https://arxiv.org/abs/2104.00355
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This al
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 speech resynthesis task를 수행하는 self-supervised discrete representation을 제안합니다. disentangled representation을 생성하기 위해, 저자들은 speech content, prosodic information, speaker identity에 대해 각각 low-bitrate representation을 추출했습니다. 이를 통해 controllable manner로 speech를 합성할 수 있도록 만들어줍니다. 저자들은 다양한 SOTA self-supervised representation learning method에 대해 분석하고, reconstruction quality와 disentanglement 특성을 고려하여 각 method들의 장점을 확인하였습니다. 구체적으로 F0 reconstruction, speaker identification preformance (both resynthesis and voice conversion), recording's intelligibility, overall quality using subjective human evaluation에 대한 평가를 진행했습니다. 마지막으로 이러한 representation들을 ultra-lighweight speech codec으로 사용되는 방법을 보여주며 입증합니다. 1초마다 365 bit인 rate로 baseline method보다 더 나은 speech quality를 달성합니다.
Introduction
self-supervised learning method의 성공에 따라, continuous and discrete 모두에서의 unsupervised speech representation learning이 큰 도약을 이루었습니다. 하지만 대부분의 speech SSL들은 ASR 관점에서 평가하는 데 초점을 맞추고 있습니다. 그래서 이러한 representation들이 speech synthesis에 적합한지에 대한 연구는 명확하지 않습니다. 특히 spekaer identity와 F0 정보가 얼마나 잘 포함되어 있는지에 대한 연구가 부족합니다.
전통적으로 음성 합성과 TTS model은 textual feature가 input으로 들어오면 autoregressive 하게 Mel-spectrogram을 생성합니다. 그다음 vocoder가 Mel-spectrogram으로부터 phase를 reoncstruct 합니다. 이 연구에서 저자들은 learned speech unit을 vocoder의 input으로 사용하며, spectrogram estimation을 사용하지 않습니다. 그리고 저자들은 learned unit에 quantized F0 representation과 global speaker embedding을 추가했습니다.

위 그림은 전체적인 method를 보여줍니다. 이는 speech content, speaker identity, F0에 대한 learned unit의 평가가 가능하며, audio 합성을 더 잘 control 할 수 있습니다. 마지막으로 저자들은 기존 연구 결과들을 바탕으로 학습된 unit이 ultra-lightweight speech codec으로 어떻게 사용될 수 있는지 입증합니다. 저자들이 제안한 method를 통해 초당 365bit라는 encoding rate를 달성하면서도 baseline method보다 훨씬 뛰어난 모습을 보입니다. 저자들의 contribution은 다음과 같습니다.
- 저자들은 self-supervised manner로 discrete speech unit이 high-qualtiy synthesis를 수행할 수 있음을 입증하였습니다.
- signal reconstruction, voice conversion, F0 manipulation과 같은 추가적인 실험을 진행하여 SSL speech unit이 음성 합성에서 사용될 수 있음을 보였습니다.
- 얻어진 speech unit으로부터 ultra-lightweight speech codec을 얻는 방법을 제안합니다.
Method
제안하는 architecture는 3가지 pre-trained and fixed encoder로 구성됩니다. content encoder, F0 encoder, speaker identity encoder이며, decoder network도 존재합니다. 첫 2가지 encoder는 raw audio에서 discrete representation을 추출하며, 마지막 encoder는 single global representation을 추출합니다.
Encoders
audio sample의 domain을 $x \in R$이라 하겠습니다. raw signal의 representation은 $x = (x_1, ... , x_T), x_t \in X$형태의 sample sequence로 나타낼 수 있습니다.
- Content Encoder
content encoder network $E_c$로의 input은 speech utterance $x$이고, output은 $E_c(x) = (v_1, ... , v_{T'})$이며, low-frequency로 sample 된 spectral representation sequence입니다. 저자들은 $E_c$에 대해 3가지 SOTA unsupervised representation learning function을 가지고 평가를 진행했습니다. 구체적으로 (1) CPC는 이전 값들을 기반으로 encoder는 미래 state들을 예측하며, contrastive loss로 최적화됩니다. (2) HuBERT는 BERT와 유사하게 masked prediction task로 학습되며, masked continuous audio signal을 input으로 사용합니다. (3) VQ-VAE는 Variational Auto Encoder와 유사하게 동작하며 encoder의 output이 continuous가 아닌 discrete 합니다.
CPC와 HuBERT로 학습된 representation은 continuous하기 때문에, k-means algorithm을 이용해 model의 output을 discrete unit으로 변환하고 이는 $z_c = (z_1, ... , z_L)$ 형태로 나타납니다. $z_c$에 있는 각 $z_i$는 positivie integer이며 $z_i \in {0, 1, ... , K}$에서 $K$는 discrete unit 수를 나타냅니다. VQ-VAE의 경우 이미 양자화된 representation을 사용하기 때문에, 저자들의 방식과는 다릅니다.
