이번 강의에서는 CNN에 대해서 좀 더 자세히 배웠습니다.
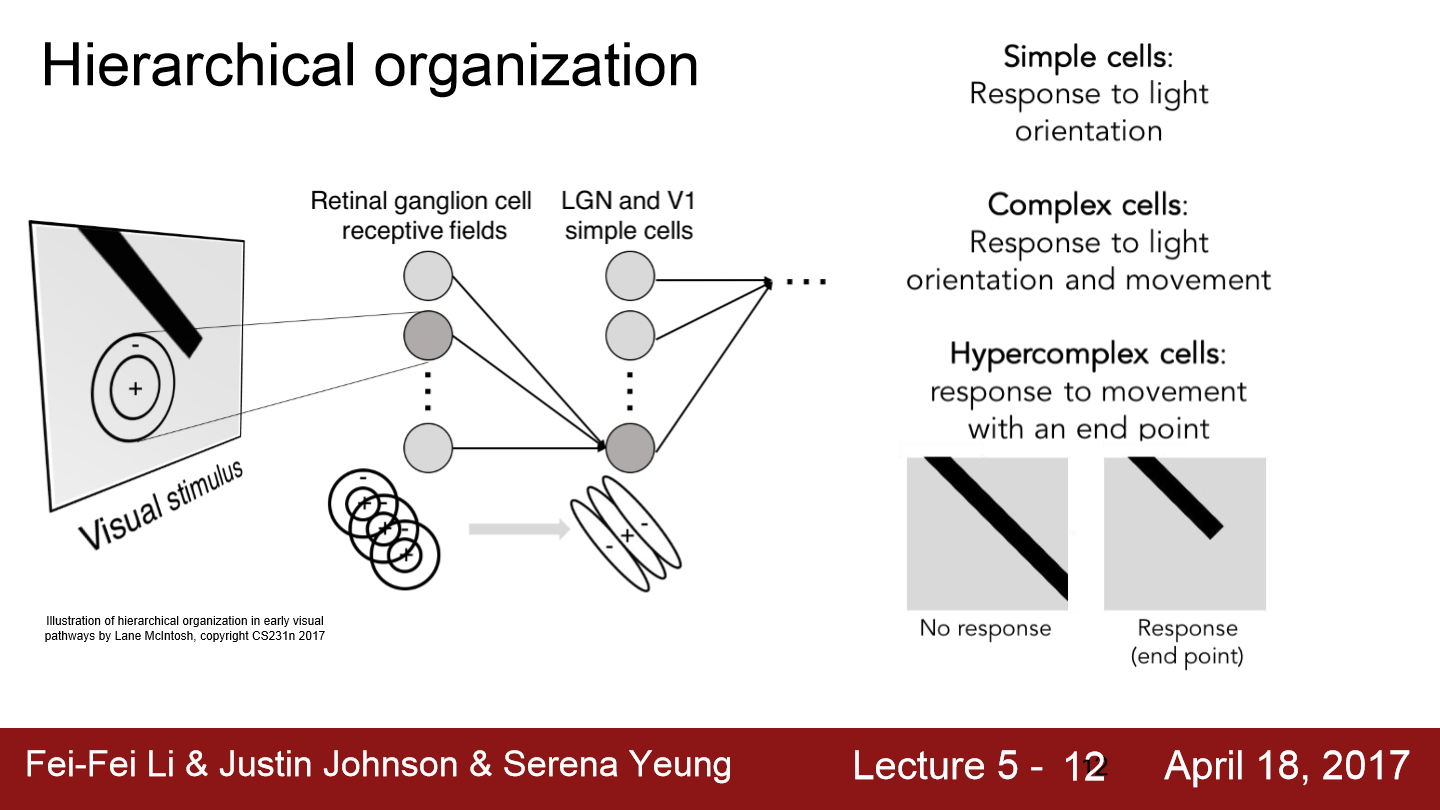
다양한 종류의 시각 자극을 관찰하면서 시각 신호가 가장 먼저 도달하는 곳은 Retinal ganglion이라는 것을 발견했고 복잡도가 증가할수록 hypercomplex cells은 end points와 같은 것에 반응한다는 것을 알았습니다. 이러한 시각신호에 대한 처리 방식을 예전부터 연구하고 공부해온 결과 현대의 CNN구조가 생겨났습니다. 2012년에 AlexNet의 등정과 함께 CNN의 현대화 바람이 일어났고 이 AlexNet은 이미지 검색에 좋은 성능을 보였습니다. 또한 GPU 성능이 발전하면서 수많은 데이터에 대한 연산도 빨라지며 CNN이 더 대중화되었습니다. 이런 CNN은 이미지뿐만 아니라 영상에서도 사용 가능한데 이 경우 단일 이미지의 정보에다 시간적 정보도 같이 활용합니다.

