https://arxiv.org/abs/2307.03168
Recovering implicit pitch contours from formants in whispered speech
Whispered speech is characterised by a noise-like excitation that results in the lack of fundamental frequency. Considering that prosodic phenomena such as intonation are perceived through f0 variation, the perception of whispered prosody is relatively dif
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
whispered speech는 noise와 같은 음성 특징을 가지고 있으며 fundamental frequency가 결여되어 있습니다. 억양(intonation)과 같은 prosodic phenomena는 주로 $f_0$ 변화를 통해 지각되기 때문에, whispered prosody를 지각하는 것은 상대적으로 어렵습니다. 연구에 따르면 화자들은 속삭임 과정에서도 억양을 생성하려 한다는 것이 밝혀졌으며, 운율적 변화가 전달되고 whispered formant 구조에 억양이 남아있습니다.
이 논문에서 저자들은 machine learning model을 이용해 속삭임에 있는 implicit pitch contour와 formant contour가 어떻게 상관관계가 있는지 추정하는 것을 목표로 합니다. 저자들이 제안한 method는 two-step으로 이뤄집니다: parallel corpus와 denoising autoencoder를 이용해 whispered formant를 phonated formant로 변환합니다. 그다음 phonated pitch contour의 변화를 예측하기 위해 formant contour를 분석합니다. 저자들의 method는 whispered formant와 phonated formant 간의 relationship을 확립하고, whisper에 있는 implicit pitch contour를 발견하는 데 효과적임을 확인하였습니다.
Introduction
pitch는 prosody를 encoding할 때 중요한 feature이며, 시간에 따른 pitch 변화는 억양의 특성으로 정의됩니다. whispered speech에서는 성문이 열린 채로 유지되고 성대가 진동하지 않기 때문에, fundamental frequency가 존재하지 않습니다. 이론적으로 whisper를 통해 pitch와 운율의 전달이 이뤄지지 않습니다. 하지만 여러 연구들에서 청자들은 whispered speech에서 pitch와 억양 효과를 지각할 수 있음을 발견했습니다. 마찬가지로, whispered signal에는 억양에 대한 단서를 제공하는 특징이 포함되어 있다는 것으로 보입니다.
특히 whispered speech에서 F1의 상승 (formant raising)은 phonated speech과 비교하여 잘 알려진 특징입니다. whisper에서 나타나는 더 높은 formant frequency position은 더 열린 vocal tract 구성과 관련이 있을 수 있습니다. 이전 스웨덴어 관련 연구에서 whispered 모음은 jaw (하악)이 더 열린 상태를 유지한다는 것을 보여줬습니다. 하지만 다른 연구에서는 formant raising이 whispered pitch perception와 연관 있다고 말합니다. 예를 들어 청자들이 F1과 F2의 상승을 기반으로 low pitch와 high pitch의 whispered 모음을 구별할 수 있음을 보여주었습니다. 그리고 상승된 formant frequency는 prosody-related laryneal activity와 연결되는 것으로 봅니다. 다른 연구에서는 whispered speech를 생성할 때, pitch 변화와 관련된 후두 움직임이 phonated speech에서와 유사하게 유지된다는 것을 보여주었습니다. 이는 whispered speech에서도 운율과 관련된 구강 구조의 변형이 일어나며, vocal tract을 통과하는 음향을 변경할 수 있음을 나타냅니다. 이를 통해 청자는 pitch를 추론할 수 있게 됩니다.
$f_0$와 formant 사이 harmonic relation은 speech technology에서도 사용되어 왔습니다. 예를 들어 whisper speech로부터 phonated speech를 복원하는 voice conversion system에 대한 몇몇 연구들의 solution은 GAN을 이용해 whispered speech로부터 harmonic excitation을 생성하여 사라진 $f_0$를 해결하기도 합니다.
이 논문에서 먼저 저자들은 phonated speech에 있는 $f_0$와 formant 사이 관계와 whispered speech의 spectral 특성과의 connection을 학습하는 것을 목표로 합니다. 이를 위해, 저자들은 whispered formant value의 변화를 통해 phonated speech에 존재하는 $f_0$의 변화를 modeling하는 machine learning method를 제안합니다. 이 method의 goal은 $f_0$ 없이도 prosody를 지각할 수 있게 하는 whispered speech 내의 implicit pitch contour를 발견하고 이해하는 것입니다. 또 다른 goal은 voice conversion을 수행하는 것입니다.
