https://arxiv.org/abs/2210.15272
A Fast and Accurate Pitch Estimation Algorithm Based on the Pseudo Wigner-Ville Distribution
Estimation of fundamental frequency (F0) in voiced segments of speech signals, also known as pitch tracking, plays a crucial role in pitch synchronous speech analysis, speech synthesis, and speech manipulation. In this paper, we capitalize on the high time
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
pitch tracking이라 알려진 speech signal에 존재하는 voiced segment의 fundamental frequency (F0)를 추정하는 것은 pitch synchronous speech analysis, speech synthesis, speech manipulation에서 중요한 역할을 합니다. 이 논문에서, 저자들은
pseudo Wigner-Ville distribution (PWVD)의 high time and high frequency resolution을 활용하여 새로운 PWVD-based pitch estimation method를 제안합니다. 저자들은 PWVD를 더 빠르게 연산하기 위한 효율적인 algorithm을 고안했으며 cross-term interference를 피하기 위해 cepstrum-based pre-filtering을 사용하였습니다. 저자들의 방식은 약 4Hz의 SOTA MAE 성능을 기록했으며, 저자들의 method는 voiced/unvoiced classification을 효과적으로 처리할 수 있으며 급격히 변하는 frequency에 대해서도 효과적임을 보여줍니다.
Introduction
fundamental frequency (F0)는 vocal fold 진동 주기의 역수로 정의되며, pitch tracking task를 통해 추정됩니다. 신뢰할 수 있는 pitch tracking은 speech synthesis, speech prosody analysis, speech manipulation, melody extraction, glottal source processing, intonation teaching 등 다양한 응용분야에서 사용되고 있습니다.
전통적인 pitch estimation은 일반적으로 3가지 category로 나눌 수 있습니다. 먼저, cepstrum-based method가 있습니다. 이는 cepstrum의 large peak로 frequency domain의 pitch period를 나타내는 방식입니다. 두번째, correlation-based method입니다. 이는 3가지의 sub-category로 나눌 수 있습니다. spectrum flattener의 output의 auto-correlation을 활용하는 auto-correlation-based method, normalized-cross-correlation-based method, auto-correlation function 외에 cumulative mean normalized difference function을 사용하는 YIN-based method로 나눌 수 있습니다. 마지막 세 번째 traditional method는 time-frequency representation을 이용하는 method입니다.
최근 몇 년동안, data-driven algorithm을 기반 pitch estimation 연구들이 등장하고 있습니다. 이전 machine learning method는 annotated data가 부족하기 때문에 traditional approach보다 좋은 성능을 보이지 못했습니다. CREPE는 합성 dataset으로 F0 tracking을 학습함으로써 제약을 피하고 SOTA를 달성했습니다. 이후 self-supervised learning을 사용하여 CREPE와 유사한 pitch estimation 성능을 달성한 SPICE가 등장하였습니다.
지금까지 time-frequency representation 기반 traditional signal processing method들은 주목을 받지 못했습니다. 주요한 이유 중 하나는 Heisenberg uncertainty principle 때문에 time and frequency resolution에 대한 제약이 존재한다는 것입니다. 이는 artifact 없이는 time and frequency resolution을 동시에 증가시키는 것은 불가능하다는 것을 의미합니다. traditional short-time Fourier transform (STFT)와 wavelet transform에서는 time resolution이 나빠지는 대신 frequency resolution이 좋아지며, 반대의 경우에도 이러한 문제가 발생했습니다.
Wigner-Ville distribution (WVD)는 time and frequency domain 둘 다에서 high resolution을 가지며, 가장 powerful 하고 기본적인 time-frequency representation 중 하나입니다. 하지만 WVD는 연산량이 많고 다른 구성 요소 간의 간섭 (cross term) 때문에 false information이 발생할 수 있으며, non-locality가 크기 때문에 널리 사용되고 있지 않았습니다.
이 논문에서 저자들은 WVD의 단점을 극복하고 pseudo WVD (PWVD) 기반의 high-performance pitch tracker를 제안합니다. 저자들은 Hibert transform, downsampling, segmentation를 활용하고 FFT 기반 WVD를 구현해 빠르게 PWVD를 계산합니다. 그리고 저자들은 F0와 harmonic에 존재하는 cross term을 제거하기 위해 cepstrum based pre-filtering을 사용합니다. PWVD는 저자들이 제안한 pitch tracker가 frequency 변화에 더 sensitive 하게 반응하도록 만들어줍니다. 저자들의 algorithm이 널리 사용되는 REAPER와 STRAIGHT method보다 더 뛰어난 성능임을 보였으며 pYIN, CREPE와 같은 SOTA method보다 더 뛰어난 Mean Absolute Error (MAE), F0 Frame Error (FFE) 결과를 보인다는 것을 보였습니다.
Method
Basics of WVD
signal $x(t)$의 Wigner-Ville distribution은 다음과 같은 식으로 정의됩니다.

instantaneous auto-correlation function $R(t, \tau)$는 다음 식으로 정의됩니다.