Fully Connected layer의 경우 데이터를 일자로 쭉 펴서 연산을 진행하지만 convolution layer의 경우 구조를 보존하는 차이가 있습니다. 위 그림에서 filter는 우리가 전에 사용했던 W(가중치)가 됩니다. 이 filter가 sliding을 하면서 공간적으로 내적을 수행합니다.

사실 filter가 sliding 하면서 해당 위치에 값을 서로 곱해 더하는 방식인데 실제로 모두 펴서 벡터 간 내적을 구하는 것과 같은 의미입니다.
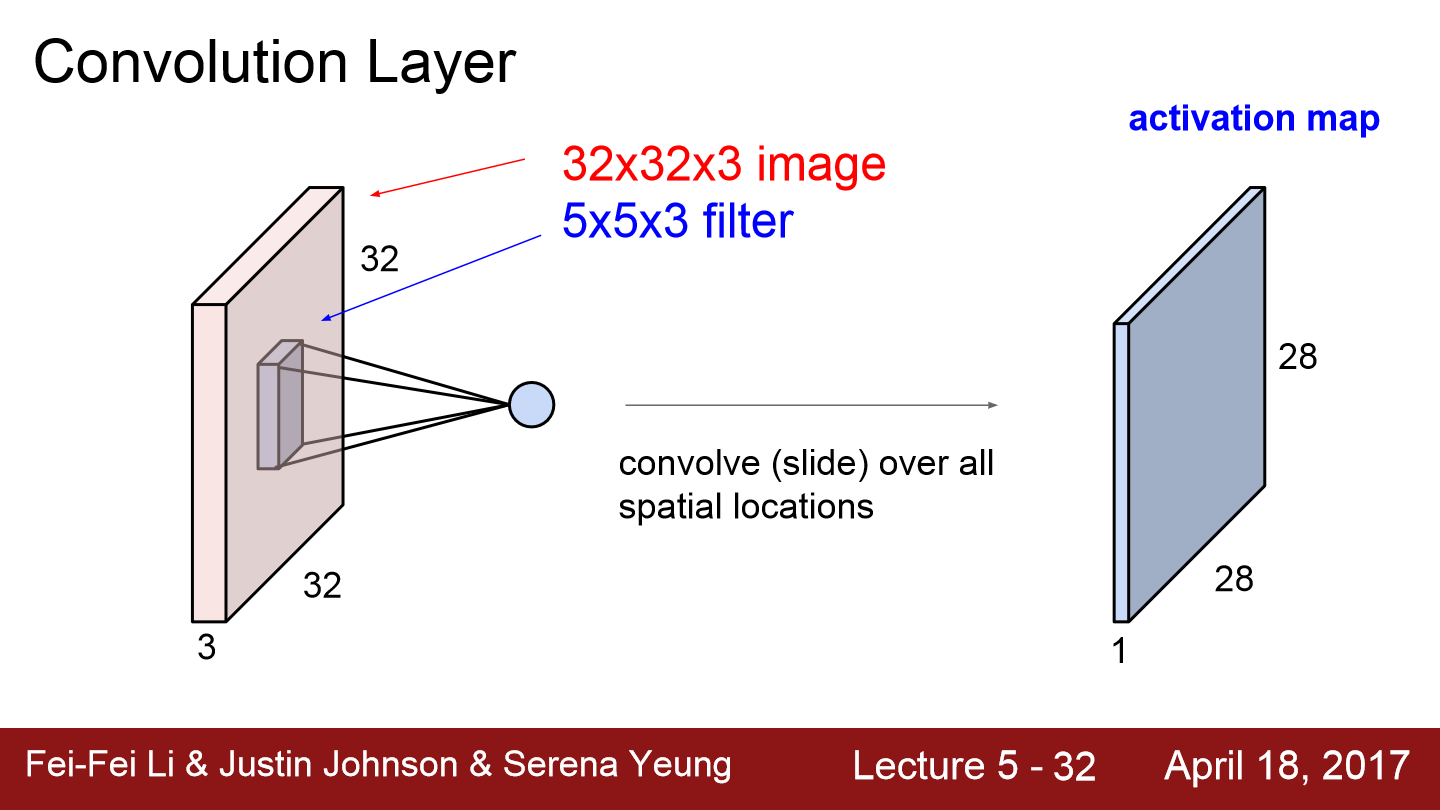
filter만큼 내적을 하면 하나의 값(곱셈들의 함)이 나오는데 이 값은 output acitvation map의 한 위치에 저장이 됩니다. 만약 좌측 상단에 filter가 적용되었다면 output activation map의 좌측 상단에 값이 저장될 것입니다.

