https://arxiv.org/abs/2008.07788
CinC-GAN for Effective F0 prediction for Whisper-to-Normal Speech Conversion
Recently, Generative Adversarial Networks (GAN)-based methods have shown remarkable performance for the Voice Conversion and WHiSPer-to-normal SPeeCH (WHSP2SPCH) conversion. One of the key challenges in WHSP2SPCH conversion is the prediction of fundamental
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 GAN-based method들이 Voice Conversion과 WHiSPer-to-normal SpeeCH (WHSP2SPCH) conversion에서 주목받고 있습니다. WHSP2SPCH conversion의 주요 과제 중 하나는 fundamental frequency ($F_0$)를 예측하는 것입니다. 최근에 SOTA method인 Cycle-Consistent Generative Adversarial Networks (CycleGAN) for WHSP2SPCH conversion이 등장했습니다. CycleGAN-based methods는 Mel Cepstral Coefficients (MCC) mapping과 $F_0$ prediction을 사용하며, $F_0$는 pre-trained MCC mapping model에 크게 의존합니다. 이를 통해 predicted $F_0$에 non-linear noise가 추가된다는 단점이 발생하게 됩니다. 이 noise를 suppress 하기 위해, 저자들은 Cycle-in-Cycle GAN (i.e., CinC-GAN)을 제안합니다. 이는 MCC mapping 정확도 손실 없이 $F_0$ prediction의 효율성을 향상시키도록 design 되었습니다. objective and subjective test를 통해 저자들의 CinC-GAN이 CycleGAN보다 뛰어나다는 것을 입증하였습니다. 그리고 CycleGAN과 CinC-GAN의 unseen speaker에 대한 성능을 비교했으며 CinC-GAN의 우수성을 보였습니다.
Introduction
Whisper and normal speech는 서로 다른 의사소통 방식입니다. 사람들은 보통 normal mode로 말을 하지만, 공공장소에서의 통화, 회의, 도서관, 병원 등과 같이 대화를 숨겨야할 상황이 존재하며, 이러한 경우 사람들은 whisper mode conversion을 사용하여 의사소통을 진행합니다. whisper and normal speech는 생성 및 지각 방식에서 차이가 있기 때문에 cross-domain entity로 간주됩니다. speech가 주어졌을 때, normal speech인지 아닌지에 대한 결정은 후두 및 성문(glottis)의 상태에 따라 달라집니다. 때때로 사고나 질병으로 인해 speech 생성에 관여하는 부분에 영향을 받은 사람들은 normal speech를 만들지 못하기도 합니다. 사람이 normal style로 말을 할 때, vocal fold는 특정 fundamental frequency (i.e., $F_0$)로 진동하지만, whisper speech는 그렇지 않습니다. 그리고 current speech processing system은 normal speech를 제외한 speech 방식들에는 효과적으로 동작하지 않으며, WHSP2SPCH conversion task가 필요한 이유입니다.
WHSP2SPCH conversion의 주요 과제 중 하나는 $F_0$ prediction입니다. 하지만 $F_0$는 복잡한 방식으로 whispered speech에 encapsulate 되어 있습니다. $F_0$가 존재하거나 존재하지 않는 것은 normal speech와 whispered speech의 가장 큰 차이입니다. WHSP2SPCH conversion 시도들은 parallel data를 사용한 연구들만 존재합니다. LSTM, MSpecC-Net, DiscoGAN, CycleGAN 등 여러 method들이 그렇습니다. WHSP2SPCH conversion에서 SOTA를 달성한 $F_0$ preidction을 사용하는 CycleGAN은 parallel data를 사용하며 특정 speaker의 whisper, normal speech에 의존한다는 문제가 있습니다. 실용성이 매우 떨어진다는 단점이 있으며, parallel data를 전처리 과정에서 time-align 해야 합니다. traditional method는 WHSP2SPCH conversion을 수행하기 위해 2-step sequential method를 사용합니다. CycleGAN 기반 conversion의 경우, whisper to normal speech의 cepstral feature mapping을 수행할 수 있도록 CycleGAN을 학습시킵니다. 그다음 $F_0$ prediction을 위해 또 다른 CycleGAN이 학습되며, 이는 이전에 학습된 CycleGAN에 심하게 의존한다는 문제가 존재합니다. 완벽하지 않은 cepstral feature mapping 때문에, output에 noise가 추가됩니다. non-linear DNN layer가 존재해 non-linear noise가 $F_0$ prediction에 추가됩니다.
