GAN 종류들에 대해서 간단하게 정리해보겠습니다.
기본적인 GAN 구조는 https://jeongwooyeol0106.tistory.com/13?category=1000515 에 작성했습니다.
Resnet, Unet, GAN 구조
1. ResNet 구조 2015년 ILSVRC에서 우승을 차지한 ResNet은 마이크로소프트에서 개발한 알고리즘입니다. 원 논문명은 "Deep Residual Learning for Image Recognition"입니다. 이 전까지 CNN이 이미지 인식 분야에..
jeongwooyeol0106.tistory.com
DCGAN(Deep Convolutional GAN)
DCGAN(Deep Convolutional GAN)은 CNN 구조로 판별자(D, Discriminator)와 생성자(G, Generator)를 구성한 GAN입니다. 판별자 D는 image를 input으로 받아 binary classification(real or fake)을 수행합니다. 그래서 CNN구조를 이용합니다. 생성자 G의 경우 random vector z를 input으로 받아 image를 생성합니다. 그래서 generator의 경우 deconvolutional network 구조를 이용합니다. 또한 pooling layer를 사용하지 않고 stride 2 이상인 convolution, deconvolution을 이용한 구조입니다.

DCGAN 논문에선, Z-space의 연산이 가능하다고 합니다. 예를 들어, "안경을 쓴 남자"에 해당하는 vector z가 있을 때 z에서 "안경을 쓰지 않은 남자"에 해당하는 vector z2를 빼준 후 "안경을 쓰지 않은 여자"에 해당하는 vector z3를 더해준 결과 z4로 생성한 image는 "안경을 쓴 여자"가 됩니다(하지만 "안경을 쓴 남자"에 해당하는 vector z에서 "안경을 쓰지 않은 남자" vector z2를 빼준 결과로 만들어낸 image가 "안경"인 것은 아닙니다).
Wasserstein GAN(WGAN)
이 전까지 봤던 GAN들은 BCE Loss를 사용했습니다(판별자가 real image인지 fake image인지 분류하기 때문). 하지만 이런 BCE Loss에는 문제가 있습니다.
- Mode Collapse(모드 붕괴)
먼저 Mode가 무엇인지에 대해서 알아보겠습니다. 데이터 분포에서 mode는 관측치가 높은 부분을 의미합니다.
위 그림과 같습니다. 정규분포의 경우 평균이 분포의 mode입니다. mode가 1개인 경우 single mode라 하고 2개인 경우는 bimodal이라 합니다. 2개 이상의 경우는 multimodal, multiple modes라고 합니다. MNIST의 경우는 숫자마다 1개의 mode, 총 10개의 모드가 있는 multiple modes 분포로 나타나게 됩니다.
Model collapse는 GAN에 BCE Loss를 사용할 때 생기는 문제 중 하나로, 생성자가 다양한 이미지를 만들어내지 못하고 비슷한 이미지만 계속해서 생성하는 경우를 뜻합니다. 이는 생성자가 판별자를 속이는 적은 수의 샘플을 찾을 때 일어납니다. 생성자는 계속 비슷한 샘플만 생성하고 다른 샘플은 생성하지 못하게 됩니다. 즉, 생성자가 local minimum에 빠진 것이라 볼 수 있습니다.
- Vanishing Gradient(기울기 소실)
GAN에 적용된 BCE Loss는 위와 같이 표현할 수 있습니다. generator는 BCE를 줄이는 방향으로, discriminator는 BCE를 최대화하는 방향으로 학습하는데 이를 minmaxgame이라 합니다. minmaxgame을 하면서 P_model(x)을 P_data(x)와 유사하게 만듭니다. 이 경우 생성자가 판별자를 학습하는 것보다 더 어렵습니다. 생성자는 이미지를 생성해야 하지만 판별자는 오직 0, 1(fake, real)로 판별만 하기 때문입니다.
학습 초기에는 discriminator의 성능이 그닥 좋지 않기 때문에 큰 문제가 되진 않아 gradient값이 생성자에게 유의미한 정보가 됩니다.
