https://ieeexplore.ieee.org/document/10445890
Learning Arousal-Valence Representation from Categorical Emotion Labels of Speech
Dimensional representations of speech emotions such as the arousal-valence (AV) representation provide a continuous and fine-grained description and control than their categorical counterparts. They have wide applications in tasks such as dynamic emotion u
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
arousal valence (AV) representation과 같이 speech emotion의 dimensional representation은 continuous and fine-grained secription을 제공하고 categorical representation보다 controllable 할 수 있습니다. dimensional representation은 dynamic emotion understanding과 expressive text-to-speech synthesis와 같은 task에서 널리 사용됩니다. 기존의 method들은 speech에서 dimensional emotion representation을 예측하는 작업을 supervised regression task로 정의합니다. 이 방식들은 categorical label을 얻는 것보다 dimensional annotation을 얻는 것이 더욱 어렵기 때문에 data가 부족하다는 문제에 직면합니다. 이 논문에서 저자들은 speech의 categorical emotion label로부터 AV representation을 학습하는 것을 제안합니다. 저자들은 먼저 pre-training and emotion classification fine-tuning self-supervised model을 통해 풍부하고 감정과 관련된 high-dimensional speech feature representation을 학습합니다. 그다음, 심리학적 연구 결과를 바탕으로 achored dimensionality reduction을 통해 이 representation을 2D AV space에 mapping 합니다. 실험 결과들을 통해 저자들의 method가 학습 과정에서 ground-truth AV annotation을 사용하지 않고도 Concordance Correlation Coefficient (CCC) performance에 있어 SOTA supervised regression method와 유사한 성능을 달성했음을 보였습니다.
Introduction
categorical representation은 이해하기 쉽고 annotation 작업이 간단하지만, 동일한 category 내에서의 뉘앙스 변화를 무시하며 서로 다른 범주를 부드럽게 연결하지 못합니다. dimensional representation이 감정을 다차원 space로 mapping 하여 연속적이고 세밀한 description을 제공하여 단점을 완화시킵니다. 초기 dimensional emotion model은 valence와 arousal의 개별 차원을 예측하기 위한 individual model을 개발하였습니다. 이러한 방식들은 서로 다른 감정 차원들의 inter-correlation을 무시하였습니다. 최근 연구들은 차원 간 interaction을 고려하여 문제를 multi-dimensional regression 문제로 정의하였습니다. 예측된 value와 ground-truth 사이 distance를 minimize 하고 correlation은 maximize 하는 식으로 학습이 진행되었습니다. 하지만 이는 categorical label을 얻는 것보다 더 많은 노동력과 비용을 요구합니다. 그리고 annotator의 편향에 민감한 결과를 보여줍니다. 현재까지 이러한 dimensional label을 포함한 emotional speech corpus는 매우 제한적입니다.
이 논문에서 저자들은 speech emotion의 AV dimensional representation을 학습하는 새로운 방법을 제안합니다. 대부분의 기존 method들이 supervised regression task로 정의했던 것과 달리, 저자들은 self-supervised pretraining and categorical emotion classification finetuning으로 representation을 학습합니다. 그리고 anchored dimensionality reduction을 적용하여 representation을 AV space로 mapping 합니다. 첫 step에서의 rich and emotion-relevent representation은 서로 다른 감정 category를 구분할 수 있을 뿐만 아니라 같은 감정 category 내에서의 미묘한 변화도 나타낼 수 있습니다. anchored dimensionality reduction은 latent representation을 AV space로 mapping 하며 arousal-valence space에서 서로 다른 감정 category들이 올바른 위치에 존재하도록 만들어 줍니다. 이 방식은 학습 과정에서 categorical emotion label만 필요로 하며 dimensional label을 필요로 하지 않습니다. 저자들은 IEMOCAP이라는 SOTA supervised regression method과 유사한 Concordance Correlation Coefficient (CCC) performance를 달성했음을 보였습니다. EmoDB와 MEAD dataset에서 실험을 진행하여 다양한 speech corpus에서의 일반화 성능을 입증하였습니다.
