이번 강의는 CNN architecture에 대한 내용입니다. 주로 대회에서 우승한 model들을 볼 예정입니다.

위에 나온 모델들을 볼 예정입니다.
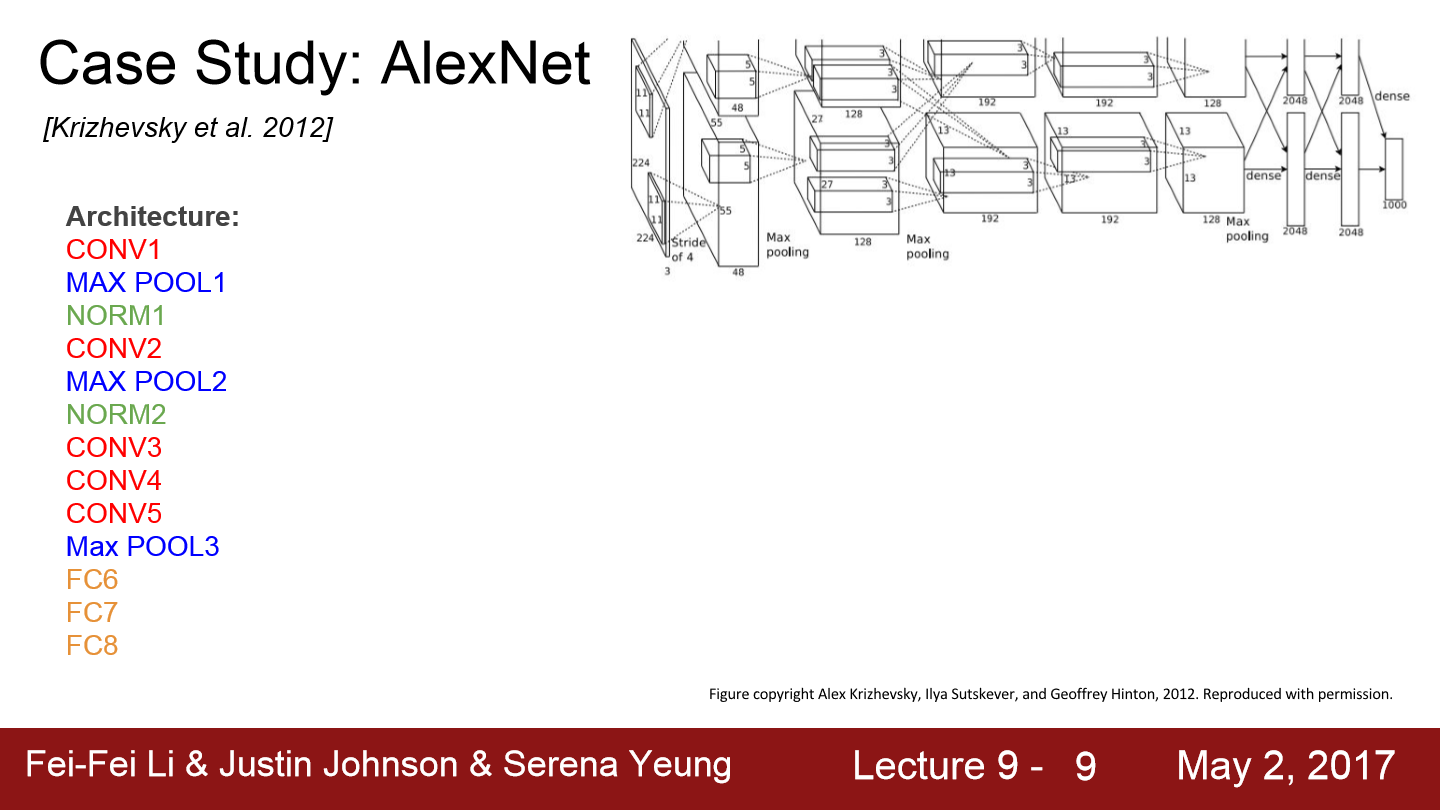
위 모델은 AlexNet입니다. 이는 최초의 Large scale CNN입니다. ImageNet Classification task를 아주 잘 수행합니다. AlexNet은 2012년에 등장해서 기존의 non-deep learning model들을 능가하는 놀라운 성능을 보여줍니다. AlexNet은 기본적으로 conv->pool->normalization 구조가 두 번 반복됩니다. 그리고 conv layer가 조금 더 붙고 그 뒤에 pooling layer가 있고 마지막에 fc-layer가 몇 개 붙습니다.

만약 input이 227x227x3인 이미지가 들어가고 conv1이 96 11x11 filter에 stride 4라면 output의 size는??
(227-11)/4 + 1 = 55이고 channel이 96여서 55x55x96가 됩니다.

최종 parameter의 수는 filter를 따라갑니다. 11x11x96에 input의 depth가 3이므로 11x11x96x3가 됩니다.

위 내용을 보면 각 layer마다 크기를 볼 수 있고 model의 detail도 볼 수 있습니다. ReLU를 사용했고 Norm layer도 사용했는데 local response normalization layer를 이용했습니다. 이는 채널 간 normalization을 위해서 사용하는 layer인데 성능이 좋지 않아 요즘엔 잘 사용하지 않습니다. heavy data augmentation도 이용했습니다. flipping, jittering, color norm 등을 적용했습니다. SGD momentum을 사용했으며 learning rate도 학습 결과에 따라 줄여나갔고 weight decay도 사용했습니다.

파란색 박스를 보면 55x55x96이 2개로 나눠진 것을 볼 수 있습니다. 이 부분은 기존 방식과는 다른 모습입니다. model이 두 개로 나눠져 서로 교차하는 모습입니다. 이 모델을 만들 때 GPU는 3GB 메모리밖에 존재하지 않아서 network를 GPU에 분산시켜서 넣었습니다. 그래서 각 GPU가 모델의 뉴런과 feature map을 반반씩 나눠서 가져갔기 때문에 저런 모습을 보입니다.

Conv1, 2, 4, 5는 전체 96 feature map을 볼 수 없고 같은 GPU 내에 있는 feature map만 볼 수 있으며 48개의 feature map만 볼 수 있습니다.

Conv3, fc6, 7, 8을 보면 이 layer들은 전체 feature map과 연결되어 있습니다. 이 layer에서는 GPU 간의 통신을 하기 때문에 전체 depth를 전부 가져올 수 있습니다.

VGGNet의 등장으로 layer가 더 깊어졌습니다. VGGNet은 16 / 19 layer를 가지고 filter의 크기는 항상 3x3입니다. 이는 out pixel을 포함할 수 있는 가장 작은 filter의 크기입니다. 이렇게 작은 filter를 유지해주고 주기적으로 pooling을 수행하면서 전체 network를 구성하게 됩니다.

왜 작은 filter를 쓰는가?? 우선 filter의 크기가 작으면 parameter의 수가 더 적습니다. 따라서 큰 filter에 비해 layer를 좀 더 많이 쌓을 수 있습니다. 즉 작은 filter를 사용하면 network의 depth를 더 키울 수 있습니다.
그럼 3x3 conv stride = 1인 layer 3개를 이용했을 때 같은 효과를 보이는 filter는??
receptive field는 filter가 한번에 볼 수 있는 입력의 spatial area입니다. 우선 첫 번째 layer의 receptive field는 3x3입니다. 두 번째 layer의 경우는 각 뉴런이 첫 번째 layer 출력의 3x3을 볼 것이고 중복되는 영역이 있기 때문에 5x5만큼 보게 될 것입니다. 마지막 세 번째 layer를 거치면 input의 7x7만큼 보게 될 것이고 결국 3x3 layer 3개는 7x7 layer 1개와 같은 결과를 보입니다.

