https://arxiv.org/abs/2102.12841
Mask CycleGAN: Unpaired Multi-modal Domain Translation with Interpretable Latent Variable
We propose Mask CycleGAN, a novel architecture for unpaired image domain translation built based on CycleGAN, with an aim to address two issues: 1) unimodality in image translation and 2) lack of interpretability of latent variables. Our innovation in the
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
non-parallel voice conversion (VC)는 parallel corpus 없이 voice conversion을 학습하는 기술입니다. Cycle-consistent adversarial network-based VCs (CycleGAN-VC and CycleGAN-VC2)는 benchmark method로 많이 사용되었습니다. 하지만 time-frequency structure를 충분히 포착하지 못해, mel-spectrogram vocoder의 발전에도 불구하고 mel-spectrogram conversion이 아닌 mel-cepstrum conversion에서만 사용되고 있습니다. 이러한 단점을 극복하기 위해, time-frequency adaptive normalization (TFAN)이라 불리는 추가적인 module을 CycleGAN-VC2에 추가한 CycleGAN-VC3가 제안되었습니다. 이렇게 되면 학습해야 할 parameter 수가 늘어나게 된다는 단점이 존재하게 됩니다. 그래서 대안으로 저자들은 filling in frames (FIF)라는 새로운 auxiliary task로 학습되는 MaskCycleGAN-VC를 제안합니다. FIF에서는 input mel-spectrogram에 temporal mask를 적용하고 converter가 주변 frame을 기반으로 missing frame을 채우도록 도와줍니다. 이 task는 converter가 self-supervised 방식으로 time-frequency 구조를 학습하고 TFAN과 같이 추가적인 module의 필요성을 제거해 줍니다.
Introduction
기존 CycleGAN voice conversion method들은 완벽히 time-frequency structure를 capture 하지 못하는 모습을 보이며, mel-spectrogram based vocoder들이 많이 등장했음에도 불구하고 mel-cepstrum conversion만 수행하는 단점이 존재합니다.
이를 해결하기 위해 CycleGAN-VC2의 variation인 CycleGAN-VC3가 제안되었습니다. 이는 time-frequency adaptive normalization (TFAN)이라 불리는 추가적인 module을 사용합니다. 성능이 뛰어나지만, converter의 parameter 수가 증가된다는 문제가 발생합니다(16M to 27M).
그래서 저자들은 CycleGAN-VC2의 variation으로 MaskCycleGAN-VC를 제안합니다. 이는 filling in frames (FIF)라 불리는 새로운 auxiliary task를 이용해 학습됩니다. FIF를 이용해 저자들은 input mel-spectrogram에 temporal mask를 추가하고 converter가 가려진 frame을 주변 frame을 이용해 채우도록 만듭니다. FIF는 image inpainting, text infilling과 같은 다른 분야들에서 사용하는 complementation-based self-supervised learning의 성공에서 영감을 받았습니다. 이를 통해 converter가 time-frequency feature를 학습하도록 만들어줍니다. 이러한 특성 덕분에 TFAN과 같은 추가적인 module의 필요성을 제거하였으며 CycleGAN-VC2의 network 수정을 거의 진행하지 않은 채로 mel-spectrogram conversion에서도 동작할 수 있게 만들어줍니다.
Conventional CycleGAN-VC2
CycleGAN-VC2는 parllel supervision 없이도 converter GX→Y가 source acoustic feature x∈X를 target acoustic feature y∈Y로 변환하도록 학습됩니다. unpaired image-to-image translation을 위해 제안된 CycleGAN에 따라, CycleGAN-VC2는 adversarial loss, cycle-consistency loss, identity-mapping loss를 사용해 문제를 해결합니다. 추가적으로 CycleGAN-VC2는 second adversarial loss를 사용해 cyclically reconstructed feature의 quality를 향상시킵니다.
Adversarial loss
adversarial loss LX→Yadv는 converted feature GX→Y(x)가 target처럼 되도록 만들어 줍니다.

위 식에서 discriminator DY는 generated GX→Y(x)와 real y를 구분하여 loss를 maximize 하지만, GX→Y는 DY를 속여 loss를 minimize 하도록 Gx→Y(x)를 생성합니다. 비슷하게 inverse converter GY→X는 LY→Xadv와 discriminator DX를 가지고 학습됩니다.
Cycle-consistency loss
cycle-consistency loss LX→Y→Xcyc는 변환된 feature를 다시 soruce feature로 inverse conversion을 수행했을 때, 둘이 유사해지도록 만들어줍니다.
유사하게 inverse-forward mapping (i.e., GX→Y(GY→X(y)))도 LY→X→Ycyc로 학습됩니다.
Identity-mapping loss
identity-mapping loss LX→Yid는 input preservation 향상을 위해 사용됩니다.
비슷하게 inverse converter GY→X도 LY→Xid를 이용해 학습됩니다.