Method
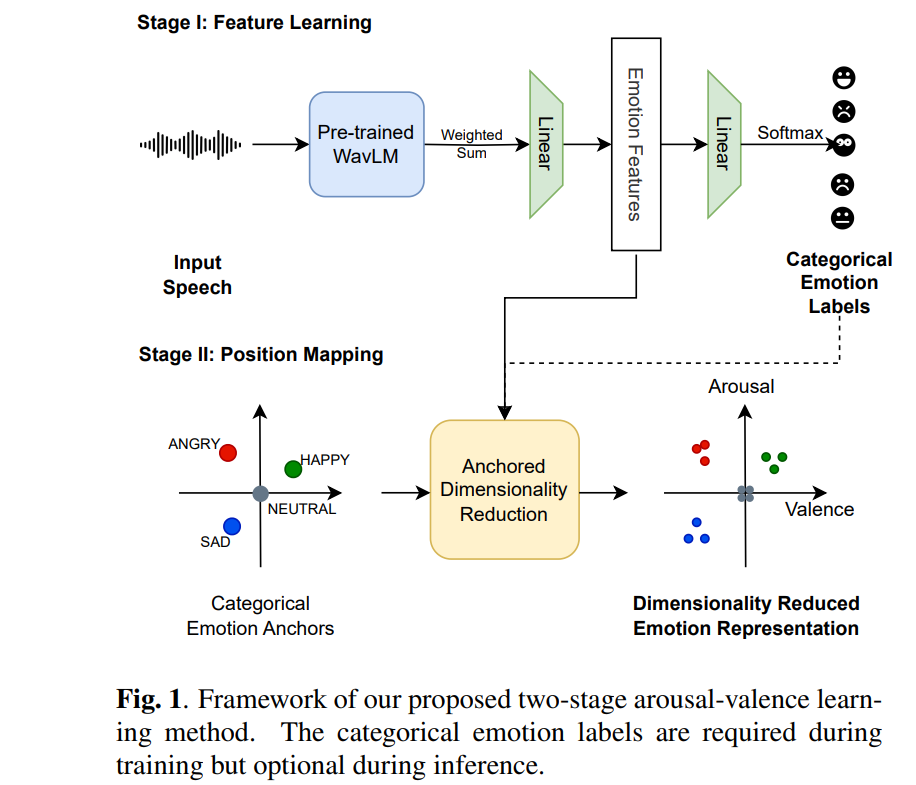
저자들의 arousal-valence (AV) representation learning은 self-supervised front-end와 speech utterance의 categorical emotion label을 사용하여 학습을 진행합니다. 저자들의 method는 2-stage로 구성되며 위 그림과 같습니다. 첫 stage에서 pre-trained slef-supervised speech model (e.g., WavLM)을 기반으로 emotion classification head를 학습하여 high-dimensional latent feature representation을 도출합니다. 저자들은 pretrain된 SSL feature가 speech emotion classification으로 refine 되었으며, 이 feature가 서로 다른 emotion category 및 같은 emotion category 내의 미세한 차이를 구별할 수 있을 정도로 풍부하고 감정 관련된 정보를 포함하고 있다고 가정합니다. 두 번째 stage에서 anchored dimensionality reduction technique을 사용하여 high-dimensional feature를 2D av space로 project 합니다. 이 전체 과정에서 학습 data로 categorical emotion label만 필요로 하며, inference 할 때는 새로운 speech utterance로부터 AV value를 예측할 수 있습니다.
Utterance-level emotion feature extraction
self-supervised speech representation은 주변 context를 기반으로 speech token을 예측하는 pretext task로 학습됩니다. 이러한 representation은 downstream emotion classification task에서 좋은 성과를 달성하며, semantic, speaker data, paralinguistic cue를 포함한 speech utterance 내의 구조적 detail을 유지합니다. 저자들은 이러한 정보들이 arousal-valence supervision이 없는 상황에서 emotion representation learning의 중요한 역할을 한다고 생각하였습니다. input speech에서 감정과 관련된 feature를 추출하기 위해, 저자들은 emotion classification challenge를 사용합니다.
