https://arxiv.org/abs/1611.07004
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org
해당 논문을 보고 공부하고 작성했습니다.

0. Abstract
이 논문은 이미지를 이미지로 변환에 대해서 해결하기 위해 conditional adversarial networks에 대한 연구를 진행했습니다. 이 네트워크는 input 이미지로부터 output 이미지를 mapping 하는 학습할 뿐만 아니라 mapping을 train 하기 위해 loss function도 학습합니다. 이 논문은 Pix2pix를 이용합니다.
Pix2Pix
먼저, image-to-image translation은 이미지를 입력으로 받아 또 다른 이미지를 출력으로 반환하는 작업을 주로 의미합니다. Pix2Pix는 이미지를 이미지로 변환하도록 generator를 학습합니다. 예를 들어, generator의 입력값으로 스케치 그림을 입력하면 완성된 그림이 나오도록 학습할 수 있습니다. 기존 GAN과 비교하여 설명하면, Pix2Pix는 기존 GAN의 noise 대신에 스케치 그림을 입력하여 학습할 수 있습니다.
1. Introduction
이미지 처리, 컴퓨터 그래픽, 컴퓨터 비전에서 많은 문제는 input 이미지에 대응하는 output이미지로 변환하는 문제를 갖고 있습니다.
위 그림과 같이 많은 데이터셋이 존재한다면 이미지를 이미지로 변환할 수 있습니다. 이미 Convolution Neural Network(CNN)을 통해 이미지 예측 문제를 해결하고 있습니다. CNN은 loss function을 최소화하기 위해 학습이 진행되고 학습이 자동으로 됩니다만, 효과적인 loss를 지정하는 데는 여전히 많은 수작업이 필요합니다. 만약 CNN으로 얻은 결과와 타깃 사이 유클리디언 거리를 줄이는 방향으로 학습을 진행한다면 모데른 흐릿한 이미지를 출력합니다. 그래서 Generative Adversairal Network(GAN)을 이용해 학습을 진행합니다. GAN에서 generative model은 loss를 줄이기 위해 학습이 진행되고 generative model이 예측한 output이미지가 진짜인지 가짜인지 판단하는 학습도 진행합니다. GAN 구조를 이용해 학습을 진행한다면 blur 처리된 이미지는 가짜라고 판별될 것입니다.
일반 GAN은 generative model의 데이터를 학습하기만 하지만, conditional GAN(cGan)은 conditional generative model을 학습합니다. input 이미지를 조건으로 대응하는 output 이미지를 생성하기 때문에 cGAN은 이미지에서 이미지로 변환하는 작업에 적절합니다.
2. Related Work
Structured losses for image modeling: Image-to-image translation의 문제는 자주 픽셀 단위로 분류되거나 회귀된다는 점입니다. 이러한 문제는 입력 이미지가 주어진 경우 각 출력 픽셀이 조건부로 다른 모든 픽셀과 독립적이라고 간주되고 이러한 점에서 출력 공간을 구조화되지 않은 것으로 간주됩니다. cGAN은 구조화된 loss(output의 공동 구성에 페널티를 부가하는 방식)를 학습합니다.
Conditional GANs: 이 논문 이전에는 불연속적인 label, text, 그리고 image에 대해 conditioned 된 GAN 구조를 발표했습니다. image-conditional model은 일반 지도로부터의 이미지 예측, 미래 프레임 예측, 제품 사진 생성을 다루었습니다. 이 논문에서는 application specific이 존재하지 않는 점이 다른 구조와는 다르고 이를 통해 다른 모델들에 비해 setup이 심플해졌습니다. 이 논문에서 제시한 model은 generator와 discriminator에 대한 몇몇 아키텍처 선택도 다릅니다. generator의 구조로 "UNet"을 이용하고 discriminator의 구조로는 convolutional "PatchGAN" classifier를 사용했습니다.
3. Method
GAN은 random noise vector z로부터 output image y(G: z -> y)를 mapping 하는 학습을 합니다.

conditional GAN은 위 그림과 같이 input 이미지 x와 random noise vector z를 이용해 output image y(G: {x, z} -> y)를 mapping 하도록 학습이 진행됩니다. generator G는 discriminator D(generator가 생성한 가짜 이미지를 잘 구별할 수 있도록 학습된)가 real image와 구분하지 못하는 image를 생성하도록 학습됩니다.
3.1 Objective
conditional GAN의 목표는 최소화하려는 G의 목표에 적대적인 D에 최댓값을 갖도록 하는 것입니다.
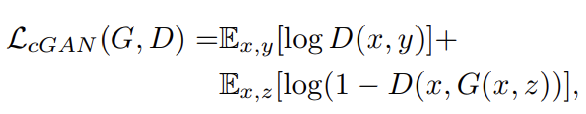
위 식과 같이 표현할 수 있습니다. unconditional 같은 경우 discriminator는 x를 받지 않습니다.
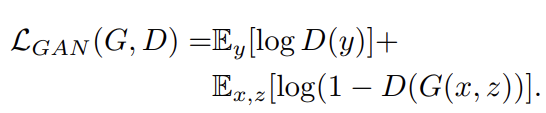
위 식과 같이 표현할 수 있습니다. conditional GAN에서 위 loss를 그냥 사용하기보다는 L1, L2 Norm 같은 traditional loss를 추가해 사용해 조금 더 나은(덜 blurring 한) 이미지를 생성할 수 있게 됩니다.
이 논문에서 L2 Loss를 사용하지 않고 L1을 사용해 더 적은 blur를 얻을 수 있는 것을 알아냈습니다.

