이 글은 '파이썬으로 만드는 OpenCV 프로젝트'를 보고 작성했습니다.
4.1 관심영역
이미지에서 본인이 관심 있는 영역만 잘라내서 연산을 하면 연산할 데이터의 양도 줄고 수행 시간도 단축됩니다.
■ 관심영역(Region Of Interesting, ROI) 지정
전체 이미지에서 연산과 분석의 대상이 되는 영역만을 지정하고 떼어내는 것을 관심영역을 지정한다고 합니다.
전체 이미지 img라는 변수가 있을 때, 관심 있는 영역의 좌표가 x, y이고 영역의 폭이 w, 높이가 h라고 하면 관심영역 roi는
roi = img[y:y+h, x:x+w]
로 표현 가능합니다. 이 코드는 원본 이미지를 y부터 y+h까지, x부터 x+w까지 슬라이싱한 코드입니다.
import cv2
import numpy as np
img = cv2.imread('../img/sunset.jpg')
x=320; y=150; w=50; h=50 # roi 좌표
roi = img[y:y+h, x:x+w] # roi 지정 ---①
print(roi.shape) # roi shape, (50,50,3)
cv2.rectangle(roi, (0,0), (h-1, w-1), (0,255,0)) # roi 전체에 사각형 그리기 ---②
cv2.imshow("img", img)
key = cv2.waitKey(0)
print(key)
cv2.destroyAllWindows()위 코드는 roi 영역을 지정해 사각형을 그리는 코드입니다.
■ 마우스로 관심영역 지정
마우스 이벤트를 적용하면 쉽게 마우스로 관심영역을 지정할 수 있습니다.
import cv2
import numpy as np
isDragging = False # 마우스 드래그 상태 저장
x0, y0, w, h = -1,-1,-1,-1 # 영역 선택 좌표 저장
blue, red = (255,0,0),(0,0,255) # 색상 값
def onMouse(event,x,y,flags,param): # 마우스 이벤트 핸들 함수 ---①
global isDragging, x0, y0, img # 전역변수 참조
if event == cv2.EVENT_LBUTTONDOWN: # 왼쪽 마우스 버튼 다운, 드래그 시작 ---②
isDragging = True
x0 = x
y0 = y
elif event == cv2.EVENT_MOUSEMOVE: # 마우스 움직임 ---③
if isDragging: # 드래그 진행 중
img_draw = img.copy() # 사각형 그림 표현을 위한 이미지 복제
cv2.rectangle(img_draw, (x0, y0), (x, y), blue, 2) # 드래그 진행 영역 표시
cv2.imshow('img', img_draw) # 사각형 표시된 그림 화면 출력
elif event == cv2.EVENT_LBUTTONUP: # 왼쪽 마우스 버튼 업 ---④
if isDragging: # 드래그 중지
isDragging = False
w = x - x0 # 드래그 영역 폭 계산
h = y - y0 # 드래그 영역 높이 계산
print("x:%d, y:%d, w:%d, h:%d" % (x0, y0, w, h))
if w > 0 and h > 0: # 폭과 높이가 음수이면 드래그 방향이 옳음 ---⑤
img_draw = img.copy() # 선택 영역에 사각형 그림을 표시할 이미지 복제
# 선택 영역에 빨간 사각형 표시
cv2.rectangle(img_draw, (x0, y0), (x, y), red, 2)
cv2.imshow('img', img_draw) # 빨간 사각형 그려진 이미지 화면 출력
roi = img[y0:y0+h, x0:x0+w] # 원본 이미지에서 선택 영영만 ROI로 지정 ---⑥
cv2.imshow('cropped', roi) # ROI 지정 영역을 새창으로 표시
cv2.moveWindow('cropped', 0, 0) # 새창을 화면 좌측 상단에 이동
cv2.imwrite('./cropped.jpg', roi) # ROI 영역만 파일로 저장 ---⑦
print("croped.")
else:
cv2.imshow('img', img) # 드래그 방향이 잘못된 경우 사각형 그림ㅇㅣ 없는 원본 이미지 출력
print("좌측 상단에서 우측 하단으로 영역을 드래그 하세요.")
img = cv2.imread('../img/sunset.jpg')
cv2.imshow('img', img)
cv2.setMouseCallback('img', onMouse) # 마우스 이벤트 등록 ---⑧
cv2.waitKey()
cv2.destroyAllWindows()
마우스 이벤트 처리를 적용해서 마우스로 관심영역을 지정하고 잘라낸 부분만 새 창에 표시하고 파일로 저장하는 코드입니다.

실행 결과는 이와 같이 나옵니다. 제가 드래그한 부분이 새로운 창에 그려지고 좌표도 출력되는 것을 볼 수 있습니다.
위 코드는 onMouse 함수를 마우스 콜백으로 등록하고 세 가지 이벤트에 따라 분기합니다. 마우스 왼쪽 버튼이 눌렸을 때 반응합니다. 처음 마우스를 드래그하는 지점을 x0, y0 전역변수에 저장하고 isDragging을 True로 변경합니다. 마우스를 드래그해 파란색 사각형을 그립니다. img.copy()에 사각형을 그리기 때문에 드래그할 때 마다 새로운 사각형이 그려집니다. 마지막으로 왼쪽 마우스 버튼을 손에서 뗄 때 최종 좌표를 구해 w, h를 구하고 새로운 창에 그립니다.
이번에는 위와 같은 기능을 하는 OpenCV 3에서 제공하는 함수에 대해서 알아보겠습니다. 이 함수를 이용하면 마우스 이벤트 처리를 위한 코드 없이도 마우스로 간단히 ROI를 지정할 수 있습니다.
- ret = cv2.selectROI([win_name, ] img [, showCrossHair = True, fromCenter = False])
- win_name: ROI 선택을 진행할 창의 이름, str
- img: ROI 선택을 진행할 이미지, Numpy ndarray
- showCrossHair: 선택 영역 중심에 십자 모양 표시 여부
- fromCenter: 마우스 시작 지점을 영역의 중심으로 지정
- ret: 선택한 영역 좌표와 크기 (x, y, w, h), 선택을 취소한 경우 모두 0
영역을 선택하고 나서 키보드의 스페이스 또는 엔터 키를 누르면 선택한 영역의 x, y 좌표와 영역의 폭과 높이를 튜플에 담아 반환합니다. 만약 선택을 취소하고 싶으면 키보드의 'c' 키를 누르면 됩니다.