이번에는 두 경우의 parameter수를 확인해보겠습니다. 3x3 layer 3층 구조는 3x3xdepthxdepth가 됩니다. 7x7 layer의 경우는 7x7xdepthxdepth가 됩니다. 즉 3x3 layer 3층 구조는 같은 일을 하지만 더 적은 parameter를 사용한다는 것을 의미하고 더 깊은 layer를 쌓을 수 있습니다. 더 깊게 쌓으므로써 non-linearity를 더 추가할 수 있습니다.

이번에는 VGG16의 각 layer마다 사용하는 memory를 보여줍니다. 보통 초기 layer에서 많은 메모리를 사용합니다. spatial dimension이 큰 곳들이 메모리를 더 많이 사용합니다. 마지막 layer은 많은 parameter를 사용합니다. 그래서 최근에는 FC layer를 아예 없애버리기도 합니다.

19가 16보다 좀 더 좋은 성능을 보이지만 그만큼 memory도 더 사용됩니다. 그래서 보통 16을 많이 사용합니다. VGG 에서 FC7은 아주 좋은 feature representation을 가지고 있습니다. 다른 데이터에서도 feature 추출이 잘되며 다른 task에서도 일반화 능력이 뛰어납니다. 위에 VGGNet에 detail 한 내용들이 나와있습니다.

이번에는 GoogLeNet에 대한 설명입니다. 이들은 높은 계산량을 효율적으로 수행하도록 network를 디자인했습니다. inception module을 사용하는 방식으로 디자인했습니다. 그리고 FC layer를 사용하지 않습니다. 그래서 전체 parameter 수가 5M정도 됩니다.
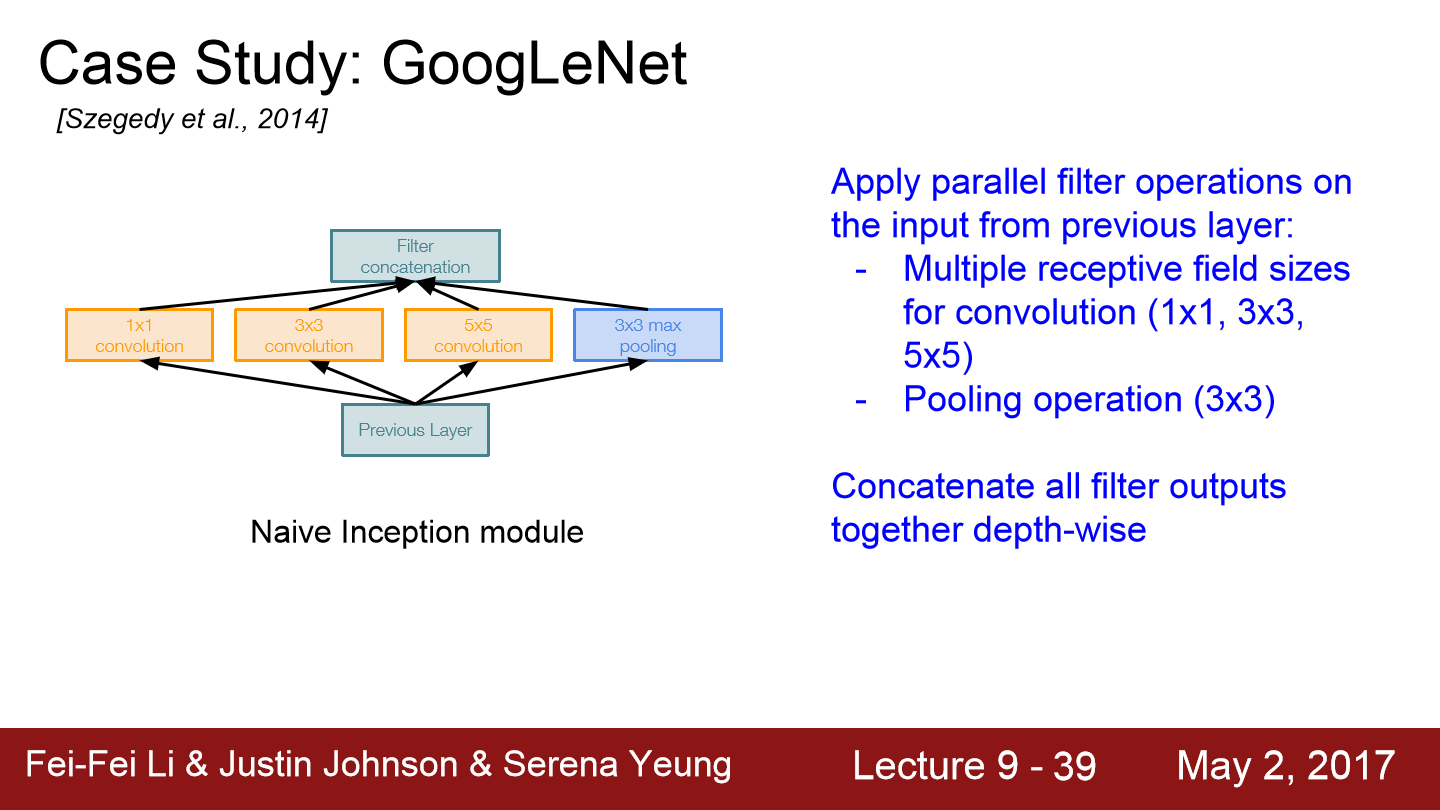
inception module 내부에는 동일한 input을 받는 서로 다른 다양한 filter들이 병렬로 존재합니다. 그 filter들의 output을 모두 depth방향으로 concat합니다. 이렇게 합치면 하나의 tensor로 출력이 결정되고 하나의 출력을 다음 layer의 input으로 들어갑니다.