하지만 판별자 D의 학습이 잘 될수록 생성되는 분포 P_model(x)와 P_data(x)를 훨씬 더 잘 구별하게 되고(실제 데이터 분포 P_data(x)는 1에 가까워지고 생성한 분포 P_model(x) 은 0에 가까워집니다) gradient는 거의 0에 가까워집니다. 이 gradient는 생성자에게 유의미한 정보가 아니게 되며 결국 생성자는 학습이 더 이상 진행되지 않고 종료하게 됩니다. 즉 discriminator가 학습 중에 잘 개선될 때 cost function의 flat 한 영역에 위치하게 되고 이는 P_model(x)와 P_data(x)가 너무 달라 discriminator가 real, fake를 너무 잘 구분할 수 있는 것을 의미합니다. 즉 cost function의 flat 한 영역에 위치하게 되어 gradient vanishing이 일어나게 됩니다.
Wasserstein Loss
위에서 말한 GAN은 BCE Loss를 사용해 문제가 있어 이를 해결하기 위해 Wassertein loss를 사용합니다. WGAN에서는 새로운 loss(Wassertein loss)를 사용하는 판별자 D를 C(critic)이라고 표현합니다. G와 C가 서로 경쟁하며 학습이 진행된다 표현합니다.
- Earth Movers' Distance
GAN의 목표는 "P_data(x)와 동일하도록 generator를 학습하기" 입니다. 이는 두 분포 P_data(x)와 P_model(x)의 거리를 줄이는 것으로 볼 수 있습니다. Earth Mover's Distance는 두 분포가 얼마나 다른지를 나타내는 수치입니다. P_model(x)를 P_data(x)와 동일하게 만들기 위해서 얼마나 이동해야 하는지 거리와 양을 나타내는 수치입니다.
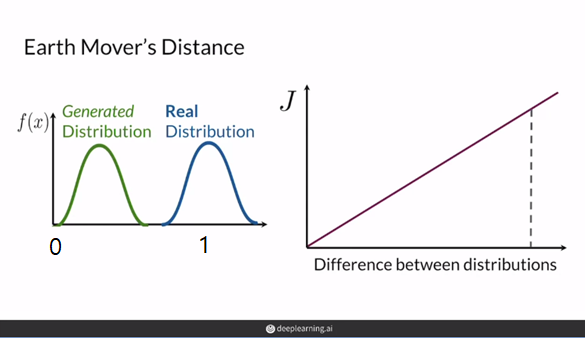
BCE Loss의 문제는 판별자 D가 sigmoid를 사용해 0, 1(fake, real)의 확률 값을 출력으로 하여, 판별자가 좋아짐에 따라 두 분포의 차이가 심해져(P_data(x)는 1에 가까워지고 P_model(x)는 0에 가까워집니다) cost fuction의 gradient가 점점 0이 되어 gradient vanishing 문제가 생긴다는 것이였습니다. 하지만 Earth Mover's Distance의 결과는 0, 1로 표현되는 한계를 극복합니다. 두 분포가 얼마나 멀리 떨어져 있든 상관없이 의미 있는 gradient를 전달해 gradient vanishing 문제를 해결 할 수 있습니다. 또한 Model collapse가 일어날 가능성도 감소시킵니다.
두 확률 분포간의 거리를 나타내는 지표의 종류는 여러 가지가 있습니다. 예를 들어 Total Variation(TV), Kullback-Leibler(KL) Divergence, Jensen-Shannon(JS) Divergence 등이 있습니다. 이 중 Earth Mover's Distance를 사용하는 이유가 있습니다. Earth Mover's Distance의 경우 추정하는 모수에 상관없이 일정한 수식을 가지고 있습니다. 다른 경우 모수에 따라 거리가 달라질 뿐만 아니라 그 값이 상수 또는 무한대의 값을 가지게 됩니다. TV, KL, JS는 두 분포가 서로 겹치는 경우에 0, 겹치지 않는 경우에는 무한대 또는 상수로 극단적인 값을 갖습니다. TV, KL, JS를 사용한다면 gradient가 제대로 전달되지 않아 학습이 어려워집니다.

이제 Earth Mover's Distance를 이용한 Wasserstein Loss를 보겠습니다. Kantorovich-Rubinstein Duality Theorem을 이용해 Earth Mover's Distance를 위와 같이 표현할 수 있습니다.
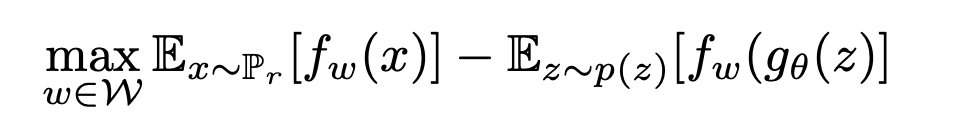
학습을 위해 parameter w가 추가된 f로 수식을 변경하고, g(θ)에 대한 식으로 변경하면 위와 같습니다.

