https://arxiv.org/abs/2207.12598
Classifier-Free Diffusion Guidance
Classifier guidance is a recently introduced method to trade off mode coverage and sample fidelity in conditional diffusion models post training, in the same spirit as low temperature sampling or truncation in other types of generative models. Classifier g
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
classifier guidance는 최근 도입된 방법으로, conditional diffusion model에서 mode coverage와 sampling fidelity 간 trade off를 조절하는 방법입니다. Classifier guidance는 diffusion model의 score estimate와 image classifier의 기울기와 결합하며, 이에 따라 diffusion model과는 별도로 image classifier를 별도로 학습해야 합니다. 이 방법은 classifier 없이도 guidance가 성능을 향상시킬 수 있는지에 대한 의문이 생기게 됩니다. 저자들은 guidance가 classifier 없는 pure generative model의 성능을 확실히 향상시킬 수 있다는 것을 보여줍니다. 저자들은 이러한 방식을 classifier-free guidance라 부르며 conditional and unconditional diffusion model을 동시에 학습합니다. 그리고 난 후 두 방식으로 얻은 score estimate를 결합하여 sample의 품질과 다양성 간의 균형을 이룹니다.
Introduction
diffusion model은 최근 image 및 audio synthesis task에서 경쟁력 있는 sample quality와 우수한 likelihood score를 제공하는 표현력 있고 유연한 generative model 중 하나로 떠올랐습니다. 이 model은 상당히 적은 inference step으로 autoregressive model과 비교 가능한 정도의 quality를 달성했으며, ImageNet generation에 있어 BigGAN-deep, VQ-VAE-2 보다 더 높은 FID score, classification accuracy를 달성했습니다.
diffusion model의 sample quality를 향상시키기 위해 추가적인 trained classifer를 사용하는 기술인 classfier guidance가 등장했습니다. classifier guidance 이전에는, BigGAN이나 low temperature Glow가 생성한 low temperature sample (다양성보다는 더 품질 높은 sample)과 유사한 sample을 diffusion model이 생성하는 방법을 알 수 없었습니다. model score vector를 scaling 하거나 diffusion sampling 과정에서 더해지는 gaussian noise 양을 줄이는 것과 같은 간단한 방법들은 효과적이지 않았습니다. 대신 classifier guidance는 diffusion model의 score estimate를 classifier의 log probability에 대한 gradient를 혼합했습니다. classifier gradient의 강도를 조절함으로써, Inception score와 FID 점수를 조절할 수 있습니다.
저자들은 classifier 없이도 classifier guidnace를 수행할 수 있는지에 관심이 있습니다. classifier guidance는 추가적인 classifier를 학습해야 하고 noisy data로 학습되어야 하므로 pre-trained classifier를 사용할 수 없기 때문에, diffusion model의 학습 pipeline을 복잡하게 만듭니다. classifier guidance는 sampling할 때 score estimate와 classifier gradient를 mix 하기 때문에, classifier-guided diffusion sampling은 gradient 기반 adversarial attack으로 image classifier를 혼란시키려는 시도로 해석될 수도 있습니다. 이는 어떻게 classifier guidance가 FID나 IS와 같은 classifier-based metric을 성공적으로 향상시키는지에 대한 이유가 단순히 classifier에 adversarial이기 때문인지에 대한 의문을 제기합니다. classifier gradient의 방향으로 나아가는 것은 GAN 학습과 유사합니다. 이는 classifier-guided diffusion model이 classifier-based metric에서 좋은 모습을 보이는 것이 GAN과 유사하게 동작하는 것인지에 대한 의문도 제기합니다.
이러한 의문들을 해결하기 위해, 저자들은 classifier-freee guidance를 제안하며, 저자들의 guidance method는 classifier를 전형 사용하지 않습니다. image classifier의 기울기 방향으로 sampling 하는 대신, classifier-free guidance는 conditional diffusion model의 score estimate와 동시에 학습되는 unconditional diffusion model의 score estimate를 결합합니다. mixing weight를 조정함으로써, 저자들은 classifier guidance로 얻는 것과 유사한 FID/IS tradeoff를 얻습니다. 저자들의 classifier-free guidance는 pure generative model이 다른 생성 model처럼 high fidelity sample을 합성할 수 있는 능력이 있다는 것을 입증합니다.
Guidance
GAN이나 flow-based model처럼 특정 생성 model들의 흥미로운 성질로, 생성 model의 sampling time에서 input으로 variance를 줄이거나 noise의 범위를 줄이면 truncated or low temperature sampling이 가능하다는 점이 있습니다. 이는 각 sample의 quality를 향상시키지만 sample의 다양성을 줄인다는 효과를 목표로 합니다. 예를 들어 BigGAN의 경우, truncation의 정도에 따라 FID score와 Inception score 사이 tradeoff curve가 생깁니다. Glow의 low temperature도 비슷한 효과를 보입니다.
불행하게도 diffusion model에 바로 truncation이나 low temperature sampling을 수행하는 것은 효과적이지 않습니다. 예를 들어 reverse process에서 model score를 scaling하거나 gaussian noise의 variance를 줄이는 것은 model이 blurry 하고 low quality의 sample을 생성하도록 만듭니다.
Classifier Guidance
diffusion model에서 truncation과 같은 효과를 얻기 위해서, 이전 연구에서는 classifier guidance를 제안했습니다. 이는 auxiliary classifier model의 log likelihood 기울기를 얻도록 diffusion score를 수정하는 방식입니다.