4.2 컬러 스페이스
■ 디지털 영상의 종류
디지털화된 이미지는 픽셀(pixel, 화소)이라는 단위가 여러 개 모여서 그림을 표현합니다. 픽셀을 어떻게 구성하느냐에 따라 이미지를 구분할 수 있습니다.
바이너리(binary, 이진) 이미지의 경우 한 개의 픽셀을 두 가지 값으로만 표현합니다. 주로 0 또는 1, 0 또는 255를 사용합니다. 흑백으로 이미지를 표현할 때 사용하는데 표현할 수 있는 값이 두 가지밖에 없어서 값으로는 명암을 표현할 수 없고, 점의 밀도로 명암을 표현할 수 있습니다.
그레이 스케일 이미지는 우리가 흔히 아는 흑백 사진을 의미합니다. 그레이 스케일 이미지는 한 개의 픽셀을 0 ~ 255의 값으로 표현합니다. 픽셀 값의 크기로 명암을 표현하는데, 가장 작은 값인 0은 가장 어두운 검은색, 점점 커질수록 밝은 색을 의미하다가 255까지 가면 가장 밝은 흰색을 나타냅니다.
컬러 이미지는 표현 방법이 다양합니다. 색상을 표현하는 방법에 따라 다르기는 하지만, 흔히 컬러 이미지는 한 픽셀당 0 ~ 255의 값 3개를 조합해서 표현합니다. 각 바이트마다 어떤 색상 표현의 역할을 맡을지를 결정하는 시스템을 컬러 스페이스(color space, 색공간)라고 합니다. 컬러 스페이스의 종류는 RGB, HSV, YUV(YCbCr), CMYK 등 여러 가지가 있습니다.
■ RGB, BGR, RGBA
RGB는 빛의 3원소인 빨강, 초록, 파랑 세 가지 색의 빛을 섞어서 원하는 색을 표현합니다. 각 색상은 0 ~ 255 범위로 표현하고 값이 커질수록 해당 색상의 빛이 밝아지는 원리로 색상의 값이 모두 255일 때 흰색으로 표현되고 모든 색상 값이 0일 때 검은색이 표현됩니다. 세 가지 색상을 표현하므로 RGB 이미지는 3차원 배열(row x column x color)로 표현됩니다.
영상의 크기에 해당하는 행(row, height)과 열(column, width)에 세 가지 색상을 표현하는 차원이 추가되는데, 이를 채널(channel)이라 합니다. OpenCV는 RGB와 순서가 반대인 BGR을 사용합니다.
RGBA는 배경을 투명 처리하기 위해 알파(alpha) 채널을 추가한 것을 말합니다. 4번째 채널의 값은 0 ~ 255로 표현할 수 있지만, 배경의 투명도를 표현하기 위해서는 0과 255만 사용한느 경우가 많습니다. cv2.IMREAD_COLOR인 경우 BGR로 읽어들이고, cv2.IMREAD_UNCHANGED인 경우 대상 이미지가 알파 채널을 가지고 있다면 RGBA로 읽어 들입니다.
import cv2
import numpy as np
# 기본 값 옵션
img = cv2.imread('../img/opencv_logo.png')
# IMREAD_COLOR 옵션
bgr = cv2.imread('../img/opencv_logo.png', cv2.IMREAD_COLOR)
# IMREAD_UNCHANGED 옵션
bgra = cv2.imread('../img/opencv_logo.png', cv2.IMREAD_UNCHANGED)
# 각 옵션에 따른 이미지 shape
print("default", img.shape, "color", bgr.shape, "unchanged", bgra.shape)
cv2.imshow('bgr', bgr)
cv2.imshow('bgra', bgra)
cv2.imshow('alpha', bgra[:,:,3]) # 알파 채널만 표시
cv2.waitKey(0)
cv2.destroyAllWindows()실행 결과는 아래와 같습니다.

옵션을 따로 지정하지 않은 기본 옵션과 cv2.IMREAD_COLOR 옵션의 shape가 (120, 98, 3)으로 동일한 것을 볼 수 있습니다. 두 그림은 투명한 배경이 검은색으로 표시되었고 로고 아래의 글씨도 검은색이다 보니 글씨가 보이지 않습니다. cv2.IMREAD_UNCHANGED 옵션으로 읽은 이미지는 shape가 (240, 195, 4)로 마지막 채널이 하나 더 있는 것을 알 수 있습니다. 이 옵션으로 읽은 이미지의 마지막 채널(배경)만 출력하면 위와 같이 로고와 글씨만 흰색으로 표현되고 배경은 검은색입니다. 배경은 0, 전경은 255의 값을 갖습니다. 이 알파 채널의 정보를 이용하면 전경과 배경을 손쉽게 분리할 수 있어서 마스크 채널(mask channel)이라고도 부릅니다.
■ 컬러 스페이스 변환
그레이 스케일이나 다른 컬러 스페이스로 변환하는 방법은 변환 알고리즘을 직접 구현할 수도 있고, OpenCV에서 제공하는 cv2.cvtColor() 함수를 이용할 수도 있습니다.
import cv2
import numpy as np
img = cv2.imread('../img/girl.jpg')
img2 = img.astype(np.uint16) # dtype 변경 ---①
b,g,r = cv2.split(img2) # 채널 별로 분리 ---②
#b,g,r = img2[:,:,0], img2[:,:,1], img2[:,:,2]
gray1 = ((b + g + r)/3).astype(np.uint8) # 평균 값 연산후 dtype 변경 ---③
gray2 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # BGR을 그레이 스케일로 변경 ---④
cv2.imshow('original', img)
cv2.imshow('gray1', gray1)
cv2.imshow('gray2', gray2)
cv2.waitKey(0)
cv2.destroyAllWindows()위 코드를 보면 3채널의 평균 값을 구해서 그레이 스케일로 변경하는 방법과 cvt.Color함수를 사용해 그레이 스케일로 변경하는 방법을 사용했습니다. img의 dtype을 np.uint16으로 변경한 이유는 덧셈의 결과가 255를 넘어갈 수 있어서 변경했고 다시 uint8로 변경해 사용합니다.
cv2.cvtColor()함수에 대한 설명을 하겠습니다.