위 그림은 6개의 filter를 적용한 모습입니다. filter의 수는 우리가 임의로 정할 수 있으면 각 filter마다 다른 image의 feature들을 담고 있습니다.

이제 이러한 Convolution 연산을 한 후 다른 연산들(ex. ReLU)을 넣어 layer들을 계층적으로 쌓을 수 있고 이 layer들의 filter들이 학습을 통해 값이 변경되어 나갈 것입니다. 위 그림에서 처음 5x5x3 filter 6개가 존재하기 때문에 output activation map의 depth가 6이 되었고 그다음 연산을 보면 5x5x6 filter 10개가 존재하기 때문에 output activation map의 depth가 10이 된 것을 볼 수 있습니다.

일반적으로 low level에서는 edge 같은 특징을 의미하고 mid level의 경우 corner나 blobs 등 더 복잡한 특징들을 의미합니다. high level에서는 좀 더 객체와 닮은 것들이 출력으로 나옵니다.

위 필터들이 나열되어 있고 아래에 activation들이 그려져 있습니다. filter가 sliding 되면서 이미지와 연산이 되는데 필터와 비슷한 값을 갖는 부분은 큰 값을 갖게 됩니다.
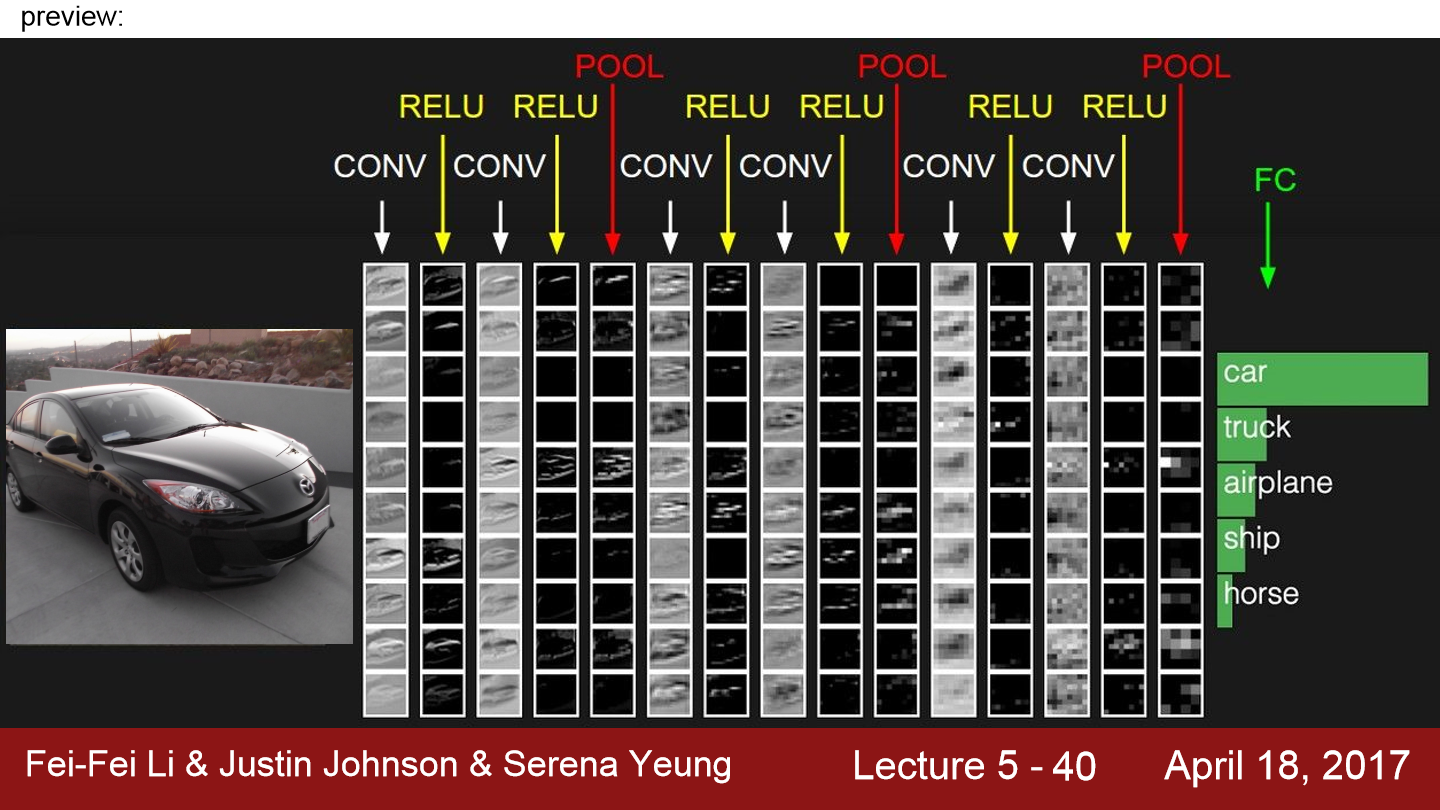
input image는 여러 layer를 통과하게 됩니다. POOL은 activation map의 사이즈를 줄이는 역할을 합니다. CNN 마지막 부분에는 FC-Layer가 있는데 이는 지난 시간까지 배운 layer와 동일하고 이 layer에서 Conv 출력 모두와 연결되어 있으며 최종 스코어를 계산하기 위해 사용됩니다. car의 점수가 제일 높게 평가되는 모습을 그리고 있습니다.
