이번에는 Neural Networks를 train 하는 방법들에 대한 내용이었습니다.

Part 1에서는 위에 해당하는 내용들을 배웁니다.

input data가 들어와 weight와 곱한 값을 activation function에 넣어줍니다. 이를 통해 비선형 연산을 거치게 됩니다.

Activation Function(활성화 함수)의 종류는 위와 같이 있으며 여기에 다루지 않은 종류들도 많습니다.

먼저 Sigmoid가 있습니다. 식은 위와 같습니다. 이 function의 output은 0부터 1 사이의 값을 갖습니다. input이 크다면 1에 가깝게, 작다면 0에 가깝게 output이 나옵니다. 이 함수는 문제가 있습니다. 먼저, 기울기가 소멸됩니다. input x가 -10이라면 값은 거의 0이 되고 기울기도 0이 됩니다. 이렇게 되면 아래로 전달되는 값은 똑같이 0이 되고 이로 인해 기울기가 소실되는 문제가 있습니다. 만약 input x가 10인 경우도 동일한 문제가 발생합니다. 그다음 문제는 sigmoid 함수의 output은 zero-centered가 아니라는 점입니다. sigmoid의 output은 0부터 1입니다. 그렇기 때문에 zero-centered가 아닙니다. 이렇게 된다면 위에서 내려온 gradient가 그대로 아래로 전달됩니다. 즉 parameter들은 update 될 때 전부 증가하거나 전부 감소하거나 합니다. 이렇게 되면 학습효율이 감소합니다. 마지막 문제점은 exp를 사용한다는 점입니다. 사실 이는 그렇게 큰 문제는 아니지만 다른 식들에 비해 지수함수는 연산 비용이 크다는 문제가 있습니다.

이번에는 tanh(x) 함수를 보겠습니다. 형태는 위와 같이 생겼습니다. 이 함수의 output은 -1에서 1사이의 값을 갖습니다. 그렇기 때문에 zero centered를 만족하지만 아직도 기울기가 0이 되는 부분이 존재합니다.

이번엔는 ReLU 함수를 보겠습니다. 이 함수는 max를 사용합니다. 이 함수는 input x가 0보다 작으면 0이 나오고 0보다 크다면 값 그대로 output이 나옵니다. 그렇기 때문에 양의 부분에서는 saturation 되지 않습니다. 그리고 계산이 간단하기 때문에 매우 효율적입니다. ReLU를 사용하면 sigmoid나 tanh보다 수렴 속도가 거의 6배 정도 빠릅니다. 그리고 생물학적 타당성도 sigmoid보다 큽니다. 하지만 이 함수는 zero-centered 된 모습은 아닙니다.

위 그림을 보면 ReLU함수의 문제를 알 수 있습니다. 예를 들어 ReLU함수에 input으로 W1 * x1 + W2 * x2같은 값들이 들어갑니다. 그리고 이 중 가중치가 왼쪽과 같이 초록색 또는 빨간색 선처럼 초평면을 이루게 됩니다. 그리고 여기에서 양의 부분인 절반만 가져갈 것입니다. 그래서 살아남은 W의 위치와 data cloud의 거리가 동떨어진다면 update는 되지 않고 dead ReLU가 되는 현상이 발생합니다. 이렇게 dead ReLU가 되는 이유는 여러 가지가 있습니다. 초기화를 잘못하는 경우 data cloud와 멀리 떨어지는데 이 경우 어떤 데이터 입력에서도 activate 되는 경우가 존재하지 않고 backprop도 일어나지 않습니다. learning rate가 너무 높은 경우도 dead ReLU가 되는데 이 경우 가중치가 학습되지 않고 날뛰게 됩니다. 이러한 원인들로 인해 dead ReLU가 발생하는데 학습한 network를 살펴보면 10 ~ 20%의 ReLU들은 dead ReLU가 되는 경우가 있습니다. 하지만 이 정도는 네트워크 학습에 크게 지장이 있지는 않습니다. dead ReLU를 막기 위해 bias를 더하는 방법이 등장했습니다. 이를 통해 update 시 조금이라도 activate ReLU가 될 가능성을 높입니다.

