https://dl.acm.org/doi/10.1145/3678515
StethoSpeech: Speech Generation Through a Clinical Stethoscope Attached to the Skin | Proceedings of the ACM on Interactive, Mob
We introduce StethoSpeech, a silent speech interface that transforms flesh-conducted vibrations behind the ear into speech. This innovation is designed to improve social interactions for those with voice disorders, and furthermore enable discreet public ..
dl.acm.org
해당 논문을 보고 작성했습니다.
Introduction
speech는 가장 효율적이고 간단한 social interaction and communication 수단입니다. 폐에서 나오는 공기가 성대를 진동시키고 혀, 볼, 입술의 조음으로 인해 speech가 생성됩니다. 하지만 특정 의학적 상태는 일반적인 음성 생성 과정을 방해할 수 있습니다. 예를 들어 신경성 음성 장애인 실성증(Aphonia)은 사람이 말을 하거나 들을 수 있는 소리를 생성할 수 없게 만들며, 이는 기도가 완전히 또는 부분적으로 막혀 발생합니다. 성대 마비, 성대 폴립, 또는 심리적 요인 등 여러 원인으로 인해 실성증이 유발될 수 있습니다. 현재 의학과 수술적 치료법이 일부 해결책을 제공하지만, 이러한 치료들은 여전히 도전과제를 동반하며 부작용이 발생할 가능성이 있습니다. 따라서 speech and sigmal processing의 발전을 통해 대안을 발견하는 것이 중요하며, 이는 Silent Speech Interfaces (SSI) 연구를 촉진해 왔습니다.
SSI는 acoustic signal을 생성하지 않고 수행되는 음성 의사소통을 의미합니다. 즉, 사용자가 소리를 내지 않고 조음 동작만 수행합니다. SSI 기술은 성대 진동에서 발생하는 무음 변형이나 진동을 분석하여 음성 내용을 이해합니다. SSI는 사용자 친화적이고 맞춤형으로 조정이 가능하며, 독립적이고 즉각적인 의사소통을 지원하는 등 다양한 장점들이 있습니다. Lip reading은 가장 단순한 SSI technique 중 하나입니다. 다른 기술들로 Ultrasound Tongue Imaging (UTI), real-time MRI (rtMRI), Electromagnetic Articulography (EMA), Permanent Magnet Articulography (PMA), Electrophysiology, Electrolarynx (EL), Electropalatography (EPG) 등이 존재합니다. 하지만 이러한 많은 기술들은 real-time 하지 않고 침습적이라는 특성 때문에 일상생활에 적용하기 어렵다는 문제가 존재합니다. 예를 들어 UTI는 초음파를 사용해 혀의 움직임을 capture 하고 rtMRI는 MRI를 이용해 upper airway의 mid-sagittal plane을 기록하고, EMA는 코일을 입술이나 혀와 같은 조음 기관에 붙여 움직임을 측정합니다. 또 다른 한계점으로 소음, 조명 등 환경적 제약이 존재하며 적응하기에 긴 시간이 소요된다는 점이 있습니다.
약 20년 전, 비 침습적 SSI 기술이 등장했으며, 이는 귀 뒤에서 발생하는 조직 진동을 capture하는 microphone을 사용하는 방식을 채택하였습니다. 저자들은 소형 condenser microphone을 의료용 청진기에 삽입해 특수 장치를 만들었으며, 이를 Non-Audible Murmur (NAM) microphone이라 부릅니다. 저자들은 작은 일본어 corpus를 이용해 NAM vibration으로부터 speech recognition의 가능성이 존재한다는 것을 입증하였습니다. 약 10년 후, 40분 길이의 영어로 녹음된 whispered speech와 NAM이 pair를 이루는 CSTR NAM TIMIT Plus가 공개되었습니다. 이후 NAM vibration을 conventional speech로 변환하는 연구들이 진행되었습니다.