CycleGAN이 SOTA 결과를 보여줌에도 불구하고 여전히 original normal speech와 converted normal speech 사이 자연스러움 차이가 존재합니다. 이 gap을 줄이고 한계를 극복하기 위해, 저자들은 non-parallel WHSP2SPCH conversion task를 수행할 수 있고 non-parallel 방식으로 $F_0$ prediction을 수행하는 CinC-GAN을 제안합니다. CinC-GAN은 특히 naturalness에 중요한 요소인 $F_0$ prediction을 효과적으로 design 하였습니다. CinC-GAN은 joint training method를 사용하여 acoustic mapping과 $F_0$ prediction을 동시에 학습시킵니다. CinC-GAN에 대한 objective result는 $F_0$ prediction에 존재하는 non-linear noise를 surpress 할 수 있음을 보여줍니다. 그래서 $F_0-RMSE$가 baseline보다 감소된 결과를 보여줍니다. objective and subjective evaluation에서 gender-specific task에 대해선 seen and unseen speaker에 대한 분석도 진행하였습니다. CinC-GAN은 gender-specific task (seen and unseen speaker)에서 자연스러움을 유지했지만, CycleGAN은 좋지 않은 결과를 보였으며 whisper speech를 생성하는 모습을 보였습니다.
Conventional Cycle-GAN
각 $x \in R^N, y \in R^N$을 whisper (X)와 normal speech (Y)의 cepstral feature라고 하겠습니다. 여기서 $N$은 feature vector의 dimension을 나타냅니다. CycleGAN에서는 $G_{X \rightarrow Y}, G_{Y \rightarrow X}$라는 두가지 generator를 사용하며, $G_{X \rightarrow Y}$는 $X$에서 $Y$로의 cepstral feature mapping을 의미하며, $G_{Y \rightarrow X}$는 $Y$에서 $X$로의 mapping을 의미합니다. 그리고 2가지 discriminator $D_X, D_Y$를 사용하며, 각각 $X, Y$의 분포에서 input이 sample 된 것인지 아닌지 predict 합니다.
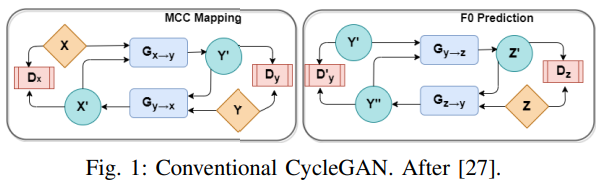
CycleGAN에서는 3가지 loss인 cycle-consistent loss, adversarial loss, identity loss를 사용합니다.
Adversarial loss
original과 구분되지 않는 converted normal speech를 만들기 위해, adversarial loss를 사용합니다. traditional binary cross-entropy loss를 사용하는 대신 least square error loss를 사용하였습니다.
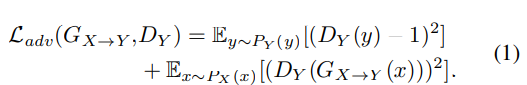
Cycle-consistent loss
이 loss의 main idea는 original distribution과 reconstructed data의 distribution을 mapping 하는 것입니다. 그리고 이 loss는 speech의 contextual information을 보존하도록 도와줍니다. 이 loss를 통해 non-parallel WHSP2SPCH conversion이 가능해집니다.
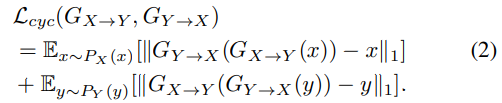
Identity-mapping loss
input linguistic content를 보존하기 위해, identity loss를 사용합니다.
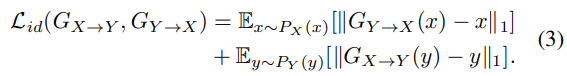
최종 total loss는 다음과 같이 정의됩니다.
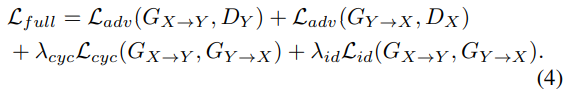
위 식에서 $\lambda_{cyc}$는 10으로, $\lambda_{id}$는 5로 설정했습니다. 이제 $F_0$ prediction을 위해, 또 다른 CycleGAN architecture를 학습합니다. $y' \in R^N$은 converted normal speech의 cepstral feature를 나타내고, 이는 MCC mapping을 위해 이전에 학습된 CycleGAN에서 추출된 feature입니다. $z \in R$은 original normal speech의 $F_0$입니다.
Proposed CinC-GAN
Problem formulation
WHSP2SPCH conversion의 conventional formulation은 cepstral feature mapping을 위한 $y' = f(x) + n$이고, $x$는 whisper speech feature, $f$는 mapping function, $n$은 additive noise입니다. $F_0$ prediction의 경우, $z = g(y') + n'$으로 정의되고 이는 $z = g(f(x) + n) + n'$이 되며, $g$는 mapping function, $n'$은 또 다른 additive noise를 의미합니다.
