https://ojs.aaai.org/index.php/AAAI/article/view/29475
V2A-Mapper: A Lightweight Solution for Vision-to-Audio Generation by Connecting Foundation Models | Proceedings of the AA
ojs.aaai.org
해당 논문을 보고 작성했습니다.
Abstract
foundation models (FMs) 위에 artificial intelligence (AI)를 설계하는 것이 AI 연구 분야에 새로운 paradigm으로 등장했습니다. 방대한 양의 data로 학습된 representative and generative ability는 추가적인 scratch training 없이도 다양한 downstream task에 쉽게 적용되고 변환될 수 있습니다. 하지만 audio modality를 포함한 cross-modal generation에 FM을 사용하는 것은 덜 연구된 분야입니다. 하지만 visual input에 맞춰 의미적으로 관련 있는 sound를 자동적으로 생성하는 것은 cross-modal generation 연구에서 중요한 problem입니다. 이러한 vision-to-audio (V2A) generation 문제를 해결하기 위해, 현재 존재하는 method들은 중간 크기의 dataset을 사용하여 복잡한 system을 구현하고 설계하여 처음부터 학습해 왔습니다. 이 논문에서 저자들은 CLIP, CLAP, AudioLDM과 같은 foundation model을 사용하여 lightweight solution을 제안했습니다. 저자들은 먼저 visual CLIP과 auditory CLAP model의 latent space 사이 domain gap을 조사했습니다. 그다음 저자들은 간단하지만 효과적인 mapper mechanism인 V2A-Mapper를 제안하며, 이는 visual input을 CLIP과 CLAP space 사이 translate 하여 domain 차이를 연결합니다. translated CLAP embedding을 condition으로 하여, pretrained audio generative FM AudioLDM이 high-fidelity and visually-aligned sound를 생성합니다. 이전 방식들과 비교했을 때, 저자들의 method인 V2A-Mapper는 빠른 학습만을 필요로 합니다. 즉 빠르고 간단한 학습을 통해 model을 구현할 수 있음을 의미합니다. 저자들은 V2A-Mapper의 선택에 따른 추가적 분석 및 광범위한 실험을 수행하였으며, generative mapper가 더 나은 fidelity and variability (FD)를 보여주고 regression mapper가 약간 더 나은 relevance (CS)를 보여주었습니다.
Introduction
대규모 data로 학습되고 종종 self-supervised learning을 사용하는 Foundation models (FMs)은 adaptation을 통해 downstream task에 대한 무관한 representative 또는 generative capability을 제공합니다. 최근 AI 연구에서 FMs는 다양한 task 전반에서 robust한 일반화 및 knowledge transfer 능력을 입증해 왔습니다. language, vision, audio에 걸친 많은 uni-modal task에서 성공을 거두었음에도 불구하고, cross-modal generation과 같은 multi-modality가 포함된 문제에서의 FMs의 adaptation은 주로 vision-language에 대해서만 연구되어 왔습니다. 2023년에 FMs을 text-to-audio generation에 적용하고 눈에 띄는 성능을 보이는 시도가 등장했지만, vision-to-audio generation에 대해 FMs을 적용하는 가능성은 여전히 불분명합니다.
사람이 세상을 인지하는데 있어 vision과 audio는 관련 있고 중요한 source입니다. 사람들은 visual event를 봤을 때 그에 대응하는 sound를 상상하는 능력을 갖고 있습니다. 사람과 같이 cross-modal generation abiltiy를 모방하는 것은 가상현실에서 몰입감을 강화하거나, content 제작자를 위한 video 편집 자동화, 시각 장애인을 돕는 다양한 scenario에서 적용 가능합니다. 저자들은 특정 domain sound type에 국한되지 않고 visual input에 맞춰 더욱 다양하고 실제 같은 자연스러운 sound를 생성하는 것을 목표로 합니다.
이러한 open-domain V2A generation 문제를 풀기 위해, 현재 method들은 보통 제한된 크기의 dataset으로 개별적으로 최적화된 sub-module로 구성된 복잡한 system을 사용합니다. 구조는 아래와 같습니다.