Second adversarial loss
second adversarial loss LX→Y→Xadv2는 위 식(2)의 L1 loss에 의해 생기는 statistical averaging을 완화시켜 줍니다.
discriminator D′X는 reconstructed GY→X(GX→Y(x))와 real x를 구분합니다. 위 식과 유사하게 inverse-forward mapping with additional discriminator D′Y는 LY→X→Yadv2로 학습됩니다.
Full objective
full objective Lfull은 다음과 같습니다.
위 식에서 λcyc과 λid는 weight parameter입니다. GX→Y와 GY→X는 loss를 minimize 하도록 학습되며, DX,DY,D′X,D′Y는 loss를 maximize 하도록 학습됩니다.
MaskCycleGAN-VC
Training with Filling in Frames (FIF)
CycleGAN-VC2는 mel-cepstrum conversion을 수행하도록 개발되었으며, mel-spectrogram conversion의 time-frequencyh structure를 capture 할 수 없습니다. 결과적으로 harmonic structure가 손상되게 됩니다. 이를 완화하기 위해, 저자들은 MaskCycleGAN-VC를 제안합니다. 이는 auxiliary FIF task를 사용하여 학습됩니다. 저자들의 overall framework는 다음과 같습니다.
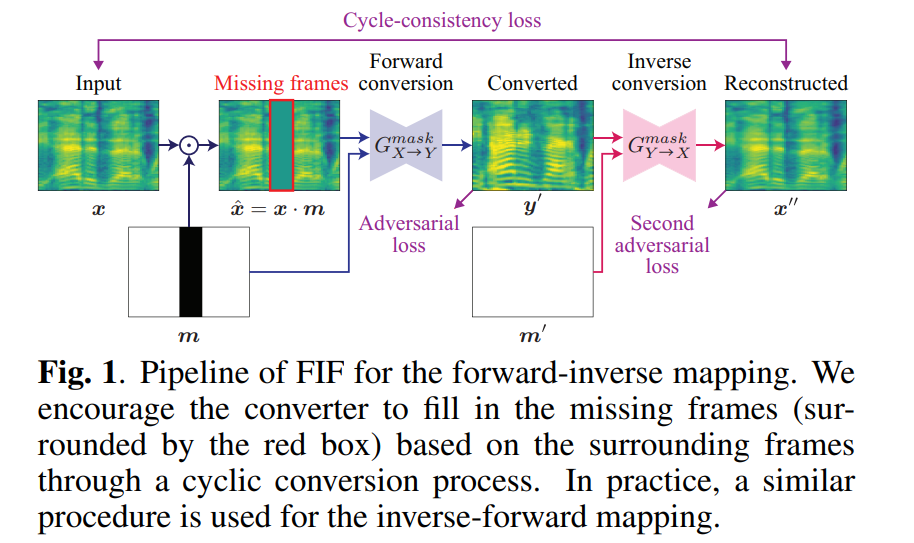
source mel-spectrogram x가 주어졌을 때, x와 동일한 크기의 temporal mask m∈M을 생성합니다. 이는 masking 하는 영역(위 그림에서 까만 영역)을 0으로 채우고 나머지 영역을 1로 채웁니다. masked region (i.e., zero region)은 사전에 정의된 rule에 따라 random 하게 결정됩니다.
생성한 mask m을 x에 적용하여 ˆx를 만듭니다.

위 식에서 ⋅은 element-wise product를 의미합니다. 이 연산을 통해, 저자들은 missing frame을 생성합니다. 위 그림에서 red box 영역입니다.
그다음 MaskCycleGAN-VC converter GmaskX→Y는 ˆx,m으로 y′을 합성합니다.
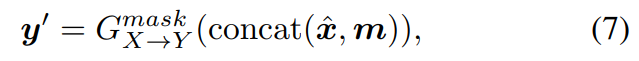
위 식에서 concat은 channel-wise concatenation을 의미합니다. m을 conditional information으로 사용함으로써, GmaskX→Y는 어느 frame을 채워야 하는지 아는 상태로 frame을 채웁니다.
CycleGAN-VC2와 비슷하게 저자들은 adversarial loss를 이용해 y′가 target Y에 존재하도록 학습되지만, parallel supervision이 없기 때문에 ground-truth와 y′을 바로 비교할 수 없습니다. 그래서 저자들은 cyclic conversion process를 이용해 frame을 채우는 것을 학습시킵니다. 이를 위해, 저자들은 inverse converter GmaskY→X를 이용해 x″를 reconstruct 합니다.
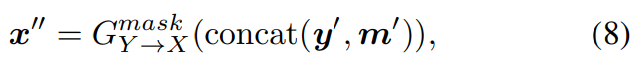
위 식에서 m′은 모든 영역이 1로 채워진 matrix를 의미하며, missing frame이 이전 forward를 통해 채워진 상태를 의미합니다. 그다음 original and reconstructed mel-spectrogram에 cycle-consistency loss를 사용합니다.
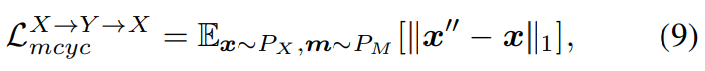
동시에 저자들은 x″에 second adversarial loss를 적용합니다.
