이번 CS231 2장 수업은 이미지 분류에 대한 내용입니다.

먼저 이와 같이 고양이 사진을 보고 고양이인지 아닌지 분류하는 classifier를 만드는 것에 대해서 설명을 합니다. 인간은 그림을 보고 판단이 쉽게 가능하지만 컴퓨터는 인간과 다르게 이미지를 입력으로 받으면 숫자로 이루어진 데이터에 불과합니다. 각 픽셀당 색에 따라 숫자의 값이 달라질 것입니다. 만약 어떤 한 이미지를 컴퓨터가 완전히 숙지했다고 해도 고양이를 바라보는 각도, 불빛의 양, 배경과 비슷한 색을 가진 고양이 등 여러 요인에 따라 컴퓨터는 고양이로 분류하기가 쉽지 않습니다.
그래서 먼저 이 강의에서는 Nearest Neigbor(NN)이라는 기초적인 분류 알고리즘에 대해서 말을 합니다.

train 메서드에서는 이미지와 label이 들어오면 그냥 저장해 model을 return 합니다. predict 메서드에서는 test image와 model을 input으로 받아주고 분류 결과를 return 합니다. 여기서 분류할 때 사용한 방식은 가장 test image와 비슷한 이미지를 정렬해 찾는 방식을 사용했습니다. 그럼 가장 비슷한지 아닌지 구분하는 함수로는 L1(Manhattan) distance를 이용했습니다. 각 픽셀의 차에 절댓값을 씌운 값들의 합을 측정하는 방식입니다.
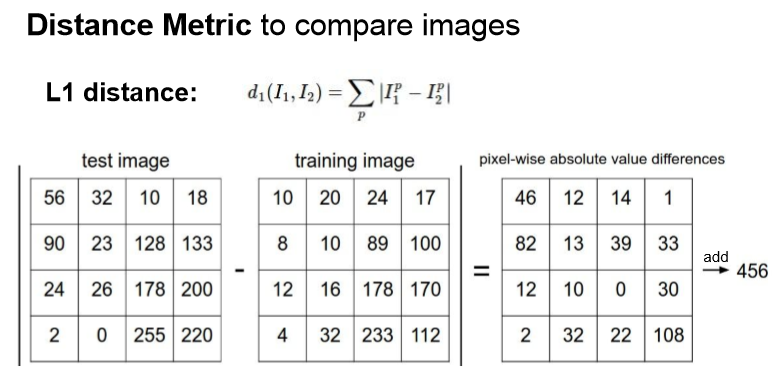
이러한 NN 알고리즘을 코드로 구현하면
import numpy as np
class NearestNeighbor:
def __init__(self):
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
for i in xrange (num_test):
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
이와 같이 작성할 수 있습니다. train에서는 들어온 이미지와 label을 저장하고 predict에서는 가장 거리가 짧은 결과를 찾습니다. 이러한 방식의 코드에는 문제점이 있습니다. 결과가 좋지 않을 뿐만 아니라 train할 때 걸리는 시간보다 test 할 때 걸리는 시간이 훨씬 길다는 점입니다. 왜냐면 train시 그냥 값을 저장만 하지만 test의 경우 n개의 데이터라 가정을 하면 n개의 데이터 전부 거리를 구해 가장 값이 작은 이미지를 찾는 방식이므로 연산 소요시간이 훨씬 길어집니다. 일반적으로 train에 걸리는 시간이 test에 걸리는 시간보다 짧길 원하는데 이 알고리즘은 그 반대의 모습을 보입니다.
이번에는 NN을 개선한 K-NN알고리즘을 알아보겠습니다.

