Analysing Diffusion-based Generative Approaches versus Discriminative Approaches for Speech Restoration
Diffusion-based generative models have had a high impact on the computer vision and speech processing communities these past years. Besides data generation tasks, they have also been employed for data restoration tasks like speech enhancement and dereverbe
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
diffusion-based generative model은 최근 몇 년 동안 computer vision, speech processing에서 큰 영향을 미쳤습니다. data generation task 외에도, speech enhancement와 dereverberation과 같은 data restoration task에서도 사용되고 있습니다. 기존에는 discriminative model이 speech enhancement와 같은 task에서 powerful 하다고 여겨졌으나, 최근엔 diffusion model이 performance gap을 상당히 좁힌 것으로 나타났습니다. 이 논문에서 저자들은 generative diffusion model과 discriminative approach의 성능을 비교하였습니다. 저자들은 generative approach가 discriminator approach보다 전반적으로 더 나은 성능을 보인다는 것을 발견했으며, 특히 reverberation과 bandwidth extension과 같은 non-additive distortion model에서 좋은 성능을 보인다는 것을 발견하였습니다.
Introduction
이 논문에서 저자들은 다양한 speech restoration task에서 동일한 deep neural network architecture를 사용하는 generative diffusion model과 discriminative model의 성능을 분석하였습니다. 저자들은 complex spectrogram domain에서 동작하는 diffusion process를 사용하였습니다. 저자들은 다양한 simulated corruption과 recorded background noise를 사용하는 WSJ0 corpus로 generative and discriminative model 사이 성능 차이를 확인하였습니다. 최종적으로 저자들의 bandwidth extension model을 SOTA bandwidth extension method와 비교하였습니다.
Speech Restoration Tasks and Related Work
Speech enhancement
speech enhancement는 corrupted mixture $y$로부터 clean speech target $s$를 추출하기 위해 additive interference n (e.g., background noise or interfering speakers)를 제거하는 작업을 의미합니다.

Wiener-inspired spectral filtering, discriminative machine learning method, denoising variational auto-encoder와 같은 generative approach들이 대표적인 enhancement method입니다. 최근엔 time domain이나 complex time-frequency (T-F) domain에서 diffusion model을 사용하여 speech enhancement를 수행하는 연구들이 등장하고 있습니다.
Speech dereverberation
reverberation은 실내 음향에 의해 발생하며, 방 구조에 의한 multiple reflection이 특징입니다. 특히 late reflection이 speech signal를 저하시켜 intelligibility를 reduce할 수 있습니다. corruption model은 convolutive model로 표현되며,
clean speech $s$에 source와 listener 사이 acoustic path를 나타내는 room impulse response (RIR) $h$를 convolve합니다. single-channel dereverberation method는 spectral enhancement, inverse filtering, cepstral processing 등 여러 method가 존재합니다.
Bandwidth extension
audio super-resolution, bandwidth extension는 low-sampling rate signal을 higher rate, regenerating time resolution, high-frequency content, high audio quality로 sample 된 version으로 변환하는 것을 목표로 합니다. corruption process는 linear 하며, anti-aliasing low-pass filter를 포함합니다.
$$ y = Resample(s * a, f_s^{up}, f_s^{low})$$
위 식으로 나타낼 수 있습니다. 위 식에서 $a$는 anti-aliasing filter impulse response를 나타내고, $f_s^{up}$은 original high sampling rate, $f_s^{low}$는 low sampling rate를 나타냅니다.
여러 discriminative method들이 제안되었습니다. generative adversarial network를 사용하는 neural vocoder 기반 generative approach, continuous-time diffsuion model 등 다양한 model들이 등장하였습니다.
Score-based Diffusion Models for Speech Restoration
score-based diffusion model은 3가지 component로 정의됩니다. forward diffusion process, score estimator, sampling method로 구성됩니다.
Forward and reverse processes
stochastic forward process ${\{x_t\}_{t=0}^T}$은 다음 Stochastic Differential Equation (SDE)의 solution으로 modeling됩니다.

위 식에서 $x_t$는 process의 current state의 index를 나타내며, $t\in[0,T]$ 입니다. initial condition $x_0$는 clean speech를 나타냅니다. 저자들의 process는 T-F domain에서 정의되기 때문에, $x_t$는 flattened complex spectrogram의 coefficient를 포함하는 $C^d$ space에서의 1차원 vector로 간주됩니다. 다른 변수들은 real scalar value를 나타냅니다. stochastic process $w$는 standard d-dimensional Brownian motion을 의미하고, $dw$는 각 T-F bin에서 표준편차가 $\sqrt{dt}$인 zero-mean Gaussian random variable임을 나타냅니다.
drift function $f$, diffusion coefficient $g$, initial condition $x_0$와 final diffusion time $T$는 unique하게 정의됩니다. $f, g$에 대한 regularity condition으로 인해 Kolmogorov equation의 해가 unique 하고 smooth 한 경우, reverse process $\{x_t\}_{t=T}^0$도 SDE의 solution인 diffusion process로 정의될 수 있습니다.