WavLM large를 self-supervised front-end로 사용하였습니다. 이는 다른 self-supervised front-end보다 다양한 benchmark speech downstream task에서 뛰어난 성능을 달성하고, 특히 다양한 emotion speech dataset에서 emotion classification 성능이 좋았기 때문에 사용하였습니다. WavLM을 기반으로, weighted projection head를 추가하여 categorical emotional classification을 수행하였습니다. 24개 transformer layer에서 weighted sum을 구한 다음 temporal average pooling을 적용하여 utterance level embedding을 추출합니다. 결과적으로 averaged-pool weighted sum output을 linear projection layer에 pass하여 feature dim을 100으로 줄였습니다. 그다음 feature vector를 또 다른 linear layer에 forward 하여 training set의 emotion 수와 동일하게 차원을 줄이고 softmax function을 적용하였습니다. 저자들은 cross-entropy loss를 사용하여 network를 optimize 하였습니다. 마지막 2번째 layer로부터 구한 model의 100차원 output을 high-dimensional emotion feature로 사용합니다. 이 feature는 self-supervised learned feature의 linear mapping이며, categorical emotion classification에 맞춰 weight를 학습합니다. 저자들은 이 feature가 AV representation learning에 맞춰 speech utterance에 존재하는 풍부한 감정 관련 data를 포함하고 있다고 믿습니다.
Categorical emotion label-guided arousal-valence representation learning
speech utterance의 arousal and valence value를 예측하기 위해, 저자들은 high-dimensional feature space에서 arousal-valence (AV) space로의 representation learning을 guide하기 위해 categorical label을 이용합니다. categorical and dimensional representation 사이 inherent connection에서 영감을 받아, 저자들은 각 categorical label의 특정 AV value를 anchor로 지정합니다. 이 anchor는 AV representation 학습을 위한 data-driven approach의 기초 guide를 제안합니다. 저자들이 사용한 anchor는 다음과 같습니다.
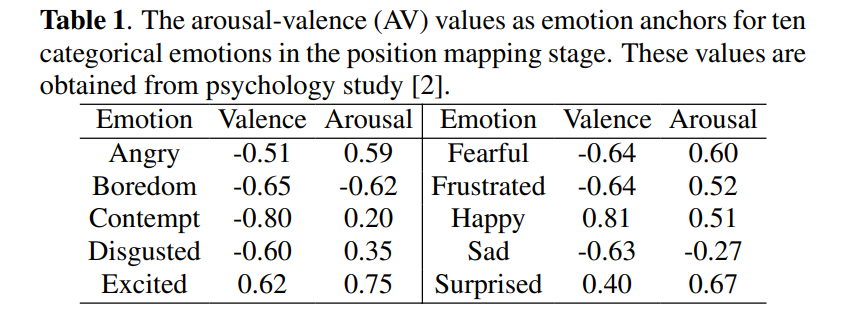
speech utterance에 대한 마지막 예측된 AV value는 이 anchor들 근처에 있을 것으로 예상됩니다. 저자들은 중립 emotion은 arousal-valence space의 원점에 있도록 설정하였습니다. 저자들은 이 anchor들을 시작점으로 embedded point의 위치를 최적화하며 emotion feature의 구조적 정보를 유지합니다.