Leaky ReLU라는 함수도 있습니다. 이 함수는 saturate되지 않습니다. ReLU처럼 학습 속도도 빠르고 효율적입니다. PReLU라는 함수도 있는데 이는 음의 범위에서 leaky ReLU처럼 기울기가 존재하지만 알파라는 파라미터에 따라 변경됩니다. 여기 알파는 정해진 값이 아닌 backprop을 통해 학습시키는 parameter입니다.
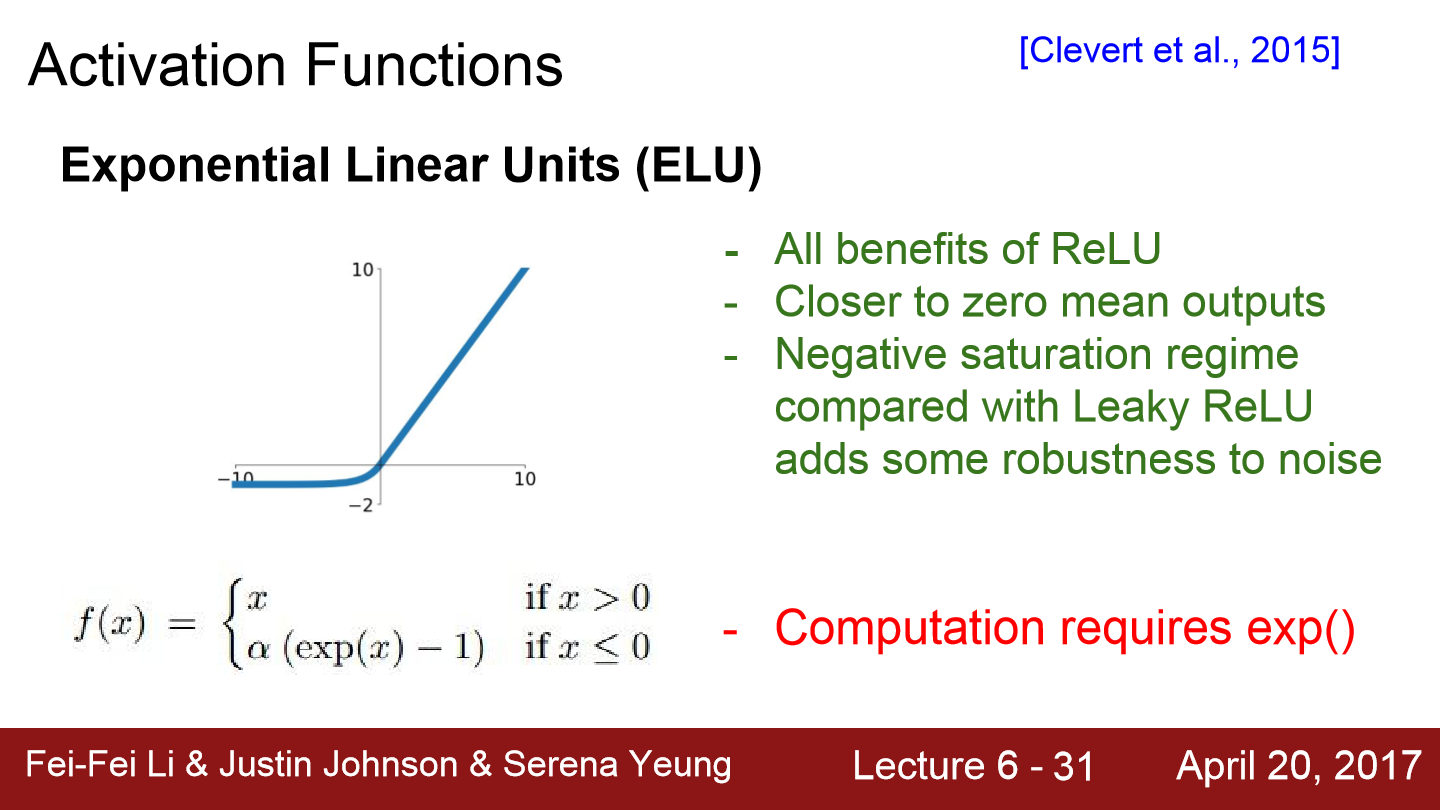
ELU라는 함수도 있는데 이는 ReLU와 같은 장점을 가지고 있습니다. 또한 음수 범위에서 0이 아닌 값을 갖습니다. 하지만 지수함수가 포함된 함수여서 연산 비용이 다른 함수들에 비해 높습니다.