LX→Y→Xmcyc를 최적화하기 위해, GmaskX→Y는 주변 frame에서 missing frame을 채우기 위한 유용한 정보를 얻어야 합니다. 이러한 induction은 self-supervised 방식으로 mel-spectrogram의 time-frequency structure를 학습하기 유용합니다. 이는 다른 분야에서 유사한 task를 수행할 때 사용했던 방식입니다. 최종적으로 TFAN을 사용하는 CycleGAN-VC3와 다르게, MaskCycleGAN-VC는 converter parameter 수의 큰 증가는 없으며(m을 받기 때문에 input channel 수가 2배로 증가되기만 함), FIF는 추가적인 data와 pretrained model을 필요로 하지 않습니다.
Conversion with all-ones mask
저자들은 conversion process (i.e., test phase)에서 all-one mask를 사용하였습니다. 그래서 저자들은 frame missing 없다는 가정 하에서 변환을 진행합니다.
Experiments
Conversion and synthesis process
CycleGAN-VC3와 비교하기 위해, 저자들은 CycleGAN-VC3와 동일한 conversion and synthesis를 수행했습니다. 저자들은 mel-spectrogram conversion을 수행할 때는 MaskCycleGAN-VC를 사용했으며 waveform을 합성할 때는 pretrained MelGAN vocoder를 사용했습니다. 공평한 비교를 위해 저자들은 vocoder의 parameter를 바꾸지 않았지만, 각 speaker 마다 fine-tuning을 수행했습니다.
Objective evaluation
저자들은 objective evaluation을 수행해 성능을 평가했습니다. mel-cepstral distortion (MCD)와 Kernel DeepSpeech Distance (KDSD)를 사용하였습니다. MCD의 경우, WORLD analyzer를 이용해 mel-cepstrum을 추출했습니다. KDSD는 DeepSpeech2 feature space에서 maximum mean discrepancy를 계산합니다. 실험 결과는 아래와 같습니다.
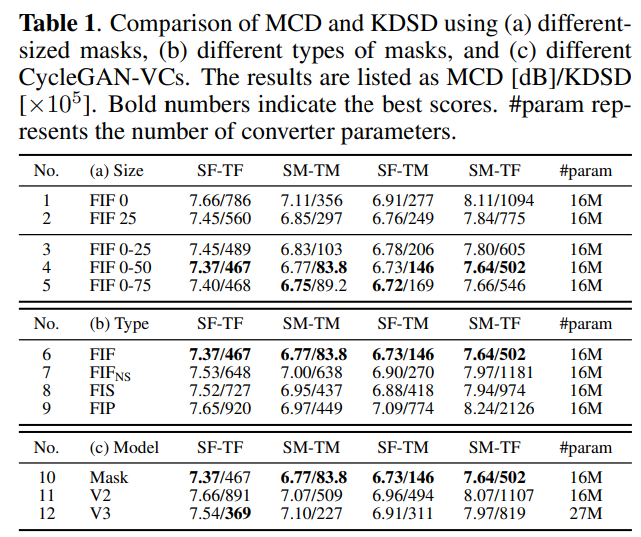
FIF mask size에 따른 결과를 보겠습니다. FIF X의 경우, X%를 masking 했다는 것을 의미합니다. FIF 0-X는 0에서 X% 사이 random 하게 mask size를 선택한다는 것을 의미합니다. No 2~5를 통해 non-zero-sized-mask가 zero-sized mask보다 뛰어난 성능을 보인다는 것을 알 수 있습니다. 그리고 No 4를 통해 mask size를 최대 50 정도로 설정하는 것이 가장 좋다는 것을 볼 수 있습니다. 그리고 constant-sized mask보다 random-sized mask가 더 나은 모습을 보인다는 것도 알 수 있습니다.
FIF는 subsequent frame을 masking 하는 것을 의미하고, FIFNS는 각 frame들을 독립적이고 random하게 선택해 masking하는 non-subsequent frame masking을 의미합니다. FIS는 subsequent spectrum band를 masking하는 것을 의미합니다. FIP는 mel-spectrogram을 point-wise masking 방식으로 masking하는 것을 의미합니다. 전부 0-50 masking size를 사용했으며, No 6을 통해 FIF가 가장 좋은 성능을 보인다는 것을 알 수 있습니다.
Conclusion
mel-spectrogram vocoder의 최근 발전에 영감을 받아, 저자들은 CycleGAN-VC2를 mel-spectrogram conversion에 적용할 수 있도록 발전시킨 MaskCycleGAN-VC를 제안합니다. TFAN과 같은 추가적인 module 없이도 mel-spectrogram의 time-frequency structure를 학습하기 위해, FIF를 도입했습니다. 이는 converter가 self-supervised manner로 time-frequency structure를 학습할 수 있도록 도와줍니다. 실험을 통해 MaskCycleGAN-VC가 CylceGAN-VC2와 비슷한 크기지만, 다른 CycleGAN model보다 뛰어난 성능을 보인다는 것을 입증했습니다.