저자들은 먼저 arousal-valence space에서의 각 speech utterance들의 embedded points position들이 각각이 속한 categorical label anchor와 가깝게 설정하였습니다. 즉, 각 utterance의 초기 arousal-valence value를 해당 anchor 값에 small Gaussian perturbation $\sigma = 0.01$을 더해 할당하였습니다. 그런 다음 stage 1에서 얻은 high-dimensional speech emotion feature를 기반으로 embedded point의 position을 fine-tuning 하였습니다. 이 speech emotion feature의 구조를 encapsulate 하기 위해, 저자들은 weigthed k-Nearest Neighbor (kNN) graph를 사용하였습니다. kNN graph는 추출된 emotion feature의 위상학적 representation으로 간주됩니다. 저자들은 categorical label을 kNN graph에 적용하여 embedding space에서 class separation이 이뤄지도록 만들었습니다. 제공된 label은 kNN graph와 교차하는 구분된 metric space로 정의됩니다. 계산적으로 이는 point 간 거리의 weight를 상수로 설정하는 것과 같습니다. UMAP에서 사용된 SGD method를 사용하여 high-dimensional feature와 low-dimensional embedding 사이 cross-entropy를 minimize 하며, 각 point의 위치들을 반복적으로 조정합니다. 이 과정에서 attractive and repulsive gradient가 사용됩니다.
inference 할 땐, 새로운 speech sample을 받아 arousal-valence value를 예측합니다. 이는 non-parametric dimensionality reduction algorithm을 기반으로 하기 때문에 재학습할 필요가 없습니다. 새로운 sample의 categorical label이 있든 없든 inference를 수행할 수 있습니다. Stage 2에서 categorical label이 사용 가능하다면, 새로운 sample의 embedding 값을 categorical label에 해당하는 reference emotion anchor 근처로 초기화합니다. 이후 extracted emotion feature를 사용하여 point를 최적화합니다. categorical label을 사용하지 못하는 경우, 학습 때 사용했던 emotion feature로 kNN search를 수행하며, 여기서 new sample의 feature를 query로 사용합니다. 각 새로운 sample에 대한 embedded value는 인접한 embedding value의 weighted average로 정의됩니다.
Experimental Setup
Database description
이 연구에서는 IEMOCAP, MEAD, EmoDB를 이용하여 저자들의 방식의 효율성과 일반화 성능을 평가하였습니다. 이 corpora들은 SER task에서 주로 사용됩니다. AV value를 predict하는 성능을 평가할 때 주로 IEMOCAP을 사용하였으며, MEAD, EmoDB를 사용해 저자들의 method의 cross-lingual and emotional context에 대한 성능을 평가하였습니다.
Evaluation metrics
predicted arousal-valence value와 human-annotated value 사이 agreement를 계산하기 위해 Concordance correlation coefficient (CCC)를 사용하였고, 식으로 나타내면 다음과 같습니다.
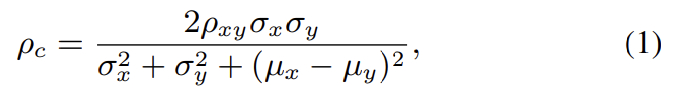
위 식에서 $\rho_{xy}$는 $x$와 $y$ 사이 Pearson correlation coefficient를 나타내며, $\sigma$는 표준편차, $\mu$는 평균을 나타냅니다. 추가적으로 MAE를 사용하여 predicted AV representation을 평가하였습니다.
Results
Comparison with human annotations
저자들읜 IEMOCAP dataset을 이용하여 predicted arousal-valence (AV) value와 human annotation를 비교하였습니다. 이전 연구들과의 공평한 비교를 위해, 저자들은 3가지 emotion subset에 대해서 평가를 진행하였습니다. 4가지 감정(분노, 행복, 중립, 슬픔), 5가지 감정(분노, 행복, 중립, 슬픔, 혐오), 9가지 감정('others'를 제외한 모든 감정들)에 대한 실험을 진행하였습니다.
