이번 CS231n 4장의 내용은 Backpropogation과 Neural Networks입니다.
먼저 Computational graphs에 대해서 설명을 합니다.
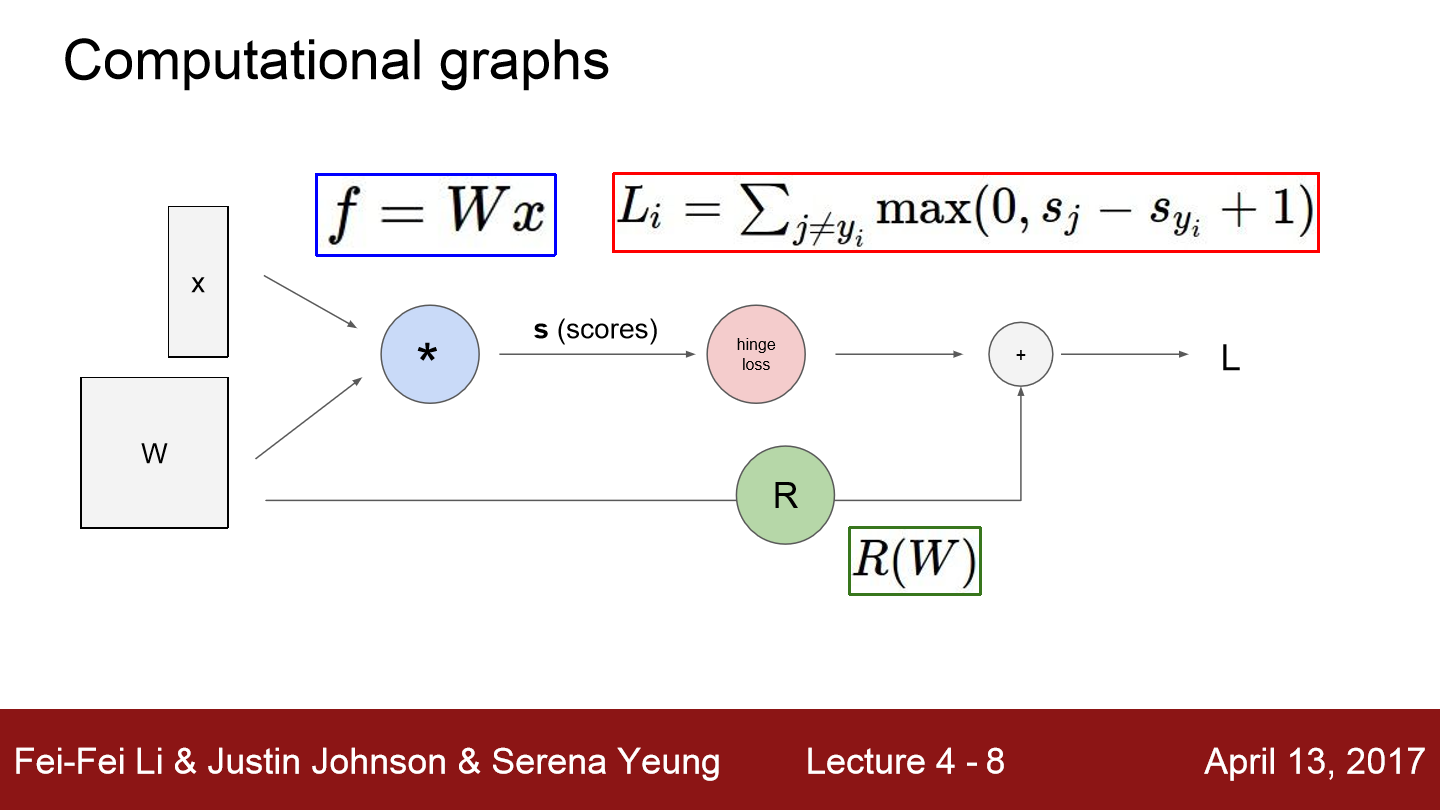
각 노드는 연산 단계를 의미합니다. 여기서 R(W)는 저번 강의에서 봤던 regularization이 됩니다.
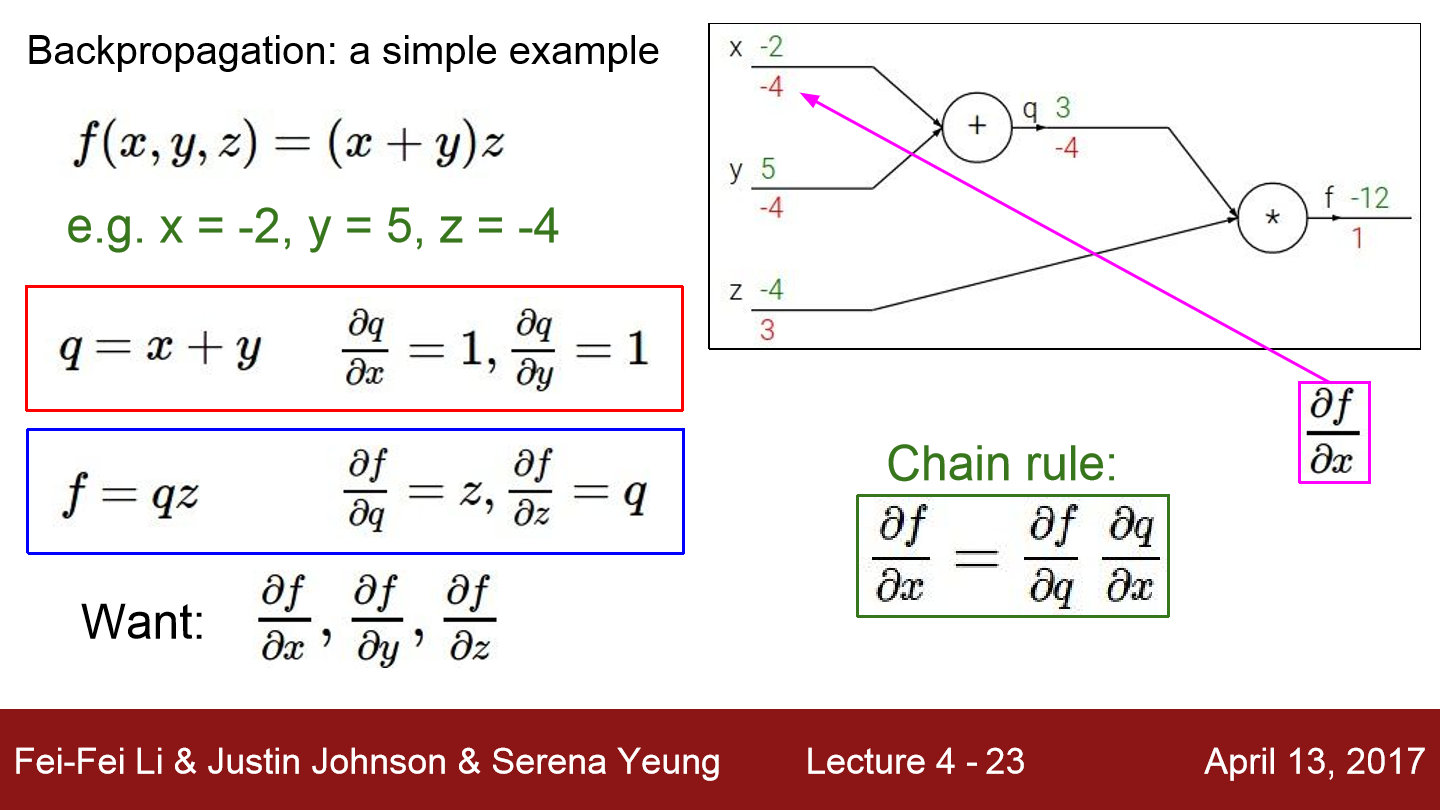
위 예시를 보겠습니다. 일단 f(x, y, z) = (x + y) z이고 x = -2, y = 5, z = -4라 하겠습니다. q는 x+y의 결과가 저장됩니다. 그리고 f에는 q*z의 결과가 들어갑니다. 초록색 글씨는 연산의 결과를 의미합니다. (5-2)*(-4)는 -12가 됩니다. 빨간색 글씨는 미분한 값, gradient가 됩니다. 일단 q = x+y이고 dq/dx = dq/dy = 1입니다. 그리고 f = qz에서 df/dq = z, df/dz = q입니다. 이를 이용해 미분된 값들이 전달되는 것을 볼 수 있습니다. df/dz는 3이 된 것을 볼 수 있고 df/dq는 -4이 된 것을 볼 수 있습니다. df/dx를 구하기 위해서는 df/dq * dq/dx를 하면 됩니다. 이를 chain rule이라 설명하셨습니다. 우리는 x, y, z의 값이 변경될 때 f에 얼마큼 영향을 미치는지를 알고 싶기 때문에 이와 같은 연산을 하는 것입니다. 그럼 f가 y에 영향을 미치는 정도는 -4라는 것을 알 수 있습니다.