위 식에서 p(c|z_λ)는 classifier model을 의미합니다. w는 classifier guidance의 strength를 조절하는 parameter입니다. 이 수정된 score를 diffusion model이 sampling할 때 대신 사용되며, 다음과 같은 분포에서 근사 sample을 생성합니다.

이 효과는 classifier가 올바른 label에 높은 likelihood를 부여하는 data의 확률을 높이는 것입니다. 즉 잘 분류된 data는 높은 inception score를 받으며, 이에 따라 generative model은 이점을 얻게 됩니다. 그래서 이전 연구자들은 w > 0으로 설정하는 것이 diffusion model의 inception score를 향상시킬 수 있지만, sample의 다양성을 감소시킨다는 것을 발견했습니다.

위 그림은 3가지 class에 대한 2D 예시를 보여줍니다. 이를 통해 guidance의 효과를 확인할 수 있습니다. guidance를 적용한 후, 분포의 형태는 현저히 non-gaussian이 됩니다. guidance의 strength가 증가함에 따라 각 conditional space는 다른 class에서 멀어지고, 높은 confidence 방향으로 확률 질량이 이동하여 더 작은 영역에 집중되는 모습을 보여줍니다. 이러한 결과는 guidance strength의 증가로 인해 발생되는 inception score 상승과 sample diversity 감소의 단순한 표현으로 볼 수 있습니다.
unconditional model에 대해 classifier guidance의 weight를 w+1로 적용하면, 이론적으로 weight w를 가진 conditional model에 guidance를 적용한 것과 동일한 결과를 가져올 것입니다.

하지만 class-conditional model에 classifier guidance를 적용했을 때 가장 좋은 결과를 얻었습니다. 이러한 이유로 저자들은 conditional model에 guiding을 하는 설정을 그대로 유지할 것입니다.
Classifier-free Guidance
classifier guidance는 truncation 또는 low temperature sampling에 맞춰 기대했던 IS와 FID 사이 tradeoff를 보여주지만, image classifier로부터 구한 gradient에 의존하며 저자들은 classifier를 제거하길 원합니다. 저자들은 classifier의 gradient와 같은 추가적인 gradient 없이도 동일한 효과를 얻을 수 있는 classifier-free guidance를 설명합니다. classifier-free guidance는 classifier를 사용하지 않지만 classifier guidance와 동일한 효과를 얻기 위해 ε(z, c)를 수정합니다.

위 algorithm은 classifier-free guidance의 training detail을 보여줍니다. classifier model을 따로 학습하는 대신, 저자들은 unconditional denoising diffusion model p_θ(z)을 conditional model p_θ(z|c)와 함께 학습합니다. single network를 사용하며, unconditional model의 경우엔 null token을 condition c로 사용합니다. hyperparameter p_{uncond}라는 확률에 맞춰 random 하게 condition c를 null로 사용하여, 두 model을 따로 학습하는 것이 아니라 동시에 학습합니다. 이를 통해 학습 pipeline이 간단해지며 parameter 수가 증가되지 않습니다.

classifier-free guidance의 sampling algorithm은 위와 같습니다. sampling할 때 conditional score estimate와 unconditional score estimate를 linear combination 합니다.

위 식과 같습니다. classifier gradient가 없기 때문에, image classifier에 의한 gradient-based adversarial attack으로 해석될 수 없습니다. 그리고 unconstrained neural network를 사용하기 때문에 score estimate는 non-conservative vector field이며, 일반적으로 classifier log likelihood와 같은 scalar 함수의 gradient로 표현될 수 없습니다. 즉, classifier-guided score로 표현될 수 없습니다.
위 식은 classifier-guided score가 존재하지 않지만, implicit classifier p(c | z_λ) ∝ p(z_λ | c) p(z_λ)에서 영감을 받았습니다. 만약 정확한 score를 안다면, implicit classifier 기울기는