이런 구조에는 문제가 있습니다. 계산 비용이 많이 든다는 점입니다. 예제를 보면 128개의 1x1 filter가 있습니다. 192개의 3x3 filter가 있고 96개의 5x5 filter가 있습니다. stride와 padding을 잘 조절해 입/출력 간의 spatial dimension을 유지시켜줍니다(이 경우 28x28).
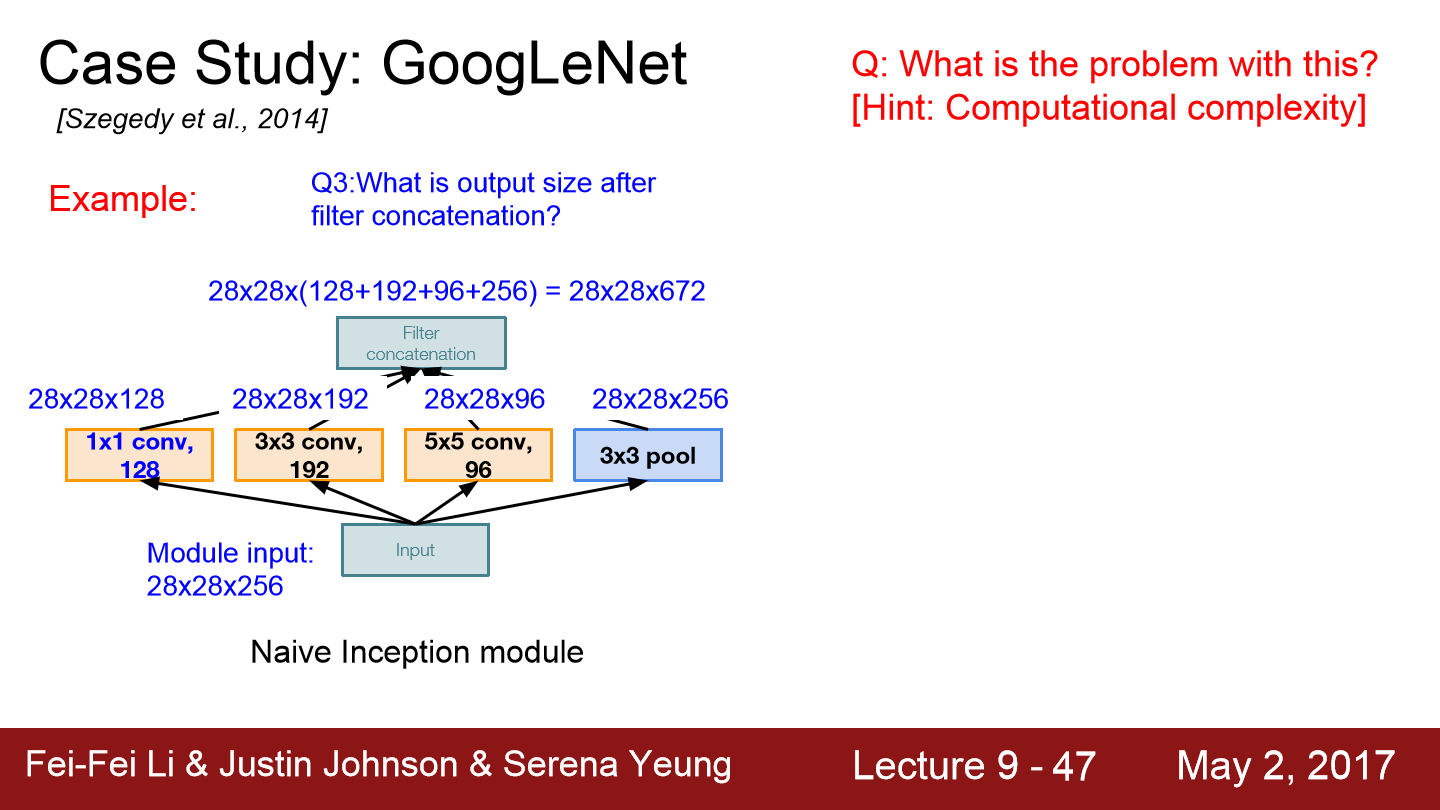
각 filter에 연산을 하면 위와 같이 28x28x672라는 결과가 나옵니다. inception module의 input은 28x28x256이었으나 output은 28x28x672가 됩니다. spatial dimension은 변하지 않지만 depth가 엄청나게 불었습니다.
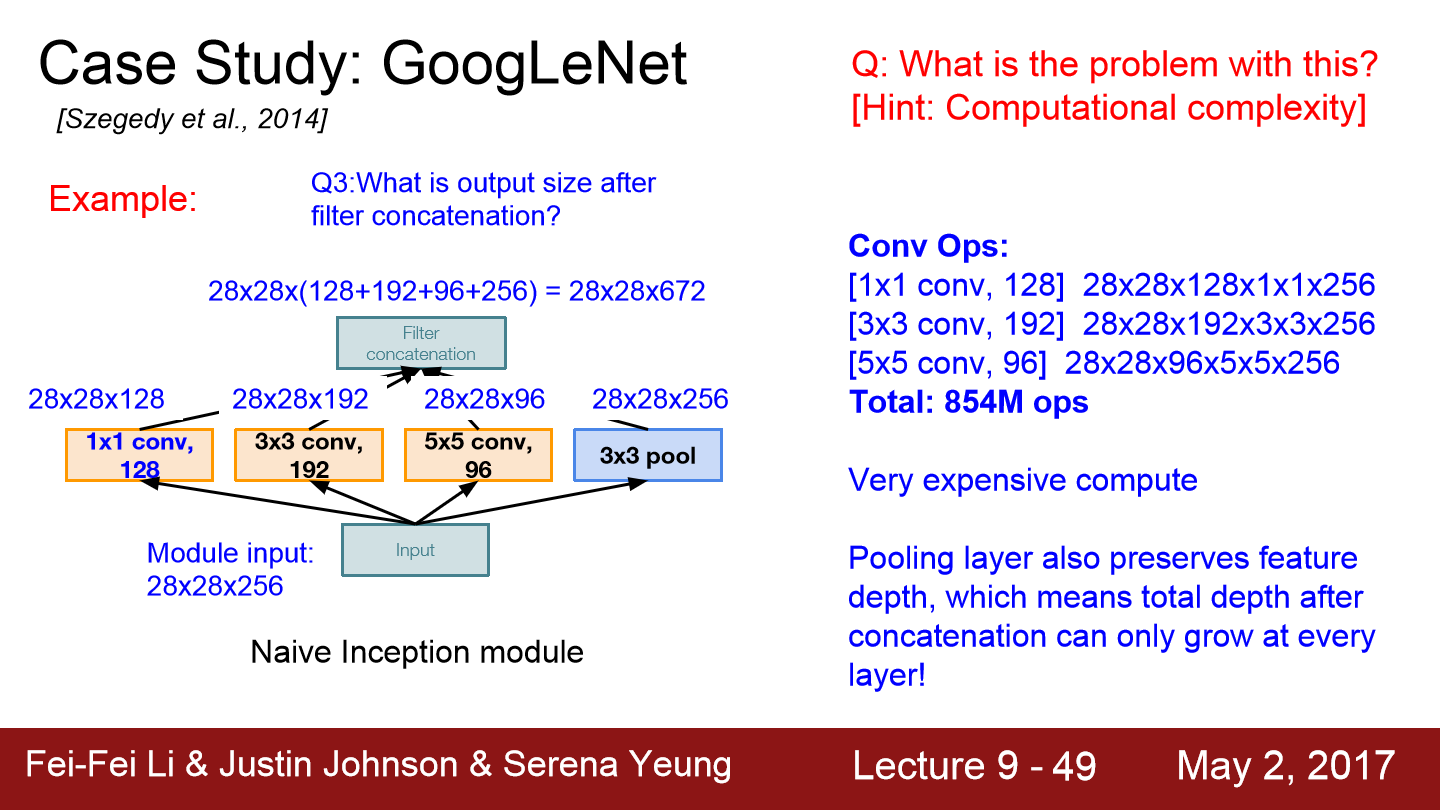
이제 연산량을 보겠습니다. 각 filter에 pixel마다 내적을 하는데 총 연산량의 합은 854M가 됩니다. 이러한 Inception module은 연산 비용이 너무 많이 듭니다.