이번에는 filter를 거친 activation map의 size에 대해서 알아보겠습니다.

위 식에서 N은 input으로 들어오는 이미지 또는 activation map의 크기가 될 것입니다. F는 filter의 size를 의미하고 stride는 filter가 한번 sliding 할 때 얼마큼 이동을 할지를 의미합니다. 위 예시를 보면 N = 7, F = 3이라 나옵니다. 이 뜻은 input data가 7x7이라는 것이고 filter는 3x3이라는 것입니다. stride가 1인 경우 (7-3)/1 + 1이 되어 output activation map의 크기는 5x5가 됩니다. stride가 2인 경우 (7-3)/2 + 1이 되어 output activation map의 크기는 3x3이 됩니다.
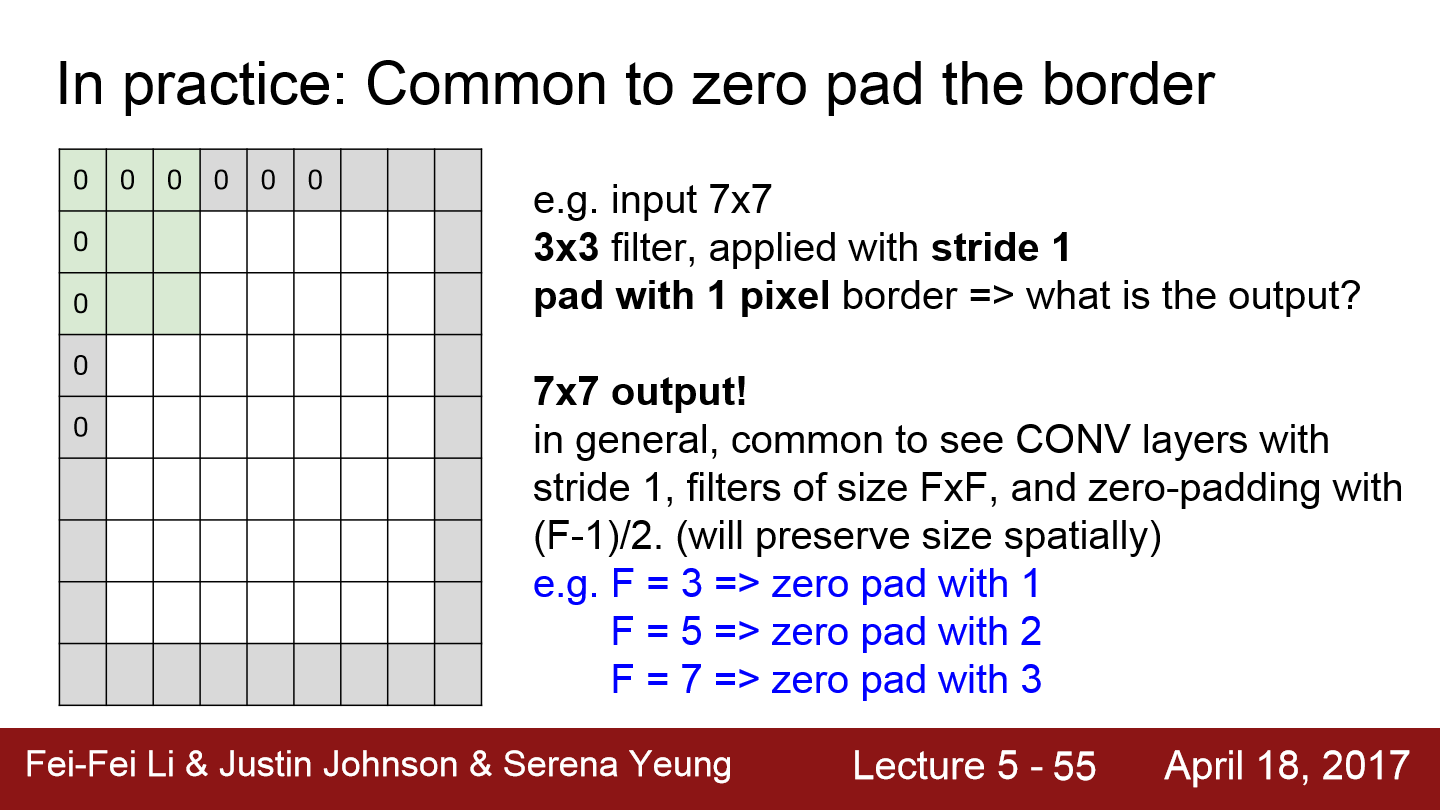
이번에는 padding에 대해서 알아보겠습니다. 위 그림은 zero padding을 나타내고 있습니다. 사실 padding의 종류는 많은데 그건 사용자가 알아서 정해 사용하면 됩니다. 위 예시처럼 N = 7, F = 3, S = 1, padding = 1인 경우 output activation map의 크기는 (7-3+2*1)/1 + 1 이 되어 7x7이 됩니다.

위 예시처럼 input volume = 32x32x3일 때 filter는 10 5x5, stride 1, pad 2인 경우 output volume size는??