- F0 Encoder
low frequency discrete F0 representation $z_{F0} = (z_1, ... , z_{L'})$을 생성하기 위해, separate encoder $E_{F_0}$를 이용해 input signal로부터 F0를 추출합니다. $z_{F0}$의 각 element들은 integer $z_s \in {0, ... , K'}$이고, $K'$는 encoder dictionary size입니다. YAAPT algorithm을 사용해 input signal $x$로부터 F0를 추출하여 $p = (p_1, ... , p_{T'})$을 생성합니다. $E_{F_0}$는 VQ-VAE framework를 이용해 학습됩니다. VQ-VAE는 convolutional encoder $E_{F_0}$를 사용하며, learned codebook $C = (e_1, ... , e_{K'})$를 이용합니다. 이때 C의 각 vector들은 128차원 vector이고, decoder $D_{F_0} $도 사용합니다. encoder는 raw audio에서 latent vector sequence $E_{F0}(p) = (h_1, ... ,h_{L'})$을 추출합니다. 여기서 $h_i$는 128차원입니다. bottleneck은 각 latent vector를 codebook $C$에 있는 가장 가까운 vector로 mapping 합니다. embedded latent vector는 decoder $D_{F_0}$에 feed 하여 original F0 signal을 reconstruct 합니다. 이를 $\hat{p}$라 합니다. 저자들은 Exponentional Moving Average updates를 사용해 codebook을 학습하고 unused embedding을 위해 random restart를 사용합니다. $z_{F_0}$로 vector를 사용하는 대신 mapped latent vector의 index를 사용합니다.
- Speaker Encoder
마지막으로 speaker encoder $E_{spk}$를 사용해 speaker embedding을 추출합니다. pre-trained speaker verification model을 사용합니다. $E_{spk}$은 input speech utterance $x$를 받아 Mel-spectrogram을 추출하고 d-vector speaker representation $z_{spk} \in R^{256}$을 output합니다. 저자들은 look-up table을 사용하여 speaker embedding을 학습하는 것에 대한 실험도 진행했으며, 이는 성능이 약간 더 뛰어나지만 unseen speaker에 대해선 동작하지 않는다는 단점이 존재합니다.
Decoder
neural vocoder를 이용해 discrete representation으로부터 speech signal을 decode합니다. 이 논문에서 decoder로 modified HiFi-GAN neural vocoder를 사용하였습니다.
HiFi-GAN architecture는 generator G와 set of discriminator D로 구성됩니다. generator는 look-up table (LUT)을 사용해 discrete representation을 embedding 하고, transposed convolution block, residual block with dilated layer로 구성됩니다. transposed convolution은 encoded representation을 upsample 하며 input sample rate와 동일하도록 만들어줍니다. dilated layer가 receptive field를 키워줍니다.
generator는 input으로 encoded representation $(z_c, z_{F_0}, z_{spk})$를 받습니다. discrete content sequence $z_c$와 discrete pitch sequence $z_{F_0}$는 $LUT_c, LUT_{F_0}$를 통해 continuous representation으로 변환됩니다. sequence들은 up-sample된 다음 concatenate 됩니다. speaker embedding $z_{spk}$는 up-sampled sequence의 각 frame에 concatenate 됩니다.
discriminator는 2가지 network인 Multi-Period Discriminator (MPD)와 Mutli-Scale Discriminator (MSD)로 구성됩니다. MPD는 여러 sub-discriminator로 구성되며, input signal에서 sample을 추출해 동작합니다. period sub-discriminator들은 sample의 간격들이 다릅니다. 저자들은 MPD로 5개 period의 discriminator로 구현했으며, period hop은 [2, 3, 5, 7, 11]입니다. Multi-scale discriminator (MSD)는 여러 sub-discrimiantor를 사용하며 input signal의 다양한 scale에서 동작합니다. 저자들은 3가지 scale을 사용했으며, original input signal scale, 2배 downsample scale, 4배 downsample scale에서 동작합니다. 모든 각 sub-discriminator $D_j$는 다음 식을 minimize 합니다.

위 식에서 $\hat{x} = G(LUT_c(Z_c), LUT_{F_0}(z_{F_0}), z_{spk})$이며, encoded representaion으로 resynthesize한 signal입니다.
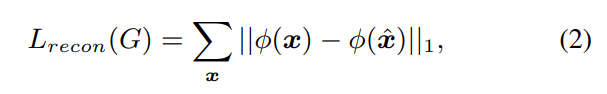
추가적으로 2가지 loss function을 사용합니다. 첫 번째는 위 식입니다. input signal의 mel-spectrogram과 generated signal 사이 reconstruction term입니다. 여기서 $\Phi$는 Mel-spectrogram을 계산하는 spectral operator입니다.
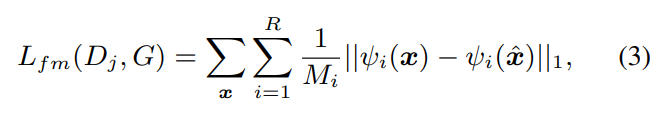
두 번째 term은 위 식인 feature-matching loss입니다. 이는 real signal의 discriminator activation과 resynthesized signal의 dsicriminator activation 사이 distance를 나타냅니다. $\psi_i$는 discriminator의 i번째 layer의 activation을 추출하는 operator입니다. $M_i$는 i번째 layer의 feature 수를 나타내고, R은 $D_j$에 존재하는 모든 layer 수를 나타냅니다.
