https://arxiv.org/pdf/1704.00028.pdf
해당 논문을 보고 작성했습니다.

Abstract
GAN(Generative Adversarial Network)는 powerful 한 모델이지만 학습 불안정성을 보입니다. 최근 제시된 Wasserstein GAN(WGAN)은 안정된 GAN 모델이지만 아직도 때때로 좋지 않은 샘플을 만들거나 값이 수렴하지 않습니다. 이러한 원인으로 Lipschitz 제약을 critic(discriminator)에 적용하기 위해 WGAN에서 가중치 클리핑을 사용하기 때문이라고 볼 수 있습니다. 그래서 이 논문에서는 clipping weights를 대신할 수 있는 것을 제시합니다: critic의 입력에 대해서 gradient의 norm에 페널티를 부여합니다. 이 방식을 사용하면 일반적인 WGAN에 비해 더 좋은 성능을 보이고, 101개의 ResNet과 연속적인 generator의 모델을 포함하여 hyperparameter 설정 없이 다양한 GAN 학습을 안정화할 수 있습니다.
1. Introduction
GAN은 generator와 discriminator의 서로 다른 적대적인 network를 사용하는 powerful 한 생성 모델입니다. GAN은 시각적으로 매력적인 샘플들을 만들 수 있지만 때 때로 학습하기 어렵고 최근에는 학습을 안정적으로 할 수 있는 방법들이 연구되고 있습니다. 그리고 아직까지도 GAN의 안정적인 학습은 문제로 남아있습니다.
Wasserstein GAN(WGAN)이라는 이름을 가진 모델이 있는데 이는 원래 GAN보다 더 나은 이론적 특징을 가진 가치 함수를 생성하기 위해 Wasserstein distance(결합 확률분포는 두 분포가 동시에 일어날 때의 사건에 대한 확률 분포를 의미하는데, 이렇게 동시에 일어나는 확률에 대해서 우리가 그 각각의 거리가 최소가 될 때를 wasserstein distance라고 한다)
를 사용했습니다. WGAN은 discriminator(여기서는 critic으로도 불립니다)가 weight clipping을 통해 시행되는 1-Lipsechitz function의 공간 내에 있어야 합니다.
- toy datasets에서 critic weight clipping이 올바르지 않은 결과를 어떻게 가져오는지를 정의했습니다.
- WGAN과 같은 문제를 겪지 않은 새로운 gradient penalty(WGAN-GP)를 제안했습니다.
- 다양한 GAN 구조에서 안정적인 training, weight clipping의 성능 향상, 고품질 image 생성 및 discrete sampling 없이 character level GAN 언어 모델을 정의했습니다.
이 논문은 위 세 가지를 제시합니다.
2. Background
2.1 Generative adversarial networks
GAN의 학습 전략은 우리가 알다시피 서로 반대되는 두 네트워크 사이에 게임으로 정의할 수 있습니다. generator는 input으로 noise 된 이미지를 받고 새로운 이미지를 만듭니다. discriminator는 generator가 만든 sample 또는 원본 데이터 sample을 받고 판별합니다. generator는 discriminator를 속일 수 있도록 학습이 진행됩니다.
식으로 표현하면 위와 같이 표현할 수 있습니다. D는 discriminator를 의미하고 G는 generator를 의미하며 두 network 사이의 게임을 minimax objective로 표현합니다. P_r은 데이터 분포를 의미하고, P_g는 model 분포를 의미하고 x˜ = G(z), z ∼ p(z)(z는 generator의 input으로 들어가는 값이고 이는 noise 분포 p로부터 sample 된 값입니다)로 정의됩니다. 만약 discriminator가 generator parameter가 업데이트되기 전에 최적의 학습을 한 상태이면, value function을 최소화될 것이고 이는 P_r과 P_g사이의 Jensen-Shannon 차이를 최소화하는 것이 됩니다. 하지만 이렇게 된다면 discriminator가 포화될 때 gradient가 사라지는 경우가 종종 발생합니다.
위 표를 보면 gradient vanishing이 일어나는 이유를 알 수 있습니다. 파란색 선은 discriminator가 판별하는 선이 됩니다. 선을 기준으로 아래에 있으면 진짜 이미지로 판별을 하고 위에 있으면 가짜 이미지로 판별합니다. 이때 generator가 생성한 가짜 이미지를 진짜 이미지로 판별하는 모습을 볼 수 있고 이렇게 되면 generator는 더 이상 feature을 학습할 필요가 없게 되고 그로 인해 gradient vanishing이 일어나는 것을 볼 수 있습니다. 최적의 discriminator일 때 generator의 parameter가 update 되기 전에 gradient가 사라지게 되어 학습이 일어나지 않거나 매우 느리게 학습되는 일이 발생합니다.
2.2 Wasserstein GANs
GAN에서 일반적으로 최소화하는 divergence는 generator의 매개 변수와 관련해 불연속적일 수 있으며, 이는 학습의 어려움을 야기합니다. 그래서 Earth-Mover(Wasserstein-1과 동일) 거리 W(q, p)를 대신 사용하라고 하는데, 이는 분포 q를 분포 p로 변환하기 위해 그렇습니다. 경미한 가정하에서, W(q, p)는 모든 공간에서 연속적이고 미분 가능합니다.
WGAN의 value function은 Kantorovich-Rubinstein duality을 이용해 구성됩니다.
D는 1-Lipschitz function의 집합이고, P_g는 GAN과 동일하게 정의됩니다. 이 경우, 최적의 discriminator(critic으로 불리고 여기서는 분류를 의해 학습되지 않습니다)하에, generator 매개변수에 관련된 value function을 최소화하는 것은 W(P_r, P_g)를 최소화하는 것과 같습니다. 가짜 이미지를 통해 얻은 확률 분포와 원본 이미지를 통해 얻은 확률 분포의 거리 차를 최소로 하는 것이 loss를 최소화하는 것과 같기 때문입니다. WGAN의 value function은 GAN보다 더 잘 작동하는 gradient를 가지는 critic function의 결과를 얻고 generator의 최적화를 더 쉽게 만들어 줍니다.
WGAN은 GAN 모델의 한계(KL, JS 발산)를 개선하기 위해 Wasserstein Distance를 도입했고 이를 구현하기 위해서 Kantrovich-Rubinstein duality를 사용했으며, 이를 사용하기 위해서 critic function은 1-Lipschitz 조건(함수 f의 |f|의 거리는 1보다 작거나 같아야하고 모든 x1, x2에 대해 |f(x1) - f(x2)| = |x1 - x2|를 만족해야 하는 조건이 있습니다. 이를 만족하는 f는 거의 모든 점에서 미분 가능하고 임의의 두 점 사이의 변화율은 1을 넘지 않는 값을 보이게 됩니다)을 만족해야만 했습니다. 이를 만족하기 위해서 WGAN은 weight clipping([-c, c] 안에 critic의 가중치가 놓이도록 clip, WGAN 논문에서는 weight를 [-0.01, 0.01]로 clip)이라는 방법을 사용했습니다. 이와 같은 방식을 사용하면 결국 weight의 분포는 -0.01과 0.01에 몰리게 되는 경향을 보이게 됩니다. 이러한 문제를 해결하기 위해서 WGAN-gp라는 모델이 생성되었습니다.
3. Gradient penalty
이제 Lipschitz constraint를 부과하는 대안의 방법을 제시합니다. 이 전 WGAN은 clipping을 이용했지만 critic의 gradient norm 손실 함수에 페널티 항목을 전달하는 것으로 학습의 최적화를 달성합니다.