기존 연구들에는 다음과 같은 제약들이 존재합니다. 먼저, SOTA approach는 특수 제작된 기기를 사용하며, 이로 인해 광범위한 사용이 어렵습니다. 다음 대부분의 연구들은 paired NAM-whisper or NAM-speech corpus이 사용 가능하다는 가정하에 진행됩니다. 이는 말하기 어렵거나 속삭임이 불가능한 환자에게는 비현실적일 수 있으며, 많은 상황에서 이에 해당됩니다. 세 번째로 대부분의 최근 연구들은 NAM vibration에서 얻은 Mel-based spectral feature를 바로 speech feature로 mapping 합니다. 이러한 model들은 ground-truth Mel에 존재하는 speaker와 ambient noise characteristic을 예측하는 경향이 존재합니다. 이를 통해 output speech의 quality에 영향을 받게 되며, NAM vibration과 같이 fundamental frequency가 없는 경우 어려움이 존재하게 됩니다. 그리고 NAM의 high-frequency 성분들의 감쇠 문제가 존재가 존재하는데, 이를 더욱 악화시킬 수 있습니다. 마지막으로 multi-speaker NAM dataset의 부재 때문에, 현재 존재하는 연구들은 아직 새로운 화자(zero-shot scenario)에 대한 real-time adaptability and generalizability를 연구하지 않습니다.
이러한 문제들을 해결하기 위해, 저자들은 StethoSpeech라는 새로운 machine learning-based framework를 제안합니다. 이는 NAM-to-speech conversion을 real-time and zero-shot scenario에서 수행 가능합니다. StethoSpeech와 SOTA의 차이는 다음과 같습니다.
- StethoSpeech는 일반 의료용 무선 청진기를 사용한 input을 받습니다. 이를 통해 저비용 및 광범위한 활용 가능성을 제공합니다.
- 저자들의 frameworks는 paired speech or whisper data를 필요로 하지 않습니다. 저자들은 recored NAM vibration과 그에 맞는 ground-truth text만 필요로 하며, textual data와 그에 대응하는 NAM vibration을 align 함으로써 ground-truth speech를 simulate하는 새로운 방법을 제안합니다. 이를 통해 normal speech나 whispering sound를 만들 수 없는 환자를 위한 맞춤형 모델 학습이 가능합니다.
- NAM-to-speech conversion에 대한 이전 연구들은 단일 사용자에 대한 실험만 진행하는 한계가 존재합니다. 반면에 저자들은 다중 사용자에 대한 실험을 진행했으며, StethoSpeech가 학습 과정에서 보지 못한 새로운 화자에 대한 일반화 성능이 존재한다는 것을 입증하였습니다.
- 저자들의 frameworks는 background and speaker-specific characteristic을 무사하고 content 정보가 풍부한 Self-Supervised Learning (SSL) representation을 사용합니다. 저자들은 NAM vibration에서 SSL embedding을 추출하고 이를 simulated speech data의 SSL embedding으로 변환합니다. 저자들은 Sequence-to-Sequence (Seq2Seq) mapping이 content는 유지하고 intelligibility는 향상시킬 수 있다는 것을 보이며, 약 35분 정도의 paired text-NAM data만 가지고 prosody를 복원할 수 있음을 보였습니다.
- SSL speech embedding을 얻은 다음 frozen speech decoder를 이용해 speech로 변환합니다. output speech는 pre-observed voice에 대해서 조정 가능합니다. 이 speaker-conditioned frameworks는 voice selection의 유연함을 제공합니다. speech decoder는 15~20분의 novel recorded voice를 가지고 augment될 수 있습니다.
- NAM vibration은 무선 청진기를 통해 bluetooth로 스마트폰에 전송되고, 스마트폰 speaker로 음성을 출력됩니다. StethoSpeech는 real-time inference performance를 달성했으며, 10초 길이 NAM vibration을 변환하는 데 0.3초보다 덜 걸립니다.