- out = cv2.cvtColor(img, flag)
- img: Numpy 배열, 변환할 이미지
- flag: 변환할 컬러 스페이스, cv2.COLOR_로 시작하는 이름(274개)
- cv2.COLOR_BGR2GRAY: BGR 컬러 이미지를 그레이 스케일로 변환
- cv2.COLOR_GRAY2BGR: 그레이 스케일 이미지를 BGR 컬러 이미지로 변환
- cv2.COLOR_BGR2RGB: BGR 컬러 이미지를 RGB 컬러 이미지로 변환
- cv2.COLOR_BGR2HSV: BGR 컬러 이미지를 HSV 컬러 이미지로 변환
- out: 변환한 결과 이미지(Numpy 배열)
사실 flag 상수는 200개가 넘는데 이 책에서 주로 사용하는 flag는 위와 같습니다. cv2.COLOR_GRAY2BGR 플래그는 그레이 스케일을 BGR 스케일로 변환하는데, 실제로 흑백 사진을 컬러 사진으로 바꿔주는 것은 아닙니다. 2차원 배열 이미지를 3개 채널이 모두 같은 값을 갖는 3차원 배열로 변환하는 것입니다. 이 플래그는 영상 간에 연산을 할 때 서로 차원이 다르면 연산을 할 수 없으므로 차원을 맞추는 용도로 주로 사용합니다.
■ HSV, HSI, HSL
HSV 포멧은 RGB와 마찬가지로 3채널로 컬러 이미지를 표시합니다. 각각 H(Hue, 색조), S(Saturation, 채도), V(Value, 명도)입니다. 이때 명도를 표현하는 방법에 따라 마지막 V를 I(Intensity, 밀도)로 표현하는 HSI, 그리고 L(Lightness, 명도)로 표기하는 HSL 컬러 시스템도 있습니다.
H는 픽셀이 어떤 색인지를 표현합니다 .원 위에 빨강에서 시작해서 노랑, 초록, 파랑을 거쳐 다시 빨강으로 돌아오는 방식으로 색상에 매칭되는 숫자를 매겨놓고 그 360˚ 범위의 값을 갖게 해서 색을 표현합니다. 하지만 OpenCV에서 영상을 표현할 때 사용하는 배열의 dtype은 최대 값이 255를 넘지 못하므로 360을 반으로 나누어 0 ~ 180 범위의 값으로 표현하고 180보다 큰 값인 경우에는 180으로 간주합니다. 165 ~ 180, 0 ~ 15는 빨강, 45 ~ 75는 초록, 90 ~ 120은 파랑을 의미합니다.
S값은 채도, 포화도, 또는 순도로 해석할 수 있는데, 해당 색상이 얼마나 순수하게 포함되어 있는지를 표현합니다. S 값은 0 ~ 255 범위로 표현하며, 255는 가장 순수한 색상을 표현합니다.
V값은 명도로서 빛이 얼마나 밝은지 어두운지를 표현하는 값입니다. 이 값도 범위가 0 ~ 255이며, 255인 경우가 가장 밝은 상태이고 0인 경우가 가장 어두운 상태로 검은색이 표시됩니다.
import cv2
import numpy as np
#---① BGR 컬러 스페이스로 원색 픽셀 생성
red_bgr = np.array([[[0,0,255]]], dtype=np.uint8) # 빨강 값만 갖는 픽셀
green_bgr = np.array([[[0,255,0]]], dtype=np.uint8) # 초록 값만 갖는 픽셀
blue_bgr = np.array([[[255,0,0]]], dtype=np.uint8) # 파랑 값만 갖는 픽셀
yellow_bgr = np.array([[[0,255,255]]], dtype=np.uint8) # 노랑 값만 갖는 픽셀
#---② BGR 컬러 스페이스를 HSV 컬러 스페이스로 변환
red_hsv = cv2.cvtColor(red_bgr, cv2.COLOR_BGR2HSV);
green_hsv = cv2.cvtColor(green_bgr, cv2.COLOR_BGR2HSV);
blue_hsv = cv2.cvtColor(blue_bgr, cv2.COLOR_BGR2HSV);
yellow_hsv = cv2.cvtColor(yellow_bgr, cv2.COLOR_BGR2HSV);
#---③ HSV로 변환한 픽셀 출력
print("red:",red_hsv)
print("green:", green_hsv)
print("blue", blue_hsv)
print("yellow", yellow_hsv)
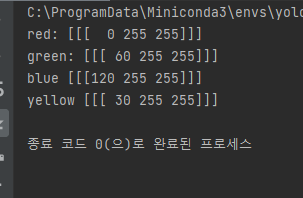
실행 결과를 보면 BGR이 HSV로 변환된 결과를 보여줍니다. 픽셀의 색상이 궁금한 경우 HSV를 이용하면 H만 확인하면 되기 때문에 효율적입니다.
■ YUV, YCbCr
YUV 포멧은 사람이 색상을 인식할 때 밝기에 더 민감하고 색상은 상대적으로 둔감한 점을 고려해서 만든 컬러 스페이스입니다. Y는 밝기(Luma)를 표현하고, U(Chroma Blue, Cb)는 밝기와 파란색과의 색상 차, V(Chroma Red, Cr)는 밝기와 빨간색과의 색상차를 표현합니다. Y(밝기)에는 많은 비트수를 할당하고 U(Cb)와 V(Gr)에는 적은 비트 수를 할당해서 데이터를 압축하는 효과를 갖습니다. YUV라는 용어는 TV 방송에서 사용하는 아날로그 컬러 인코딩 시스템인 PAL(Phase Alternating Line)에서 정의한 용어입니다. YUV는 종종 YCbCr 포멧과 혼용되기도 하는데, 본래 YUV는 텔레비전 시스템에서 아날로그 컬러 정보를 인코딩하는 데 사용하고 YCbCr 포멧은 MPEG나 JPEG와 같은 디지털 컬러 정보를 인코딩하는 데 사용하였습니다.
4.3 스레시홀딩
스레시홀딩(thresholding)이란 여러 점수를 커트라인을 기준으로 합격과 불합격으로 나누는 것처럼 여러 값을 경계점을 기준으로 두 가지 부류로 나누는 것으로, 바이너리 이미지를 만드는 가장 대표적인 방법입니다.