그래서 이를 해결하기 위해 bottleneck layer를 추가합니다.
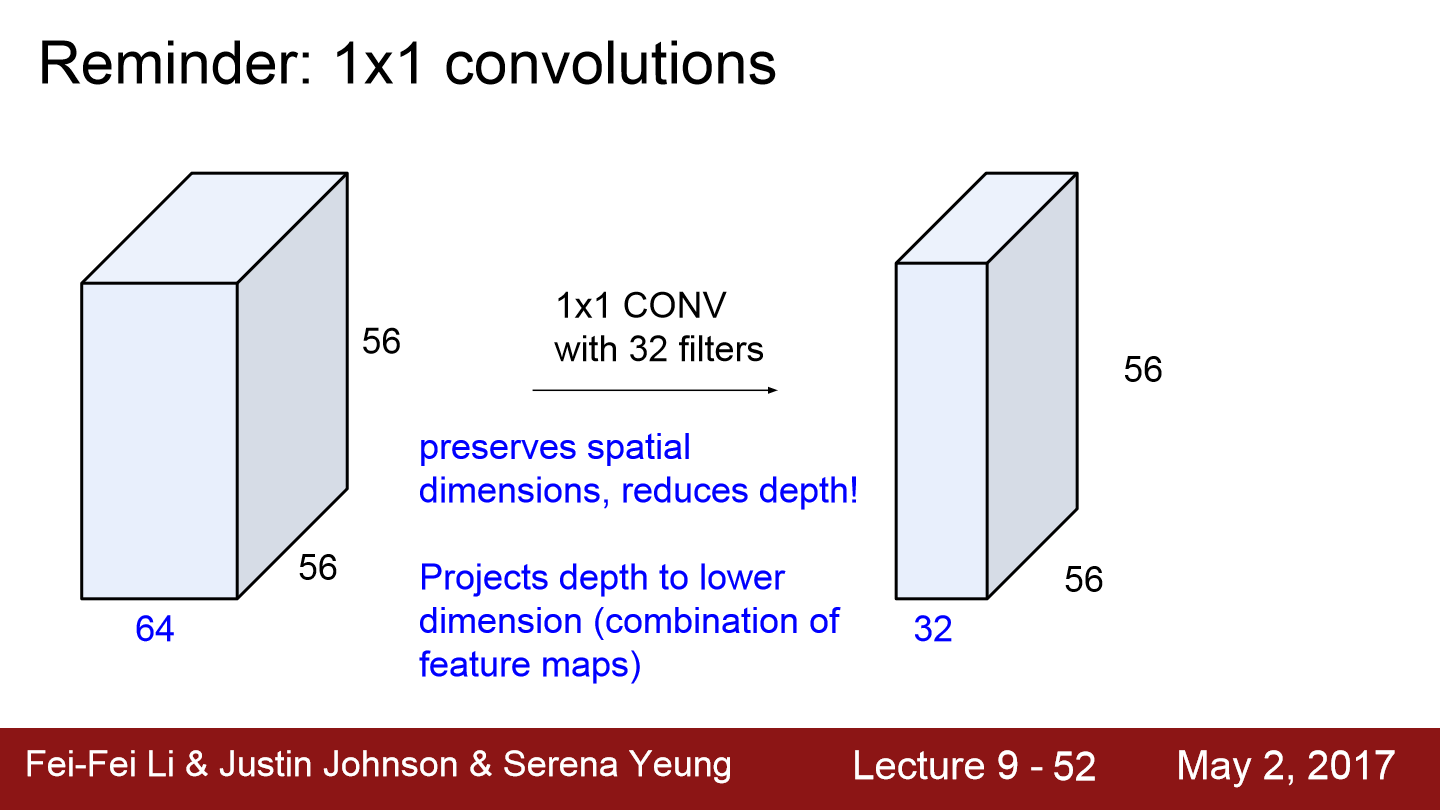
위와 같이 1x1 conv 32filter를 적용하면 depth가 줄어드는 것을 볼 수 있습니다. 이렇게 depth의 차원을 줄여 연산량을 줄일 수 있습니다.

이렇게 1x1 conv bottleneck layer를 추가합니다.

이렇게 bottleneck을 적용하면 358M으로 계산량이 상당히 줄어든 모습을 볼 수 있습니다.

위 모습은 GoogLeNet의 전체모습입니다. inception module들이 쌓여있는데 서로 조금씩 다른 모습입니다. GoogLeNet은 계산량이 많은 FC Layer를 대부분 걷어냈고 parameter가 줄어들어도 model이 잘 동작합니다.

위 그래프에 파란색 상자를 보면 추가적인 두 줄기가 있는데 이들은 보조 분류기(auxiliary classifier)입니다. 단지 mini network이고 average pooling과 1x1 conv가 있고 FC-layer 몇 개 붙어있습니다. 그리고 softmax로 1000개의 ImageNet class를 구분합니다. 이곳에서도 ImageNet trainset loss를 계산하는데 여기서도 Loss를 계산하는 이유는 network가 깊게 구현되어 있기 때문입니다. 이러한 보조 분류기를 중간 레이어에 달아주면 추가적인 gradient를 얻을 수 있고 이를 통해 중간 layer의 학습을 도울 수 있습니다.

이번에는 ResNet입니다. ResNet의 등장으로 layer가 152로 매우 깊어졌습니다. ResNet은 residual connections이라는 방법을 사용합니다. ResNet 하나로 ImageNet과 COCO classificaiton/detection 대회를 다 수상했습니다.
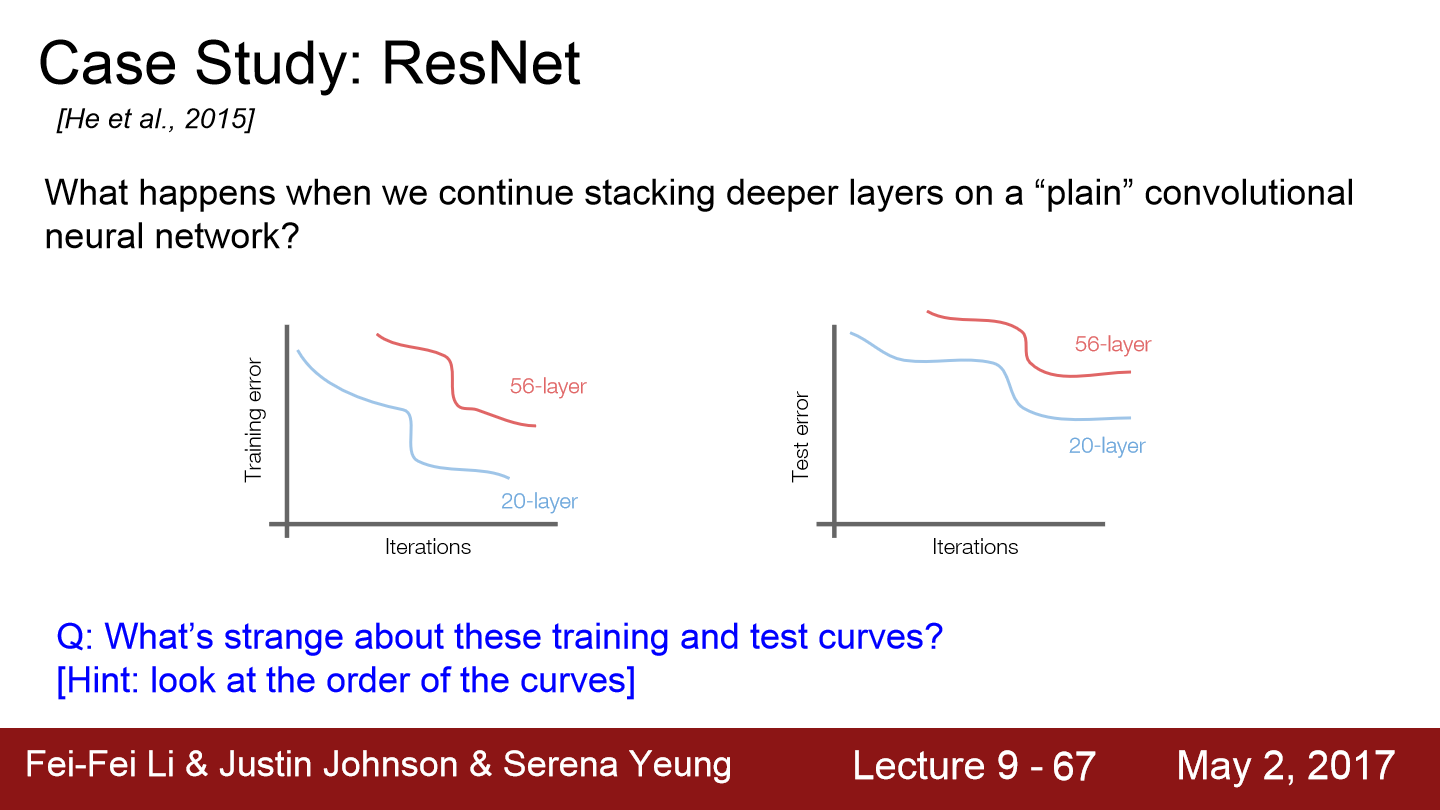
우선 일반적인 CNN 구조에서 층이 깊어진다면 성능이 어떻게 되는지 생각해보겠습니다. 일반적으로 layer가 깊어지면 test에서는 성능이 안좋을지라도 overfitting이 되어 train에서의 성능은 얕은 층보다는 좋을 것이라고 예측할 수 있습니다. 하지만 위 그래프를 보면 아닌 것을 알 수 있습니다. 이를 통해 layer가 깊은 모델이 test 성능이 안 나오는 이유가 overfitting이 아니라고 ResNet 저자들은 생각을 했습니다. 그래서 이 저자들은 deep 한 모델 학습 시 optimization 문제가 생긴다고 생각을 했습니다.

