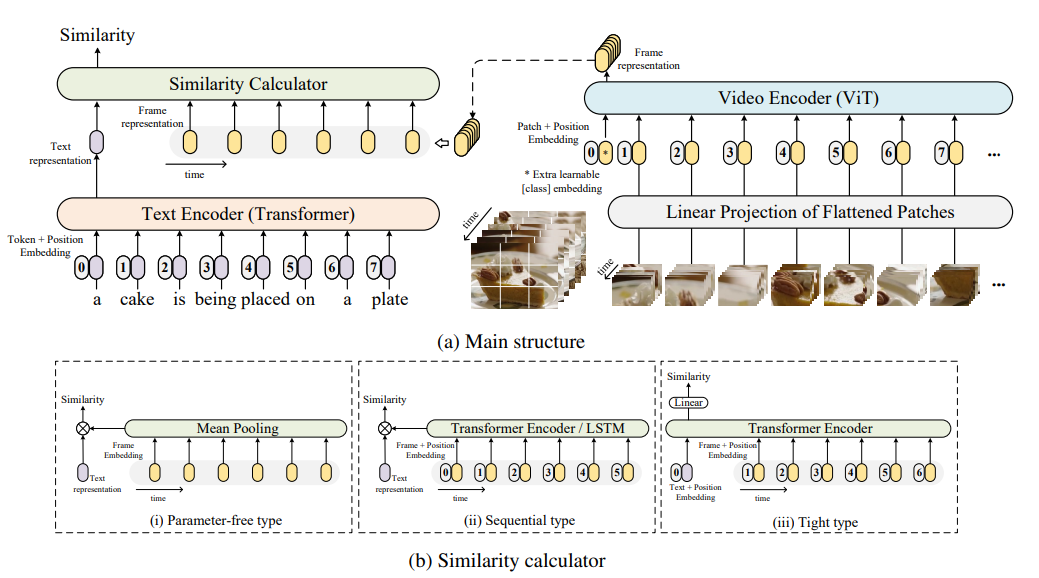
Video Encoder
video representation을 얻기 위해, 먼저 video clip에서 frame을 추출한 다음 video encoder를 통해 feature sequence를 얻도록 encode 합니다. 저자들은 ViT-B/32 with 12 layer, 32 patch size를 video encoder로 사용했습니다. 구체적으로, pre-trained CLIP (ViT-B/32)를 backbone으로 사용하고, image representation을 video representation으로 transfer 하는 것에 중점을 둡니다. pre-trained CLIP은 video-text retrieval task에서 효과적임을 이 논문에서 보여줍니다.
ViT는 non-overlapping image patch를 먼저 추출한 다음, 1D token으로 linear projection 합니다. 그다음 input image의 각 patch들 사이 관계를 modelling 하기 위해 transformer 구조를 사용하여 최종 representation을 얻습니다. ViT와 CLIP에 따라, 저자들은 [class] token의 output을 image representation으로 사용했습니다. video의 input frame sequence v_i으로 생성한 representation을 Z_i로 표기합니다.
저자들은 위 그림에서 Linear Projection of Flattened Patches module 부분에 있는 linear projection을 2D linear와 3D linear라는 2가지 type에 대해 조사했습니다. ViT의 flattened patch의 linear projection은 2D linear로 간주되며, 각 2D frame patch들을 독립적으로 embed 합니다. 이러한 2D linear는 frame 간의 temporal information을 무시합니다. 그래서 저자들은 3D linear projection에 대해 조사했으며, 이를 통해 temporal feature extraction을 향상시켰습니다.