이제는 데이터 전처리에 대해서 얘기합니다. 가장 대표적인 전처리과정은 데이터를 zero-mean으로 만들고 normalize 하는 것입니다. normalize는 보통 표준편차로 합니다. 이렇게 연산을 하면 데이터를 선형 연산을 한 것이기 때문에 데이터의 feature를 잃지 않습니다. normalize는 모든 차원이 동일한 범위 안에 있게 만들어 전부 동등한 기여를 하도록 하기 위해 사용됩니다. 실제로는 image의 경우 전처리로 zero-centering 정도만 해줍니다. 왜냐면 이미지는 이미 각 차원 간에 scale이 어느 정도 맞춰져 있기 때문에 normalize를 해주지는 않습니다. train data에 전처리 과정을 했으면 test에도 당연히 동일한 전처리 과정을 해야 합니다. train data에 했던 전처리 과정의 평균을 구해 이 평균만큼 test에 해주면 됩니다. mini batch를 사용할 경우 batch 크기만큼의 평균을 구해서 test data에 적용시켜도 상관없습니다.

이번에는 weight 초기화 방법에 대해서 알아보겠습니다.

처음 말하는 방식은 작은 수로 random 하게 초기화하는 방법입니다. 이 경우 network의 크기가 작은 경우 크게 문제 되지 않지만 deep 한 network의 경우 문제가 발생합니다.
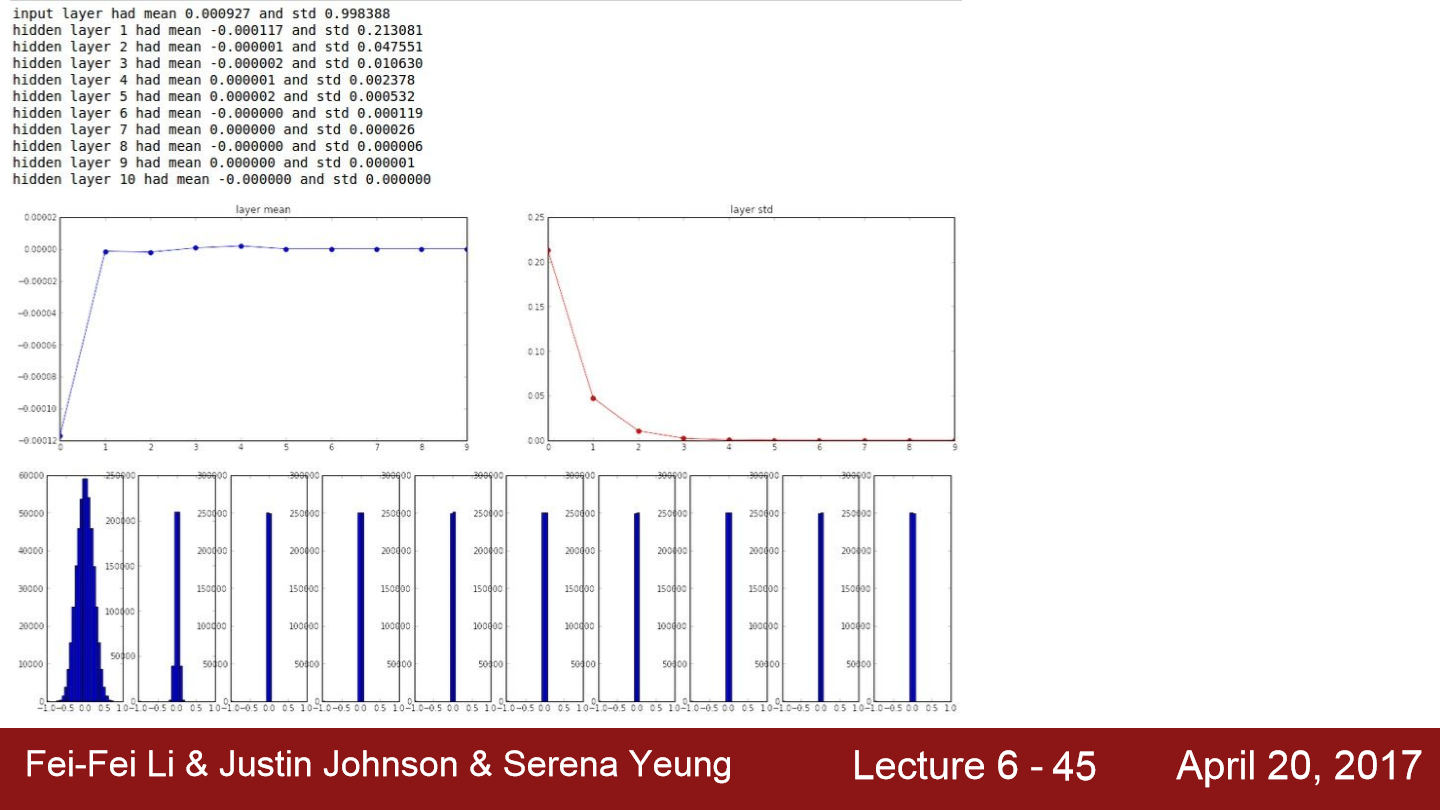
위 그림은 train 되는 모습을 보여준 그래프들입니다. weight는 편차 0.01을 곱해 random 하게 만들어줬습니다. tanh를 사용한 network입니다. tanh 특성상 평균은 항상 0 근처에 존재합니다. 표준편차도 가파르게 0으로 가까워지고 있습니다. 여기서 문제는 W를 곱할수록 W가 너무 작은 값들이라서 출력값이 급격히 줄어든다는 점입니다. 그 결과 모든 activation function의 결과가 0이 됩니다.