$W_x(t,w)$는 $\tau$ 축에 따라 $R(t, \tau)$의 Fourier Transform으로 볼 수 있으며 다음식으로 정의됩니다.

WVD의 discrete version은 다음과 같이 표현될 수 있습니다.

이 정의는 half-integer indice를 포함합니다. $s(t)$가 여러 component로 정의되면 다음과 같이 정리됩니다.

$s(t)$에 대한 WVD (i.e., $W_s(t,w)$)는 cross terms $I(s_1, s_2)$를 포함하여, 이는 다음과 같이 정의됩니다.
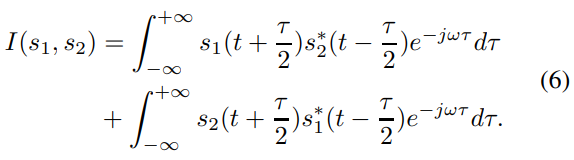
cross term가 존재한다는 것은 original signal이 cross term의 time-frequency 근방에 energy를 분포하고 있다는 것을 의미하는 게 아닙니다. 각각 component들이 고유한 time-frequency에서 energy를 가지고 있을 때 cross term은 각 component 사이 가상적인 상호작용으로 인해 생성되는 energy로, 이는 artifact로 여겨집니다.

위 그림은 두 chirp signal의 합을 이용한 WVD and STFT 결과를 보여줍니다. signal은 다음과 같이 정의됩니다.
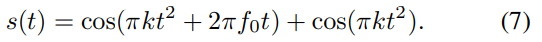
STFT는 낮은 해상도로 인해 spectrum이 흐려지고 artifact가 나타납니다. WVD의 경우 high resolution으로 두 parallel thin straight line이 완벽하게 capture됩니다. 하지만 두 line 사이 interference 때문에 진동하는 pattern이 발생합니다. 이는 cross term 때문입니다.
Stage 1: Downsampling
사람들의 발화의 경우, 일반적으로 pitch가 약 60Hz에서 400Hz 사이입니다. 이러한 추정치를 기반으로, 저자들은 이 범위 외의 frequency component들은 filtering 하였습니다. 그다음 저자들은 sampling frequency를 $f_d = 800$Hz까지 downsample 하였으며 이를 $x_d$라 부릅니다. 이 downsampling 연산은 PWVD의 연산량을 눈에 띄게 줄여줍니다.
Stage 2: V/UV Classification
voiced sound는 quasi-periodic인 반면, unvoiced sound는 noise에 더 가까우며 훨씬 더 높은 frequency component를 포함합니다. 이러한 사실을 기반으로, 저자들은 voiced/unvoiced (V/UV) classification을 위한 energy thresholding을 사용합니다. $x_d$의 voiced area는 unvoiced area보다 훨씬 더 높은 energy를 가지기 때문에 이러한 energy thresholding을 사용합니다. 저자들은 $x_d$의 frame 별로 average energy를 측정하고 higher-energy frame들을 subframe으로 나누어 더 정확한 결과를 얻었습니다. 저자들은 frame size로 25ms를 선택했으며, threshold로 0.2E를 사용했습니다. 여기서 E는 $x_d$의 averaged energy입니다.
Stage 3: Segmentation
이 논문에서 각 voiced area를 약 150ms의 segment로 나누었으며, $f_d = 800$Hz인 경우 120개 point로 구성됩니다. 이와 같이 짧은 시간 구간으로 나누면 급격한 frequency 변화가 발생할 가능성을 줄일 수 있습니다. 이는 cross term의 발생을 줄이고, 이후의 pre-filtering stage의 signal을 prepare 하는데 도움을 줍니다.
Cepstrum-based Pre-filtering
pre-filtering의 목적은 fundamental frequency component만 남기고 harmonic structure를 filtering out하는 것이며, 이를 통해 PWVD의 cross term을 최대한 감소시키는 것입니다. 이를 위해, 각 voiced segment의 average F0 ($f_a$)를 사용합니다. $f_a$를 추출하기 위해 cepstrum과 spectrum을 combine 합니다. 먼저, pre-downsampling voiced segment ($f_s = 16$kHz)를 stopband edge frequency가 1kHz인 low-pass filter (LPC)에 통과시킵니다. 다음 $f_{raw}$를 계산하기 위해 filtered segment에 cepstrum maximum dectection을 적용합니다.