이 알고리즘은 NN을 개선한 방식으로 distance metric를 이용해서 가까운 이웃 K개 만큼 찾고, 이웃끼리 투표를 진행해 가장 많은 표를 받은 label로 예측하는 알고리즘입니다. 위 그림을 보면 K=3의 경우, 경계선이 좀 더 완만한 모습을 볼 수 있고 초록색 지역 가운데에 존재하는 노란색 점을 초록색으로 분류하는 결과를 볼 수 있습니다. 이렇게 되면 학습 데이터에 존재하지 않는 데이터에 대한 분류 정확도가 좀 더 높아질 수 있습니다.
이번에는 L2 distance에 대해서 알아보겠습니다.

L1 distance는 각 픽셀의 차에 절대값을 씌운 값들의 합이었는데 L2(Euclidean) distance는 각 픽셀의 차에 제곱한 값들의 합에 제곱근을 씌운 값입니다. L1 distance는 좌표계를 회전시키면 값이 변합니다. 하지만 L2 distance는 좌표계에 영향을 받지 않고 값이 유지됩니다.

위 그림을 보면 K는 동일하고 L1, L2를 사용하는지 차이를 두고 그림을 그린 모습입니다. L2 distance가 좀 더 경계선이 자연스럽게 생긴 것을 볼 수 있습니다.

이번에는 하이퍼파라미터에 대해서 말해보겠습니다. K-NN의 경우 학습 전에 K와 거리의 척도를 구하는 방식을 정해줘야 합니다. 이렇게 train time에 학습하는 것이 아닌 전에 반드시 선택해야 하는 것을 하이퍼파라미터라고 합니다.
그럼 올바르게 하이퍼파라미터를 정하는 방법은 무엇이 있을까?? 만약 학습 데이터의 정확도와 성능을 최대화하는 하이퍼파라미터를 선택한다면 이는 좋지 않은 방법이 될 것입니다. 왜냐하면 우리가 구현하는 classifier는 처음 보는 데이터에 대해 정확한 예측을 하는 것이 목표이지 이미 알고 있는 데이터에 대한 결과를 좋게 하는 것은 목표가 아닙니다. train data에 대한 성능을 최대화하기 위해선 K = 1이 되면 됩니다. 하지만 전에 본 것처럼 K가 1보다 커야 좀 더 성능이 좋습니다. 최적은 하이퍼파라미터를 구하기 위해서 일단 data를 train set, validate set, test set으로 나누고 train set을 이용해 다양한 하이퍼파라미터를 이용해 학습을 진행합니다. validate set을 이용해 가장 결과가 좋았던 하이퍼파라미터를 선택하고 이 값을 이용해 test set을 통해 결과를 예측하는 방식이 가장 좋은 방식입니다.