■ 전역 스레시홀딩
바이너리 이미지를 만들기 위해서는 컬러 이미지를 그레이 스케일로 바꾸고 각 픽셀의 값이 경계 값을 넘으면 255, 넘지 못하면 0을 지정합니다. 이런 작업은 간단한 Numpy 연산만으로도 충분히 할 수 있지만, OpenCV는 cv2.threshold() 함수로 더 많은 기능을 제공합니다.
import cv2
import numpy as np
import matplotlib.pylab as plt
img = cv2.imread('../img/gray_gradient.jpg', cv2.IMREAD_GRAYSCALE) #이미지를 그레이 스케일로 읽기
# --- ① NumPy API로 바이너리 이미지 만들기
thresh_np = np.zeros_like(img) # 원본과 동일한 크기의 0으로 채워진 이미지
thresh_np[ img > 127] = 255 # 127 보다 큰 값만 255로 변경
# ---② OpenCV API로 바이너리 이미지 만들기
ret, thresh_cv = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
print(ret) # 127.0, 바이너리 이미지에 사용된 문턱 값 반환
# ---③ 원본과 결과물을 matplotlib으로 출력
imgs = {'Original': img, 'NumPy API':thresh_np, 'cv2.threshold': thresh_cv}
for i , (key, value) in enumerate(imgs.items()):
plt.subplot(1, 3, i+1)
plt.title(key)
plt.imshow(value, cmap='gray')
plt.xticks([]); plt.yticks([])
plt.show()
실행 결과는
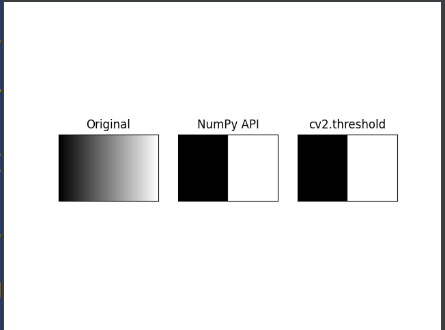
이런 이미지를 보여줍니다. 검은색에서 흰색으로 점점 변하는 그라데이션 이미지를 그레이 스케일로 읽어서 바이너리 이미지로 만드는 예제입니다. 원본 이미지와 같은 크기이면서 0으로 채워진 Numpy 배열을 생성하고 나서 127보다 큰 값을 갖는 요소에 255를 할당하는 연산을 해서 바이너리 이미지로 만들었습니다. 다음 코드는 cv2.threshold() 함수를 이용해 간단한 바이너리 이미지를 만들었습니다.
- ret, out = cv2.threshold(img, threshold, value, type_flag)
- img: Numpy 배열, 변환할 이미지
- threshold: 경계 값
- value: 경계 값 기준에 만족하는 픽셀에 적용할 값
- type_flag: 스레시홀드 적용 방법 지정
- cv2.THRESH_BINARY: px > threshold ? value : 0, 픽셀 값이 threshold를 넘으면 value를 지정하고, 넘지 못하면 0을 지정
- cv2.THRESH_TRUNC: px > threshold ? threshold : px, 픽셀 값이 threshold를 넘으면 경계 값을 지정하고, 넘지 못하면 원래 값 유지
- cv2.THRESH_TOZERO: px > threshold ? px: 0, 픽셀 값이 threshold를 넘으면 원래 값을 유지하고, 넘지 못하면 0을 지정
- cv2.THRESH_TOZERO_INV: px > threshold ? 0 : px, THRESH_TOZERO의 반대
- ret: 스레시홀딩에 사용한 경계 값
- out: 결과 바이너리 이미지
import cv2
import numpy as np
import matplotlib.pylab as plt
img = cv2.imread('../img/gray_gradient.jpg', cv2.IMREAD_GRAYSCALE)
_, t_bin = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
_, t_bininv = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY_INV)
_, t_truc = cv2.threshold(img, 127, 255, cv2.THRESH_TRUNC)
_, t_2zr = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO)
_, t_2zrinv = cv2.threshold(img, 127, 255, cv2.THRESH_TOZERO_INV)
imgs = {'origin': img, 'BINARY': t_bin, 'BINARY_INV': t_bininv, \
'TRUNC': t_truc, 'TOZERO': t_2zr, 'TOZERO_INV': t_2zrinv}
for i, (key, value) in enumerate(imgs.items()):
plt.subplot(2, 3, i + 1)
plt.title(key)
plt.imshow(value, cmap='gray')
plt.xticks([]);
plt.yticks([])
plt.show()위 코드의 실행 결과는

이와 같습니다. 플래그 상수를 변경하면서 다양한 cv2.threshold() 결과를 보여주고 있습니다.
■ 오츠의 알고리즘
바이너리 이미지를 만들 때 가장 중요한 작업은 경계 값을 얼마로 정하느냐입니다. 종이에 출력한 문서를 바이너리 이미지로 만드는 것을 예를 들면, 새하얀 종이에 검은색으로 출력된 문서의 영상이라면 굳이 스레시홀드를 적용할 필요가 없습니다. 하지만, 실제로는 흰색, 노란색, 회색 종이에 검은색, 파란색 등으로 인쇄된 문서가 더 많기 때문에 적절한 경계 값을 정하기 위해서는 여러 차례에 걸쳐 경계 값을 조금씩 수정해 가면서 가장 좋은 경계 값을 찾아야 합니다.
1979년 오츠 노부유키(Nobuyuki Otsu)는 반복적인 시도 없이 한 번에 효율적으로 경계 값을 찾을 수 있는 방법을 제안했는데, 그의 이름을 따서 그것을 오츠의 이진화 알고리즘(Otsu's binarization method)이라고 합니다. 오츠의 알고리즘은 경계 값을 임의로 정해서 픽셀들을 두 부류로 나누고 두 부류의 명암 분포를 반복해서 구한 다음 두 부류의 명암 분포를 가장 균일하게 하는 경계 값을 선택합니다.
OpenCV에서는 이미 구현한 오츠의 알고리즘을 사용할 수 있게 제공해 주는데, cv2.threshold() 함수의 마지막 인자에 cv2.THRESH_OTSU를 추가해서 전달하면 됩니다. 그럼 원래 경계 값을 전달해야 하는 두 번째 인자 threshold는 무시되므로 아무 숫자나 전달해도 되고, 실행 후 결과 값으로 오츠의 알고리즘에 의해 선택된 경계 값은 반환 값 첫 번째 항목 ret로 받을 수 있습니다.