이 저자들은 "모델이 더 깊다면 적어도 얕은 모델만큼의 성능은 나와야된다"라고 생각을 했습니다. 그래서 이런 생각으로 direct mapping이 아닌 residual mapping 하도록 block을 쌓는 구조를 만들었습니다. input x는 이전 layer에서 들어온 값이고 layer가 H(x)를 학습하기보다는 H(x) - x를 학습할 수 있도록 만들어줍니다. 이를 위해서 skip connection을 도입하게 되는데 이는 오른쪽 고리 모양의 connection입니다. skip connection은 가중치가 없으며 input identity mapping으로 그대로 보냅니다. 이러면 layer는 x의 변화량만 학습하게 됩니다. 최종 출력은 x + 변화량이 됩니다.
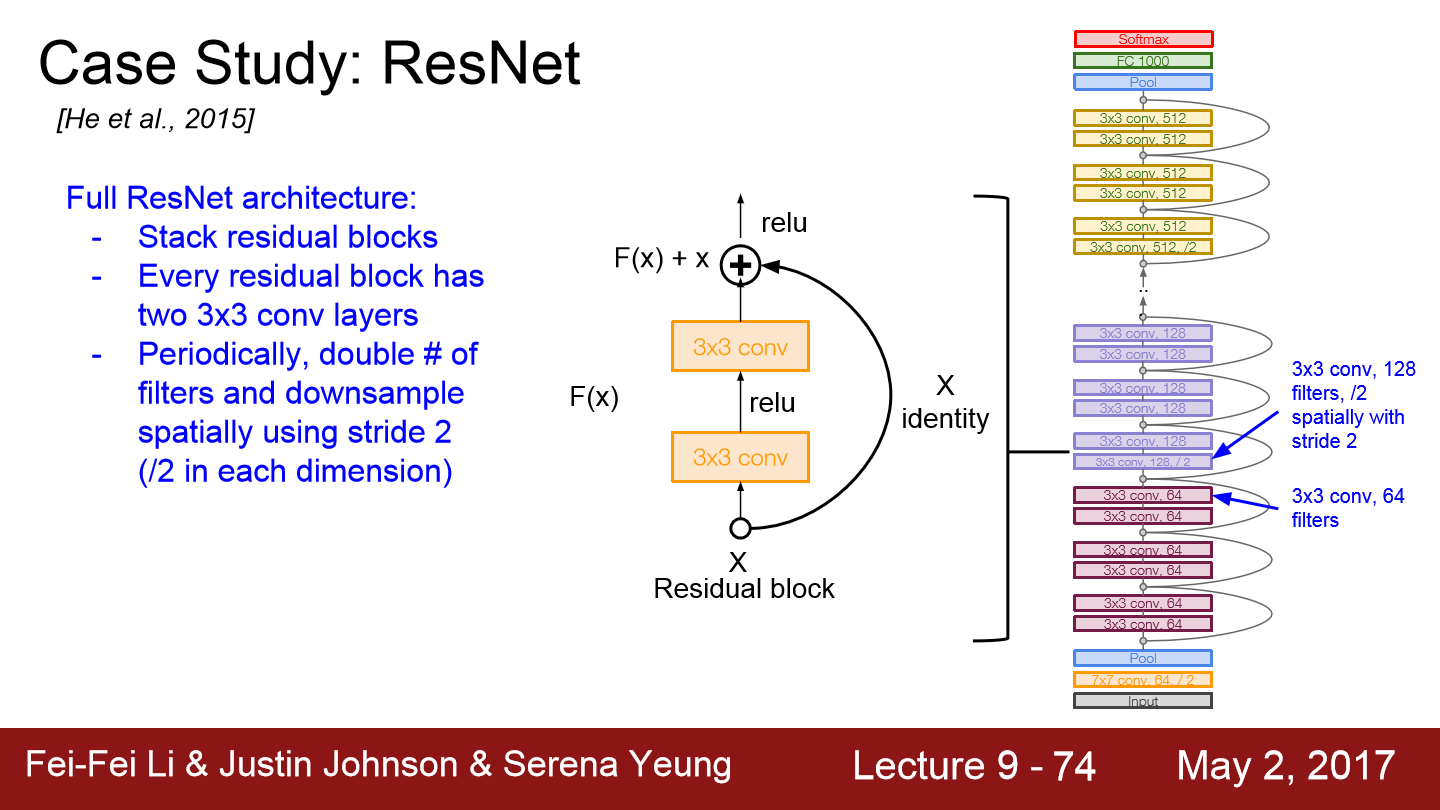
하나의 residual block은 두 개의 3x3 conv layer로 이루어져 있고 이러한 block들 사이에 filter를 2배씩 늘리고 stride 2를 이용해 downsampling합니다.