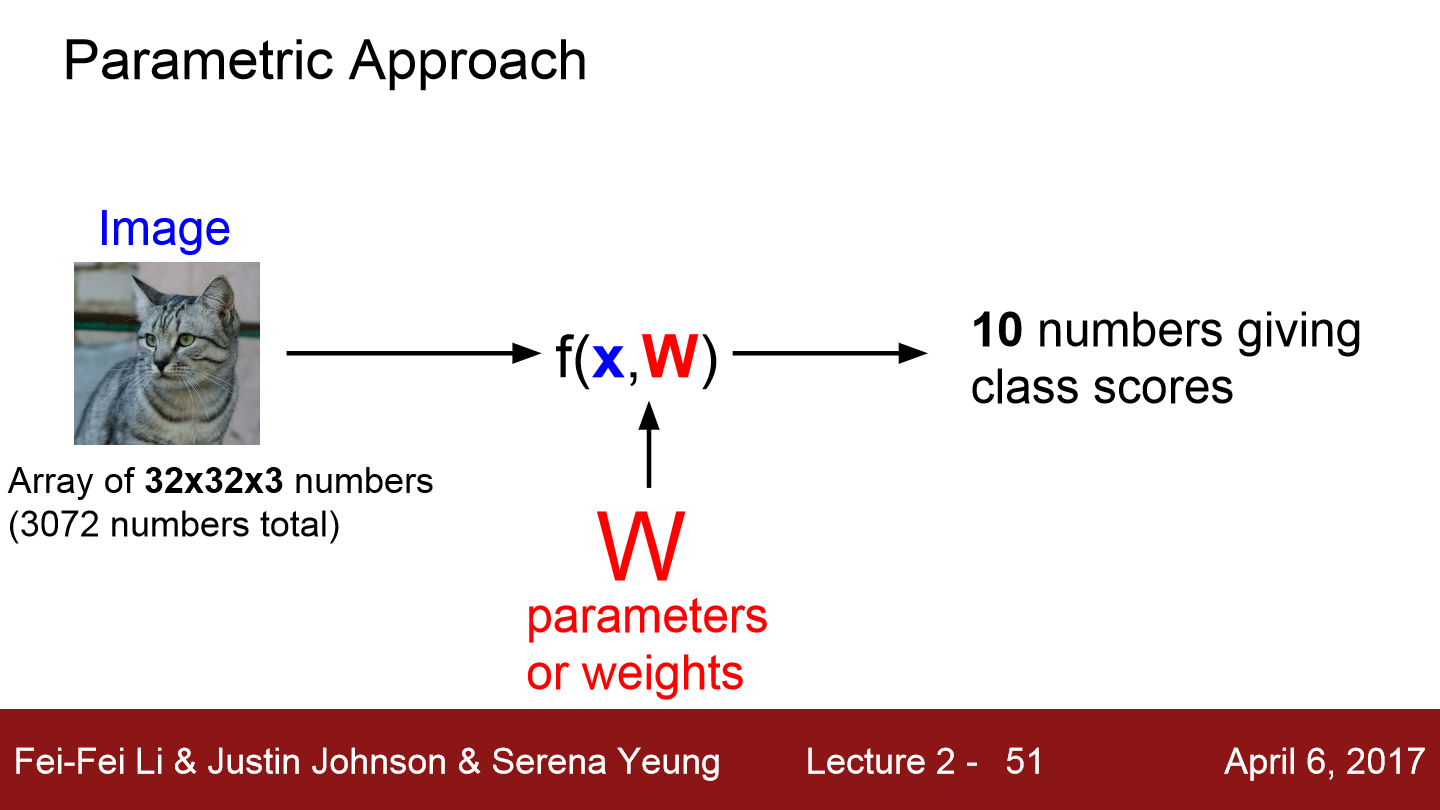
이번에는 Linear Classification에 대한 설명입니다. 일단 이 강의에서 사용하는 CIFAR-10 데이터는 한 이미지당 32x32의 크기를 갖고 3 channel color 이미지입니다. 위 식을 보면 input image는 x로 표현되고 파라미터, 즉 가중치는 W로 표현됩니다. 이 classifier의 결과는 10개의 숫자가 나오는데 이는 각 카테고리에 대한 스코어라 볼 수 있습니다.

input image 데이터를 한 줄로 쭉 펴 3072x1 크기의 행렬로 표현할 수 있고 결과를 10x1로 출력하기 위해서 W는 10x3072가 됩니다.

간단한 예시를 보면 위 그림은 input image가 2x2 크기를 갖고 3가지의 class로 점수를 출력합니다. 그렇기 때문에 W는 위와 같이 생겼습니다.

만약 위 그림과 같이 고차원 이미지 한 장을 하나의 점으로 표현을 한다면 linear classfier는 각 클래스를 구분시켜주는 선형 결정 경계를 그어주는 역할을 할 것입니다.

그럼 만약 데이터 분포가 위와 같이 되어 있다면 선형방식으로 분류하는 것은 불가능합니다. Linear classifier는 이와 같은 한계를 갖고 있습니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
|---|---|
| Lecture 6. Training Neural Networks, Part1 (0) | 2022.05.08 |
| Lecture 5. Convolutional Neural Networks (0) | 2022.05.04 |
| Lecture 4. Backpropagation and Neural Networks (0) | 2022.05.02 |
| Lecture 3. Loss Functions and Optimization (0) | 2022.05.01 |