변경한 식에서 f_w를 C(critic or D)로 변경한다면 GAN Loss와 비슷한 형태가 됩니다. 이와 같은 형태로 wasserstein Loss 식을 작성할 수 있습니다.
Earth Mover's Distance의 출력이 [0, 1]로 제한되지 않아 loss에 사용하는 것이 적절하다는 것을 알아보았는데, 일반적으로 신경망에서 너무 큰 숫자는 학습에 좋지 않기 때문에 Lipshitz 제약이라는 제약조건을 걸어줍니다. 제약은 critic C가 1-lipshitz continuous function이어야 한다는 조건입니다.

식으로 표현하면 위와 같습니다. |D(x_1) - D(x_2)|는 C의 예측 간의 차이의 절대값이고, x1 - x2는 두 이미지의 픽셀의 평균값 차이의 절댓값입니다.
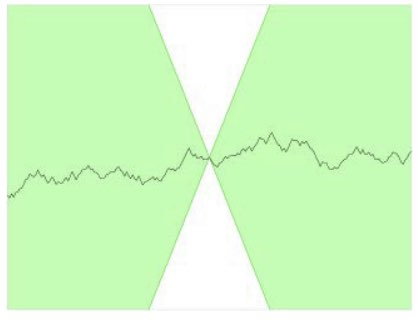
위 식을 만족하는 어느 점에 원뿔을 놓더라도 하얀색 원뿔에 들어가는 영역이 없습니다. 즉 위 식(제약)을 만족하는 직선은 어느 지점에서나 상승하거나 하강하는 비율이 한정되어 있다는 뜻입니다.
Weight Clipping(가중치 클리핑)을 통해 lipshitz 제약을 만족하도록 할 수 있습니다. WGAN 논문에서는 critic C의 가중치를 [-0.01, 0.01] 안에 놓이도록 weight clipping을 이용해 제약을 부과했습니다.
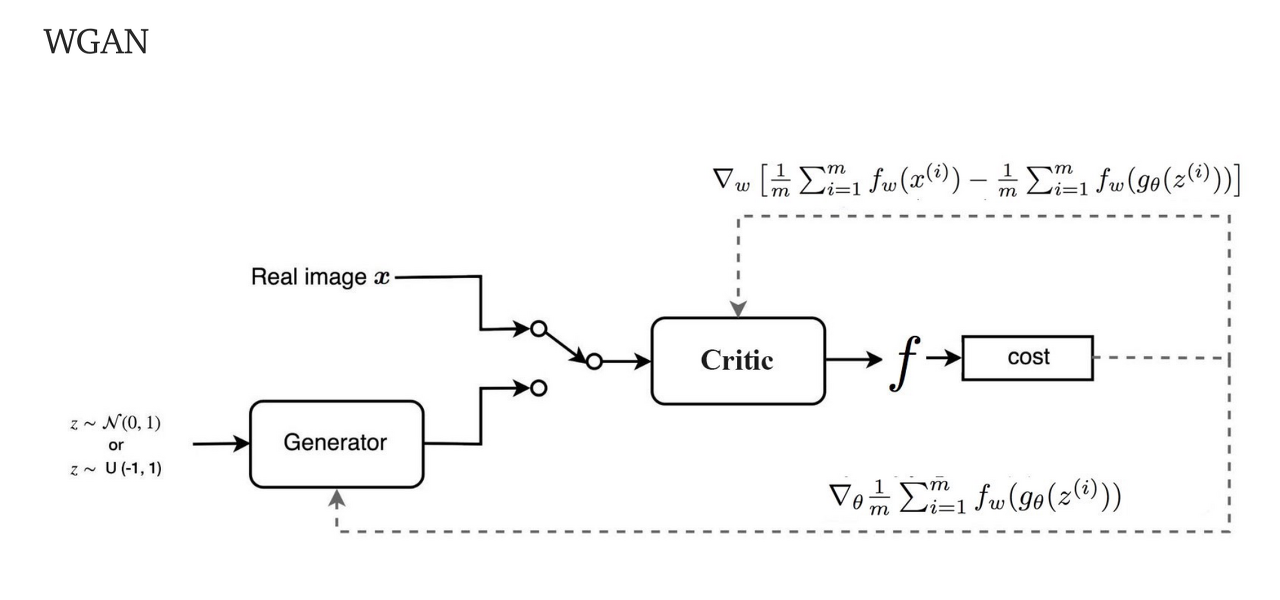
WGAN의 구조는 위와 같습니다.