Method
Data
이 논문에서 저자들은 phonated and whispered speech pair로 구성된 CHAINS dataset을 사용하였습니다. CHAINS는 20명 남성과 16명 여성의 Irish, American speaker로 구성되어 있습니다. dataset은 natural phonated and whisper라는 서로 다른 speech mode로 녹음한 sentence와 그에 맞는 text fragment로 구성됩니다. 저자들은 Wav2Vec2 model을 이용해 phonated audio sample을 transcribe 하고, 이를 whispered speech에 copy 하였습니다. 그다음 Montreal Forced Aligner을 이용해 pre-trained model로 labeling을 수행하였습니다.
Feature extraction and preprocessing
모음 phone에서 $f_0$와 formant contour를 추출했습니다. $F_0$ value는 Praat를 이용해 0.01 time step마다 추출되었으며, pitch floor와 ceil은 75, 300Hz입니다. formant contour를 추출하기 위해, 저자들은 Praat의 Burg method를 이용하였으며, 최대 formant 수를 5로 설정했습니다. 남성 화장의 경우 formant ceiling을 5000Hz로, 여성 화자의 경우 5500Hz로 설정했으며, Escudero method로 최적화를 진행했습니다. formant contour의 speaker variability를 줄이기 위해, 저자들은 각 speaker 마다 Lobanov's normalization method를 적용해 정규화하였습니다. 이를 통해 data는 평균 0, 분산 1이 되었습니다.
Whispered pitch prediction
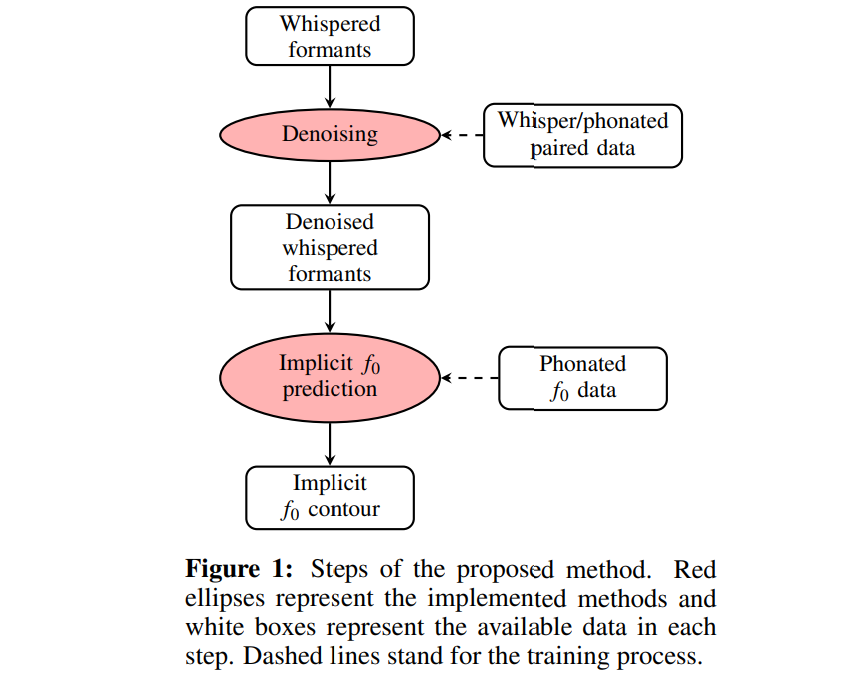
whispered formant structure에서 whispered speech에 있는 implicit $f_0$ contour를 추정하기 위해 machine learning method를 제안합니다. two-step method를 사용하며 위와 같습니다. first step에서 저자들은 paired phone에 존재하는 whispered and phonated formant의 relationship을 이용하여 whispered formant frequency의 denoised representation을 만들어줍니다. 두번째 step에서는 denoised formant representation과 phonated $f_0$를 modeling 함으로써 implicit, whispered $f_0$ contour를 예측합니다.