저자들의 approach를 평가하기 위해, 저자들은 12명의 화자로부터 자체적으로 구축한 StethoText corpus와 CSTR NAM TIMIT Plus dataset을 사용하였습니다. 저자들의 contribution은 다음과 같습니다.
- 저자들은 귀 뒤 피부에 부착한 사용 청진기를 이용해 intelligible speehc를 생성하는 새로운 StethoSpeech framework를 제안합니다. 저자들의 novelty는 (a) NAM과 text를 통한 noisy alignment를 이용해 paired speech를 simulate하고 (b) SSL embedding을 이용해 NAM-to-speech translation 하는 method를 제안하였습니다.
- 저자들은 15시간 이상의 NAM vibration과 text로 구성된 StethoText corpus를 공개하였습니다. 이 dataset은 noise가 존재하는 NAM sample을 포함하고 있습니다. 여기서 noise는 약간 소음이 있는 일상 사무실 환경, 매우 시끄러운 배경 음악이 있는 high noise 환경을 의미합니다.
- CSTR NAM TIMIT Plus와 제안한 StethoText dataset에 대한 종합적인 실험 결과를 제시하였습니다. 저자들의 method가 paired speech 없이도 SOTA method를 뛰어 넘었으며, 일관성 있는 prosody로 자연스러운 speech를 합성할 수 있습니다. 그리고 StethoSpeech는 일반적인 음성이 이해되지 않는 극단적인 소음 환경에서도 충분히 가능하다는 것을 보였습니다. 그리고 사용자가 걷는 등 mobility 상황에서도 framework가 동작 가능함을 보이며 robustness 하다는 걸 입증하였습니다.
Method
이전 NAM-to-speech 방식들은 paired speech & NAM vibration 또는 paired whisper audio & NAM vibration이 사용가능하다는 가정을 두었습니다. 이러한 method들은 처음에 studio recorded speech를 이용해 conversion model을 학습시킨 후 Dynamic Time Warping (DTW)를 이용해 Mel feature space에서 speech와 NAM vibration을 align 하였습니다. 저자들은 위 방식들들의 2가지 문제를 제안합니다. (1) 명시적으로 recording 된 ground-truth speech는 실용적이지 않을 수 있으며, 특히 speech를 생성할 수 없는 환자의 경우엔 불가능합니다. (2) DTW alignment는 converted speech signal에서 artifact를 유발하며, speech의 quality와 intelligibility를 저하시킵니다. 대신 저자들은 새로운 StethoSpeech method를 제안하며, 이는 paired speech data가 필요하지 않습니다.

위 그림은 StethoSpeech framework를 보여주며, 4가지 module로 구성되는 것을 볼 수 있습니다. ground-truth preparation module, speech encoder, Seq2Seq network, speech decoder로 구성됩니다. ground-truth data preparataion step은 이전 연구들과 다른 부분입니다. 이 과정에서 whisper or speech data 대신 text를 이용해 NAM vibration에 해당하는 ground-truth speech를 simulate 합니다. shared speech encoder는 NAM vibration과 ground-truth speech를 SSL embedding으로 변환합니다. Seq2Seq network는 vibration에서 얻어진 input embedding을 받아 그에 대응하는 speech embedding을 mapping 합니다. 마지막으로 speech decoder는 이 변환된 embedding을 이용해 output speech를 reconstruct 합니다.
Ground-truth Data Preparation
저자들은 ground-truth speech를 simulate 하는 새로운 방식을 제안합니다. 이는 NAm vibration과 그에 대응하는 textual content만 이용합니다. textual data가 주어지면, text-to-speech synthesis model을 이용해 ground-truth speech를 simulate 합니다. 하지만 NAM vibration과 simulated speech 사이 잠재적인 temporal misalignment가 발생할 수 있기 때문에 문제가 됩니다. unaligned data는 Seq2Seq network를 NAR 방식으로 학습시키는데 어려움을 일으킵니다. autoregressive model은 이러한 제약이 없습니다. 하지만 inference 속도가 느리고 skipping/repetition과 같은 문제 때문에 real-time으로 동작하는데 어려움을 직면하게 됩니다.