각 module을 개별적으로 학습하는 것은 번거로우며, train data가 부족하여 각 module의 generalization 성능이 제한될 수 있습니다.
이 논문에서 저자들은 open-domain vision-to-audio generation task에 foundation model을 채택하는 가능성을 탐구합니다. 위 그림의 (b)와 같이, 저자들의 lightweight method는 vision representation FM CLIP과 audio generative FM AudioLDM 사이 domain gap을 연결시키도록 V2A-Mapper만 학습하면 됩니다. V2A-Mapper는 audio representative FM CLAP에 의해 supervise되어 visual space를 auditory space로 translation 되는 것을 학습합니다. foundation model의 일반화 성능과 knowledge transfer 성능을 사용하여, V2A-Mapper는 적당한 크기의 dataset을 가지고 학습되지만, 전체 system은 훨씬 더 나은 성능을 달성할 수 있습니다. 저자들의 contribution은 다음과 같습니다. 1) FMs을 vision-to-audio generation에 적용하는 것에 대한 가능성을 조사합니다, 2) visual and auditory FMs를 연결하는 간단하지만 효과적인 V2A-Mapper를 제안합니다, 3) V2A-Mapper의 generative & regression strategy에 대해 조사했습니다, 4) 두 개 V2A dataset에 대한 subjective and objective evaluation에서 저자들의 method가 효율성과 효과를 입증했습니다. 86% 적은 parameter로 학습되었지만, FD와 CS에서 각각 53%, 19% 성능 향상을 달성했습니다.
Method
저자들의 lightweight solution은 visual encoder FM (CLIP), audio encoder FM (CLAP), audio generation FM (AudioLDM), trainable V2A-Mapper로 구성됩니다.

구조는 위와 같습니다. 위 그림은 frozen CLIp and CLAP model을 가지고 있는 V2A-Mapper를 어떻게 학습하는지, frozen CLIP과 AudioLDM model을 어떻게 통합하여 high-fidelity and visually-aligned sound를 생성하는지 나타냅니다.
Selected Foundation Models
저자들은 현재 가장 좋은 성능을 보여주는 vision representation, audio representation, audio generation FMs을 foundtaion model로 선택했습니다. 다른 model들로 대체할 수 있습니다.
- CLIP
저자들의 V2A generation task는 두 가지 modality에 걸쳐 있기 때문에, multi-modal FMs을 적응시키는 것은 여러 domain이 포함된 task에서 semantic feature를 사용하는 자연스러운 방식입니다. CLIP은 text-image representation model이며, 이는 contrastive learning을 통해 400M paired text and image data 사이 유사도를 maximize하도록 학습되었습니다. CLIP을 통해 학습된 vision space는 high-level semantic meaning인 language supervision을 통해 guide 되기 때문에, visual feature는 semantic information이 풍부합니다. 그러므로 저자들은 pre-trained CLIP model을 사용하여 visual prompt의 feature를 extract 합니다.
- CLAP
CLAP은 최근 등장한 largest audio representation FM이며, 2.5M text-auido paired data로 학습되었습니다. CLIP과 유사하게, CLAP은 language supervision을 사용하는 contrastive learning을 통해 joint text-audio embedding space를 학습합니다. CLIP과 CLAP을 사용한 주요한 이유로 둘 모두 학습할 때 common domain으로 text modality를 공유하기 때문입니다. 저자들은 더 쉽게 vision을 audio로 변환하도록 text가 bridge 역할을 할 수 있다고 가정했습니다.
- AudioLDM
AudioLDM은 3.3M 10초 길이 audio clip으로 self-supervised 방식으로 학습된 continuous latent diffusion model (LDM)입니다. CLAP audio embedding을 condition으로 사용하여 audio mel-spectrogram의 latent code을 생성하여 audio waveform으로 decode 하고 변환합니다. original work는 text-to-audio (T2A) generation task의 LDM 부분에 대해서만 연구를 진행했습니다. CLAP은 text와 audio를 동시에 나타내기 때문에, AudioLDM은 T2A task에 적응될 때 text를 input으로 받을 수 있습니다. 비록 AudioLDM이 주로 T2A generation task을 위해 제안되었지만, AudioLDM은 audio feature에 더 자연스럽게 적응할 수 있습니다. 이는 저자들이 visual feature를 CLAP space에서의 그에 대응하는 audio embedding으로 translate 할 수 있다면, AudioLDM을 완전히 수정하지 않고 기존의 audio generation FM으로 사용할 수 있을 것이라고 생각했습니다.
- Bridge the Domain Gap Between Vision and Audio
CLIP과 CLAP으로 학습된 vision and audio space 사이의 domain gap 차이가 존재하는지 조사했습니다. random 하게 video dataset VGGSound에서 5000개 sample을 선택하여 visual feature 분포와 auditory feature 분포 사이를 추정했습니다. 구체적으로 pre-trained CLIP image encoder을 사용하여 video frame을 512-d feature vector로 encode 하고 난 후 time axis에 맞춰 평균을 구해 각 video마다 1개 single embedding을 얻었습니다. audio data의 경우, 저자들은 pretrained CLAP audio encoder를 사용하여 각 audio sample을 512-d feature vector로 project 하였습니다. 그 다음 UMAP visualization을 사용하여 5000개 CLIP image embedding과 5000개 audio embedding을 동일한 2-d space로 project하였습니다. 결과는 다음과 같습니다.