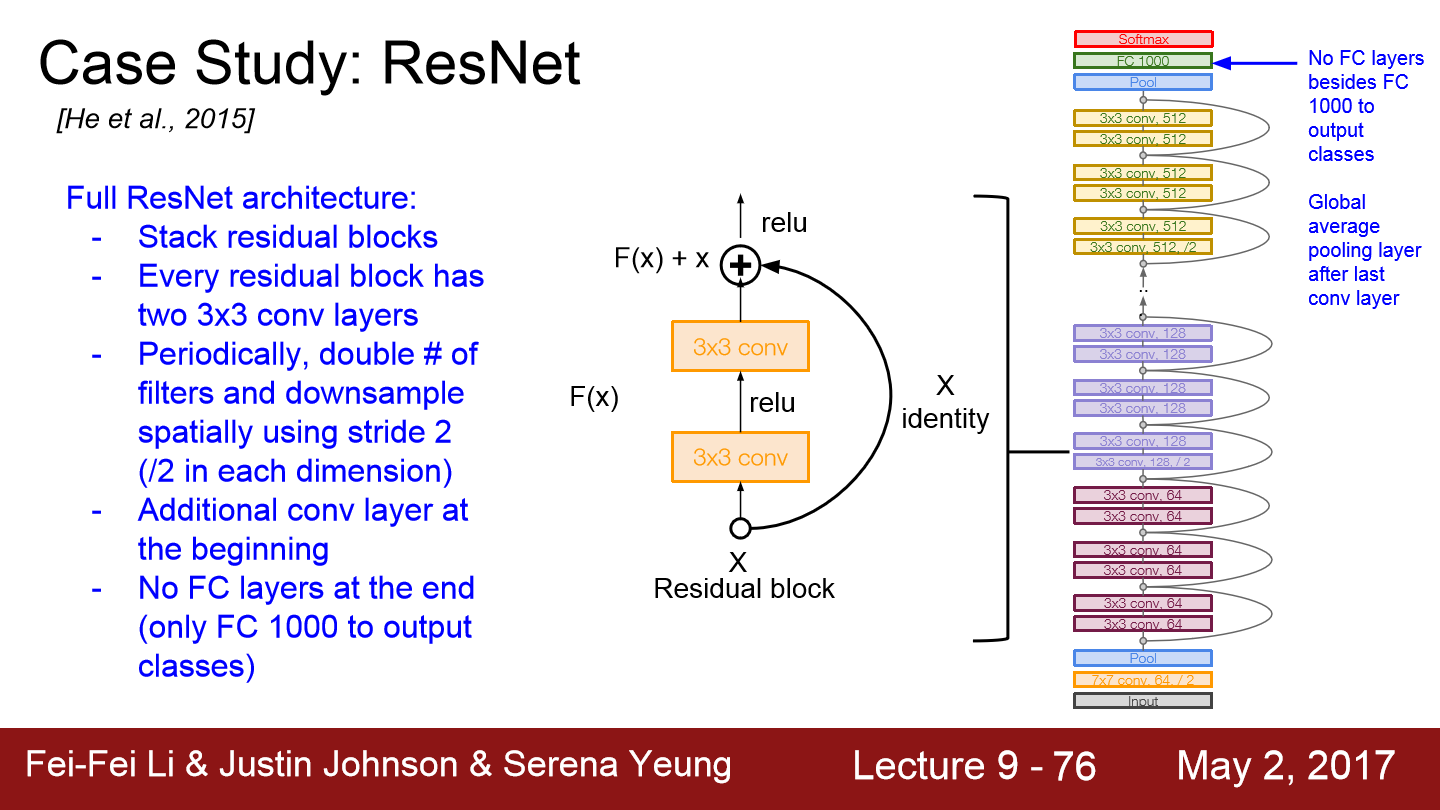
network 초반에는 추가적으로 conv layer가 붙고 network 끝에는 FC-layer가 없습니다. 대신에 global average pooling layer를 사용합니다. GAP은 하나의 map 전체를 average pooling 하는 것입니다. 그리고 마지막에는 1000개의 class 분류를 위한 노드가 붙습니다.
ResNet은 model depth가 50 이상일 때 bottleneck layer를 도입합니다. bottleneck layer는 1x1 conv를 도입해 초기 필터의 depth를 줄여줍니다.
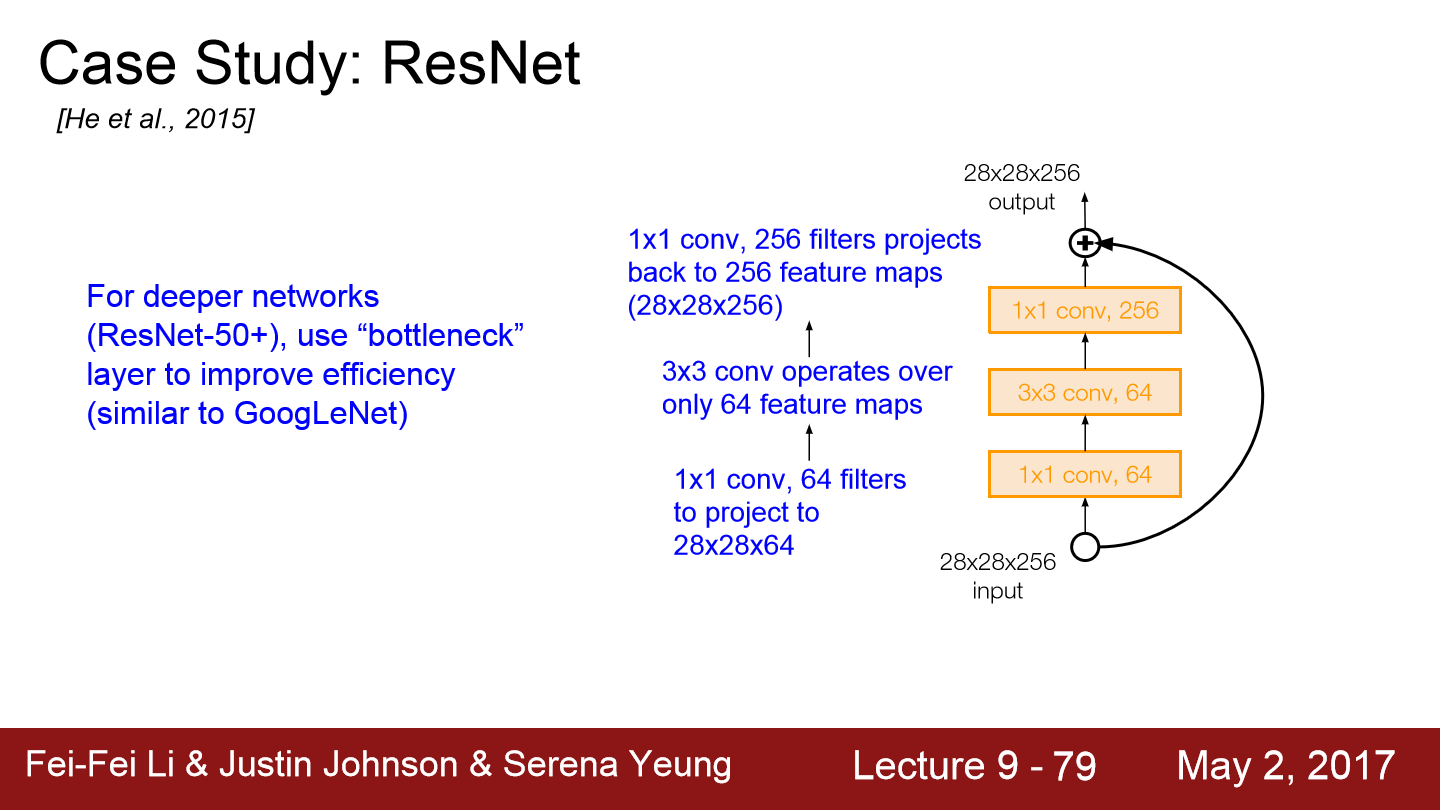
이와 같이 input이 28x28x256일 때, 1x1 conv를 적용해 depth를 줄여 28x28x64로 만듭니다. 이로 인해 3x3 conv계산량이 줄어듭니다. 마지막에 다시 1x1 conv를 추가해 depth를 다시 256으로 늘립니다.