WGAN에 gradient penalty를 적용한 WGAN-GP도 존재하는데 이에 대한 설명은 해당 링크에 있습니다. https://jeongwooyeol0106.tistory.com/33?category=1000515
[논문] Improved Training of Wasserstein GANs(WGAN-gp)
https://arxiv.org/pdf/1704.00028.pdf 해당 논문을 보고 작성했습니다. Abstract GAN(Generative Adversarial Network)는 powerful 한 모델이지만 학습 불안정성을 보입니다. 최근 제시된 Wasserstein GAN(WGAN)..
jeongwooyeol0106.tistory.com
Conditional GAN(CGAN)
Conditional GAN(CGAN)은 생성자와 판별자가 훈련하는 동안 추가 정보를 사용해 조건이 붙는 GAN입니다. CGAN은 우리가 원하는 class가 담긴 데이터를 생성할 수 있습니다.
| Condtional GAN | Unconditional GAN |
| Example from the classes you want | Examples from random classes |
| Training dataset needs to be labeled | Training dataset doesn't need to be labeled |
위와 같이 Conditional GAN과 Uconditional GAN의 차이가 있습니다. CGAN은 생성자와 판별자 모두 학습할 때 label을 사용합니다.
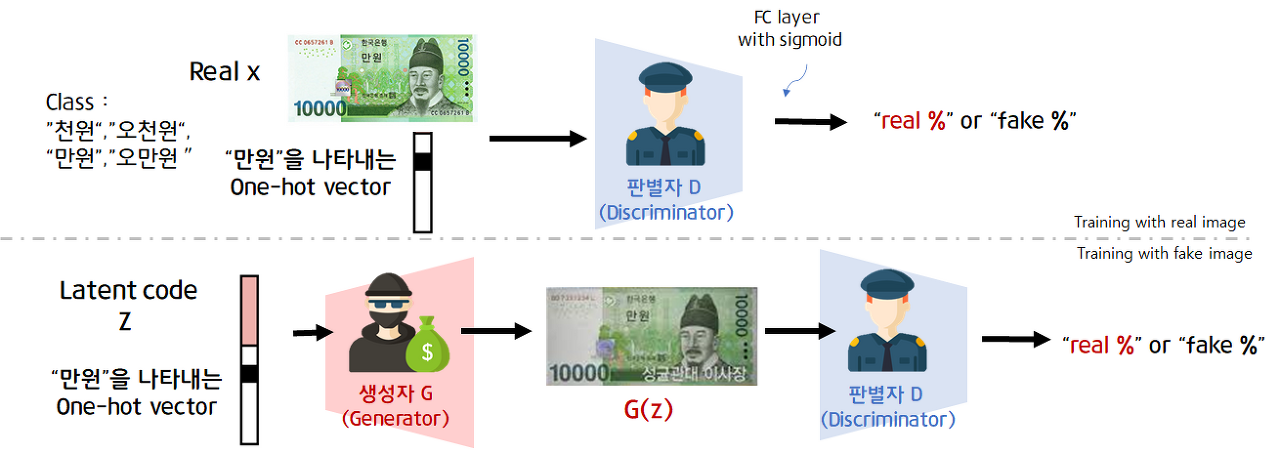
위와 같은 그림입니다. 생성자 G에게 input으로 random vector z와 label이 주어집니다. 생성자 G의 output은 label에 맞게 생성된 sample image입니다(G(z, y)). generator의 목표는 label에 맞는 진짜 같은 가짜 sample image를 만드는 것이라고 보면 됩니다. 판별자 D의 경우 input으로 train dataset의 x, y(image, label)과 함께 G가 만든 sample image와 label이 들어옵니다. output은 input으로 들어온 sample이 진짜이고 sample-label 쌍이 맞는지 나타내는 하나의 확률입니다. discriminator의 목표는 가짜 image, label 쌍과 진짜 image, label 쌍을 구별하는 것입니다.

위 그림은 discriminator에게 들어가는 input에 대한 모습입니다. 판별자에는 label(one-hot vector)와 image가 input으로 들어가고 label vector를 embedding layer에 통과시켜 이미지와 동일한 사이즈로 만들고 concat 합니다. 이렇게 one-hot vector인 label과 image가 한 번에 input으로 들어옵니다.