paired visual (CLIP) feature와 audio (CLAP) feature 사이 average cosine similarity는 0에 가깝고, CLIP image domain과 CLAP audio domain 사이 상당한 간극이 존재합니다.
이 domain gap을 줄이기 위해, 저자들은 V2A-Mapper라는 mapper를 학습할 것을 제안합니다. CLIP과 CLAP사이를 mapping 하며, visual embedding이 CLAP space로 변환됩니다. 학습 pipeline은 아래와 같습니다.
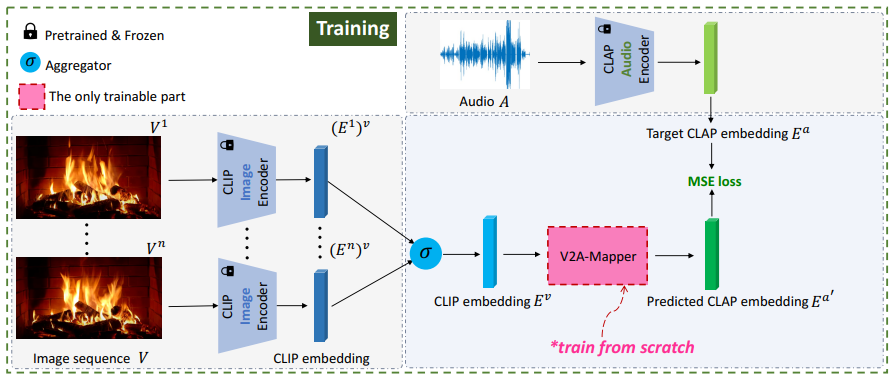
video V_i는 n개 image sequence {V_i^1, ... , V_i^n}입니다. video에 대한 visual embedding을 얻기 위해, frozen CLIP model을 사용하여 각 frame을 512-d feature vector로 encode 하여 frame feature를 얻습니다. 그다음 저자들은 aggregator function σ를 사용하여 single vector E_i^v를 구해 video input에 대한 visual feature로 사용합니다. aggregator function은 random 하게 1개 vector를 선택하거나, middle frame의 vector를 선택하거나, 시간 축에 따라 평균화한 값을 사용합니다. 저자들은 실험을 통해 시간 축에 따라 평균화한 값을 사용하는 것이 fidelity와 relevance 측면에서 가장 좋은 성능을 보여준다는 것을 알아냈습니다. 유사하게 paired audio data A_i에 대해, 저자들은 frozen CLAP model을 사용하여 512-d feature vector E_i^a를 encode합니다. paired visual feature E_i^V and auditory features E_i^a를 구한 후, CLIP embedding을 pseudo CLAP embedding E_i^a'로 convert하는 mapper를 학습합니다. 저자들은 MSE loss를 사용하여 학습을 guide합니다.