import cv2
import numpy as np
import matplotlib.pylab as plt
# 이미지를 그레이 스케일로 읽기
img = cv2.imread('../img/scaned_paper.jpg', cv2.IMREAD_GRAYSCALE)
# 경계 값을 130으로 지정 ---①
_, t_130 = cv2.threshold(img, 130, 255, cv2.THRESH_BINARY)
# 경계 값을 지정하지 않고 OTSU 알고리즘 선택 ---②
t, t_otsu = cv2.threshold(img, -1, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
print('otsu threshold:', t) # Otsu 알고리즘으로 선택된 경계 값 출력
imgs = {'Original': img, 't:130':t_130, 'otsu:%d'%t: t_otsu}
for i , (key, value) in enumerate(imgs.items()):
plt.subplot(1, 3, i+1)
plt.title(key)
plt.imshow(value, cmap='gray')
plt.xticks([]); plt.yticks([])
plt.show()이 코드를 보면 이미지를 직접 threshold를 130으로 지정해 cv2.threshold()를 진행하는 방식과 cv2.threshold(.., cv2.THRESH_OTSU)를 통해 오츠 알고리즘을 사용해 진행하는 방식이 있습니다. 오츠 알고리즘을 사용한 결과 threshold 값은 자동으로 131이 되는 모습을 보여줍니다. 오츠 알고리즘은 모든 경우의 수에 대해 경계 값을 조사해야 하므로 속도가 빠르지 못하다는 단점이 있습니다. 또한 노이즈가 많은 영상에는 오츠의 알고리즘을 적용해도 좋은 결과를 얻지 못하는 경우가 있고 이 경우는 블러링 필터를 먼저 적용해야 합니다.
■ 적응형 스레시홀드
영상에 조명이 일정하지 않거나 배경색이 여러 가지인 경우에는 아무리 여러 번 경계 값을 바꿔가며 시도해도 하나의 경계 값을 이미지 전체에 적용해서는 좋은 결과를 얻지 못합니다. 이때는 이미지를 여러 영역으로 나눈 다음 그 주변 픽셀 값만 가지고 계산을 해서 경계 값을 구해야 하는데, 이것을 적응형 스레시홀드(adaptive threshold)라고 합니다.
- cv2.adaptiveThreshold(img, value, method, type_flag, block_size, C)
- img: 입력 영상
- value: 경계 값을 만족하는 픽셀에 적용할 값
- method: 경계 값 결정 방법
- cv2.ADPTIVE_THRESH_MEAN_C: 이웃 픽셀의 평균으로 결정
- cv2.ADPTIVE_THERSH_GAUSSIAN_C: 가우시안 분포에 따른 가중치의 합으로 결정
- type_flag: 스레시홀드 적용 방법 지정(cv2.threshold() 와 동일)
- block_size: 영역으로 나눌 이웃의 크기(n x n), 홀수(3, 5, 7, ...)
- C: 계산된 경계 값 결과에서 가감할 상수(음수 가능)
import cv2
import numpy as np
import matplotlib.pyplot as plt
blk_size = 9 # 블럭 사이즈
C = 5 # 차감 상수
img = cv2.imread('../img/sudoku.png', cv2.IMREAD_GRAYSCALE) # 그레이 스케일로 읽기
# ---① 오츠의 알고리즘으로 단일 경계 값을 전체 이미지에 적용
ret, th1 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)
# ---② 어뎁티드 쓰레시홀드를 평균과 가우시안 분포로 각각 적용
th2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C,\
cv2.THRESH_BINARY, blk_size, C)
th3 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, \
cv2.THRESH_BINARY, blk_size, C)
# ---③ 결과를 Matplot으로 출력
imgs = {'Original': img, 'Global-Otsu:%d'%ret:th1, \
'Adapted-Mean':th2, 'Adapted-Gaussian': th3}
for i, (k, v) in enumerate(imgs.items()):
plt.subplot(2,2,i+1)
plt.title(k)
plt.imshow(v,'gray')
plt.xticks([]),plt.yticks([])
plt.show()
실행 결과를 보면
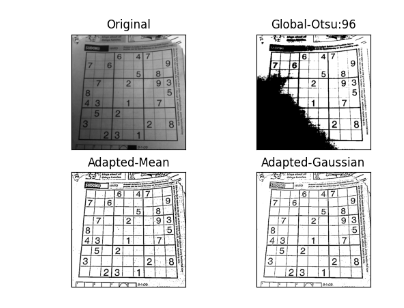
이와 같이 나옵니다. 이미지를 읽어와 Otsu 알고리즘을 이용해 threshold()함수를 진행했더니 좌측 하단에 검게 타버리고, 우측 상단은 하얗게 날라갔습니다. 반면 아래 두 경우(cv2.ADPTIVE_THRESH_MEAN_C, cv2.ADPTIVE_THRESH_GAUSSIAN_C)는 훨씬 더 좋은 성능을 보여줍니다. 그 중에서도 가우시안 분포를 이용한 결과를 보면 선명함은 조금 떨어지지만 잡티(noise)가 훨씬 적은 것을 알 수 있습니다.
4.4 이미지 연산
■ 영상과 영상의 연산
영상에 연산을 할 수 있는 방법은 Numpy의 브로드캐스팅 연산을 직접 적용하는 방법과 OpenCV에서 제공하는 네 가지 함수를 사용하는 방법이 있습니다. OpenCV에서 굳이 연산에 사용할 함수를 제공하는 이유는 영상에서의 한 픽셀이 가질 수 있는 값의 범위는 0 ~ 255인데, 더하거나 빼기 연산을 한 결과가 255보다 클 수도 있고 0보다 작을 수도 있어서 결과 값을 0과 255로 제한할 안전 장치가 필요하기 때문입니다.
- dest = cv2.add(src1, src2[, dest, mask, dtype]): src1과 src2 더하기
- src1: 입력 영상 1 또는 수
- src2: 입력 영상 2 또는 수
- dest: 출력 영상
- mask: 0이 아닌 픽셀만 연산
- dtype: 출력 type
- dest = cv2.subtract(src1, src2[, dest, mask, dtype]): src1에서 src2를 빼기
- 모든 인자는 cv2.add()와 동일
- dest = cv2.multiply(src1, src2[, dest, scale, dtype]): src1과 src2를 곱하기
- scale: 연산 결과에 추가 연산할 값
- dest = cv2.divide(src1, src2[, dest, scale, dtype]): src1을 src2로 나누기
- 모든 인자는 cv2.multiply()와 동일
import cv2
import numpy as np
# ---① 연산에 사용할 배열 생성
a = np.uint8([[200, 50]])
b = np.uint8([[100, 100]])
#---② NumPy 배열 직접 연산
add1 = a + b
sub1 = a - b
mult1 = a * 2
div1 = a / 3
# ---③ OpenCV API를 이용한 연산
add2 = cv2.add(a, b)
sub2 = cv2.subtract(a, b)
mult2 = cv2.multiply(a , 2)
div2 = cv2.divide(a, 3)
#---④ 각 연산 결과 출력
print(add1, add2)
print(sub1, sub2)
print(mult1, mult2)
print(div1, div2)실행결과는
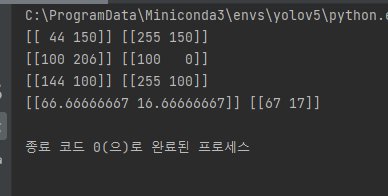
이와 같습니다. OpenCV에서 제공하는 연산 함수를 사용하면 0 ~ 255 사이를 벗어나지 않는 것을 알 수 있습니다. 그리고 실수형이 아닌 정수형으로 표현되는 것도 볼 수 있습니다.
cv2.add() 함수를 보면 mask를 지정하는 부분이 있는데 이 mask에 전달된 Numpy 배열에 어떤 요소 값이 0이면 그 위치의 픽셀은 연산을 하지 않습니다.