몇몇 NAR TTS model들은 각 phoneme의 rendering duration을 명시적으로 제어할 수 있습니다. 따라서, 저자들은 NAM vibration과 ground-truth text 사이 phoneme-level alignment를 적용함으로써 ground-truth speech를 simulate 할 수 있게 됩니다. 저자들은 forced alignment tool을 이용해 NAM vibration에 존재하는 모든 phoneme의 duration을 추출할 수 있습니다. 하지만 forced alignment tool은 내부적으로 acoustic model을 이용해 phoneme을 detect 하고 text-phonemicized token으로 align 할 것입니다. NAM vibration data의 경우 inaudible 하고 intelligibility가 부족하며 운율적 패턴을 전달하지 않는다는 특성이 존재하기 때문에, 기존의 acoustic model을 NAM vibration에 사용할 수 없습니다. 그러므로 저자들은 NAM vibration과 그에 대응하는 textual representation을 이용하여 acoustic model이 phoneme-level alignment를 수행할 수 있도록 학습시켜야 합니다. 저자들은 Montreal Forced Aligner (MFA) repository를 이용해 acoustic model을 학습시켰습니다. model은 먼저 vibration에서 39차원 Mel-Frequency Cepstral Coefficients (MFCC) feature를 추출합니다. 이후 40번의 monophone Gaussian Mixture Model (GMM) 학습과 35번 triphone GMM 학습을 수행하여 contextual phoneme information을 capture 합니다. 이는 phoneme-level duration을 얻기 위해 maximum likelihood linear regression을 이용하여 acoustic feature 변환을 학습합니다. 결과적으로 이 duration와 text를 FastSpeech2 TTS model에 넣어 input NAM vibration과 align 된 ground-truth speech를 합성합니다.
Speech encoder
SOTA NAM-to-speech conversion 기술은 Mel-cepstral feature를 이용해 raw audio를 encode 합니다. 하지만 이 feature는 주변 noise 특성과 같은 input audio의 전체 특징을 encode합니다. 그러므로 NAM-to-speech conversion model을 학습할 때, network는 주변 noise 정보도 복원하기 쉽습니다. 이는 학습일 복잡하게 만들고 converted speech의 intellgibility와 quality에 부정적인 영향을 미칩니다.
최근 SSL의 발전으로 인해 high-fidelity, compressed speech representation을 학습할 수 있습니다. 저자들은 speaker 정보와 주변 정보를 무시하고 풍부한 content 정보만 가지고 있는 분리된 representation을 얻는 것에 초점을 두었습니다. 이를 위해, 저자들은 Base HuBERT라는 self-supervised neural network를 사용하였습니다. 이 method는 audio를 작은 chunk로 분할하고 feature를 계산합니다. 그다음 k-mean algorithm을 통해 cluster 합니다. network는 cluster ID를 pseudo label로 사용하고 random 하게 masking 된 segment의 pseudo label을 예측하도록 classification을 수행합니다. 적절한 self-supervised unit을 얻기 위해 cluster id가 반복적으로 계산됩니다.
Seq2Seq network
unit-based Seq2Seq translation network의 발전과 함께, 저자들은 처음에 speech encoder를 통해 discrete unit level output을 이용한 speech translation을 시도하였습니다. 하지만 decoding 결과는 poor-quality speech가 되었으며, NAM vibration이 encode되고 이를 discrete unit으로 변환될 때 상당히 많은 정보 손실이 존재한다는 것을 발견하였습니다. 대부분의 unit-based Seq2Seq architecture에서 벗어나, 저자들은 latent space embedding을 이용하였습니다. NAM vibration을 embedding으로 encoding하는 것이 합성된 speech의 intelligibility를 향상시키기 때문에 이와 같이 수행하였습니다. shared speech encoder는 pre-trained HuBERT의 마지막 hidden layer에서 768차원 SSL embedding을 추출하였습니다. 그다음 저자들의 새로운 transformer-based Seq2Seq network가 이 embedding을 mapping 할 수 있도록 학습시켰습니다. real-time efficiency를 위해, 저자들은 NAR encoder-decoder network를 채택하였습니다. 이 구조는 1번 만에 output embedding을 예측할 수 있으며, 이전 embedding을 기반으로 한 번에 output embedding을 한 개씩 생성하는 autoregressive model보다 상당한 잠재적 이점이 있습니다.