K는 batch size를 나타내고 E_i^a'는 mapper(E_i^v)에서 구해집니다.

위 그림은 학습 후 domain shift를 보여줍니다. mapper는 초기에는 random하게 초기화되기 때문에 변환된 embedding cluster가 여전히 target CLAP space와는 거리가 있습니다. 학습이 끝난 후에는, 변환된 space와 target CLAP space는 overlap 되며, 성공적으로 mapper가 최적화되었음을 보여줍니다.
- Diffusion-based V2A-Mapper
mapper가 visual space에서 얻은 embedding을 audio space로 project 시킬 것으로 기대되기 때문에, mapper를 구현하는 자연스러운 방법으로 multilayer perceptrons (MLPs)을 stack 하여 one-to-one regression task로 하는 것입니다. DALLE2의 prior model에 영감을 받아, 저자들은 projection process를 conditional generation task로 고려했습니다. 이는 one-to-many mapping을 model 하여 target audio 분포의 다양성과 일반화를 보장합니다. 구체적으로 저자들은 diffusion model을 mapper로 사용하여 학습했습니다. standard gaussian distribution이 될 때까지 gaussian noise를 점진적으로 추가하는 forward process를 timestep T번 사용합니다. 그리고 noisy distribution에서 target을 recover 하기 위해 recursive 방식으로 점진적으로 noise를 제거하는 reverse process를 수행합니다. DALLE2를 따라, 각 step에서 추가된 중간 noise를 예측하는 대신, 저자들은 바로 target embedding을 predict 합니다. 그러므로 저자들은 mapper network f_θ가 visual embedding을 condition으로 사용하여 t번 timestep마다 noisy audio embedding을 예측하여 최종 audio embedding을 구하도록 학습합니다. 학습 objective는 다음과 같습니다.