가 되며, score 추정치는 다음처럼 됩니다.
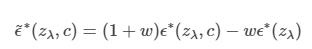
위 식처럼 ε*는 ε_θ와 근본적으로 다릅니다. ε*는 scaled classifier gradient로 구해진 값입니다. ε_θ는 score estimate로 구성된 것이며, classifier의 기울기가 아닙니다.
저자들은 classifier-free guidance가 classifier guidance와 동일한 방식으로 FID와 IS 사이의 균형을 조절할 수 있음을 실험을 통해 보여줍니다.
Experiments
저자들은 classifier-free guidance를 사용하는 diffusion model을 ImageNet을 가지고 학습시켰습니다. 이는 BigGAN 논문부터 시작된 FID와 Inception score 사이 tradeoff를 연구하는 표준 설정입니다.
저자들의 실험들은 sample quality metric을 최신 성능으로 향상시키는 것이 아니라, classifier-free guidance가 classifier guidance와 유사한 FID/IS tradeoff가 가능하다는 것을 입증하는 것이고 classifier-free guidance 동작에 대한 이해를 하는 것입니다. 이를 위해 저자들은 이전에 등장한 guided diffusion model과 동일한 구조와 hyperparameter를 사용했습니다. 이전에 등장했던 model의 hyperparameter는 classifier guidance에 맞춰져 있기 때문에 classifier-free guidance에서는 sub-optimal 한 결과를 가져다줄 수 있습니다. 그리고 저자들은 conditional and unconditional model을 추가적인 classifier 없이 동일한 architecture로 통합했기 때문에, 이전 연구보타 더 적은 model capacity를 사용합니다. 그럼에도 불구하고 저자들의 classifier-free guided model은 경쟁력 있는 sample quality metric을 보여주며 때때로는 더 뛰어난 결과를 보여줍니다.
Varying the Classifier-free Guidance Strength
classifier-free guidance가 IS와 FID 사이 tradeoff가 가능하다는 것을 증명했습니다. 저자들은 classifier-free guidance를 64 x 64 & 128 x 128 class-conditional ImageNet generation에 적용했습니다.

위 실험 결과를 통해, 저자들은 guidance strength w에 따라 sample quality effect를 보여줍니다. 저자들은 w ∈ {0, 0.1, 0.2, ... , 4}에 대해 실험을 진행했으며, 각 value마다 50000개 sample을 가지고 FID와 IS를 구했습니다. w가 작을 때 가장 좋은 FID 결과를 얻었습니다. 그리고 w가 클수록 가장 좋은 IS를 얻었습니다. w가 증가함에 따라 FID는 단조적으로 감소하고 IS는 단조적으로 상승하는 명확한 trade-off 관계를 보였습니다. 128 x 128에 대한 실험에서는 저자들의 model은 SOTA 성능을 보여줍니다. 결과는 아래와 같습니다.


w = 0.3일 때 저자들의 model은 classifier-guided ADM-G보다 더 뛰어난 성능을 보여줍니다. 그리고 저자들의 model은 BigGAN-deep보다 FID & IS 모두 더 뛰어난 모습을 보여줍니다.

위 그림은 생성 결과를 보여줍니다. classifier-free guidance strength를 키우면 기대했던 것과 같이 sample 다양성이 감소되고 sample fidelity가 증가되는 것을 볼 수 있었습니다.