Formant denoising
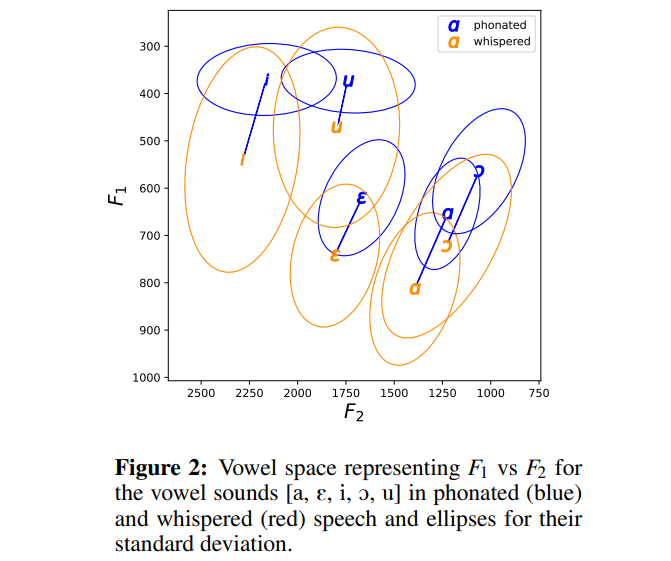
whispered formant structure는 phonated formant structure와 매우 연관이 있다고 저자들은 가정합니다. 단, whisper에서는 formant frequency가 상승하고 spectral evelope peak가 평탄화되어, 결과적으로 더 잡음이 많은 형태로 나타납니다. 저자들이 사용한 dataset에서는 위와 같은 모음 공간이 생성됩니다. 몇몇 phone은 dataset에서 자주 등장하지 않아 $F_1$ value의 분산이 높은 모습을 보여줍니다. whispered speech의 효과로 인해 phonated에 비해 $F_1, F_2$의 formatn value가 상승되는 모습을 보여줍니다.
저자들은 whispered formant contour를 phonated formant의 noisy representation으로 고려하여 whispered formant contour를 phonated formant contour로 변환하기 위한 denoising strategy를 제안합니다. formant contour에서 higher-order statistical information을 학습하는 autoencoder를 사용합니다. whispered-phonated formant pair를 model의 input, output으로 사용하여 whispered speech에서 얻은 contour를 동일한 phone의 phonated speech의 formant contour로 mapping 하는 것을 목표로 만듭니다.
symmetric encoder-decoder 구조로 구성된 machine learning method를 사용합니다. time-dependent feature를 filtering하기 위해 3개 1D convolutional layer (16 channel, 3 kernel length)를 사용합니다. 이 layer 뒤에 fully-connected layer를 추가하고, 이를 통해 whispered formant contour로부터 encoder embedding을 생성합니다. decoder는 embedding을 phonated speech formant로 변환하기 위해 3개 transposed convolutional layer를 사용합니다.
저자들은 data에 있는 대부분의 contour에 variation이 많지 않다는 것을 알아냈습니다. 그래서 network의 bias가 constant value를 예측하도록 치우칠 가능성이 존재합니다. target contour와의 similiarity를 maximize 하기 위해, 저자들은 target and predicted contour 사이 cosine distance를 구하는 loss function을 사용하였습니다.
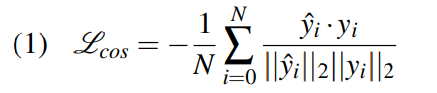
위 식에서 $y_i$와 $\hat{y}_i$는 i번째 sample의 target formant sequence와 denoised formant sequence를 의미하며, $\cdot$ 은 두 vector 사이 dot product를 나타냅니다.
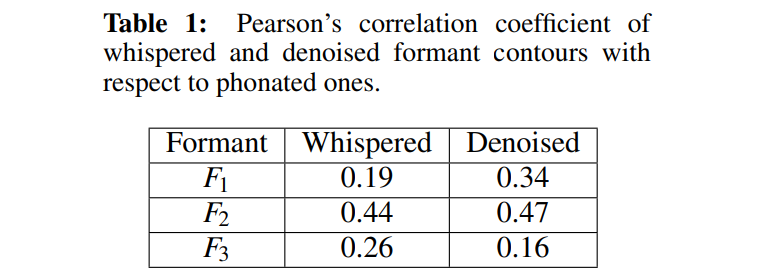
dnl vysms $F_1, F_2, F_3$ 의 correlation coefficient를 나타냅니다. phonated and denoised formant contour 사이 correlation의 경우, $F_1, F_2$에서는 증가되지만 $F_3$에서는 감소되는 것을 볼 수 있습니다. 그러므로 저자들은 denoised $F_1, F_2$를 사용하고 unmodified $F_3$를 사용합니다.
Implicit $f_0$ prediction
denoised $F_1, F_2$, unmodified $F_3$의 contour를 기반으로 implicit $f_0$ contour를 추정하는 sequence prediction model이 second step입니다. phonated data의 $f_0$ contour가 whispered data와 연관되어 있을 것이라는 가정을 기반으로 합니다. formant contour에서 non-existing pitch signal의 정확한 value를 modeling 하는 것은 어려운 task입니다. 그러므로 이 model은 억양 변화를 나타내는 pitch contour의 relative change를 추정하는 것에 focus 합니다.