저자들은 mapper network로 simple MLP와 Transformer를 사용하여 실험을 진행했습니다. Transformer에서 출력된 512-d learnable token을 recovered audio embedding으로 사용합니다. 그다음 time embedding, noisy audio embedding 뿐만 아니라 visual condition을 동일한 shape의 token으로 받아서 Transformer encoder에 입력하여 recovered audio embedding을 얻습니다. simple MLP의 경우, 3가지 token을 concatenate 하여 input으로 사용하고 fully-connected network를 통해 512-d vector를 output 하여 predicted audio embedding으로 사용합니다. 저자들은 Transformer가 MLP와 비교했을 때 condition을 더 잘 통합한다는 것을 발견했습니다.
Experiments
Experimental Setup
- Datasets
저자들은 V2A-Mapper와 변형된 version들을 VGGSound video dataset으로 학습했습니다. VGGSound는 YouTube에 upload 된 video에서 추출된 199,176개 10초 video clip을 포함하며, audio-visual correspondence가 있습니다. 저자들의 foundation model은 VGGSound를 가지고 학습되지 않습니다. original train/test split에 따라, 저자들은 183,730개 video로 학습하고 15,446개 video로 evaluate 했습니다. 저자들의 V2A-Mapper의 일반화 성능을 증명하기 위해, 저자들은 out-of-distribution dataset ImageHear를 가지고 test 했으며, 이 dataset은 30개 class로 구성된 101개 image를 포함합니다. 각 class는 2~8개 image를 가지고 있습니다. 저자들은 evaluation 할 때, 10초 audio sample을 생성했습니다.
- Metrics
저자들은 visual prompt에 대한 fidelity와 relevance라는 두 관점에서 성능을 평가했습니다. 구체적으로 Frechet Distance (FD)를 사용하여 생성된 audio clip의 전반적인 quality와 다양성을 평가하였습니다. FD는 합성된 sample의 embedding 분포와 real sample의 embedding 분포 사이 거리를 계산합니다. 이전 method와 비교하기 위해, 저자들은 Frechet Audio Distance (FAD)도 사용했습니다. FD와 FAD는 embedding extractor가 서로 다른데, FD는 PANNs를 사용하지만 FAD는 VGGish를 사용합니다. 저자들은 PANNs이 VGGish보다 long distance temporal change를 더 잘 고려하기 때문에, FD를 sound quality에 대한 main evaluation metric으로 사용했습니다. relevance evaluation으로 CLIP-Score (CS)를 사용하였습니다. 이는 visual input에 대한 CLIP embedding과 generated sound의 Wav2CLIP embedding 사이 cosine similarity를 계산합니다. Wav2CLIP은 frozen CLIP image encoder의 guidance를 통해 contrastive loss를 사용하여 audio encoder를 학습하기 때문에, 생성된 sound가 visual input가 맞다면 Wav2CLIP embedding은 pair를 이루는 CLIP embedding과 유사할 것으로 예상됩니다.
- Subjective Testing
objective metric을 보완하기 위해, 저자들은 generated audio clip과 관련된 visual prompt 사이 fidelity를 측정하기 위해, linstening test를 진행했습니다. 저자들은 20명 listener에게 random 하게 선택된 20개 visual sample을 보여주면서 fidelity와 relevance 관점에서 5-point scale 평가를 요청했습니다. 모든 listener에게서 얻은 점수를 평균 내여 Mean Opinion Score (MOS)를 구했습니다. 저자들은 또한 결과를 paired comparison으로 re-code 하고 간접적인 scaling을 통해 상대적인 순위를 추정합니다. 다른 방식들이 저자들의 방법보다 얼마나 뛰어난지를 JMD (Just Meaningful Difference) 점수로 계산합니다. 음수의 경우, 해당 algorithm이 저자들의 method보다 좋지 않음을 나타냅니다.
- Implementation Details
저자들은 "ViT-B/32" version CLIP model을 사용했습니다. CLAP model과 audio generator의 경우, 저자들은 pretrained AudioLDM에서 가져와 사용했습니다. diffusion based V2A-Mapper의 경우, 저자들은 학습할 때 1000 diffusion step cosine noise schedule을 사용하고, inference 때는 200 step을 사용했습니다. batch size로 448개 visual-audio embedding pair를 사용했으며, dropout rate가 0.1인 classifier-free guidance를 사용했습니다.
Compare with SOTA
IM2Wav는 open-domain vision-to-audio generation에서 가장 좋은 성능을 보이는 method입니다. 이는 latent code 생성을 위한 두 개의 다른 규모의 Transformer decoder, audio mel-spectrogram을 encode 하고 decode 하는 VQ-VAE, waveform conversion을 수행하는 vocoder로 구성됩니다. CLIPSonic-IQ는 저자들의 연구와 동시적인 연구로, visual representation을 condition으로 하여 mel-spectrogram을 생성하도록 학습된 diffusion model입니다. 이는 BigVGAN을 학습하여 generated mel-spectrogram을 audio waveform으로 변환합니다. 이 method들과 비교했을 때, 저자들의 방법은 single V2A-Mapper만 학습시키면 됩니다. 동일한 size의 VGGSound data로 학습했을 때, 저자들의 method가 foundation model의 knowledge transfer 덕분에 더 좋은 성능을 달성했습니다.
- Objective Results

위 표를 통해 저자들의 method가 모든 objective metric에서 뛰어난 성능을 보여준다는 것을 보였습니다.

뿐만 아니라 위 그림을 통해 VGGSound에 대한 FD와 CS 결과를 보여주고 있습니다. 저자들의 model이 더 적은 학습 가능한 parameter가 있음에도 불구하고 더 좋은 relevance, fidelity 성능을 보여줍니다. Im2Wav와 비교했을 때, 저자들의 model은 86% 적은 parameter를 포함하고 있지만, FD는 53% 향상되었고 CS는 19% 향상되었습니다. 그리고 저자들의 model이 Im2Wav보다 24배 더 빠른 inference speed를 보여준다는 점도 주목할 부분입니다. 저자들의 method는 CLIPSonic-IQ보다도 더 적은 parameter를 가지고도 모든 metric에서 더 좋은 성능을 보여주며 inference speed도 더 빠릅니다. 저자들의 method가 reference보다 더 뛰어난 CS를 보여주는데, 저자들은 VGGSound에 포함된 audio와 visual stream이 반드시 높은 관련성을 가지지 않는 noise data가 있기 때문이라고 추정하며, 이는 저자들의 method가 noise가 있는 data에 대해 robust 하다는 것을 의미한다고 합니다.
- Subjective Results