그래서 최종 loss는 위와 같은 식으로 정의됩니다. z 없이도 x를 통해 y를 mapping 가능하지만, 다양한 mapping을 생성할 수는 없습니다. 생성 이미지에 영향을 주기 위해 z를 사용합니다. 최종 모델의 경우 train과 test에서 generator의 몇몇 층에 dropout을 추가해 noise를 추가합니다.
3.2 Network architectures
generator와 discriminator 둘 다 convolution-BatchNorm-ReLu를 이용했습니다.
3.2.1 Generator with skips

과거 generator 구조로 skip connection을 이용하지 않았습니다. input x를 인코더로 단순히 압축하고, 압축된 벡터를 다시 디코더로 복원해 y를 만드는 구조였고 이 경우, 핵심적인 정보만 남게 됩니다. 즉, 디테일한 정보는 유지하기가 쉽지 않게 됩니다. 그래서 U-Net을 이용했습니다. U-Net은 skip connection을 추가해 디테일한 부분 또한 전달할 수 있게 됩니다.
3.2.2 Markovian discriminator(PatchGAN)
잘 알려진 L2 loss, L1 loss을 이용하면 blurry 한 결과를 보여줍니다. 아래 그림을 보면 알 수 있습니다.

비록 고주파(급격하게 색이 변경되는 부분)에서 선명도를 높여주지는 못하지만, 저주파(색 변화가 크게 나타나지 않는 부분)에서의 선명도는 높여주고 있습니다. L1을 이용하면 저주파수의 선명도를 높일 수 있습니다. GAN discriminator는 고주파수 구조에서만 사용하고, 저주파수에서는 L1 loss를 이용해 선명도를 높일 수 있습니다. discriminator의 구조를 pathes 크기만큼의 구조에만 페널티를 부과하는 방식으로 디자인했습니다. discriminator는 NxN patch 만큼의 각각 이미지가 진짜인지 가짜인지 판별하도록 노력합니다. discriminator가 전체 이미지에 대해서 convolution을 진행하고, discriminator의 최종 output을 얻기 위해 값들의 평균을 냅니다.
전체 이미지보다 훨씬 작은 크기의 N으로 학습을 진행해도 높은 결과를 보여줍니다. 왜냐면 PatchGAN 구조에서 N의 크기가 작으면 그만큼 parameter의 수는 줄어들고 빠르게 진행되고 임의로 큰 이미지에 적용 가능하기 때문입니다.
이러한 discriminator는 path보다 더 작게 분리된 pixel 간의 독립성을 가정하여 image를 Markov random field로 효과적으로 modeling 할 수 있습니다. 그러므로 여기서 사용하는 PatchGAN은 texture/style의 loss로 이해할 수 있습니다.
3.3 Optimization and inference
이 논문은 network를 최적화하기 위해 gradient descent를 discriminator가 진행한 후 generator가 진행합니다. 이렇게 번갈아 가면서 최적화가 진행됩니다. generator는 log(1 − D(x, G(x, z))의 값을 최소화시키고, discriminator는 log D(x, G(x, z)) 의 값이 커지도록 최적화가 진행됩니다. 미니 배치에 SGD를 사용하고 Adam을 사용하며, learning rate는 0.0002, momentum parameter는 β1 = 0.5, β2 = 0.999로 설정했습니다.
4. Experiments

위 그림과 같이 복원된 이미지를 구할 수 있습니다.
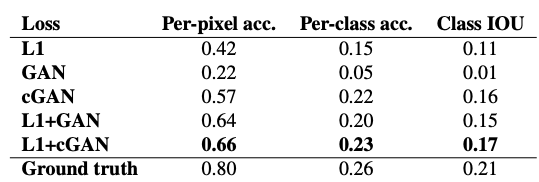
위 오차는 다양한 loss를 사용한 FCN-score, Cityscape의 label/photo로 측정한 값입니다.

위 결과를 보면 확실히 L1 + cGAN을 이용한 경우 생성된 이미지 품질이 좋은 것을 볼 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| custom dataset으로 YOLOv5 학습하기(마스크 인식) (0) | 2022.07.02 |
|---|---|
| [논문] Improved Training of Wasserstein GANs(WGAN-gp) (0) | 2022.04.04 |
| UNet++ 코드 (0) | 2022.03.30 |
| [논문] Unet++ : A Nested U-Net Architecture for Medical Image Segmentation (0) | 2022.03.28 |
| DenseNet 코드 (0) | 2022.03.24 |