■ 알파 블렌딩
두 영상을 합성하려고 할 때 더하기(+) 연산이나 cv2.add() 함수만으로는 좋은 결과를 얻을 수 없는 경우가 많습니다. 직접 더하기 연산을 하면 255를 넘는 경우 초과 값만을 가지므로 영상이 거뭇거뭇하게 나타나고 cv2.add() 연산을 하면 대부분의 픽셀 값이 255 가까이 몰리는 현상이 일어나 영상이 하얗게 날아간 것처럼 보이게 됩니다. 그래서 두 영상을 합성하려면 각 픽셀의 합이 255가 넘지 않도록 각 영상에 가중치를 줘서 계산해야 합니다. 예를 들어 두 영상이 정확히 절반씩 반영된 결과 영상을 원한다면 각 영상의 픽셀 값에 각각 50%씩 곱해서 새로운 영상을 생성하면 됩니다. 이때 각 영상에 적용할 가중치를 알파(alpha) 값이라고 부릅니다.
직접 Numpy 배열을 이용해 가중치 연산을 해도 되지만, OpenCV는 함수를 제공해줍니다.
- cv2.addWeight(img1, alpha, img2, beta, gamma)
- img1, img2: 합성할 두 영상
- alpha: img1에 지정할 가중치(알파 값)
- beta: img2에 지정할 가중치, 흔히 (1 - alpha) 적용
- gamma: 연산 결과에 가감할 상수, 흔히 0 적용
import cv2
import numpy as np
win_name = 'Alpha blending' # 창 이름
trackbar_name = 'fade' # 트렉바 이름
# ---① 트렉바 이벤트 핸들러 함수
def onChange(x):
alpha = x/100
dst = cv2.addWeighted(img1, 1-alpha, img2, alpha, 0)
cv2.imshow(win_name, dst)
# ---② 합성 영상 읽기
img1 = cv2.imread('../img/man_face.jpg')
img2 = cv2.imread('../img/lion_face.jpg')
# ---③ 이미지 표시 및 트렉바 붙이기
cv2.imshow(win_name, img1)
cv2.createTrackbar(trackbar_name, win_name, 0, 100, onChange)
cv2.waitKey()
cv2.destroyAllWindows()위 코드는 보면 트랙바를 조정해 두 이미지의 가중치를 조절해 합성하는 코드입니다. 트랙바를 움직여서 알파 값을 조정하면 마치 사람이 서서히 사자로 바뀌는 것처럼 보입니다. 알파 블렌딩은 흔히 페이드-인/아웃(fade-in/out) 기법으로 영상이 전환되는 장면에서 자주 사용되며, '구미호'나 '늑대인간' 같은 영화의 변신 장면에서 얼굴 모핑(face morphing)이라는 기법으로 효과를 내는데, 이 기법을 구성하는 한 가지 기술이기도 합니다.
■ 비트와이즈 연산
OpenCV는 두 영상의 각 픽셀에 대한 비트와이즈(bitwise, 비트 단위) 연산 기능을 제공합니다.
- bitwise_and(img1, img2, mask = None): 각 픽셀에 대해 비트와이즈 AND 연산
- bitwise_or(img1, img2, mask = None): 각 픽셀에 대해 비트와이즈 OR 연산
- bitwise_xor(img1, img2, mask = None): 각 픽셀에 대해 비트와이즈 XOR 연산
- bitwise_not(img1, mask = None): 각 픽셀에 대해 비트와이즈 NOT 연산
- img1, img2: 연산 대상 영상, 동일한 shape
- mask: 0이 아닌 픽셀만 연산, 바이너리 이미지
import numpy as np, cv2
import matplotlib.pylab as plt
#--① 이미지 읽기
img = cv2.imread('../img/girl.jpg')
#--② 마스크 만들기
mask = np.zeros_like(img)
cv2.circle(mask, (150,140), 100, (255,255,255), -1)
#cv2.circle(대상이미지, (원점x, 원점y), 반지름, (색상), 채우기)
#--③ 마스킹
masked = cv2.bitwise_and(img, mask)
#--④ 결과 출력
cv2.imshow('original', img)
cv2.imshow('mask', mask)
cv2.imshow('masked', masked)
cv2.waitKey()
cv2.destroyAllWindows()
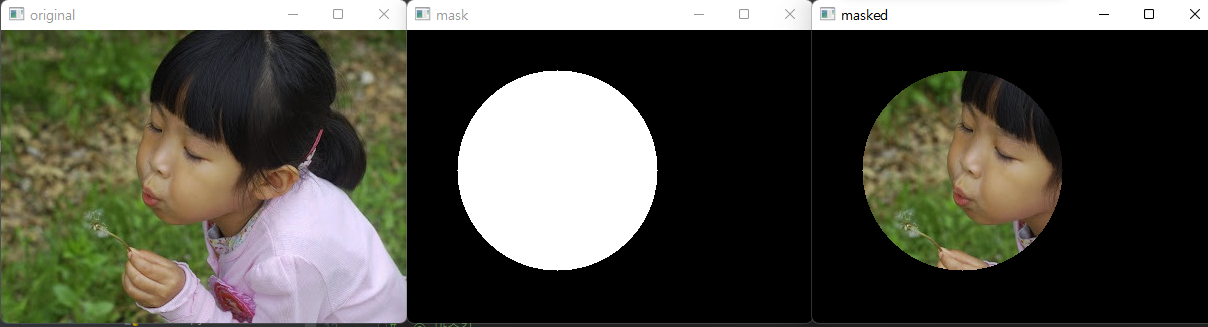
이와 같은 결과를 얻을 수 있습니다. 원을 그리고 그 안에 값은 255로 채우고 다른 공간은 0으로 채웁니다. bitwise_and 연산을 통해 원은 mask 역할을 하게 됩니다.