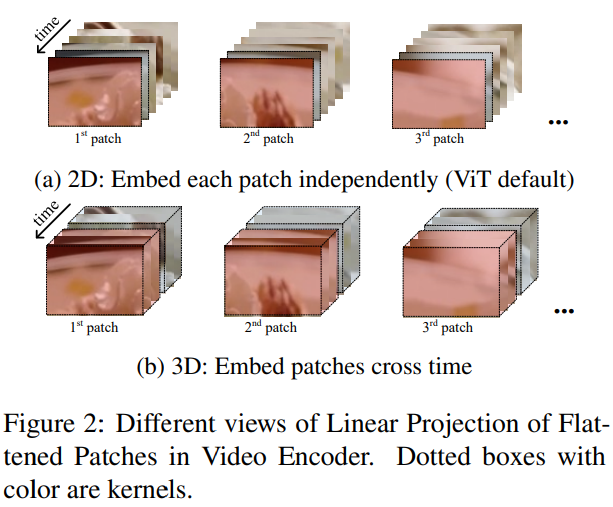
위 그림은 2D와 3D의 차이를 보여줍니다. 3D linear는 patch를 시간에 따라 embed 합니다. 구체적으로 3D linear는 kernel이 [t x h x w]인 3D convolution을 사용하며, 2D linear는 [h x w] kernel을 사용합니다. 여기서 t는 temporal, h는 height, w는 width를 나타냅니다.
Text Encoder
저자들은 CLIP으로부터 text encoder를 가져와 사용하여 caption representation을 생성했습니다. text encoder는 Transformer를 수정한 구조를 사용합니다. 8개 attention head를 가지고, 12개 layer를 가진 model입니다. CLIP에 따라, transformer의 마지막 layer의 [EOS] token의 activation을 caption의 feature representation으로 사용했습니다.
Similarity Calculator
video representation Z_i를 추출하고 caption representation w_j를 추출한 다음의 key point는 유사도를 계산하는 것입니다. 저자들의 model은 pre-trained image-text model을 기반으로 하기 때문에, 저자들은 새로운 학습 가능한 weight를 similarity calculator에 신중하게 추가해야 했습니다. weight initialization 없이 학습하는 것은 어려웠으며, backpropagation을 통해 pre-trained model의 성능을 저하할 수도 있었습니다. 그래서 저자들은 similarity calculator를 새로운 parameter를 사용하는지 아닌지에 따라 3가지 category로 나눴습니다.
paraparameter-free 방식, 즉 meaning pooling은 video representation을 새로운 parameter 없이 융합합니다. 이 외에도, sequential type and tight type이라는 두 가지 method가 있는데, 이 둘은 학습 가능한 새로운 weight를 사용하며, weight의 크기가 다릅니다.
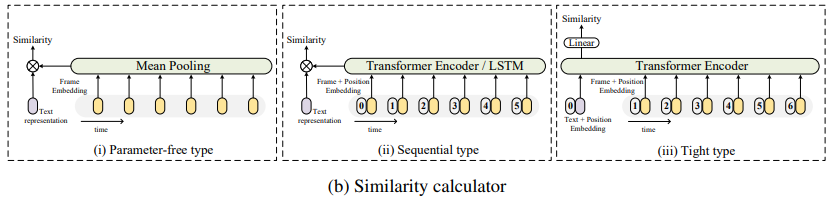
위 그림과 같이 구조가 이뤄집니다. parameter free type과 sequential type similarity calculator는 loose type에 속하며, video 및 text representation을 독립적으로 두 개의 별도 branch를 사용하여 cosine similarity를 계산합니다. tight type similarity calculator는 multi-modal interaction을 위해 transformer model을 사용하고 linear projection을 사용하여 similarity를 구합니다. transformer model과 linear projection 모두 학습할 새로운 weight를 가지고 있습니다.
- Parameter-free type
CLIP에 따르면, frame representation Z_i와 caption representation w_j는 layer normalize 된 후, 대규모 image-text pair에 대한 pre-train을 통해 multi-modal embedding space로 linear project 됩니다. parameter-free type을 사용하여 video에서 직접적으로 image/frame의 유사성을 계산할 수 있습니다. parameter-free type은 모든 frame에 대한 feature를 집계하여 'average frame'을 얻는 mean pooling을 사용합니다. \hat{z_i} = mean-pooling(Z_i)이며, 이를 이용해 유사도 함수 s(v_i, t_j)를 cosine similarity로 정의합니다.
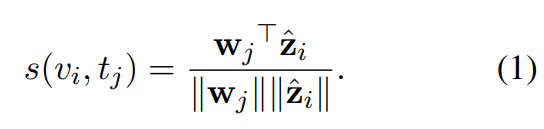
- Sequential type
mean-pooling 연산은 frame 사이 sequential information을 무시합니다. 그래서 저자들은 Sequential type similarity calculator를 위해 sequential feature를 modelling 하는 2가지 method를 연구합니다. 하나는 LSTM 기반이고, 다른 하나는 position embedding P를 사용하는 Transformer encoder이며, 둘 모두 sequence feature를 modelling 하는데 효과적입니다. encoding을 통해, encoded representation은 temporal information을 embed 합니다. 이후에 둘 모두 동일하게 parameter-free type similarity calculator를 사용합니다. 즉 mean-pooling을 수행한 후 cosine similarity를 구합니다.