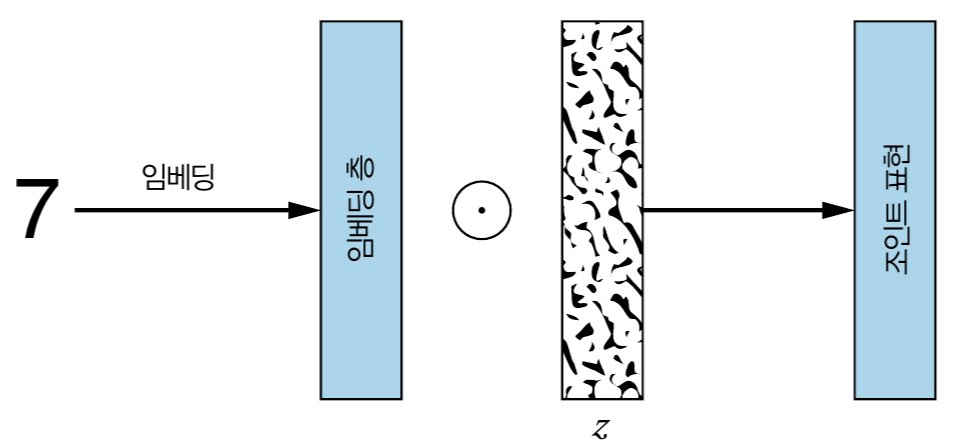
위 그림은 generator에게 들어가는 input에 대한 모습입니다. 생성자의 input으로 들어가는 random noise Z는 생성되는 이미지의 다양성이 보장되도록 합니다. random vector z와 label이 동시에 들어가는데, 그냥 vector concat형식이 아니라 z의 dimension에 맞춰 label vector의 크기를 변환해 원소곱을 한 값이 들어가게 됩니다.
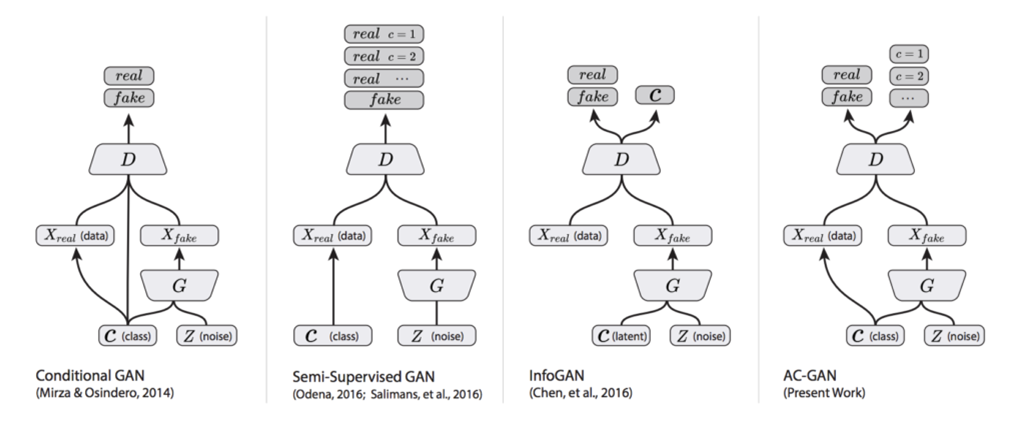
위 그림은 최종 CGAN의 구조와 다양한 종류의 GAN들을 보여줍니다.
LSGAN
original GAN의 경우 BCE Loss를 사용해 gradient vanishing 문제가 생긴다고 했습니다. 이를 개선하기 위해 LSGAN이 만들어졌습니다.