$\tau$는 80Hz에서 320Hz 사이 cepstrum 값이 maximum인 부분을 나타내는 quefrency index입니다. 세번째, $f_{raw}$의 배수와 약수를 후보로 생성하며, 여전히 80Hz에서 320Hz 사이를 유지합니다. 마지막으로 주변 frequency 대역에서 가장 뚜렷한 spectrum peak가 존재하는 가장 작은 candiate를 선택합니다.
average F0 value를 추출한 다음, signal의 edge 부분이 희미해지는 WVD의 경향성을 완화하기 위해 각 voiced segment에 인접한 point들을 concatenate 합니다. 각 voiced segment에 pre-filtering을 적용하여 0.7$f_a$에서 1.4$f_a$ 사이 frequency component만 남깁니다.
Stage 5: PWVD
pre-filtered voiced segment만 PWVD stage로 넘어옵니다. Hilbert trasnform이 spectrum aliasing을 위해 수정을 적용한 것과 같이, 저자들도 다음과 같이 수정합니다.
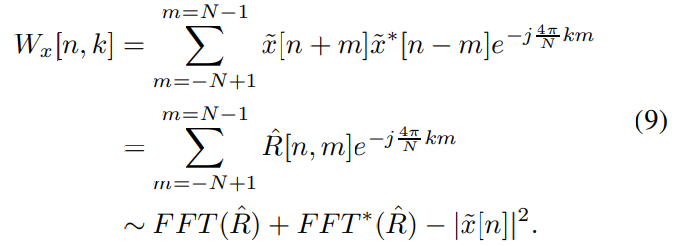
위 식에서 $\tilde{x}$는 x의 analytic signal이고, *는 complex conjugate입니다. 지수부에 있는 $4\pi$는 단순히 frequency stretching을 나타내며, 실제 계산에서는 모든 주파수를 2로 나눕니다. interpolation을 피하고 WVD을 FFT 연산으로 변환합니다.
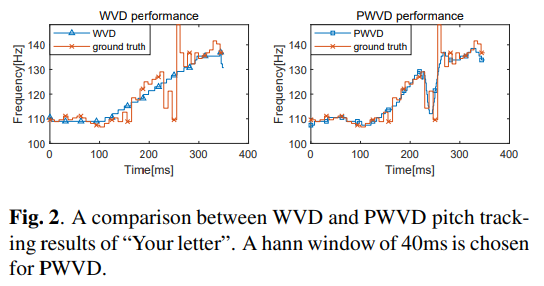
WVD를 계산한 다음, 각 time index n에서 첫 번째 뚜렷한 peak를 찾아 $F_0$를 추정합니다. 위 결과가 WVD를 사용한 pitch tracking 결과를 보여주며, ground-truth를 정확하게 추적하지는 못합니다. 이는 WVD연산의 non-local 특성 때문입니다. 즉 이전, 현재, 미래 point들에 동일한 weight를 할당해 연산하기 때문입니다. 현재를 강조하기 위해 window function $w[m]$을 $\hat{R}[n,m]$에 적용한다면, 이러한 non-local effect는 완화할 수 있습니다. 이 연산을 Pseudo-WVD라 부르며 식으로 나타내면 다음과 같습니다.
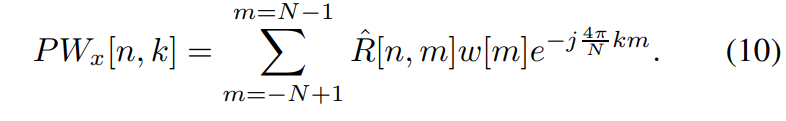
PWVD가 frequency 변화에 더 정확하게 반응하는 것을 볼 수 있습니다.
Results
Evaluation
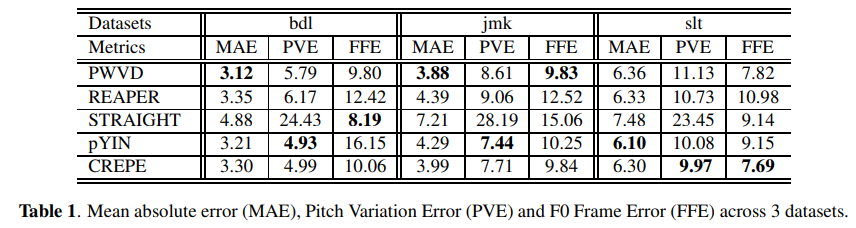
저자들은 REAPER, STRAIGHT, pYIN, CREPE들과 성능을 비교했습니다. 결과는 위와 같습니다. CREPE는 V/UV classification을 지원하지 않기 때문에, CREPE는 저자들의 V/UV method를 적용했습니다. MAE의 경우, 저자들의 PWVD-based pitch tracker가 bdl, jmk dataset에서 가장 좋은 모습을 보였습니다. FFE 수치도 좋은 모습을 보여줍니다.
Discussion and Conclusion
저자든은 pseudo Wigner-Ville distribution 기반 pitch tracker인 (PWVD)를 제안합니다. 이는 high time-frequency resolution을 이용합니다. 그리고 이전 방식들보다 더 빠르게 WVD를 계산하는 algorithm을 제안하며 cepstrum-based pre-filtering을 이용해 대부분의 cross term을 제거하였습니다. 저자들은 PWVD를 사용해 WVD가 급작스러운 frequency 변화에도 잘 반응하도록 만들었습니다.