- Tight type
위 parameter-free type, sequential type과 다르게, tight type은 video and caption 사이 multi-modal interaction을 위해 Transformer Encoder를 사용하며, linear layer를 사용하여 유사도를 예측합니다. 먼저, Transformer Encoder는 caption representation w_j와 frame representation Z_i를 concatenate 한 fused feature U_i를 받습니다.
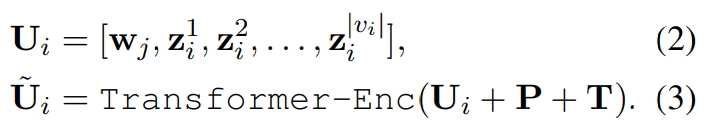
위 식에서 [,]는 concatenate를 나타냅니다. P는 position embedding, T는 BERT의 segment embedding과 유사한 type embedding을 나타냅니다. T는 caption에 대한 embedding과 video frame에 대한 embedding을 포함합니다. 그다음 저자들은 마지막 layer의 첫 번째 token output U˜_i[0, :]에 두 개 linear projection layer와 activation을 사용하여 유사도 점수를 계산합니다. 구체적으로 s(v_i, t_j) = FC(ReLU(FC(U˜_i[0, :])))입니다. 여기서 FC는 linear projection을 의미하고, ReLU는 ReLU activation function입니다.
Training Strategy
- Loss Function
B개 (video, text) or (video clip, text) pair를 batch로 받고, model은 B x B 개의 유사도를 계산하고 최적화해야 합니다. 저자들은 유사도 점수에 symmetric cross entropy loss를 사용하여 model의 parameter를 학습시킵니다.
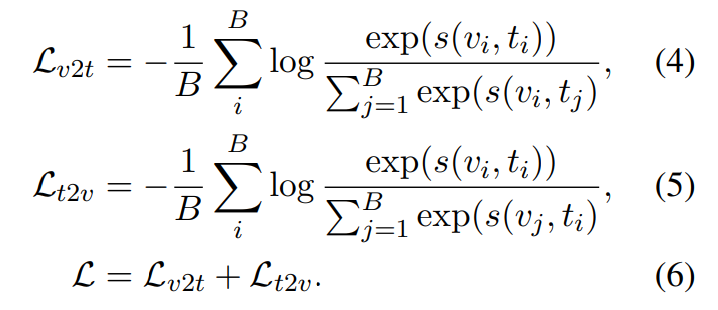
loss L은 video-to-text loss L_{v2t}와 text-to-video loss L_{t2v}의 합입니다.
- Frame Sampling
저자들의 model은 frame을 input으로 받아서 pixel에서 바로 학습되기 때문에, frame을 추출하는 방식이 매우 중요합니다. 효과적인 sampling strategy는 정보량과 연산량 사이의 balance를 고려해야 합니다. video의 sequential information을 고려하기 위해, 저자들은 random sparse sampling strategy 대신 uniform frame sampling strategy를 사용했습니다. 1초마다 1개 frame을 sampling 했습니다.
- Pre-training
CLIP이 image의 visual concept을 학습하기에 효과적이지만, video에서 temporal feature를 학습해야만 합니다. knowledge를 video로 transfer 하기 위해, 저자들의 CLIP4Clip model을 Howto100M dataset으로 post-pretrain 합니다. video-text dataset으로 pre-training 하는 것은 효율성 문제로 인해 매우 어려운 문제입니다. 저자들은 parameter-free type에서 CLIP을 최적화하기 위해 MIL-NCE를 사용합니다. optimizer로 Adam을 사용했습니다.
Experiments
Datasets
저자들은 5가지 dataset인 MSR-VTT, MSVC, LSMDC, ActivityNet, DiDeMo를 가지고 실험을 진행했습니다.