이러한 문제 상황에서, 저자들은 따로 학습된 mapping function과 $F_0$ prediction 때문에 non-linear noise가 추가된다는 것을 발견했습니다. 그래서 effective $F_0$ prediction과 noise를 surpress 하기 위해, 저자들은 동시에 학습될 수 있는 mapping function를 필요로 하고 $f(x)$대신 input에서 바로 rely 되는 방법을 필요로 합니다.
Proposed solution
이 논문에서 저자들은 Cycle-in-Cylce GAN (CinC-GAN)이라 불리는 CycleGAN의 advanced version을 제안합니다. 이는 WHSP2SPCH conversion을 위해 제안된 다른 학습 방식입니다. CycleGAN에서는 acoustic feature mapping을 위한 model과 $F_0$ prediction을 위한 model을 사용하였으며, 각각 분리되어 학습됩니다 (i.e., sequential training). 하지만 CinC-GAN에서는 acoustic feature mapping은 inner cycle에서, $F_0$ prediction은 outer cycle에서 처리되며, outer cycle은 converted normal speech의 cepstral feature와 input whisper speech에 의존합니다. 이를 통해 extra noise effect를 suppress 할 수 있습니다.
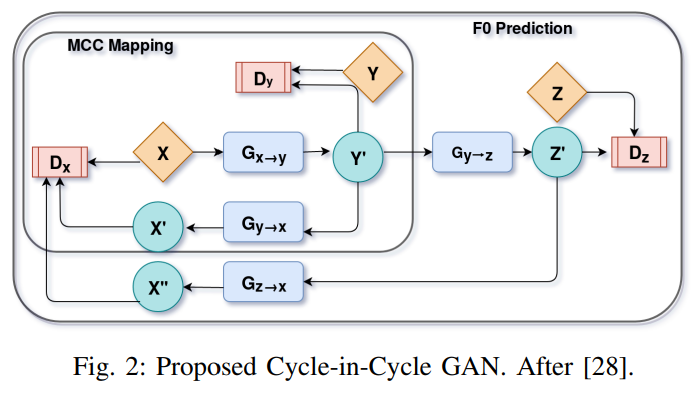
요약하자면, Cycle-in-Cycle GAN은 위와 같은 구조입니다. $X$ to $Y$, $Y$ to $X$ mapping을 각각 학습하는 2가지 CycleGAN을 사용합니다. non-parallel dataset $x \in X, y \in Y, z \in Z$를 사용해 학습하며, $X, Y$는 whisper and normal speech의 cepstral feature set이고 $Z$는 normal speech에서 추출된 $F_0$ set입니다.
- Acoustic feature mapping
위 그림의 inner cycle은 whisper speech의 cepstral feature $X$를 normal speech의 cepstral feature $Y$로 mapping 합니다. 2가지 generator $G_{X \rightarrow Y}, G_{Y \rightarrow X}$를 사용하며, $G_{X \rightarrow Y}$는 $x$를 $Y$로 mapping하고 $G_{Y \rightarrow X}$는 $y$를 $X$로 mapping합니다. $D_X, D_Y$라는 2가지 discriminator를 사용하며, 각각 X, Y 분포에서 생성된 것인지 예측합니다. 이를 위해 adversarial loss, cycle-consistency loss, identity loss를 사용합니다. adversarial loss는 다음과 같습니다.
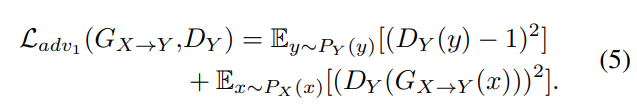
single cycle-consistency loss는 다음과 같이 정의됩니다.
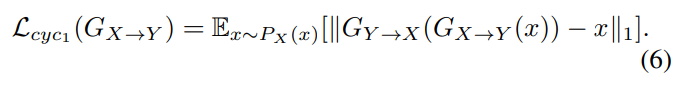
identity loss는 linguistic content를 보존하며 다음과 같이 정의됩니다.