일단 output size먼저 연산을 하면 (32 - 5 + 2*2)/1 + 1 = 32가 되어 32x32가 됩니다. 여기에 filter의 개수가 10개 이므로 결과는 32x32x10이 됩니다.
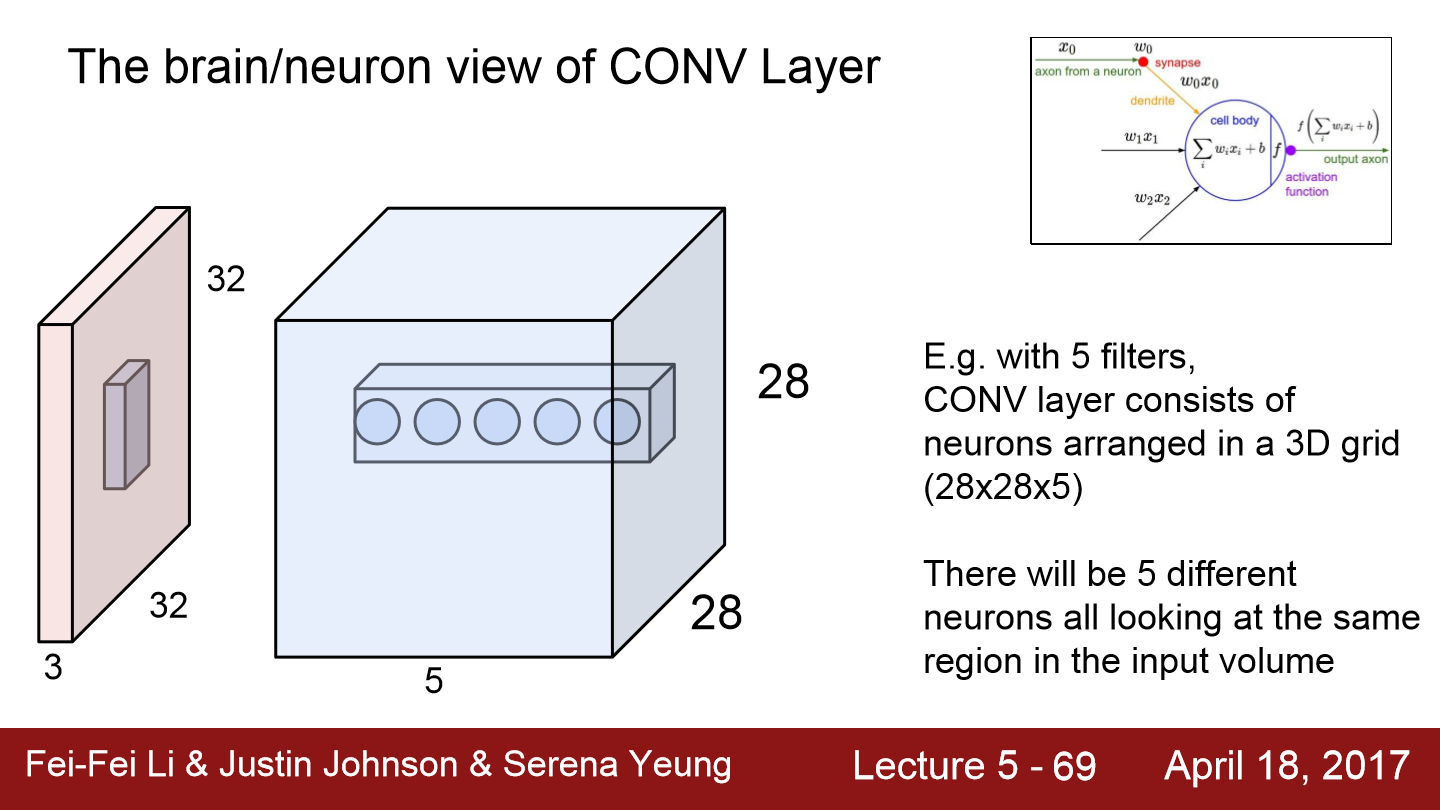
이 이미지를 보면 filter 5개를 적용해 나온 모습이 파란색 상자입니다. 이 다섯 개의 점은 정확하게 같은 지역에서 추출된 서로 다른 feature입니다. 하지만 각 filter는 서로 다른 feature들을 추출합니다. 각 필터는 이미지에서 같은 지역을 돌더라도 서로 다른 특징을 뽑아낸다는 사실은 중요합니다.

위 그림은 max pooling에 대해서 나타내고 있습니다. pooling도 padding과 같이 종류가 여러 가지 있습니다. 먼저 pooling이란 정보들을 더 작고 관리하기 쉽게 만들기 위해서 size를 줄여주는 과정을 의미합니다. 이 pooling은 depth에는 아무런 영향을 주지 않고 오직 size만 줄어들게 합니다. 이렇게 size가 줄어들면 parameter수가 줄어들고 공간적인 불변성도 얻을 수 있어 사용합니다. 위 그림처럼 pooling에서도 filter가 존재하는데 해당 filter를 적용한 부분에서 가장 큰 값을 뽑아내는 걸 max pooling이라 합니다. 이런 max pooling은 어떤 신호에 대해 얼마나 그 필터가 활성화되었는지를 알려줍니다.

이 그림을 한번 더 가져왔습니다. 위 그림을 보면 차 사진이 input으로 들어간 모습입니다. 마지막 Conv layer의 출력은 3차원으로 이루어져 있을 것입니다. 이제 이 값들을 전부 1차원 벡터로 만들어 FC Layer에 넣어줍니다. 이렇게 되면 모든 Conv layer의 출력을 서로 연결하게 되고 이 마지막 layer부터는 공간적 구조를 신경 쓰지 않게 됩니다.
위 사진에서 activation map을 보면 사실 어떤 걸 의미하는지 알 수 없습니다. 이러한 정보를 가지고 어떻게 차인지 다른 이미지인지 분류를 할까??
오른쪽 맨 끝에 있는 Pool layer의 출력 값은 전체 네트워크를 통과한 집약체입니다. 그러므로 우리가 만든 계층 구조의 최상위에 위치한다 할 수 있습니다. 이런 higher-level에서는 객체에 대한 정보들이 존재합니다. 전에 존재했던 layer의 output인 activation map이 그다음 layer의 input으로 들어가고 또 이러한 과정을 반복해 더 복잡한 정보들을 얻을 수 있습니다. 그래서 마지막 Pool layer의 출력을 집약체라 표현할 수 있고 객체에 대한 정보들이 존재한다 볼 수 있으며 이러한 정보를 통해 image를 분류할 수 있습니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
|---|---|
| Lecture 6. Training Neural Networks, Part1 (0) | 2022.05.08 |
| Lecture 4. Backpropagation and Neural Networks (0) | 2022.05.02 |
| Lecture 3. Loss Functions and Optimization (0) | 2022.05.01 |
| Lecture 2. Image Classification (0) | 2022.05.01 |