Varying the Unconditional Training Probability
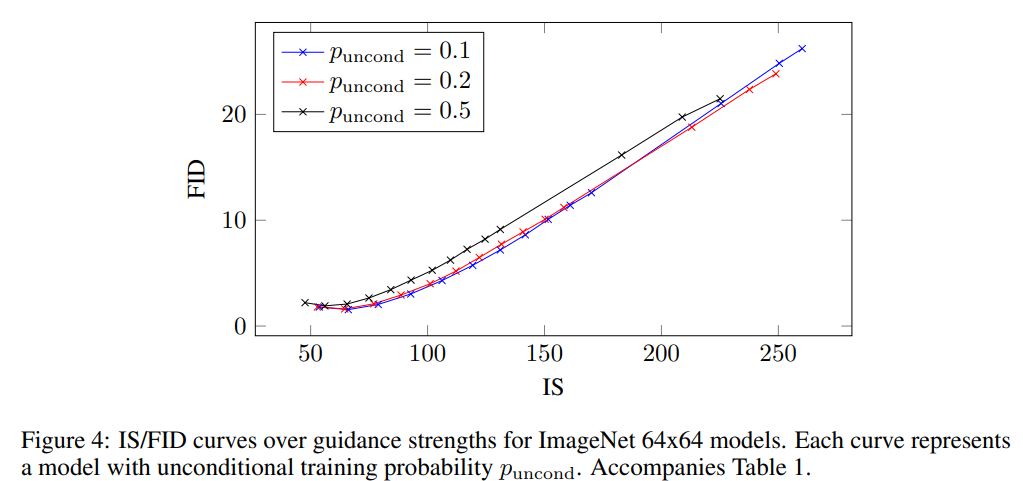
학습할 때 classifier-freee guidance의 main hyperparameter는 p_{uncond}이고, 이는 conditional and unconditional diffusion model을 동시에 학습할 때 unconditional generation에 대해 학습할 확률을 나타냅니다. 저자들은 64 x 64 ImageNet에 대해 p_{uncond}의 따른 학습 효과를 연구했습니다.
Table1, Fig. 4는 p_{uncond}에 대한 sample quality effect를 보여줍니다. 저자들은 p_{uncond} = 0.5일 때 일관성 있게 p_{uncond} = 0.1 or 0.2일 때보다 성능이 떨어지는 것을 보였습니다. 0.1이나 0.2에서는 서로 유사했습니다.
이러한 결과를 바탕으로, sample quality에 효과적인 classifier-free guided score를 생성하기 위해서는 diffusion model의 capacity 중 상대적으로 적은 부분만이 unconditional generative task에 할당되어야 한다는 결론을 내렸습니다. 흥미롭게도, classifier guidance에서는 상대적으로 작은 capacity의 small classifier를 사용하는 것이 classifier guided sampling에 충분하다고 했으며, classifier-free guided model도 이러한 현상을 반영하는 결과를 보여줍니다.
Discussion
저자들의 classifier-free guidance method의 가장 실용적인 이점은 매우 간단하다는 점입니다: 학습 과정에서 conditioning 부분을 random으로 설정하는 한 줄만 변경하면 되며, sampling 과정에서는 conditional and unconditional score estimate를 mix 하면 됩니다. 대조적으로 classifier guidance는 추가적인 classifier를 학습해야 하기 때문에 학습 pipeline을 복잡하게 만듭니다. 이 classifier는 noisy z_λ로 학습되어야만 하며, standard pre-trained classifier를 바로 가져다가 사용할 수 없습니다.
classifier-free guidance는 추가적인 trained classifier 없이도 classifier guidance처럼 IS & FID 사이 trade off를 수행할 수 있기 때문에, 저자들은 pure generative model로 guidance를 수행할 수 있음을 입증했습니다. 그리고 저자들의 diffusion model은 unconstrained neural network에 의해 parameterize 되므로, score estimate는 반드시 conservative vector field를 형성하지 않으며, classifier gradient와 다릅니다. 따라서 저자들의 classifier-free guided sampler는 classifier gradient와 닮지 않은 방향으로 step을 진행하기 때문에 image classifier에 대한 gradient-based adversarial attack으로 해석할 수 없습니다. 따라서 저자들은 classifier 기반 IS 및 FID 지표를 강화하는 것이 pure generative model로 가능하다는 것을 보여줍니다.
그리고 저자들은 어떻게 guidance가 동작하는지에 대한 직관적인 설명을 보여줍니다: conditional likelihood를 향상시키지만, sample의 unconditional likelihood를 감소시킵니다. classifier-free guidance는 negative score term을 사용하여 unconditional likelihood를 감소시키는데, 이는 저자들이 아는 한 탐구되지 않았으며, 다른 application에서도 사용할 수 있을 것입니다.
classifier-free guidance는 unconditional model 훈련에 의존하지만, 일부 경우에는 이를 피할 수 있습니다. class 분포를 알고 있고 적은 수의 class가 존재한다면, Σp(x|c)p(c) = p(x)을 사용하여 conditional score로부터 unconditional score를 얻을 수 있습니다. 물론 class 수만큼 많은 forward pass를 요구하며, 고차원 conditioning에서는 비효율적일 수 있습니다.
classifier-free guidance의 potential disadvantage는 sampling speed입니다. 일반적으로 classifier는 generative model보다 더 작고 더 빠를 수 있기 때문에, classifier guided sampling은 classifier-free guidance보다 빠를 수 있습니다. classifier-free guidance는 conditional score, unconditional score라는 두 번의 forward pass를 필요로 합니다. diffusion model의 여러 pass를 동작하는 것의 필요성은 conditioning을 나중에 network에 inject 하는 방식으로 구조를 변경하여 완화시킬 수 있을 것입니다.
마지막으로 sample의 다양성을 희생하고 sample fidelity를 높이는 모든 guidance method는 다양성의 감소가 가능한지 여부에 대한 질문에 직면해야 합니다. sample 다양성을 유지하는 것이 중요한 응용 프로그램에서는 특정 data 부분이 다른 data와 비교하여 충분히 표현되지 않을 수 있기 때문에, 이는 배포된 model에 부정적인 영향을 미칠 수 있습니다. sample 다양성을 유지하면서 sample quality를 향상시키려는 시도는 향후 연구가 될 것입니다.