6-layer Seq-encoder and Seq-decoder network는 two-multi-head self-attention block과 1-dim convolution으로 구성된 feed-forward transformer block을 포함하고 있습니다. Seq-encoder는 NAM vibration을 고정된 차원의 vector sequence로 처리하며 Seq-decoder는 ground-truth speech embedding을 예측합니다. 저자들의 방식은 ground-truth data preparation step을 통해 input embedding과 target embedding 사이 align을 수행했기 때문에 variance adaptor나 length regulator를 더 이상 사용하지 않습니다. 저자들은 batch size를 16, maximum step을 30,000으로 설정하였습니다. HuBERT model은 speech와 vibration을 50Hz의 frame rate로 encode 하였습니다. model은 MSE loss로 최적화되고 식은 다음과 같습니다.
$$L_{MSE} = \frac{1}{T} \sum_{i=1}^{T} {||S_{ssl_i}- \hat{S}_{ssl_i}||^2}$$
위 식에서 $S_{ssl}$은 ground-truth speech embedding을 나타내고, $\hat{S}_{ssl}$은 decoded speech embedding을 나타내며, $i$는 time-step의 index를 나타냅니다.
저자들은 Connectionist Temporal Classificiation (CTC) token을 예측할 수 있도록 Seq-encoder layer 뒤에 fully connected linear head를 추가적으로 사용하였습니다. text sequence를 tokenize 하기 위해, 저자들은 Wav2Vec2 tokenizer를 이용하였으며, text preprocessing을 수행하였습니다. input NAM embedding $N_{ssl}$이 주어졌을 때, $Enc_{ssl}$를 Seq-encoder의 output이라 하겠습니다. $C$를 ground-truth text에 대응하는 character label이라 하겠습니다. 이때 negative log-likelihood를 minimize 하는 것이 goal이며 다음과 같습니다.
$$L_{CTC} := -log{P_{CTC}(C|Enc_{ssl})}$$
MSE와 CTC loss function에 weighted sum을 적용하여, 최종 objective function은 다음과 같이 정의됩니다.
$$L_{Tot} = \alpha_{CTC} * L_{CTC} + \alpha_{MSE} * L_{MSE}$$
저자들은 $\alpha_{CTC} = 0.001, \alpha_{MSE} = 1$로 설정하였습니다.
Speech decoder
speech를 생성하기 위해, 저자들은 Seq2Seq network에서 예측된 speech embedding을 input으로 받고 decoder가 output으로 speech를 합성합니다. HiFiGAN-v2를 이용하여 self-supervised embedding을 speech 합성에서 사용합니다. 하지만 HiFiGAN-v2는 discrete unit을 input으로 받지만, 저자들은 Seq2Seq model이 예측한 embedding을 사용합니다. 그래서 저자들은 two-step process를 사용합니다. 먼저 Fairseq repository를 이용하여 English voice로 k-means model을 학습시켰습니다. inference 할 땐 학습된 k-means model을 이용해 cluster unit을 예측하였습니다. 이 cluster unit을 HiFiGAN speech decoder의 discrete unit으로 사용하였으며, 이를 통해 model의 speech generation 성능을 사용할 수 있었습니다.
decoder의 generator는 ground-truth speech의 SSL unit을 upsampling 하기 위해 transposed convolution을 이용하였으며, receptive field expansion을 위해 residual block을 이용하여 합성된 signal을 생성하였습니다. discriminator는 합성된 signal과 original signal을 구분하며, multi-period and multi-scale network를 이용해 temporal pattern, detail, global structure를 capture 합니다. 두 signal 사이 dissimilarity를 minimize 하도록 main objective가 설계되었으며, speech fidelity도 향상시킵니다. 저자들은 multi-speaker speech decoder를 학습시켰으며, 사용자가 원하는 화자의 음성을 생성할 수 있도록 지원하였습니다.