ResNet의 detail 한 내용이 위에 작성되어 있습니다.
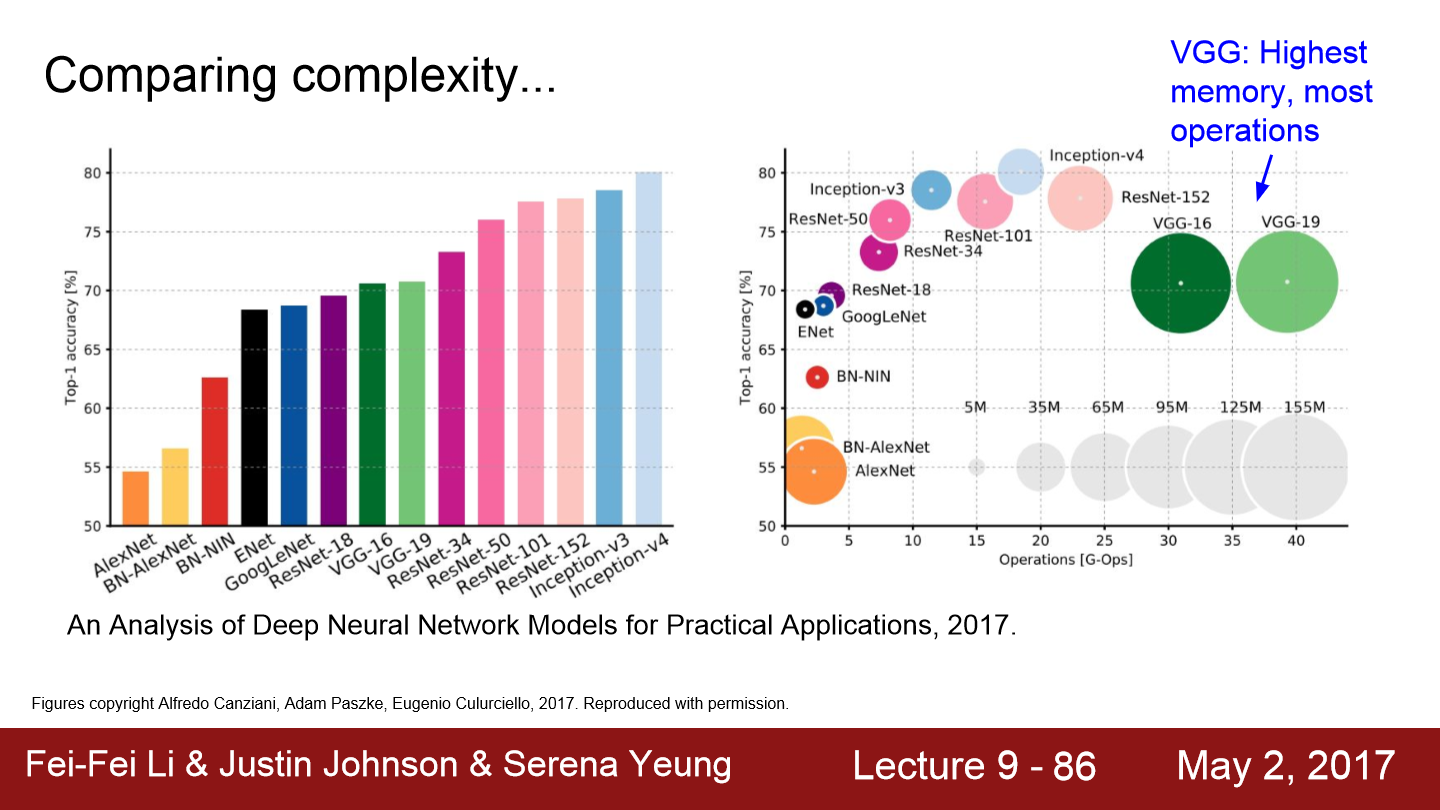
지금까지 봤던 구조들을 평가한 그래프입니다. 왼쪽 그래프는 정확성을 보여줍니다. Inception-v4가 가장 좋은 성능을 보이는데 이는 ResNet + Inception 모델입니다. 오른쪽 그래프는 정확성과 연산 메모리를 의미합니다. VGG의 경우 연산 memory가 매우 많이 사용되는 것을 볼 수 있습니다. GoogLeNet은 연산량은 상당히 낮고 정확도도 어느 정도 나오는 것을 볼 수 있습니다. ResNet과 Inception들이 좋은 성능을 보입니다.
이제 ResNet을 좀 더 발전시키거나 반대되는 구조들에 대해 간략하게 설명합니다.
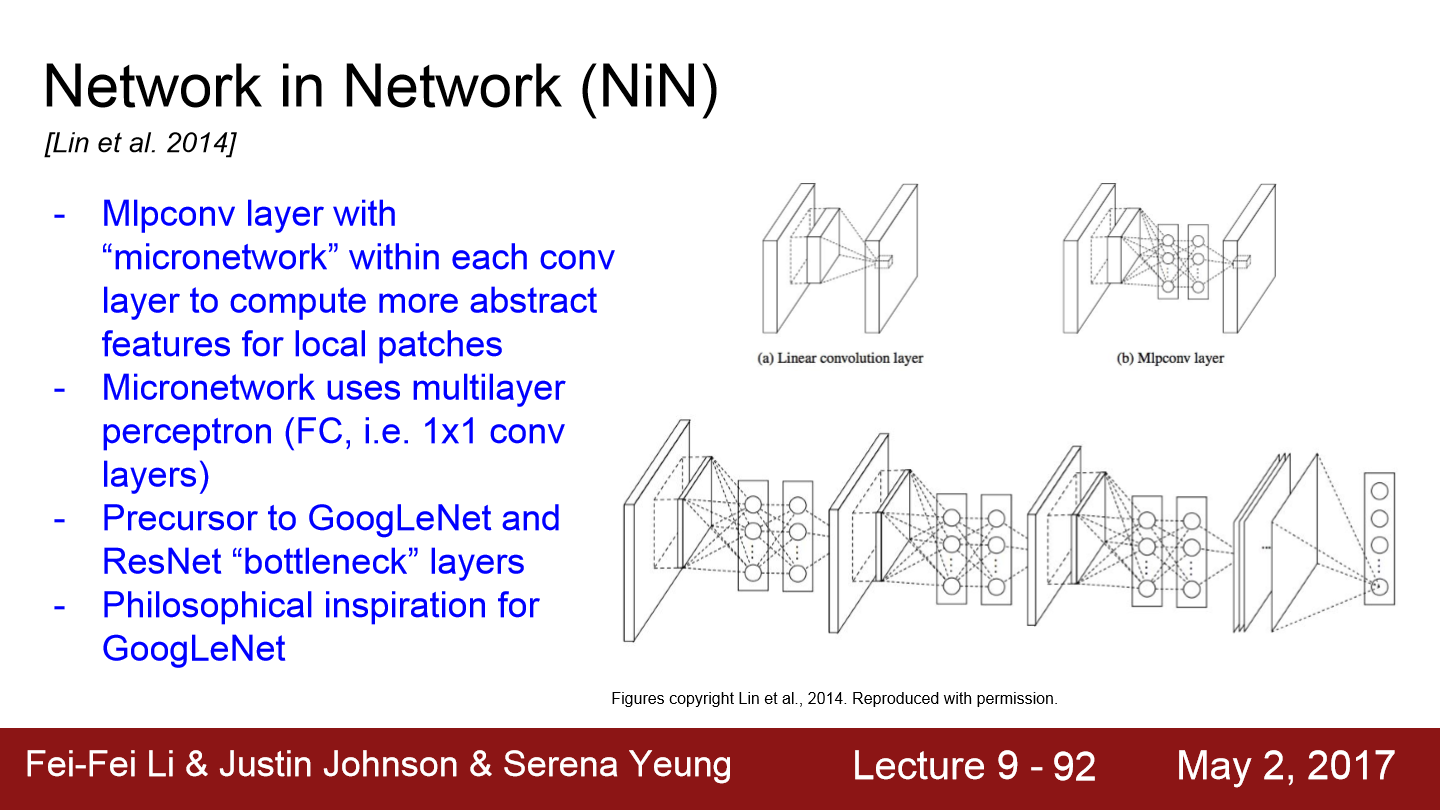
NiN의 기본 아이디어는 MLP conv layer입니다. network안에 작은 network를 삽입하는 방식이고 각 conv layer안에 MLP(Multi-Layer-Perceptron)를 쌓고 FC-Layer 몇 개를 쌓는 방식입니다. 처음에는 기존의 conv layer가 있고 FC layer를 통해 abstract feature를 잘 뽑을 수 있도록 도와줍니다. 단순히 conv filter만 사용하지 않고 조금 더 복잡한 계층을 만들어 activation map을 얻는 방식입니다.
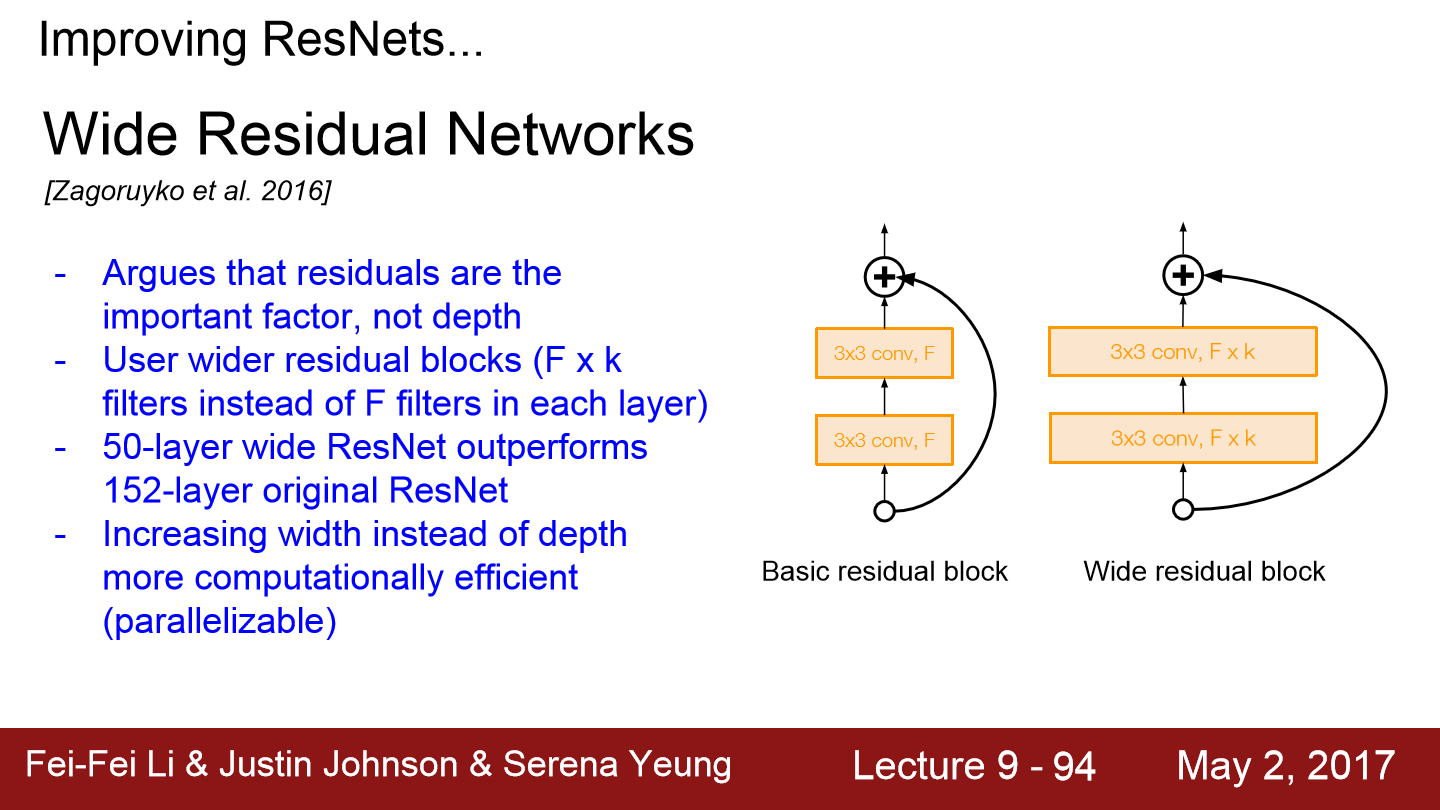