최종 loss는 다음과 같은 식으로 나타납니다.
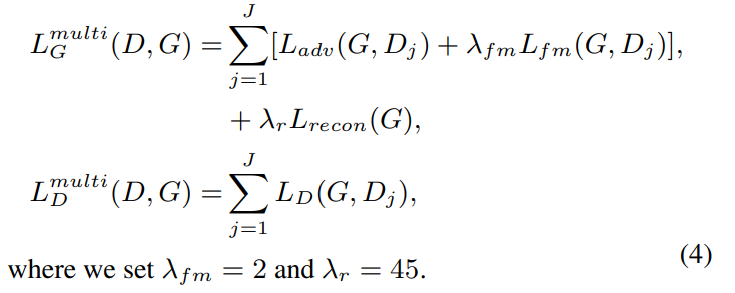
Results
저자들은 3가지 setting에서 실험을 진행하였습니다. speech reconstruction, speaker converison, F0 manipulation, bitrate analysis를 진행하였습니다. CPC의 경우, 저자들은 LibriLight dataset의 6k hour sub-sample을 이용해 학습하였습니다. 저자들은 중간 layer을 이용해 downsampled 256차원 embedding을 추출했습니다. HuBERT Base model을 사용했으며, 960 시간 LibriSpeech corpus로 학습됩니다. model은 raw audio를 320배 downsampling 하며, 768차원 vector sequence를 생성합니다. 저자들은 6번째 layer에서 feature를 추출하였습니다.
CPC와 HuBERT에 LibriSpeech clean-100h로 학습된 k-means algorithm을 적용하였습니다. 학습된 representation을 K=100 centroid로 quantize 했습니다. CPC의 bitrate는 700bps, HuBERT는 350bps가 됩니다.
VQ-VAE content encoder를 LibriLight dataset의 6k hours subset으로 학습시켰습니다. 그다음 raw signal에서 discrete unit을 추출하기 위해 encoder를 사용하였습니다. 그리고 codebook vector의 사용률이 predetermined threshold보다 낮은 경우, random restart를 사용하였습니다. 간단한 convolution layer 대신 HiFi-GAN을 decoder로 사용하여전반적인 audio quality를 향상시켰습니다. 이 model은 raw audio를 discrete token sequence로 encode 합니다.
speaker verification network는 VoxCeleb2 dataset으로 학습되고 VoxCeleb1 dataset의 test data에 대해서 speaker verification의 7.4 Equal Error Rate (EER)를 기록하였습니다.
모든 model에서 단일 F0 representation을 사용하며, VCTK dataset으로 학습되었습니다. window size 20ms, 5ms hop size를 사용하여 raw audio에서 F0를 추출하였습니다. 결과적으로 F0 sequence는 200Hz로 sample 되었습니다.
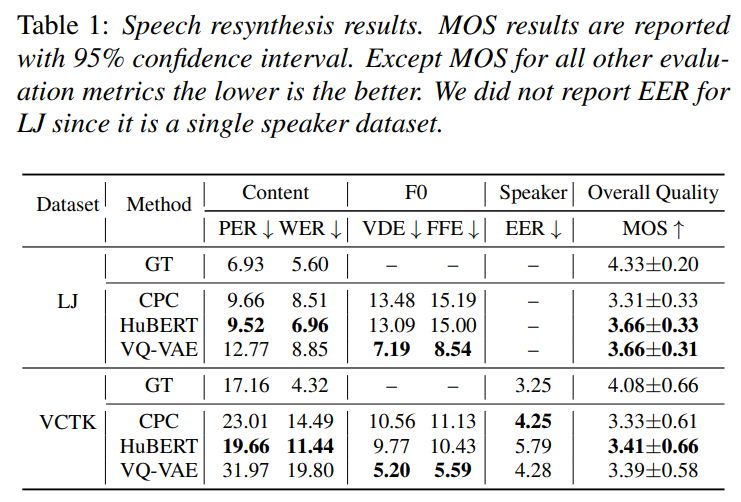
위 표는 reconstruction performance에 대한 실험 결과를 보여줍니다. HuBERT를 이용했을 때 가장 좋은 성능을 달성했으며, CPC와 HuBERT가 VQ-VAE보다 더 좋은 결과를 보여줍니다. 하지만 F0 reconstruction의 경우, VQ-VAE가 더 나은 성능을 보입니다. VQ-VAE는 input signal을 fully reconstruct 하도록 학습되기 때문입니다.
다양한 실험 결과는 논문을 참고하시면 될 것 같습니다.
Conclusion
저자들은 self-supervised discrete representation을 통한 speech resynthesis를 수행하였습니다. 그리고 signal reconstruction, voice conversion, F0 manipulation에 있어 효과적으로 disentangle 한다는 것을 입증하였습니다.



