이번 CS231n 3장의 내용은 loss function과 optimization에 관련된 내용입니다.

위 예시를 보면 일단 3장의 train set이 존재하고 3 class가 존재합니다. 그리고 input image에 대해 각 class 점수들이 작성되어 있습니다. 고양이 사진의 경우 정답 레이블인 고양이는 3.2점이 기록되어 있고 자동차 사진의 경우 4.9점이 기록되어 있습니다. 위 식을 보면 x가 있는데 여기서 x는 주로 input을 의미합니다. 우리는 이미지 분류 알고리즘에 대해서 알아보고 있으니 input image가 됩니다. y는 주로 label 또는 target이라고 하며 CIFAR-10 같은 경우 1에서 10 또는 0에서 9 사이의 값을 갖습니다. L_i가 의미하는 것은 손실 함수인데 예측 함수 f의 결과값과 정답 y를 입력으로 받아서 training sample이 얼마나 틀리게 예측하는지 정량화해줍니다. 최종 Loss인 L은 우리 dataset에서 각 N개의 샘플들의 Loss들의 평균이 됩니다. train을 통해 Loss를 최소화하는 W를 찾습니다.

먼저 Loss function으로 Muticlass SVM을 알아보겠습니다. L_i를 구하기 위해 사진에 대한 참인 카테고리를 제외한 나머지 카테고리 y의 합을 구합니다. 즉 맞지 않는 카테고리를 전부 합칩니다. 그리고 올바른 카테고리의 스코어와 올바르지 않은 카테고리의 스코어를 비교합니다. 만약 올바른 카테고리의 점수가 올바르지 않은 카테고리의 점수보다 높고 그 격차가 일정 margin(위 예에서는 1)이상이면 올바른 경우의 점수가 틀린 경우의 점수보다 훨씬 크다는 것을 의미하고 이렇게 되면 Loss는 0이 됩니다. 이 과정을 모든 train dataset에 거쳐 평균을 구하면 최종 Loss가 나옵니다.

예를 들어 고양이 사진에 대한 결과를 보면 위 식과 같습니다.

자동차의 경우 정답 카테고리의 점수가 오답 카테고리의 점수보다 margin 이상으로 크기 때문에 오차가 0이 나오는 모습을 볼 수 있습니다.

개구리의 오차까지 전부 구하고 최종 Loss를 구하면 5.27이라는 값이 나옵니다.
만약

이 질문과 같이 자동차 점수가 살짝 변경된다면 과연 오차는 변할까??
아니다 자동차의 경우 정답 점수가 다른 오답 점수보다 훨씬 크기 때문에 조금 값이 줄어든다 해도 Loss에는 변화가 일어나지 않습니다.

그럼 이번 질문과 같이 W가 작아서 모든 s가 거의 0과 같다면 Loss는 어떤 값을 가질까??
Loss를 계산할 때 정답이 아닌 오답 클래스들을 순회합니다. 그러면 C-1개의 클래스를 순회하는데 비교하는 두 스코어가 거으 비슷하니 차는 margin과 같을 값이 될 것이고 결과는 C-1이 됩니다.