이번에는 Wide Residual Network입니다. 기존 ResNet의 논문은 깊게 쌓는 것에 집중했지만 사실 중요한 것은 depth가 아닌 residual이라 주장합니다. residual connection이 있다면 network가 굳이 더 깊어질 필요가 없다고 합니다. 그래서 residual block을 더 넓게 만들어줍니다. conv layer의 필터를 더 많이 추가합니다. 기존 ResNet에서는 Block 당 F개의 filter만 있었다면 F*K개의 필터로 구성합니다. 이와 같은 방식으로 50개의 layer로도 150개의 layer보다 더 좋은 성능을 보여줍니다. 그리고 depth 대신 filter의 width를 늘리면 계산 효율도 증가되는데 이는 병렬화가 더 잘되기 때문입니다.

depth가 깊어질수록 gradient가 사라지는 문제를 해결하기 위해 ResNet을 이용했습니다. 이를 더 해결하기 위해 train time에서 일부를 제거해버립니다. short network면 gradient가 잘 전달되어 트레이닝이 더 잘 될 수 있기 때문에 이와 같은 구조로 network를 구성합니다. dropout과 유사한 모습입니다. 이런 구조들 말고도 여러 model들이 있고 다양하게 연구 중입니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 11. Detection and Segmentation (0) | 2022.05.21 |
|---|---|
| Lecture 10. Recurrent Neural Networks (0) | 2022.05.19 |
| Lecture 8. Deep Learning Software (0) | 2022.05.14 |
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
| Lecture 6. Training Neural Networks, Part1 (0) | 2022.05.08 |