위 표와 figure를 통해, 저자들의 method가 이전 연구들보다 fidelity와 relevance 관점에서 모두 뛰어나다는 것을 보여줍니다. CLIPSonic-IQ와 저자들의 method를 보면 diffusion model을 사용하면 audio quality를 향상시킬 수 있다는 것을 확인할 수 있다고 합니다. CLIPSonic-IQ가 video를 input으로 받으면 relevance 측면에서 좋지 않은 모습을 보이는 반면, 저자들의 method는 video와 image 모두에서 SOTA 보다 더 뛰어난 성능을 보여줍니다. 하지만 ground-truth와는 여전히 격차가 있다는 것을 볼 수 있습니다.
Ablation Study
- Different Ways of Utilizing FMs

AudioLDM은 text-to-audio generation을 목적으로 제안되었기 때문에, V2A 합성에 이를 바로 사용하는 방법은 captioning model을 통해 text input을 생성하도록 위 그림처럼 변경하는 것입니다. 이 vision-text-audio idea를 입증하기 위해, 저자들은 SOTA captioner BLIP을 사용하여 image에 대한 description을 생성했습니다. video-to-audio generation의 경우, 저자들은 VGGSound에서 주어지는 tag information을 사용하였습니다.

실험 결과는 위와 같습니다. text를 bridge로 사용하는 것이 어느 정도 gap을 완화할 수는 있지만, fidelity와 quality 모두에서 V2A-Mapper를 사용하는 저자들의 method보다 좋지 않은 모습을 보여줍니다. captioner가 bottleneck이라는 것을 의미하며, 이는 Audio LDM에서 생성될 audio를 직접적으로 영향을 미칩니다.
visual condition을 text format으로 decoding 하는 대신, 저자들의 V2A-Mapper는 visual information을 latent code form으로 유지하며 이를 CLIP의 visual space로부터 CLAP의 audio space로 변환합니다. 이는 vision-txt-audio conversion 과정에서 생길 수 있는 정보 손실을 피할 수 있습니다. V2A-Mapper를 skip 한다면, vision과 audio space 사이의 domain gap 때문에 AudioLDM이 관련 있는 소리를 생성하지 못합니다. 최근에 등장한 text-audio generation task model인 Make-An-Audio는 CLIP text embedding을 사용하여 audio generator를 학습했으며, visual-audio generation을 처리하기 위해 CLIP image embedding을 input으로 사용했습니다. "w/o mapper" 방식과 유사하게, visual information과 audio generator가 작동하는 embedding space 간의 domain gap이 해결되지 않았습니다.
- Inside the Mapper: Generative vs Regression
V2A-Mapper는 generative or regression strategy로 이행될 수 있습니다. generative V2A-Mapper는 one-to-many mapping을 학습하지만, regression은 one-to-one projection을 학습합니다.

실험 결과는 위와 같습니다. regression model이 one-to-one mapping을 통해 약간 더 나은 relevance를 학습할 수 있지만, FD가 좋지 않은 것을 보아 생성된 sound는 diversity와 fidelity가 부족합니다. generative mapper는 text-to-image 합성에서 관측되었던 것처럼 다양성도 보장되어야 합니다. 저자들의 method의 다양성을 보여주기 위해, 저자들은 input visual input에 대한 3가지 sample을 보여줍니다. 그리고 linear projection과 비교할 때, Transformer에서 사용된 attention mechanism이 visual condition을 더 잘 통합하는 것을 보여줍니다.
- Different Aggregator Methods σ
저자들은 video의 visual information을 aggregating 하는 3가지 방식에 대해 탐구합니다. 1) random 하게 frame을 key frame으로 선택하여 video를 표현하기, 2) random frame 대신 middle frame을 선택하여 video를 표현하기, 3) 모든 frame에 대한 CLIP feature를 구해 시간 축을 따라 평균을 구하여 video를 표현하기, 입니다.