■ 차영상
영상에서 영상을 뺴기 연산하면 두 영상의 차이, 즉 변화를 알 수 있습니다. 차영상을 구할 때 두 영상을 무턱대고 빼기 연산하면 음수가 나올 수 있으므로 절대 값을 구해야 합니다.
- diff = cv2.absdiff(img1, img2)
- img1, img2: 입력 영상
- diff: 두 영상의 차의 절대값 반환
import cv2
import numpy as np
import matplotlib.pylab as plt
#--① 크로마키 배경 영상과 합성할 배경 영상 읽기
img1 = cv2.imread('../img/man_chromakey.jpg')
img2 = cv2.imread('../img/street.jpg')
#--② ROI 선택을 위한 좌표 계산
height1, width1 = img1.shape[:2]
height2, width2 = img2.shape[:2]
x = (width2 - width1)//2
y = height2 - height1
w = x + width1
h = y + height1
#--③ 크로마키 배경 영상에서 크로마키 영역을 10픽셀 정도로 지정
chromakey = img1[:10, :10, :]
offset = 20
#--④ 크로마키 영역과 영상 전체를 HSV로 변경
hsv_chroma = cv2.cvtColor(chromakey, cv2.COLOR_BGR2HSV)
hsv_img = cv2.cvtColor(img1, cv2.COLOR_BGR2HSV)
#--⑤ 크로마키 영역의 H값에서 offset 만큼 여유를 두어서 범위 지정
# offset 값은 여러차례 시도 후 결정
#chroma_h = hsv_chroma[0]
chroma_h = hsv_chroma[:,:,0]
lower = np.array([chroma_h.min()-offset, 100, 100])
upper = np.array([chroma_h.max()+offset, 255, 255])
#--⑥ 마스크 생성 및 마스킹 후 합성
mask = cv2.inRange(hsv_img, lower, upper)
mask_inv = cv2.bitwise_not(mask)
roi = img2[y:h, x:w]
fg = cv2.bitwise_and(img1, img1, mask=mask_inv)
bg = cv2.bitwise_and(roi, roi, mask=mask)
img2[y:h, x:w] = fg + bg
#--⑦ 결과 출력
cv2.imshow('chromakey', img1)
cv2.imshow('added', img2)
cv2.waitKey()
cv2.destroyAllWindows()위 코드는 사람과 배경을 img1, img2로 읽어들입니다. 크로마 키는 img1[:10, :10, :]으로 지정합니다. 그리고 모든 영상은 HSV 컬러스페이스로 변경합니다. cv2.inRange()함수를 통해 이미지가 lower에서 upper 사이의 값을 갖는지를 확인합니다(단, H만 비교해 색만 비교하는 형태입니다). 해당 범위 안에 있는 픽셀은 255이 되고 아니면 0이 되므로 인물을 제외한 배경만 255가 되고 인물은 0이 됩니다. 이 값은 mask로 사용가능하며 mask를 bitwise_not을 하면 mask_inv가 되며 이 부분은 인물만 의미합니다. mask에 배경과 bitwise_and를 하고 mask_inv에 인물과 bitwise_and를 하면 원하는 배경에 인물이 포함되는 이미지를 얻을 수 있습니다.
영상 합성에는 대부분 알파 블렌딩 또는 마스킹이 필요합니다. 하지만, 이런 작업은 블렌딩을 위한 적절한 알파 값 선택과 마스킹을 위한 모양의 좌표나 색상 값 선택에 많은 노력과 시간이 필요합니다. OpenCV는 알아서 두 영상의 특징을 살려 합성하는 함수를 제공합니다.
- dst = cv2.seamlessClone(src, dst, mask, coords, flags[, output])
- src: 입력 영상, 일반적으로 전경
- dst: 대상 영상, 일반적으로 배경
- mask: 마스크, src에서 합성하고자 하는 영역은 255, 나머지는 0
- coords: src가 놓여지기 원하는 dst의 좌표(중앙)
- flags: 합성 방식
- cv2.NORMAL_CLONE: 입력 원본 유지
- cv2.MIXED_CLONE: 입력과 대상을 혼합
- output: 합성 결과
- dst: 합성 결과
4.5 히스토그램
히스토그램(histogram)은 뭐가 몇 개 있는지 개수를 세어 놓은 것을 그림으로 표시한 것으로 영상을 분석하는 데 도움이 많이 됩니다.
■ 히스토그램 계산과 표시
영상 분야에서의 히스토그램은 전체 영상에서 픽셀 값이 1인 픽셀이 몇 개이고 2인 픽셀이 몇 개이고 하는 식으로 픽셀 값이 255인 픽셀이 몇 개인지까지 세는 것을 말합니다. 그렇게 하는 이유는 전체 영상에서 픽셀들의 색상이나 명암의 분포를 파악하기 위해서입니다.
OpenCV는 영상에서 히스토그램을 계산하는 cv2.calcHist() 함수를 제공합니다.
- cv2.calcHist(img, channel, mask, histSize, ranges)
- img: 입력 영상, [img] 처럼 리스트로 감싸서 표현
- channel: 처리할 채널, 리스트로 감싸서 표현
- 1채널: [0], 2채널: [0, 1], 3채널: [0, 1, 2]
- mask: 마스크에 지정한 픽셀만 히스토그램 계산
- histSize: 계급(bin)의 개수, 채널 개수에 맞게 리스트로 표현
- 1채널: [256], 2채널: [256, 256], 3채널: [256, 256, 256]
- ranges: 각 픽셀이 가질 수 있는 값의 범위, RGB인 경우 [0, 256]
import cv2
import numpy as np
import matplotlib.pylab as plt
#--① 이미지 그레이 스케일로 읽기 및 출력
img = cv2.imread('../img/mountain.jpg', cv2.IMREAD_GRAYSCALE)
cv2.imshow('img', img)
#--② 히스토그램 계산 및 그리기
hist = cv2.calcHist([img], [0], None, [256], [0,255])
plt.plot(hist)
print("hist.shape:", hist.shape) #--③ 히스토그램의 shape (256,1)
print("hist.sum():", hist.sum(), "img.shape:",img.shape) #--④ 히스토그램 총 합계와 이미지의 크기
plt.show()
위 코드는 간단하게 그레이 스케일로 읽은 이미지에 대한 히스토그램을 계산한 코드입니다.