저자들은 sequence에서의 시간적 dependency를 효과적으로 uncover 할 수 있는 deep learning method인 RNN을 사용합니다. formant와 $f_0$ contour의 시간적 의존성을 고려하면, sequence-to-sequence model이 두 dynamic contour 사이 의존성을 특히 효과적으로 modeling 할 수 있습니다. input formant contour는 two bi-directional LSTM layer with 4 hidden unit으로 처리되어 총 8-dim feature sequence가 됩니다. 그다음 8-dim feature sequence를 그에 대응하는 target pitch value로 mapping 하는 fully-connected layer에 의해 output sequence가 생성됩니다.
formant denoising과 유사하게 target sequence와 similarity가 maximize 되도록 만들어주는 function이 필요합니다. MSE 대신 cosine similarity를 사용해 더 정확한 근사가 가능합니다. 그리고 target의 pitch value도 근사하기 위해, 저자들은 loss function에 MSE도 추가하였습니다. 최종 loss function은 다음과 같이 MSE와 cosine similarity의 combination 형태입니다.
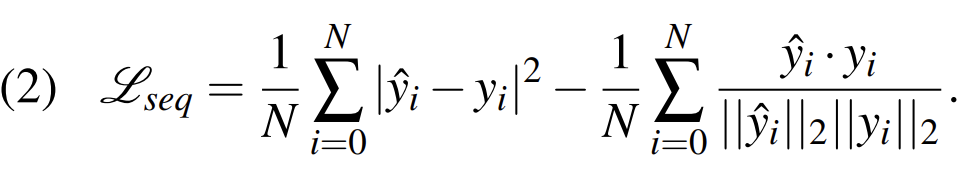
Results
먼저, 저자들의 실험 결과는 whispered formant를 denoise 할 때, whispered and phonated speech 사이 relationship을 성공적으로 사용하고 있다는 것을 보여줍니다. Table 1을 통해, denoised whispered formant contour가 phonated couterpart와 더 높은 correlation을 보인다는 것을 알 수 있습니다. 가장 크게 개선된 부분은 $F_1$에서 볼 수 있으며, 이는 whispered speech와 phonated speech 간의 가장 큰 차이를 보이는 부분입니다.
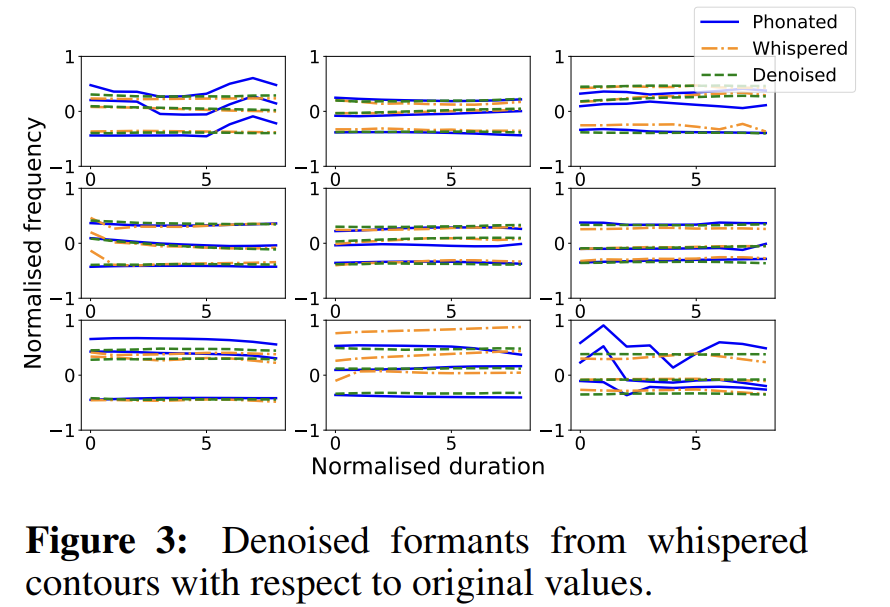
위 그림은 denoised formant contour의 여러 예재를 보여줍니다. denoising model이 smoothing function 역할을 하는 것을 볼 수 있습니다. 이를 통해 CHAIN corpus dataset에 있는 모음 구간에서 cosine similarity loss function이 frequency contour formant를 정확히 estimate 할 수 있도록 만들었음을 알 수 있습니다. 하지만 몇몇 extreme 한 case (contour variability가 높은 경우)에서는 network가 실패한 모습을 보여주며, 이는 formant tracking error, 주변 phone의 잔여 영향 등 다양한 원인 때문으로 볼 수 있습니다.