이 그림을 보면 좀 더 이해가 됩니다.

이번에는 좀 더 복잡한 식을 가지고 연산을 했습니다. f는 위 식과 같습니다. 먼저 이 식에 사용된 연산들의 미분한 값들을 정라해놨습니다. 그리고 아까와 같이 뒤에서부터 순차적으로 local gradient와 upstream gradient의 곱을 계속해서 구합니다. 이렇게 w0가 f에 미치는 영향의 강도를 -0.20로 구할 수 있습니다.

그럼 이 질문과 같이 max gate인 경우 gradient는 어떻게 표현될까??
max는 input들 중 큰 값을 받는 gate이므로 gradient도 큰 값으로 전달되고 나머지 값은 0이 됩니다.

곱의 경우 서로 대칭되서 upstream gradient와 곱한 값이 전달되는 것을 볼 수 있습니다. 이번에는 scalar가 아닌 vector에 대한 연산을 진행해보겠습니다.

vector인 경우 행렬로 표현이 되는데 행렬을 미분하기 때문에 각 요소의 미분을 포함하는 행렬이 됩니다. 예를 들어 x의 각 원소에 대해 z에 대한 미분을 포함하는 행렬이 됩니다.

이번에는 벡터를 이용해 위 식에 대해서 연산을 진행해보겠습니다. W는 위 행렬과 같이 크기가 2x2인 행렬이고 x도 위 행렬과 같이 크기가 2x1인 행렬입니다. 두 행렬 곱의 결과가 위와 같이 곱셈 노드에 전달됩니다. L2 노드의 결과는 0.116이 됩니다. 이제 이를 역으로 gradient를 구한 결과들은 빨간 글씨로 적혀있습니다. W와 x의 곱이 서로 어떤 값이 곱해지고 더해졌는지 생각하면 위 식이 이해될 것입니다. 예를 들어 0.22는 0.1x0.2 + 0.5x0.4입니다. 그리고 0.26은 -0.3x0.2 + 0.8x0.4입니다. 그로 인해 0.088 = 0.44 * 0.2가 되고 0.176 = 0.4 * 0.44가 됩니다.

결국 행렬곱에 대한 gradient를 구하는 방식은 상대 행렬를 전치한 후 곱하는 형태입니다. -0.112 = 0.1x0.44 + -0.3x0.52가 됩니다. 여기까지 벡터의 gradient를 구하는 방법까지 알아봤습니다.

위는 x*y = z인 식에 대해 forward와 backward의 간단한 형태를 보여줍니다. 아까 곱셈은 서로 대칭해서 곱하면 된다 했고 코드도 그렇게 작성되면 됩니다.

여기서 h는 x와 W1의 곱이 됩니다. 그리고 s는 h*W2가 됩니다. W2는 h에 가중치를 부여해 모든 점수를 더해 클래스에 대한 최종 점수 s를 얻는 그림입니다.
import numpy as np
from numpy.random import randn
N, D_in, H, D_out = 64, 1000, 100, 10
x, y = randn(N, D_in), randn(N, D_out)
W1, W2 = randn(D_in, H), randn(H, D_out)
for t in range(2000):
h = 1 / (1 + np.exp(-x.dot(W1)))
y_pred = h.dot(W2)
loss = np.square(y_pred - y).sum()
print(t, loss)
grad_y_pred = 2.0 * (y_pred - y)
grad_W2 = h.T.dot(grad_y_pred)
grad_h = grad_y_pred.dot(W2.T)
grad_W1 = x.T.dot(grad_h * h * (1 - h))
W1 -= 1e-4 * (grad_W1)
W2 -= 1e-4 * (grad_W2)
sigmoid함수를 활성화함수로 이용해 간단한 코드를 작성했습니다. 이는 위 그림과 같이 hidden layer 1개를 가진, weight 2개를 가진 neural network입니다. 랜덤하게 x, y, W1, W2를 정해주고 학습을 진행합니다. 실행결과를 보면

학습할수록 loss가 줄어드는 것을 볼 수 있습니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
|---|---|
| Lecture 6. Training Neural Networks, Part1 (0) | 2022.05.08 |
| Lecture 5. Convolutional Neural Networks (0) | 2022.05.04 |
| Lecture 3. Loss Functions and Optimization (0) | 2022.05.01 |
| Lecture 2. Image Classification (0) | 2022.05.01 |