MSR-VTT는 10,000개 video로 구성되며, 각 video는 10초에서 32초 사이 길이이며 200,000개 caption이 있습니다. 저자들은 Training-7K와 Training-9K 방식으로 data split을 진행했습니다. 두 split의 test data는 'test 1k-A'이며, 1000개 clip-text pair를 포함하고 있습니다.
MSVD는 1,970개 video를 포함하며, 각 video는 1초에서 62초 사이 길이입니다. 학습으로 1200개, validation으로 100개, test로 670개를 사용했습니다. 각 video는 약 40개 sentence를 가지고 있습니다.
LSMDC는 118,081개 video로 구성되며, 각 video는 2초에서 30초 사이 길이입니다. video는 202개 영화에서 추출되었습니다. validation set은 7,408개 video로 구성되며, test set으로 1,000개 video를 사용하고 이 video는 training, validation과 독립적인 영화로부터 구해집니다.
ActivityNet은 20,000개 YouTube video로 구성됩니다. video에 대한 모든 description을 하나의 문단으로 concatenate 하여 video-paragraph retrieval로 model을 평가합니다.
DiDeMo는 10,000개 video와 40,000개 sentence로 구성됩니다. 저자들은 video에 대한 모든 sentence description을 concatenate하여 하나의 query로 사용하는 video-paragraph retrieval을 평가했습니다.
저자들은 기본적인 retrieval metric을 사용했습니다. K rank recall (R@K, 높을수록 좋음), median rank (MdR, 낮을수록 좋음), mean rank (MnR, 낮을수록 좋음)를 사용하여 model의 성능을 평가했습니다. R@K (Recall at K)는 test sample에서 query sample에 대해 상위 K개 검색된 항목 내에서 올바른 결과를 찾은 test sample 비율을 계산합니다. 저자들은 R@1, R@5, R@10 (or R@50 for Activitynet)을 사용해 결과를 확인했습니다. Median Rank는 ranking의 ground-truth result의 median을 계산합니다. 유사하게 Mean Rank는 모든 correct result의 mean rank를 계산합니다.
Experimental Details
text encoder와 video encoder로 CLIP (ViT-B/32)을 사용했습니다. similarity calculator의 parameter를 어떻게 initialize 하는지가 실질적인 문제입니다. 저자들의 solution은 CLIP에서 유사한 parameter를 재사용하는 것입니다. 구체적으로 sequential type과 tight type에 있는 position embedding으로 저자들은 CLIP의 text encoder를 position embedding을 사용하여 초기화했습니다. 비슷하게 transformer encoder는 pre-trained CLIP의 image encoder의 layer로 초기화했습니다. LSTM과 linear projection과 같이 남은 parameter들은 random 하게 초기화됩니다. 3D linear, 2D linear의 temporal dimension t, height dimension h, width dimension w로 저자들은 3, 32, 32를 사용했습니다. 3D linear의 경우, 저자들은 temporal dimension에 대해 stride와 padding을 1로 설정했습니다. 저자들은 3D linear를 pre-trained CLIP의 2D linear에 대한 'central frame initialization' strategy를 사용하여 초기화했습니다. 구체적으로 저자들은 CLIP의 image encoder의 2D weight E_{2D}로부터 [0, E_{2D}, 0]을 사용합니다. sequential type과 tight type의 transformer encoder는 4개 layer를 사용하고, LSTM은 1개 layer를 사용했습니다.
Comparison to the State of the Art
저자들은 pre-trained CLIP 기반 모든 similarity calculator를 SOTA와 비교합니다. '-meanP'는 parameter-free type (즉 mean pooling)이고, '-seqLSTM'은 LSTM 기반 sequential type, '-seqTransf'는 Transformer Encoder 기반 sequential type, '-tightTransf'는 tight type을 사용했습니다.