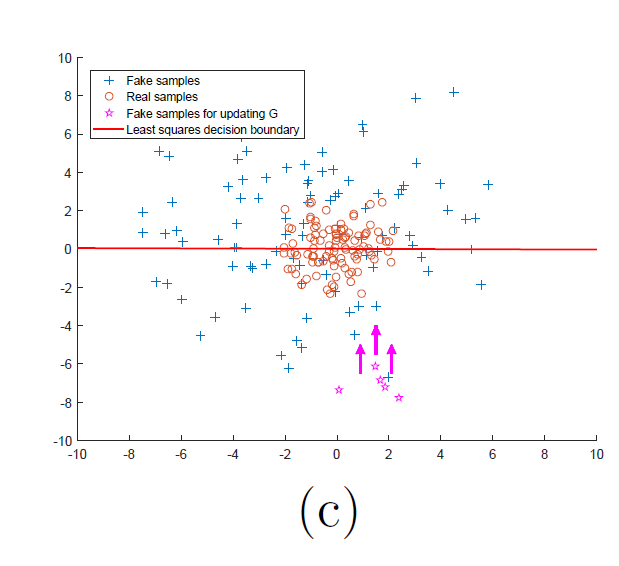
위와 같은 그림으로 LSGAN은 멀리 떨어진 sample들을 거리에 penalty를 부과해 경계 근처로 끌어올 수 있다면 fake image는 실제에 거의 근접하게 될 것이라는 아이디어에서 출발합니다.
그래서 discriminator D를 위한 loss function을 least squares로 대체하면, 경계로부터 먼 sample들은 penalty를 받아 경계 근처로 올라오게 됩니다.
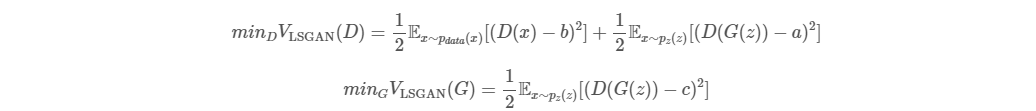
LSGAN의 목적 함수는 위와 같이 표현됩니다. 위 식에서 a는 fake data label, b는 real data label, c는 D가 fake sample을 믿도록 G가 원하는 값으로 정의합니다.
이와 같이 함수를 바꾸면 장점 2가지가 존재합니다.
- original GAN과는 달리 decision boundary에서 멀리 떨어진 sample을 오랫동안 가만히 두지 않고, 설령 맞는 영역에 위치한다고 해도 이에 penalty를 줍니다. 이는 G가 이미지를 생성할 때 decision boundary에 최대한 가까운, 즉 실제 이미지에 가깝게 생성하게 됩니다.
- 멀리 떨어진 sample일수록 square 함수에 의해 penalty를 더욱 크게 받습니다. 따라서 gradient vanishing문제가 많이 해소되고 학습이 안정적이게 됩니다.
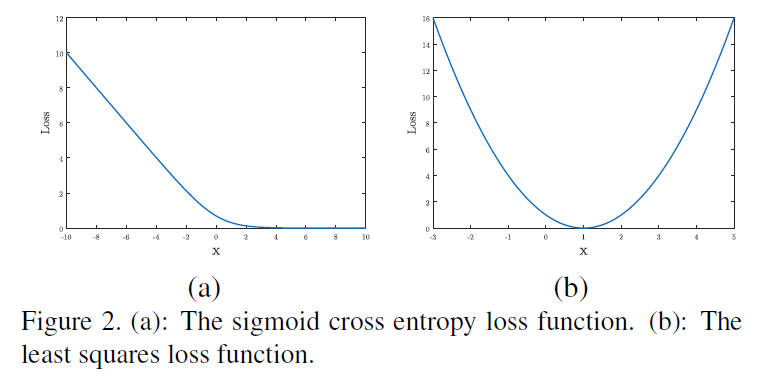
위 그래프를 보면 2번 장점이 잘 이해됩니다. least squares loss의 경우 최솟값이 한 점에서 존재하므로 좀 더 안정적으로 학습이 진행됩니다.
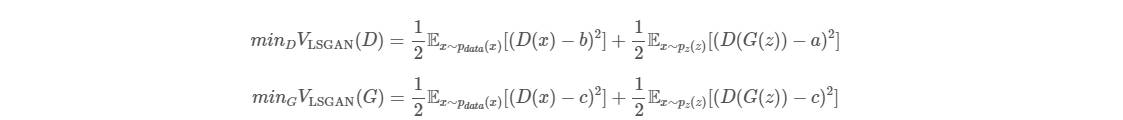
위에서 봤던 식을 위와 같이 확장 가능합니다. V_LSGAN(G)에 (D(x) - c)^2 만 추가한 모습인데 사실 V_LSGAN(G)에서는 G에 대한 문제이기 때문에 위와 같은 확장은 문제가 되지 않습니다.