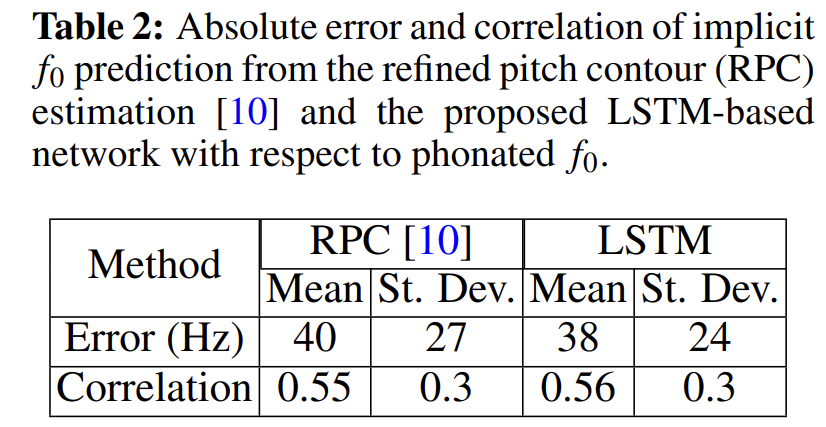
위 표는 pitch prediction step에서 측정된 error와 correlation value를 나타냅니다. refined pitch contour (RPC)는 baseline입니다. 저자들의 model이 predicted and target contour 사이 positive correlation (Mean r = 0.56, SD = 0.3)을 보여줍니다.
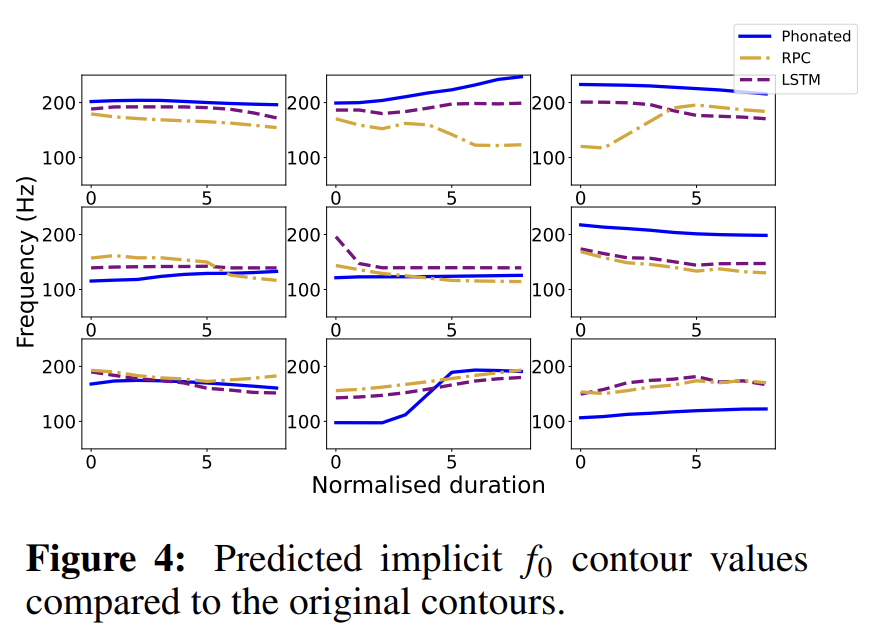
위 그림은 predicted and phonated contour의 mapping 결과를 보여줍니다. 대부분의 case에서 올바른 경향을 보여줍니다. RPC baseline과 비교했을 때, LSTM이 개별 case에서 더 나은 결과를 보였지만, correlation과 error는 비슷한 결과를 보였습니다. 이는 LSTM과 같은 복잡한 system이 최소한의 formant set 외에도 추가적인 input feature를 활용한다면 성능이 향상될 것으로 예상되는 결과라 합니다.
Conclusion
이 논문에서 저자들은 whispered vowel의 formant contour로부터 implicit $f_0$ contour를 추정하는 machine learning method를 제안합니다. 저자들의 model은 whisper speech에서도 implicit $f_0$ trajectory를 uncover 할 수 있으며, $F_1, F_2, F_3$만 사용하여 이를 수행합니다.