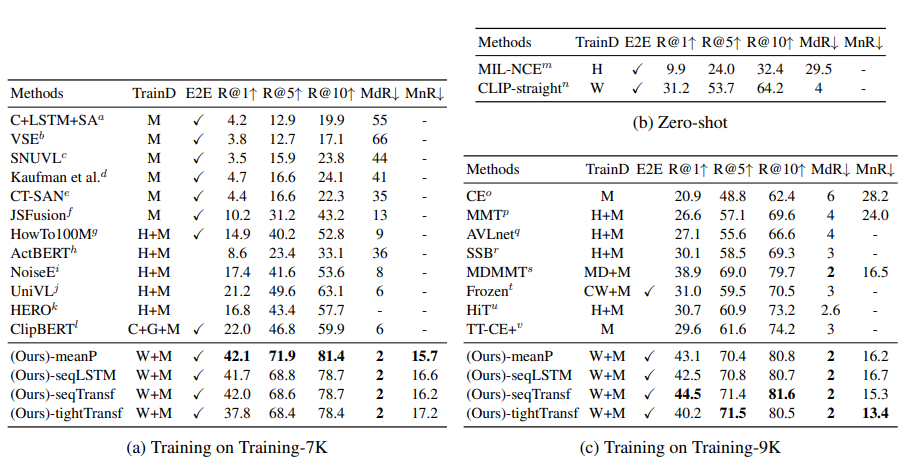
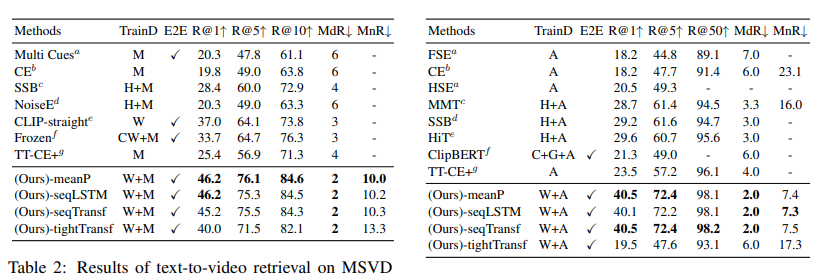
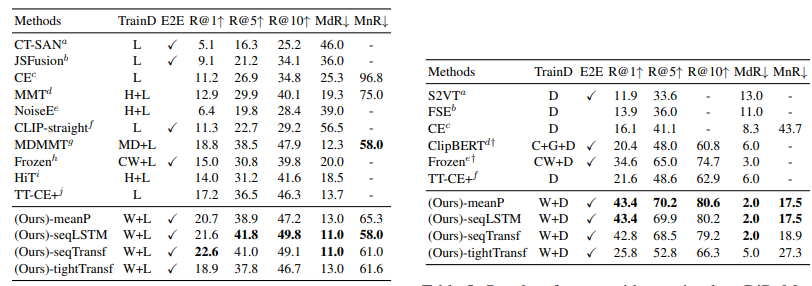
위 표들은 MSR-VTT, MSVC, LSMDC, AcitivtyNet, DiDeMo에 대한 text-to-video retrieval 결과를 보여줍니다. 저자들은 모든 5가지 dataset에 대해 SOTA 성능을 달성했습니다. TrainD는 pre-train으로 사용한 dataset을 나타냅니다. 저자들은 CLIP-straight를 통해 pre-trained CLIP의 성능 발전이 있었음을 보였습니다. 그리고 end-to-end finetuning에서 얻은 성능 향상이 video-text retrieval에 대한 image-text pretrain model의 잠재력을 증명합니다.
MSR-VTT dataset의 경우, parameter-free type (-meanP) model이 'Training-7k' data split에서 가장 좋은 성능을 보였으며, sequential type (-seqTransf) model이 'Training-9k' data split의 다른 method보다 더 좋은 성능을 달성했습니다. 저자들은 적은 수의 dataset으로 pre-trained parameter와 추가적인 parameter를 학습하는 것은 어렵기 때문에 이러한 성능을 보여주며, 큰 dataset을 사용하면 추가적인 parameter를 학습할 수 있다고 합니다. LSMDC dataset의 경우 sequential type model이 다른 두 type보다 더 좋은 성능을 보여줍니다. 두 sequential type (-seqLSTM, -seqTransf)은 비슷한 결과를 보였습니다. MSVD dataset에서는 parameter-free type이 가장 좋은 성능을 보였습니다. MSVD는 MSR-VTT보다 적어도 2배 이상 작은 크기를 보여주며, pretrained weight의 이점을 유지하기 위해선 더 많은 추가적 dataset이 필요로 합니다. ActivityNet과 DiDeMo에 대한 video paragraph retrieval 성능은 pre-trained model을 사용할 때 parameter-free type의 장점을 입증했습니다. 5가지 dataset에서 tight type (-tightTransf)에 대한 대부분의 결과는 모든 calculator보다 더 좋지 않은 성능을 보였습니다. 저자들은 이러한 결과에 대해서 tight type이 여전히 cross-modality interaction을 학습하기엔 충분한 data가 없다고 판단했습니다.