그럼 이번에는 이전보다 좀 더 큰 값으로 random 하게 weight를 초기화했습니다. 0.01을 곱한 것이 아닌 1을 곱했습니다. 이러한 값들이 tanh에 들어간다면 가중치가 큰 값을 갖기 때문에 tanh의 output은 항상 saturation될 것입니다. 왜냐하면 작은 값이 들어가면 그 값은 계속 작은 값이 되고 이를 반복하다보면 -1에 가깝게 output이 나올 것입니다. 반대로 큰 값이 들어가면 그 결과고 큰 값이 나오고 그 값이 또 들어가는 과정을 반복해 결국 output은 1에 가깝게 위치합니다. 그러다보니 gradient는 0이 되고 가중치 update는 결국 일어나지 않습니다.
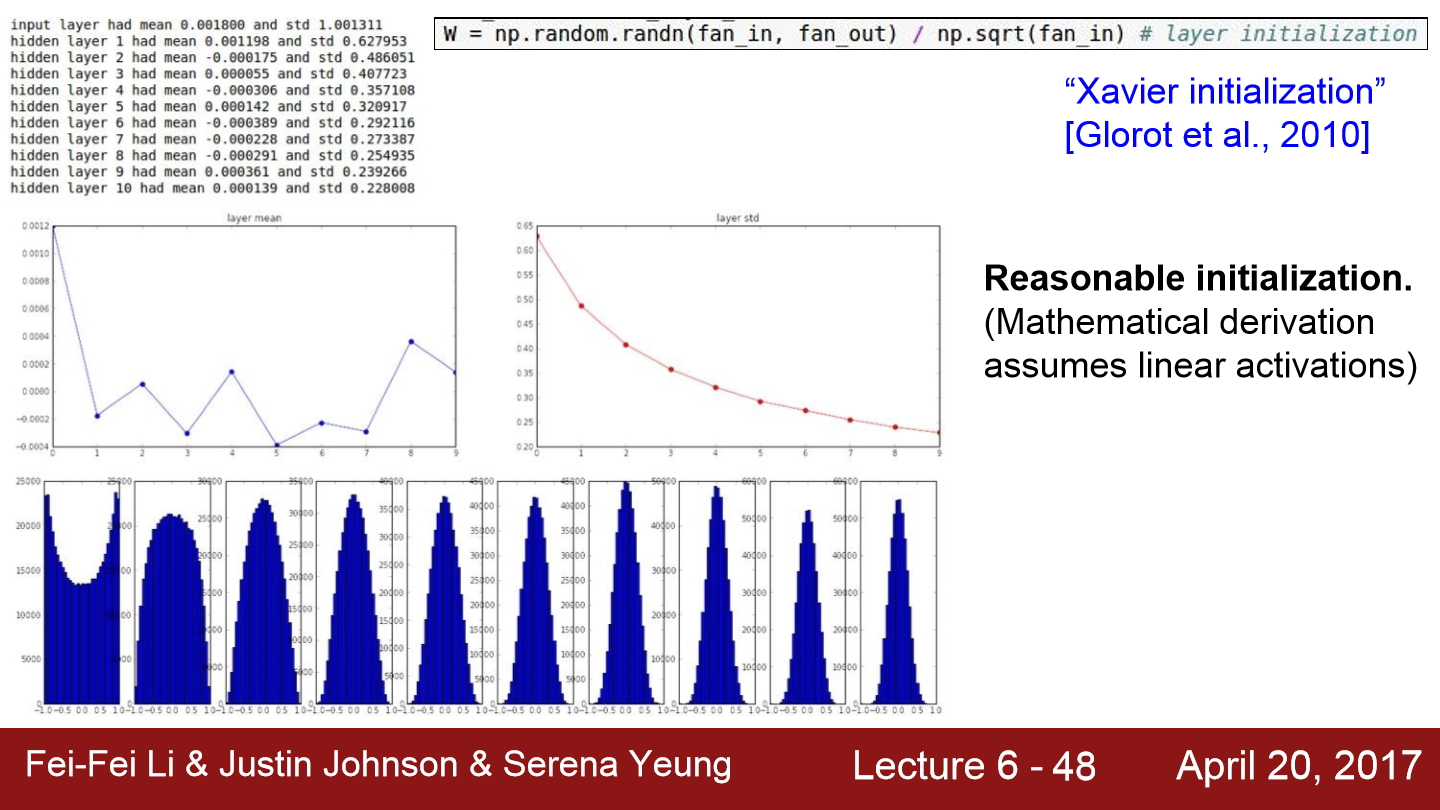
이번에는 Xavier initialization 방법입니다. 이 경우 random하게 뽑은 값들을 input의 수로 sacling 하는 방식입니다. input의 수가 적으면 더 작은 값으로 나누고 더 큰 값을 얻습니다. 작은 input의 수와 가중치의 곱셈을 이용하기 때문에 가중치가 더 커야만 출력의 분산만큼 큰 값을 얻을 수 있기 때문이고 반대로 input의 수가 큰 경우는 반대로 적용됩니다. 하지만 이러한 initialization은 ReLU에서는 잘 적용하지 않습니다. 절반은 0으로 죽이기 때문에 출력의 분산을 반토막 내버립니다.