$d\bar{w}$는 time flow가 reverse일 때의 d차원 Brownian motion을 의미합니다. $\nabla_{x_t}log{p_t(x_t)}$는 score function으로, current process state $x_t$에 대한 logarithm data distribution의 기울기를 나타냅니다.
Speech restoration task는 corrupted speech $y$를 condition으로 하여 clean speech $x_0$를 생성하는 conditional generation task로 볼 수 있습니다.

저자들은 위 Ornstein-Uhlenbeck SDE의 solution을 forward process로 정의함으로써 diffusion process에서 바로 conditioning을 수행하도록 만들었습니다. 위 식에서 $\lambda$는 stiffness hyperparameter이고 $\sigma_{min}, \sigma_{max}$는 noise scheduling을 control 하는 hyperparameter입니다. 이를 통해 각 timestep에서 inject 되는 gaussian white noise 양을 조절합니다.

위 식에서 나타내는 forward process는 위 그림으로 볼 수 있습니다. 각 time step에서 각 T-F bin은 독립적이며, current process state $x_t$에 표준편차 $g(t)\sqrt{dt}$인 Gaussian noise와 적은 양의 corruption이 추가됩니다. initial state $x_0$와 $y$가 주어졌을 때, forward process는 perturbation kernel로 불리는 process state $x_t$의 Gaussian distribution으로 나타낼 수 있습니다.
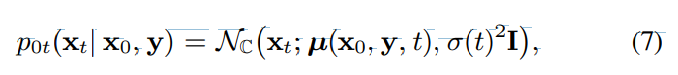
위 식에서 $N_C$는 원형 대칭 complex normal distribution을 나타내고, I는 identity matrix를 나타냅니다. 단순한 Gaussian kernel 덕분에 평균과 분산은 closed-form solution으로 정의될 수 있습니다.
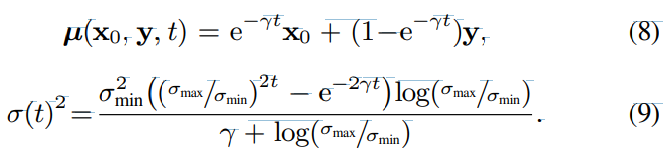
Score function estimator
reverse SDE를 통해 sampling을 수행할 때, score function $\nabla_{x_t}log{p_t(x_t)}$는 바로 사용할 수 없습니다. 그래서 score model이라 불리는 DNN $s_{\theta}$를 이용해 근사하였습니다. perturbation kernel $p_{0t}(x_t|x_0, y)$의 gaussian form과 평균 및 분산에서 유도되는 regularity condition을 고려하여, denoising score matching objective를 사용해 score model $s_{theta}$를 학습할 수 있습니다. perturbation kernel의 score function은 다음과 같습니다.
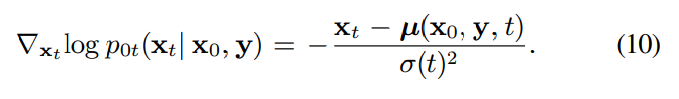
denoising score matching objective는 다음과 같이 reparameterize할 수 있습니다.
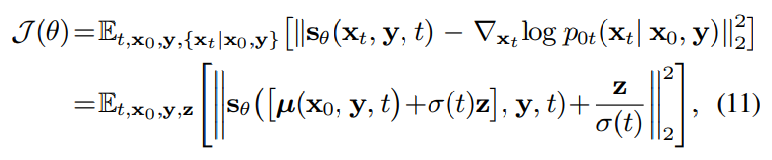
$x_t = \mu(x_0, y, t) + \sigma(t)z$, with $z \sim N_C(z; 0, I)$를 사용하여 정의합니다. $t$는 $[t_{\epsilon}, T]$에서 uniform 하게 sample 되고, $t_{\epsilon}$은 불안정성을 피하기 위한 minimal diffusion time입니다.
Inference through reverse sampling
inference 할 때, 먼저 저자들은 $x_T$라는 reverse process의 initial condition을 sample합니다.
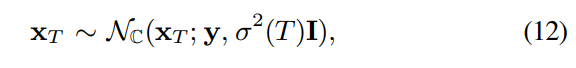
이 sample은 Gaussian noise with variance $\sigma(t)^2$를 더한 corrupted speech $y$를 의미합니다.
conditional generation은 t = T에서 t = 0으로의 plug-in reverse SDE를 통해 수행됩니다. score function은 estimator $s_{\theta}$로 대체되며, 학습을 통해 구해집니다.