Hyperparameters and Learning Strategy
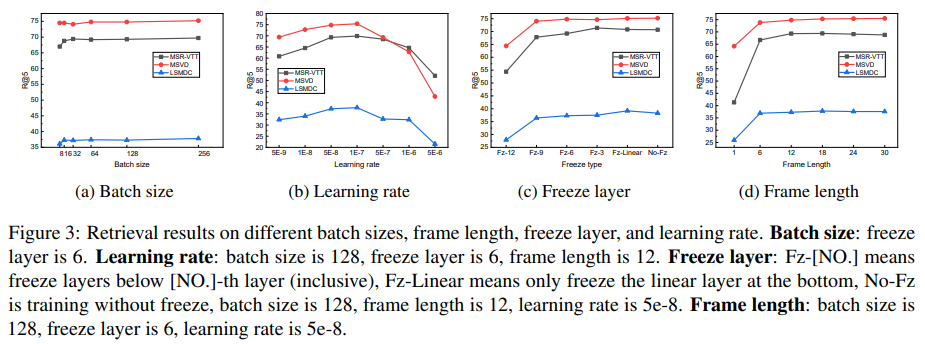
저자들은 hyperparameter와 learning strategy에 대한 실험을 진행하여 가장 좋은 setting을 탐구했습니다. 결과는 위와 같습니다. batch size가 증가함에 따라 성능도 향상되었으며, batch size가 128에서 256 사이에서는 유사한 성능을 보여줍니다. 그래서 저자들은 batch size를 128로 설정하여 사용했습니다. frame length에 대한 실험도 진행했습니다. 저자들은 실험을 통해 frame을 1개에서 6개로 증가할 때 성능이 크게 향상되는 것을 볼 수 있었고, single frame 대신 여러 frame sequence을 사용해야지 video를 modelling 할 수 있음을 보여줍니다. 저자들은 실험에서 12개 frame을 사용했습니다. 저자들은 pre-trained CLIP의 각 layer의 parameter를 freeze 해야 하는지 아닌지에 대한 연구도 진행했습니다. 실험을 통해 learning rate를 작게 설정하고 bottom linear layer는 유지한 채로 모든 transformer encoder layer를 fine-tune 하는 것이 더 좋은 성능을 보여준다는 것을 알 수 있었습니다. learning rate에 대한 실험을 통해 가장 좋은 rate가 1e-7라는 것을 발견했습니다.
Post-pretraining on Video Dataset
image pre-training model인 pre-trained CLIP을 기반으로 model을 설계했습니다. 이 type variance (image v.s. video)를 해결하기 위해, 저자들은 Howto100M-380k video dataset을 가지고 model의 post-pretraining을 수행했으며, zero-shot과 fine-tuning에서 성능 향상을 이끌어 낼 수 있었습니다.