서로 다른 방식들에 대한 실험 결과는 위와 같습니다. task는 large time-span (10초)의 highly dynamic signal (audio)을 생성하는 것이기 때문에, 시간 관련 information을 condition으로 사용하는 것이 도움을 줄 수 있습니다. video의 temporal dynamic 전체에서 풍부한 의미적 내용을 담고 있는 average abstract frame embedding이 single frame embedding보다 video에 대해 더 잘 요약합니다.
- Different Pretrained Vision FMs
저자들의 V2A-Mapper는 BLIP과 같은 다른 vision-language model에도 일반화될 수 있습니다.

위 표를 보면 알 수 있듯이, 저자들이 제안한 V2A-Mapper가 CLIP 또는 BLIP 기반 system의 성능을 향상시킬 수 있습니다. 어떤 vision-language model이 사용되든, 그리고 vision space와 audio space 사이 domain gap이 얼마나 크든 상관없이, 제안된 V2A-Mapper는 gap을 연결시킬 수 있고 visual information을 audio space로 변환할 수 있습니다. 위 표의 두 system은 저자들의 V2A-Mapper와 비슷한 성능을 달성합니다.
- Different Pretrained Audio FMs
저자들은 AudioLDM으로 다양한 pretrained audio generator를 사용하여 실험을 진행했습니다: 1) audioldm-s가 base model이며, 2) audioldm-s-v2는 base model이지만 더 여러 step 학습한 model이고, 3) audioldm-1는 더 큰 architecture인 model입니다.

위 결과와 같이, model을 scaling 하고 학습을 더 많이 하는 것이 성능을 향상시킬 수 있습니다.
Latent Space Interpolation
visual condition을 CLAP latent space로 변환하기 때문에, 저자들은 visual or textual guidance에 따라 audio embedding을 interpolation 합니다. 간단화를 위해, 저자들은 두 embedding 사이 linear interpolation을 수행했습니다.

위 그림과 같이 interpolation은 개구리 소리에서 flute을 연주하는 남자의 image로 지정된 소리로, 또는 text description에 맞춰 target으로 수행될 수 있습니다. visual, text, audio가 실제로 three modality로 학습되지 않았음에도 불구하고 동일한 space에 의미적으로 모인 것을 주목할 수 있습니다. interpolation을 수행할 때 상대적으로 부드러운 변환이 일어나는 것을 들을 수 있는데, 이는 V2A-Mapper가 CLIP space에서 CLAP space로의 변환을 잘 학습한다는 것을 청각적으로 나타냅니다.
Limitation and Future Work
저자들의 approach가 상당한 성공을 달성했지만, 몇 가지 한계가 존재합니다. 먼저, system은 괜찮은 control을 수행할 수 없습니다. 생성된 sound는 일반적인 상황에서는 의미적 연관성을 나타내지만, 특정 detail에 대한 정밀한 제어는 하지 못합니다. 둘째, visual cues가 unclear subject (e.g., multiple object, blurry/demaged image)를 포함한다면 system은 잘 동작하지 못합니다. 셋째, system은 audio와 visual signal 사이 temporal alignment를 명시적으로 처리하지 않습니다.
Conclusion
이 논문에서 저자들은 open-domain vision-to-audio generation task을 수행할 때 foundation models (FMs)을 사용하는 것이 용이하고 효과적이라는 것을 보이는 연구를 진행했습니다. 저자들은 간단하지만 효과적인 mapper mechanism인 V2A-Mapper를 제안하며, 이를 통해 representative visual FM CLIP과 generative auditory FM AudioLDM 사이를 연결합니다. CLIP space의 visual feature를 auditory CLAP space로 변환하는 것을 학습하고 V2A-Mapper는 성공적으로 visual information을 auditory counterpart로 pass 하여 AudioLDM이 high-fidelity and visually-aligned sound를 합성합니다. 저자들의 method는 V2A-Mapper만 최적화하면 되기 때문에, 상대적으로 학습하기 가볍습니다. 이러한 간단함에도 불구하고 subjective and objective evaluation 모두에서 훨씬 더 복잡한 학습 체계를 가진 최신 model들보다 더 뛰어난 성능을 달성합니다.