Results
Simulated Ground-truth speech
text와 NAM vibration을 align 하여 ground-truth speech를 simulation 하는 것이 저자들의 StethoSpeech framework와 이전 연구들과의 차이입니다. CSTR NAM TIMIT Plus와 StethoText dataset에 대한 simulated speech quality를 평가하였습니다. 먼저, NAM-to-Speech conversion과 동일한 구조이지만, whisper-to-speech conversion을 수행하도록 paired data를 이용하여 학습시킨 model을 "Paired-Baseline"으로 표현합니다.
- CSTR NAM TIMIT Plus
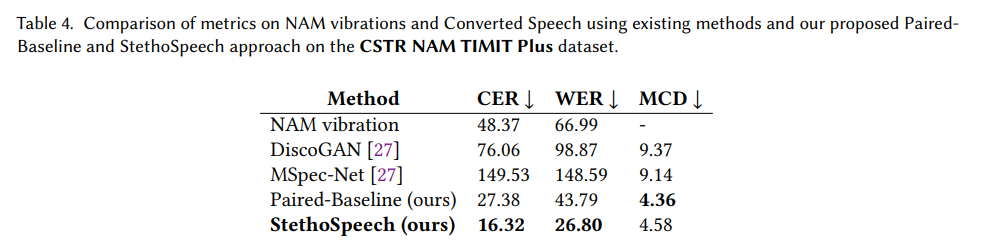
NAM vibration과 그에 대응하는 text, whisper audio를 포함하고 있는 corpus입니다. 저자들은 text를 기반으로 하는 alignment method를 사용하였으며, paired-Baseline을 위해 whisper에 대해서도 ground-truth speech를 simulation을 수행하였습니다. 실험 결과는 위와 같습니다. NAM-text alignment를 이용하는 것이 whisper에서 speech를 생성한 것보다 더 뛰어난 성능을 보여줍니다.

위 표는 StethoText에 대한 실험 결과를 보여줍니다. NAM-text alignment method를 이용하여 simulate 한 ground-truth speech에 대한 실험 결과입니다. s1, s2에 대한 sample이 더 많기 때문에, alignment module이 더 높은 quality를 보여주는 것을 알 수 있습니다.
Evaluation on the StethoText corpus (speaker-specific models for speakers s1 and s2)

위 표는 NAM vibration과 그에 대한 converted speech에 대한 error rate를 보여줍니다. speaker s1, s2에 대한 data로 평가를 진행했습니다. Seq2Seq architecture를 통해 3가지 다른 목소리로 변환을 수행하였습니다. 이를 통해 voice selection 성능을 강조하였습니다. raw NAM vibration을 ASR model에 넣은 경우, error rate가 100%를 초과하였습니다. 이는 추가적인 단어를 예측하여 발생한 결과이며, NAM 진동의 내용이 전혀 이해할 수 없는 상태임을 의미합니다. 하지만 StethoSpeech로 변환한 speech의 error rate를 보면 SOTA랑 유사하며, StethoSpeech의 우수성을 입증합니다.
Zero-Shot evaluation

학습 때 보지 못한 화자(zero-shot setting)에 대한 StethoSpeech의 변환 성능 결과입니다. 학습 때 보지 못한 화자에 대해서도 우수한 성능을 보이는 것을 알 수 있습니다. 그리고 다른 성별에 대해서도 뛰어난 성능을 보였습니다. 저자들의 framework는 NAM에는 fundamental frequency, speaker characteristic이 존재하지 않기 때문에 이러한 일반화 성능을 보인다고 합니다.