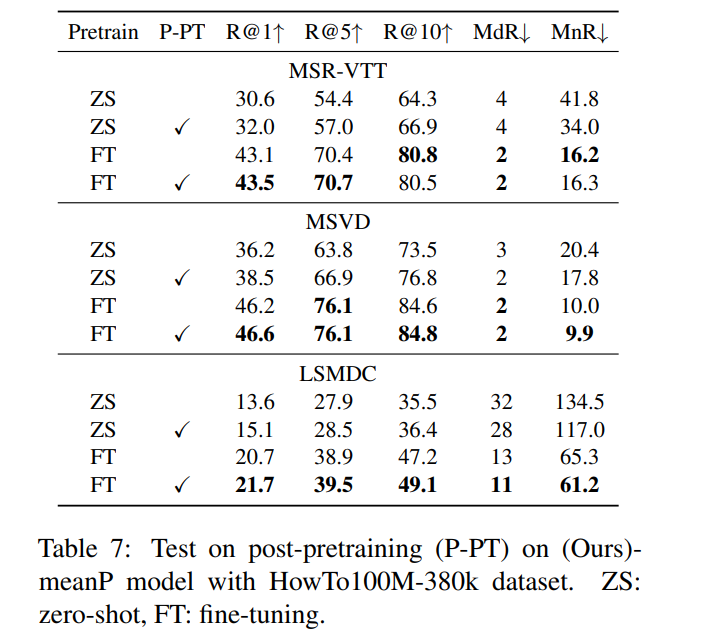
위 실험 결과를 통해, zero-shot과 fine-tuning setting에서의 성능 모두 증가된 것을 볼 수 있습니다. zero-shot에서의 성능 향상이 더 크며, 이는 동일한 data type (video)으로 post-preprocessing을 수행하여 일반적인 knowledge를 학습하고 이를 직접 transfer 할 수 있음을 보여줍니다. 추가적으로 post-pretrained model에 대한 fine-tuning이 LSMDC와 MSVD dataset에 대한 성능 향상을 이끌어냈으며, MSR-VTT dataset에서도 유사한 결과를 얻을 수 있었습니다.
2D/3D Patch Linear
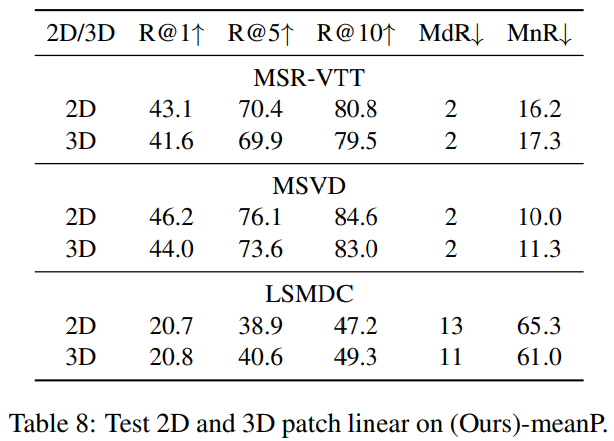
저자들은 2D and 3D linear에 대한 비교를 진행했습니다. 결과는 위와 같습니다. 3D patch linear는 temporal information을 추출할 수 있으며 더 나은 discriminant feature를 생성할 수 있지만, 3D linear는 2D linear에 비해 MSR-VTT, MSVD에서 더 좋지 않은 결과를 보여줍니다. 저자들은 CLIP이 3D linear 대신 2D linear로 학습되었고, 3D linear에 대한 초기화 불일치 때문에 temporal information을 학습하기에 어려워졌다고 생각했습니다. 저자들은 대규모 video-text dataset으로 pretrain 하여 성능을 향상시킬 수 있을 것이라고 저자들은 이야기합니다.
Conclusion
이 논문에서 저자들은 pretrained CLIP을 backbone으로 사용하여 frame-level input을 받아 video clip retrieval task를 수행합니다. 저자들은 parameter-free type, sequential type, tight type similarity calculator를 사용하여 최종 결과를 얻었습니다. 실험을 통해 MSR-VTT, MSVC, LSMDC, ActivityNet, DiDeMO에서 SOTA를 달성하여 저자들의 model의 성능을 입증했습니다. 저자들은 경험적 연구를 통해 몇 가지 insight를 제공했습니다. 1) image feature가 video-text retrieval 성능을 향상시킬 수 있습니다. 2) image-text pre-trained CLIP에 post-pretrain을 하는 것이 video-text retrieval 성능을 크게 향상 시켜줍니다. 3) 3D patch linear projection과 sequential type similarity는 retrieval task에 대한 유망한 approach입니다. 4) CLIP을 video-text retrieval에 사용할 때 learning-rate에 민감합니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Classifier-Free Diffusion Guidance (0) | 2024.08.28 |
|---|---|
| [논문] I Hear Your True Colors: Image Guided Audio Generation (0) | 2024.08.23 |
| [논문] Video-to-Audio Generation with Hidden Alignment (0) | 2024.08.20 |
| [논문] TiVA: Time-Aligned Video-to-Audio Generation (0) | 2024.08.19 |
| [논문] Diverse Video Captioning by Adaptive Spatio-temporal Attention (0) | 2024.08.15 |