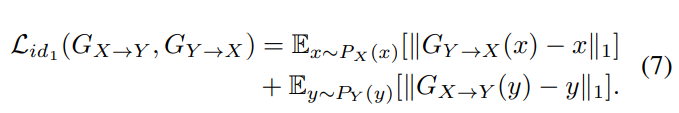
- $F_0$ Prediction
whisper-to-normal speech의 cepstral feature를 mapping 한 후, $F_0$ prediction task에 focus 합니다. 이전 method들은 converted normal speech의 cepstral feature로부터 $F_0$를 predict 하였으며, 이때 사용하는 CycleGAN은 따로 학습되었습니다. 하지만 이 논문에서는 converted normal speech의 cepstral feature로부터 $F_0$를 동시에 예측하며 joint traininig 합니다.
converted normal speech $G_{X \rightarrow Y}(X)$로부터 $F_0$를 예측하기 위해 generator $G_{Y \rightarrow X}$를 사용하며, $G_{Z \rightarrow X}$를 사용해 predicted $F_0$를 normal speech가 아닌 whisper speech로 mapping 합니다. original whisper speech와 joint training method를 사용함으로써 non-linear noise를 제거할 수 있습니다. 그리고 discriminator $D_Z$를 사용해 original $F_0$와 같은 $F_0$를 생성하였습니다. 하지만 whisper speech의 effect를 더함으로써 4번째 generator를 사용하여 predicted $F_0$로부터 whisper speechc feature를 생성하였습니다. 그래서 이를 위해 adversarial loss, cycle-consistency loss를 도입하였습니다.
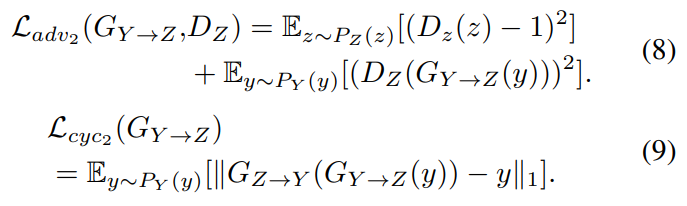
그리고 3번째 discriminator인 $D_X$의 loss를 결합하였습니다. discriminator는 $G_{Y \rightarrow X}, G_{Z \rightarrow X}$의 output이 X의 original distribution에서 생성된 것인지 예측합니다.
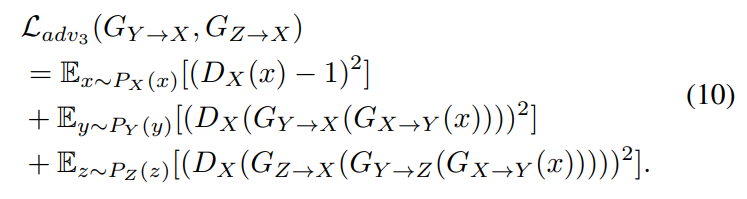
- Overall Objective of the Proposed method
요약하자면, 두 cycle을 동시에 학습합니다. 그리고 모든 generator, discriminator를 다음 loss로 최적화합니다.
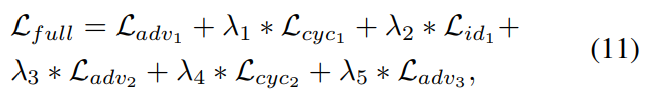
$\lambda_1, \lambda_2, \lambda_3, \lambda_4, \lambda_5$는 각 loss에 대한 hyperparameter를 의미합니다. 이 parameter들은 각 loss들의 상대적 중요성을 나타냅니다. 저자들은 $\lambda_1=10, \lambda_2=5, \lambda_3=10, \lambda_4=1, \lambda_5=1$로 설정하였습니다.
Experimental Results
Objective Evaluation
저자들은 Mel Cepstral Distortion (MCD)와 log($F_0$)-based Root Mean Square Error (RMSE)를 사용하여 WHSP2SPCH conversion system의 효율성을 측정하였습니다. MCD는 converted and refernece cepstral feature 사이 거리를 의미하며, 더 낮은 MCD를 보일수록 더 나은 system임을 의미합니다. 더 낮은 RMSE를 보일수록 더 나은 system임을 의미합니다.