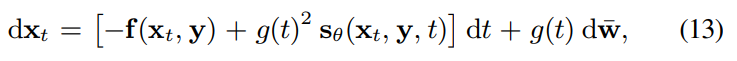
위 식에서 $f$는 drift function, g는 diffusion term입니다.
저자들은 $[0, T]$ 사이 N개 point를 사용해 discretization을 적용하여 classical numerical solver를 사용합니다. 각 reverse diffusion step에서 score network를 호출하기 때문에 diffusion model의 inference 시간이 discriminative 보다 2배 이상 깁니다. 그래서 이와 같은 방법을 사용하였습니다.
Experimental Setup
Evaluation metrics
speech enhancement와 dereverberation performance에 대한 중요 evaluation으로 저자들은 Perceptual Evaluation of Speech Quality (PESQ), extended short-term objective intelligibility (ESTOI), scale-invariant signal to distortion ratio (SI-SDR)을 사용하였습니다. bandwidth extension의 경우, 저자들은 log spectral distance (LSD)를 사용하였습니다. 하지만 이는 linstening experiment와는 잘 상관되지 않을 수 있습니다. DNN-based mean opinion score (MOS)인 WV-MOS를 사용하여 bandwidth extension performance를 평가하였습니다.
Experimental Result and Discussion
Speech Enhancement
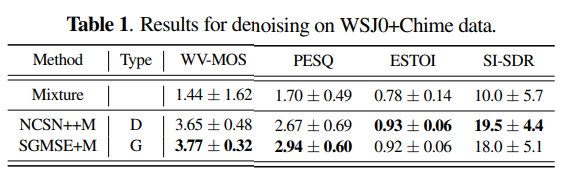
위 표는 WSJ0+Chime dataset에 대한 speech enhancement 결과입니다. generative SGMSE+M이 더 좋은 quality의 sample을 생성하는 것을 알 수 있습니다. 하지만 discriminative NCSN++M이 intelligibility, noise removal에 대해선 약간 더 좋은 모습을 보여줍니다. 하지만 discriminative approach는 low-energy speech region을 표현하지 못하는 경향을 보입니다. 그리고 generative approach는 train and test data가 많이 달라도 일관성 있는 모습을 보여준다는 장점이 있습니다.
Speech dereverberation
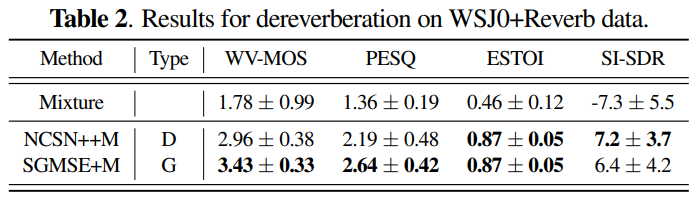
위 표는 WSJ0+Reverb dataset에 대한 dereverberation 결과입니다. generative SGMSE+M이 discriminative NCSN++M보다 WV-MOS & PESQ에서 크게 뛰어난 모습을 보여줍니다.
Bandwidth extension
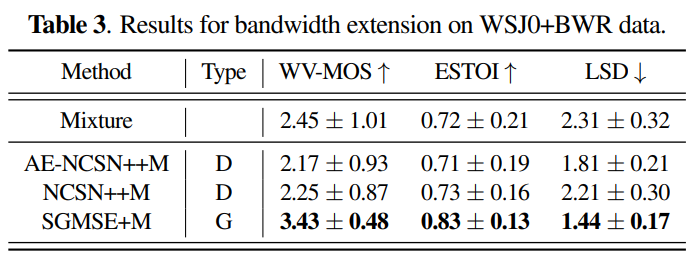
위 표는 WSJ0+BWR dataset에 대한 bandwidht extension 성능을 보여줍니다. STFT representation을 사용한 discriminative approach는 손실된 high-frequency content를 복원하지 못합니다. NCSN++M이 뛰어난 성능을 보여줌을 알 수 있습니다.
Conclusion
이 연구는 최근 diffusion 기반 generative approach들이 discriminative approach보다 다양한 speech restoration task에서 보여주는 잠재적 이점을 분석하는 것을 목표로 하였습니다. 저자들은 최근 제안된 diffusion generative 기반 speech enhancement, dereverberation, bandwidth extension model들과 discriminative approach를 비교하였습니다. generative approach가 모든 task에서 일반적으로 discriminative method보다 더욱 뛰어난 모습을 보인다는 것을 발견했으며, 특히 dereverberation, bandwidth extension과 같은 non-additive distortion model에서 더 뛰어난 모습을 보였습니다.