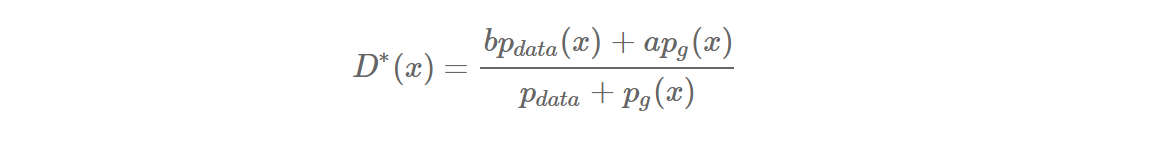
generator G가 fix 된 상태에서 D의 최적 값(optimal D*)은 위와 같습니다.
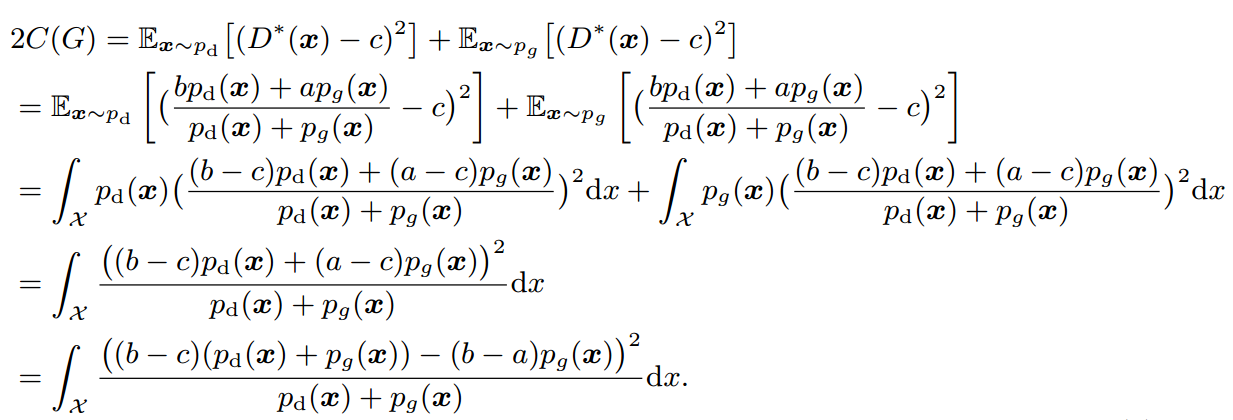
이제 위에서 소개했던 확장식을 위와 같이 변형할 수 있습니다(p_data는 p_d로 표현했습니다). 이렇게 나온 식에 b - c = 1, b - a = 2라는 조건을 주면
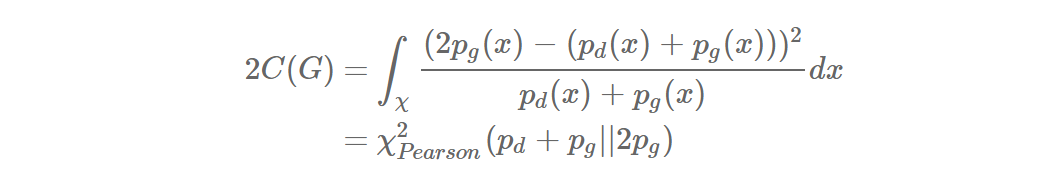
위와 같이 됩니다. 여기서 χ^2_Pearson은 Pearson χ^2 divergence라고 합니다. 즉, a, b, c가 위 조건을 만족할 때, LSGAN이 하는 일은 p_g + p_d와 2p_g 사이의 Pearson χ^2 divergence를 최소화하는 것과 동치라는 말입니다. p_g = p_d일 때, 즉 generator가 만들어내는 sample의 distribution이 data distribution과 같을 때 divergence가 최소가 되어 0이므로 궁극적으로 원래 GAN의 목적과 비슷하다는 것을 보여줍니다.
'연구실 공부' 카테고리의 다른 글
| 성능 평가 지표(정확도(accuracy), 재현율(recall), 정밀도(precision), F1-score) (0) | 2022.09.07 |
|---|---|
| [Keras] Dogs vs Cats classification (0) | 2022.08.23 |
| custom dataset으로 YOLOv5 학습하기(마스크 인식) (0) | 2022.07.02 |
| [논문] Improved Training of Wasserstein GANs(WGAN-gp) (0) | 2022.04.04 |
| [논문] Image-to-Image Translation with Conditional Adversarial Networks (0) | 2022.03.31 |