만약 위와 같이 점들이 존재한다고 보겠습니다. x_t는 x~p_g, y~P_r로 sampling한 두 점의 내분점 중 하나를 sampling한 점입니다. x~P_g, y~P_r로 sampling한 두 점의 내분점 아무 곳에서나 f(x_t)(f는 최적화된 함수)의 기울기는 1이 됩니다.
최적화된 f의 특성(두 sampling 된 점의 내분점 아무 곳에서나 기울기는 1)을 알게 됐으므로, f_w(critic의 함수)가 그 특성을 갖도록 학습시키면 f에 근사할 수 있게 됩니다. 그 전 WGAN은 근사된 f함수를 찾아가는 방식으로 학습이 진행되었다면 WGAN-gp는 최적의 f를 알고 그 특징을 갖는 유사한 f를 찾아 나가는 방식입니다.
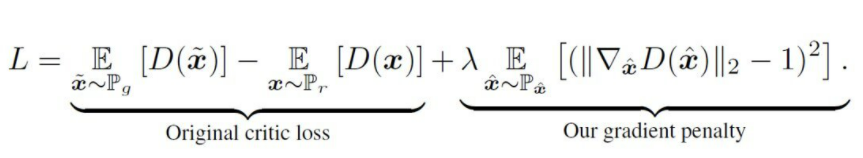
위 식과 같이 critic loss에 regularizer term을 추가하면 됩니다. 위 식에서 λ는 얼마나 penalty의 세기를 줄 것인지를 의미하는 hyperparameter가 됩니다. 기울기가 1이 되지 않는 경우 페널티를 부과하는 식의 loss로 변경했습니다. 즉 이는 WGAN에 gradient penalty를 추가한, WGAN-gp가 됩니다. 이를 통해 ADAM 함수를 사용할 수 있게 되었고 weight clipping할 필요가 사라졌습니다. 이를 통해 weight들이 clip에 몰려있는 분포가 아닌 골고루 퍼져있는 형태를 보입니다.
Experiment

이와 같이 GAN의 종류와 method들에 따라 결과를 볼 수 있습니다. WGAN-gp가 안정적으로 학습되는 모습을 볼 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| GAN 정리(DCGAN, WGAN, CGAN, LSGAN) (0) | 2022.08.15 |
|---|---|
| custom dataset으로 YOLOv5 학습하기(마스크 인식) (0) | 2022.07.02 |
| [논문] Image-to-Image Translation with Conditional Adversarial Networks (0) | 2022.03.31 |
| UNet++ 코드 (0) | 2022.03.30 |
| [논문] Unet++ : A Nested U-Net Architecture for Medical Image Segmentation (0) | 2022.03.28 |