마지막으로 L_i가 이와 같이 변경된다면 값은 어떻게 될까??
차이가 큰 값은 더 커지고 차이가 작은 값은 더 작아집니다.
이러한 Multiclass SVM을 코드로 표현하면
def L_i_vectorized(x, y, W):
scores = W.dot(x)
margins = np.maximum(0, (scores - scores[y] + 1))
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
이와 같이 작성할 수 있습니다.
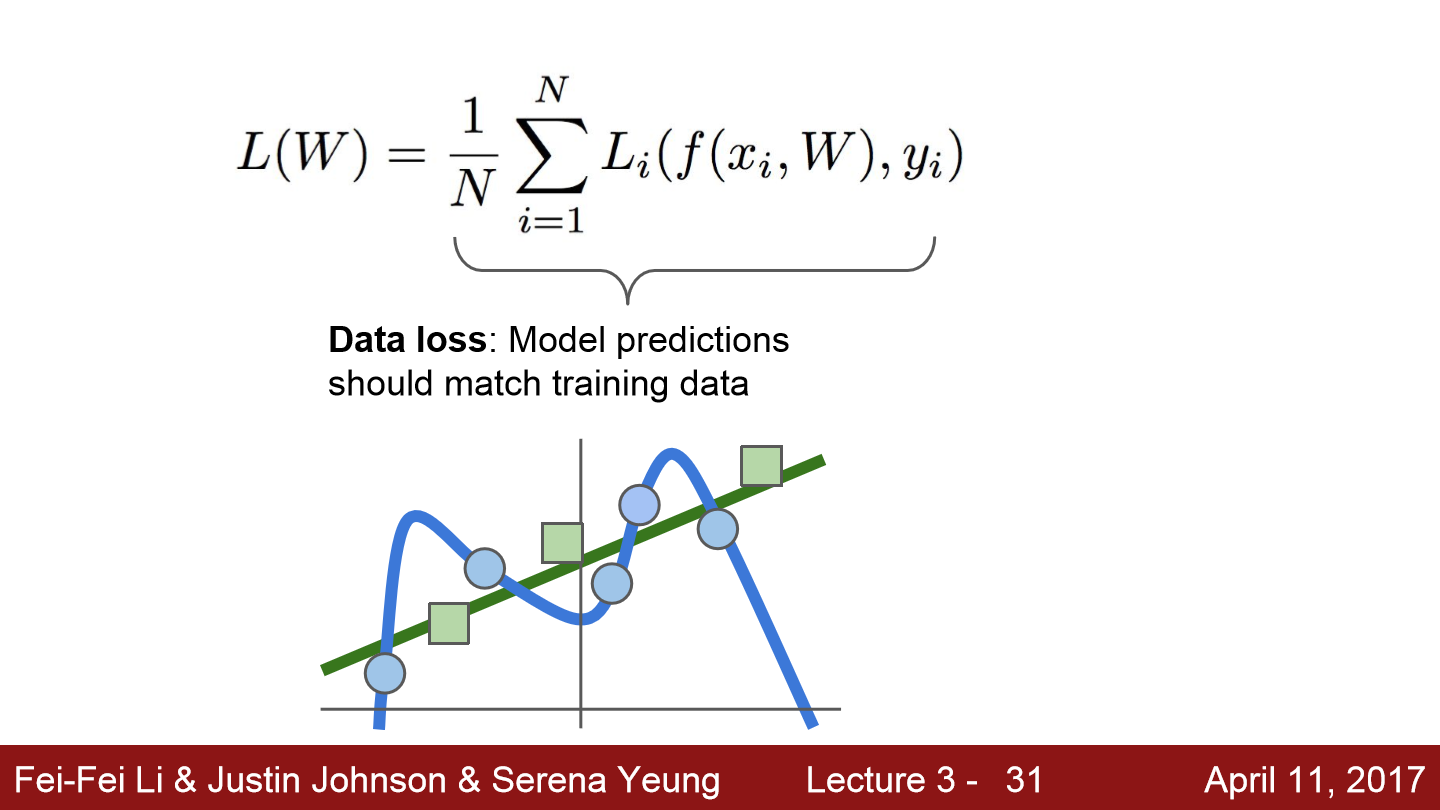
위 그림에서 파란색 점은 train dataset이고 초록색 점은 test dataset입니다. train을 통해 train data에 대해서는 오차 없이 분류하는 상태가 된 모습입니다. 이는 절대 좋지 않은 상태입니다. 우리는 처음 보는 이미지를 넣어 분류하는 model을 만드는 것이지 train data를 잘 분류하는 model을 만드는 것이 아닙니다. 이렇게 overfitting 되는 것을 막기 위해 정규화(Regularization)라는 개념이 도입됩니다.