그래서 이를 어느 정도 해결하기 위해 fan_in의 절반을 식에 작용하는 방법이 등장했습니다. 이 경우 좀 더 잘 작동합니다.

이제 Batch Normalization에 대해서 얘기해보겠습니다.

어떤 layer로부터 나온 batch 단위만큼의 activation이 있다고 할 때, 이 값들이 unit gaussian이기를 원합니다. batch에서 계산한 평균과 분산을 이용해 normalization을 하면 되고 이런 작업을 통해 unit gaussian이 되도록 할 수 있습니다. 가중치를 잘 초기화하는 것 대신에 normalization을 통해서 우리가 원하는 데이터 형태를 만들 수 있습니다.

batch 당 N개의 학습 데이터가 있고 각 데이터가 D차원이라고 할 때, N개의 학습 데이터 전부 각 차원별로 평균을 구해 normalize 합니다.
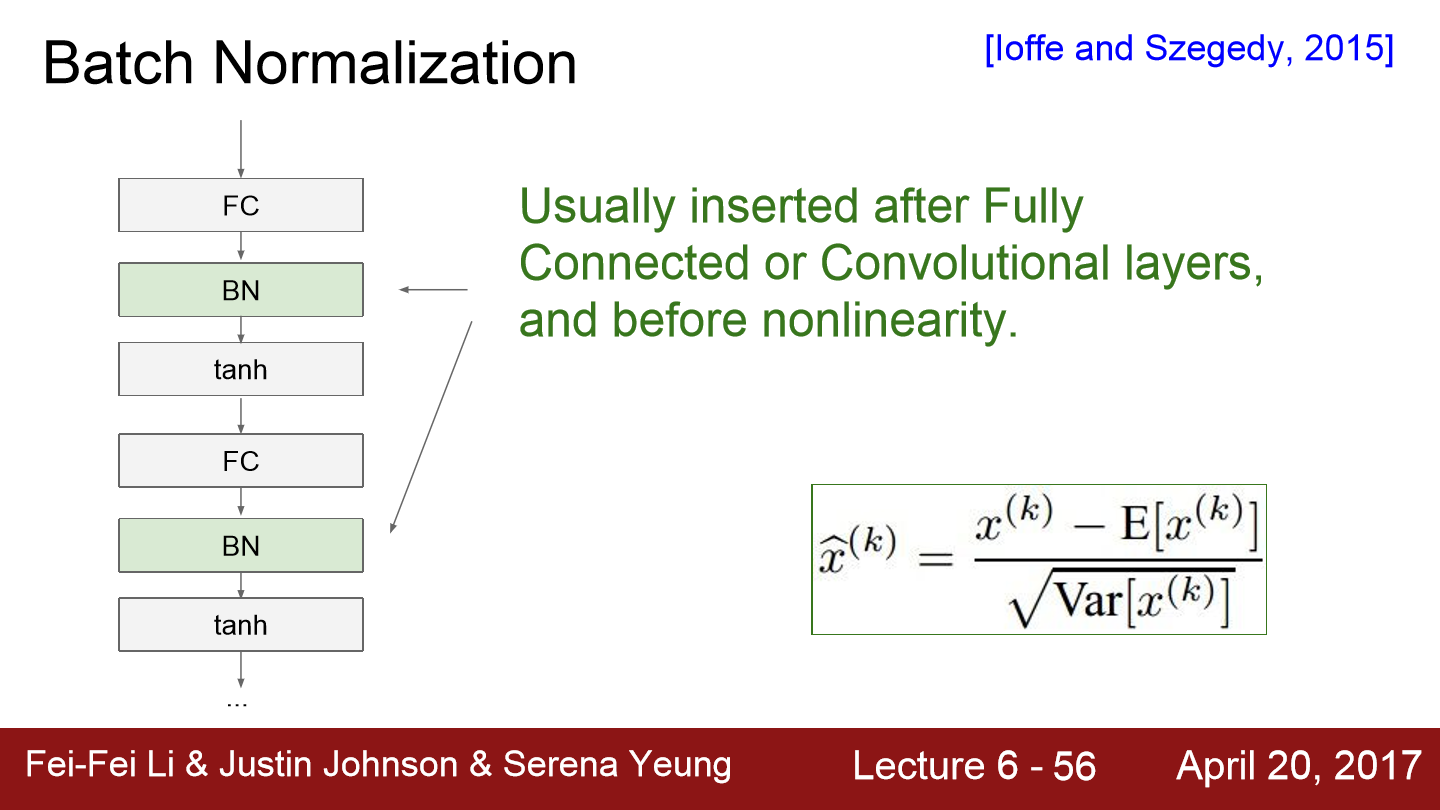
이런 BN(Batch Normalization)을 FC 또는 Conv layer 직후에 넣어줍니다. BN은 bad scaling effect를 상쇄시켜주기 때문에 FC나 CNN 어디든 적용할 수 있습니다. 그런데 위 그림에서 과연 tanh함수에 항상 unit gaussian 한 데이터가 들어가는 것이 올바를까?? 이는 사용자가 임의적으로 정해줘야 합니다. Normalization이 하는 일은 input이 tanh의 linear 한 영역에만 존재하도록 강제로 scale을 조정하는 것인데 이렇게 되면 saturation은 일어나지 않습니다. 그래서 사용자가 saturation 얼마나 일어날지 조절해주는 것이 좋습니다.

이 식으로 보면 Normalization을 control 하는 방법에 대해서 서술되어 있습니다. 위 식에서 γ는 scaling의 효과를, β는 이동 효과를 줍니다. 이러한 식을 BN뒤에 넣어주면 Normalization 된 값을 다시 원상복구도 가능합니다. 이 식을 이용해 normalization에 대한 유연성을 줄 수 있습니다.
이다음 강의에서는 learning rate에 대한 설명이 있습니다. 너무 큰 learning rate를 이용하거나 너무 작은 learning rate를 설정한 경우에 대해서 예를 보여줍니다. 일반적으로 learning rate를 1e-3에서 1e-5 사이의 값을 갖는다 합니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 8. Deep Learning Software (0) | 2022.05.14 |
|---|---|
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
| Lecture 5. Convolutional Neural Networks (0) | 2022.05.04 |
| Lecture 4. Backpropagation and Neural Networks (0) | 2022.05.02 |
| Lecture 3. Loss Functions and Optimization (0) | 2022.05.01 |