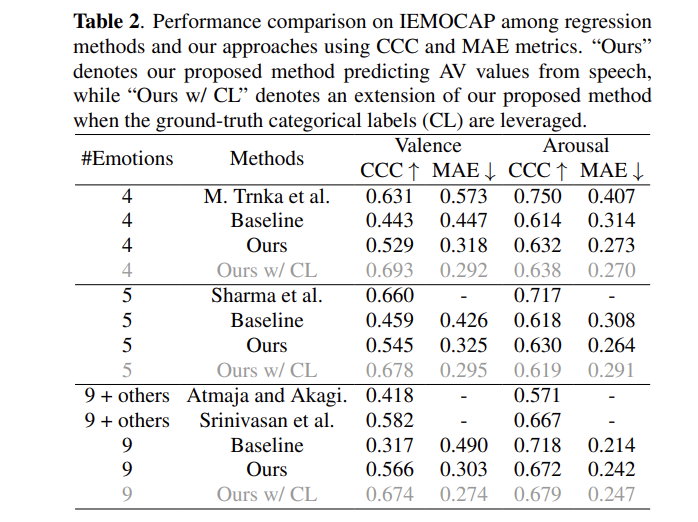
실험 결과는 위와 같습니다. 저자들의 method는 다른 최신 SOTA method와 비슷한 성능을 달성합니다. 4 and 5 emotion subset에 대해서 저자들의 method는 약간의 성능 저하가 존재하지만, 9개 emotion subset에 대해선 뛰어난 성능을 보여줍니다. 최신 supervised regression method들은 복잡한 model을 사용하고 categorical label과 text 정보 같은 보조적인 data도 활용하여 ground truth annotation으로부터 바로 학습을 진행하기 때문에 뛰어난 성능을 보여줍니다. 하지만 저자들의 method는 annotation 없이도 9가지 감정에 대한 실험에서 좋은 성능을 달성하였습니다.
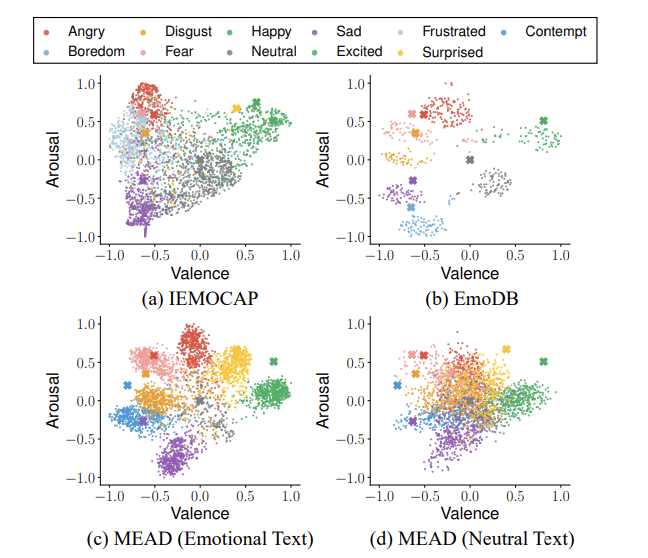
IEMOCAP, EmoDB, MEAD dataset에 대한 visualization 결과는 위와 같습니다. IEMOCAP의 경우, emotion cluster들이 guide anchor와 잘 정렬되어 있는 것을 볼 수 있습니다. EmoDB의 경우, 다른 dataset에 비해 더 뚜렷한 cluster를 형성하였습니다. 이 dataset은 화자가 10명 밖에 존재하지 않기 때문에 이러한 모습을 보인다고 합니다. MEAD의 경우, emotional text를 기반으로 얻은 emotion acting voice로 학습했을 때는 명확히 분리된 cluster를 보여줍니다. 하지만 neutral text를 사용한 경우엔 원점에 가까워지는 경향을 보였습니다.
Conclusion
저자들은 categorical label을 이용하여 speech의 arousal-valence (AV) representation을 학습하는 새로운 method를 제안합니다. 이는 self-supervised pretraining and anchor dimensionality reduction을 이용합니다. 이 method는 IEMOCAP dataset에 있어 simple regression baseline보다 뛰어난 성능을 달성했으며, SOTA regression techinque과 유사한 성능을 보여줍니다.