위 식과 같이 Loss를 구할 때 정규화를 더하는 모습입니다. 여기서 쓰이는 정규화에는 여러 종류가 있습니다.

위와 같이 여러 종류가 있습니다. 정규화에 존재하는 λ는 얼마나 정규화를 할 지 정도를 의미하고 이는 하이퍼파라미터입니다. 즉 train 전에 정해줘야 하는 값입니다. regularization은 모델이 train dataset에 완벽히 fit하지 못하도록 모델의 복잡도에 페널티를 부여하는 방식입니다.
어떤 regularization 방식을 사용할 지는 내가 만드는 model에 따라 다릅니다. 모델이 어떤 방식으로 복잡도를 측정하는지를 파악해 사용하는 것이 좋습니다. 예를 들어 L1 regularization의 경우 W에 0의 개수에 따라 복잡도를 다루고 L2 regularization의 경우 W의 데이터가 골고루 분포되어 있나에 따라 복잡도를 다룹니다.

이번에는 Softmax classifier에 대해서 알아보겠습니다. 위 식에서 P의 우측항이 softmax 식이 됩니다. 전체 스코어에 지수를 취한 값의 합이 분모가 되고 정답 스코어에 지수를 취한 값이 분자가 되어 정답일 확률이 됩니다. 우리는 모델이 얼마나 틀리는지를 측정하기 때문에 정답일 확률 P가 1에 가까울수록 L_i는 0에 가까운 값을 갖습니다.

위 예를 보면 좀 더 명확하게 이해할 수 있습니다. 모든 클래스의 점수를 지수화하는 과정을 거쳐 정답 레이블에 대한 확률을 구하는 모습입니다. SVM은 정답 스코어와 정답이 아닌 스코어 간의 margin을 신경 쓰는 방식이었지만 Softmax는 확률을 구해 정답 레이블일 확률에 신경을 씁니다.
이번에는 Optimization에 대해서 알아보겠습니다. 최적화를 의미하는 이 부분은 처음에 미분에 대해서 설명을 합니다.

이와 같이 W가 있고 이에 대한 오차도 있습니다. W의 첫번째 값에 아주 작은 값 h를 더한 후 다시 오차를 구합니다. 두 오차의 차를 h로 나눈 값이 미분 값이 되며 이 예에서 -2.5가 됩니다. 이와 같은 방법을 반복해 모든 W에 대한 미분 값을 구할 수 있습니다. 해당 dW 방향으로 이동을 하면 좀 더 오차값이 작도록 이동하는 모습이 될 것입니다. 하지만 이와 같은 방식으로 하나하나 직접 다 미분하는 것은 좀 더 복잡한 구조에서는 시간이 너무 오래 걸리기 때문에 비효율적입니다.

Gradient Descent는 우선 W를 임의의 값으로 초기화한 후 Loss와 gradient를 계산한 뒤에 가중치를 gradient의 반대 방향으로 업데이트 합니다. -gradient 방향으로 아주 조금씩 이동하다 보면 언젠간 수렴하는 값에 도달하게 됩니다. 위에서 말하는 step_size는 learning rate라고도 불리며 이 값도 하이퍼파라미터입니다.

마지막으로 Stochastic Gradient Descent(SGD)에 대해서 알아보겠습니다. train dataset 전체의 gradient와 loss를 계산하면 너무 많은 시간이 걸립니다. 이 문제를 해결하기 위해 minibatch라는 작은 training sample들로 나눠서 학습을 진행합니다. 이 작은 minibatch들을 이용해서 loss의 전체 합의 추정치와 실제 gradient의 추정치를 계산합니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 7. Training Neural Networks, Part 2 (0) | 2022.05.10 |
|---|---|
| Lecture 6. Training Neural Networks, Part1 (0) | 2022.05.08 |
| Lecture 5. Convolutional Neural Networks (0) | 2022.05.04 |
| Lecture 4. Backpropagation and Neural Networks (0) | 2022.05.02 |
| Lecture 2. Image Classification (0) | 2022.05.01 |