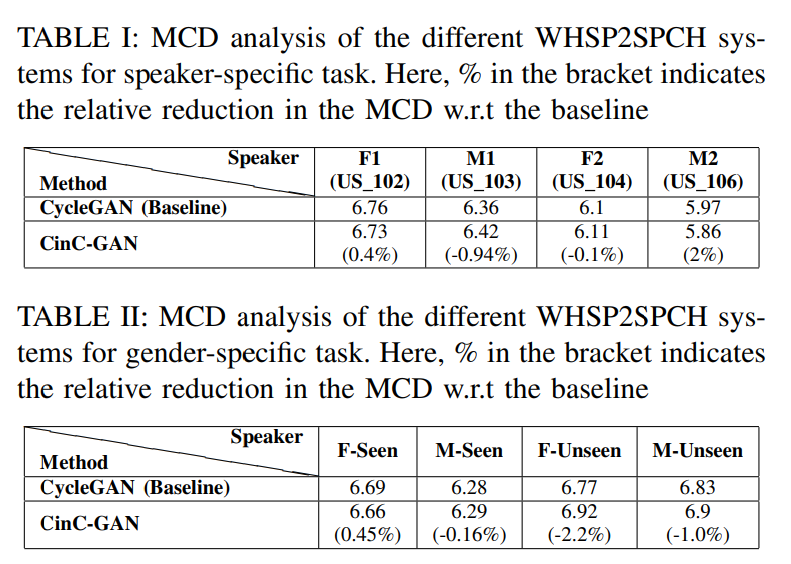
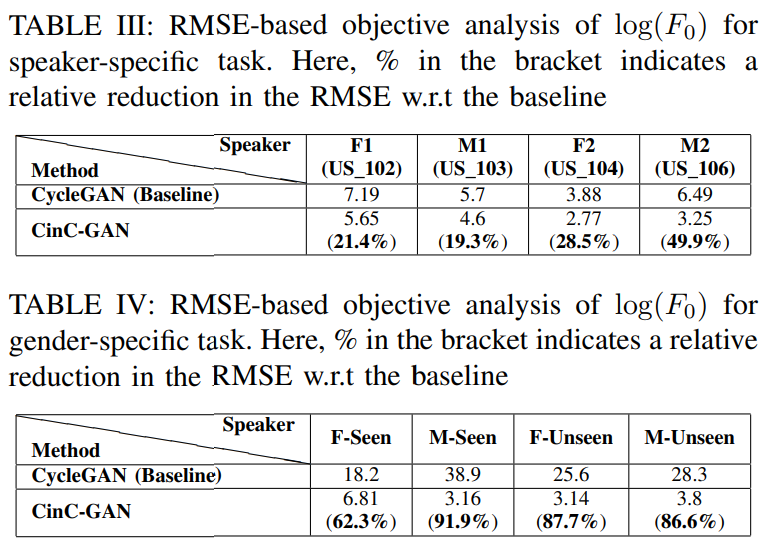
CinC-GAN의 효과는 WHSP2SPCH conversion system의 objective result에서 명확하게 확인할 수 있습니다. 단일 화자 data로 학습되고 평가를 진행한 speaker-specific task와 정해진 수의 화자로 학습한 후 seen뿐만 아니라 unseen speaker에 대해서도 평가를 진행하는 gender-specific task에 대한 성능을 비교하였습니다. 결과는 위와 같습니다. MCD 성능을 보면 CycleGAN과 비슷한 성능을 보입니다. 하지만 RMSE에서 더욱 뛰어난 모습을 보여줍니다. CycleGAN은 combined dataset에서 $F_0$를 예측하지 못하는 모습을 보여주지만, CinC-GAN은 unseen speaker and unseen utterance에서도 좋은 성능을 보여줍니다.
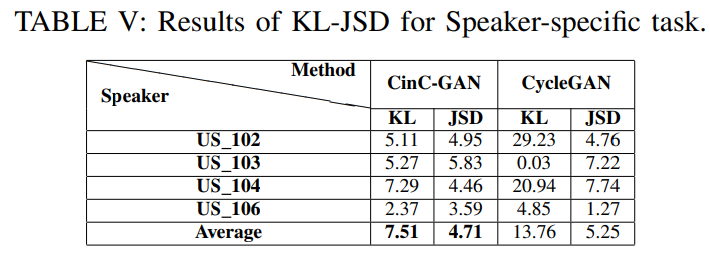
spekaer specific task에서의 original $F_0$와 predicted $F_0$ 사이 Kullback-Leibler Divergence (KLD) & Jensen-Shannon Divergence (JSD) 결과는 위와 같습니다. CinC-GAN이 더 좋은 모습을 보여줍니다.
Summary and conclusion
이 논문에서 저자들은 CinC-GAN을 제안합니다. 이는 MCC mapping 정확도에 영향을 주지 않으면서 $F_0$ prediction의 효율성을 증가시켰습니다. baseline (i.e., CycleGAN)은 sequential training을 사용하여 $F_0$ prediction에 non-linear noise가 추가됩니다. 하지만 CinC-GAN은 noise를 감소시키기 위해 joint training method를 사용합니다. objective와 subjective result는 CinC-GAN의 우수성을 보여줍니다. 그리고 CycleGAN은 gender-specific task에서 WHSP2SPCH conversion을 수행할 수 없지만, CinC-GAN은 unseen speaker에 대해서도 동작할 수 있습니다.