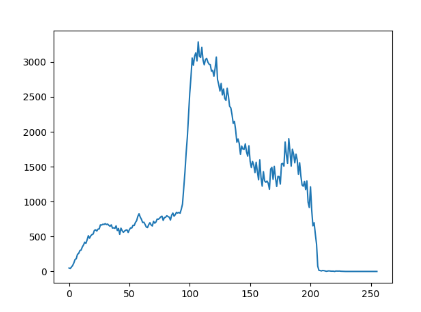
이와 같은 실행결과를 보여줍니다. 그레이 스케일로 이미지를 읽어서 1차원 히스토그램으로 출력했습니다. 히스토그램 대상 이미지는 [img], 1채널만 있기 때문에 [0], 마스크는 사용하지 않으므로 None, 가로축(x축)에 표시할 계급(bin)의 개수는 [256], 픽셀 값 중 최소 값과 최대 값은 [0, 256]이라는 의미입니다.
만약 그레이 스케일이 아닌 컬러 스케일로 이미지를 읽어 히스토그램을 계산하면
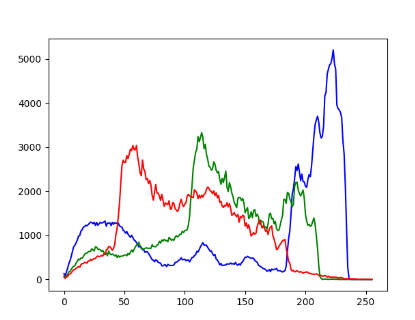
이런 식으로 각 채널에 맞춰 각각 따로 계산해서 그릴 수 있습니다.
■ 노멀라이즈(Normalize, 정규화)
영상 분야에서 픽셀 값들이 0 ~ 255에 골고루 분포하지 않고 특정 영역에 몰려 있는 경우 노멀라이즈를 통해 화질을 개선하기도 하고 영상 간의 연산을 해야 하는데 서로 조건이 다른 경우 같은 조건으로 만들기도 합니다.
OpenCV는 노멀라이즈 기능 함수를 제공합니다.
- dst = cv2.normalize(src, dst, alpha, beta, type_flag)
- src: 노멀라이즈 이전 데이터
- dst: 노멀라이즈 이후 데이터
- alpha: 노멀라이즈 구간 1
- beta: 노멀라이즈 구간 2, 구간 노멀라이즈가 아닌 경우 사용 안함
- type_flag: 알고리즘 선택 플래그 상수
- cv2.NORM_MINMAX: alpha와 beta 구간으로 노멀라이즈
- cv2.NORM_L1: 전체 합으로 나누기, alpha = 노멀라이즈 전체 합
- cv2.NORM_L2: 단위 벡터(unit vector)로 노멀라이즈
- cv2.NORM_INF: 최대 값으로 나누기
import cv2
import numpy as np
import matplotlib.pylab as plt
#--① 그레이 스케일로 영상 읽기
img = cv2.imread('../img/abnormal.jpg', cv2.IMREAD_GRAYSCALE)
#--② 직접 연산한 정규화
img_f = img.astype(np.float32)
img_norm = ((img_f - img_f.min()) * (255) / (img_f.max() - img_f.min()))
img_norm = img_norm.astype(np.uint8)
#--③ OpenCV API를 이용한 정규화
img_norm2 = cv2.normalize(img, None, 0, 255, cv2.NORM_MINMAX)
#--④ 히스토그램 계산
hist = cv2.calcHist([img], [0], None, [256], [0, 255])
hist_norm = cv2.calcHist([img_norm], [0], None, [256], [0, 255])
hist_norm2 = cv2.calcHist([img_norm2], [0], None, [256], [0, 255])
cv2.imshow('Before', img)
cv2.imshow('Manual', img_norm)
cv2.imshow('cv2.normalize()', img_norm2)
hists = {'Before' : hist, 'Manual':hist_norm, 'cv2.normalize()':hist_norm2}
for i, (k, v) in enumerate(hists.items()):
plt.subplot(1,3,i+1)
plt.title(k)
plt.plot(v)
plt.show()
실행결과는

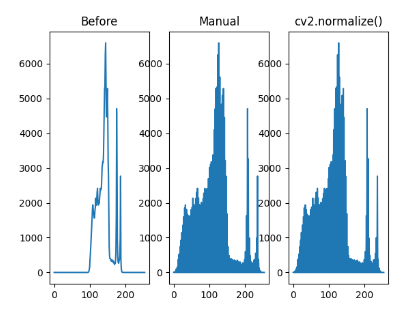
이와 같이 나옵니다. 뿌연 원본 영상을 정규화를 통해 화질을 개선한 모습입니다. cv2.NORM_MINMAX 플래그 상수를 사용하고 alpha(0), beta(255)는 구간을 나타냅니다. 중앙에 몰려 있던 픽셀들의 분포가 전체적으로 고르게 퍼져서 화질이 개선된 것을 볼 수 있습니다.
■ 이퀄라이즈(Equalize, 평탄화)
노멀라이즈는 분포가 한곳에 집중되어 있는 경우에는 효과적이지만 집중된 영역에서 멀리 떨어진 값이 있을 경우에는 효과가 없습니다. 이 경우에는 이퀄라이즈(equalize, 평탄화)가 필요합니다. 이퀄라이즈는 히스토그램으로 빈도를 구해서 노멀라이즈한 후 누적값을 전체 개수로 나누어 나온 결과 값을 히스토그램 원래 픽셀 값에 매핑합니다. 이퀄라이즈는 각각의 값이 전체 분포에 차지하는 비중에 따라 분포를 재분배하므로 명암 대비(contrast)를 개선하는 데 효과적입니다.
- dst = cv2.equalizeHist(src[, dst])
- src: 대상 이미지, 8비트 1채널
- dst: 결과 이미지
import cv2
import numpy as np
import matplotlib.pylab as plt
#--① 대상 영상으로 그레이 스케일로 읽기
img = cv2.imread('../img/yate.jpg', cv2.IMREAD_GRAYSCALE)
rows, cols = img.shape[:2]
#--② 이퀄라이즈 연산을 직접 적용
hist = cv2.calcHist([img], [0], None, [256], [0, 256]) #히스토그램 계산
cdf = hist.cumsum() # 누적 히스토그램
cdf_m = np.ma.masked_equal(cdf, 0) # 0(zero)인 값을 NaN으로 제거
cdf_m = (cdf_m - cdf_m.min()) /(rows * cols) * 255 # 이퀄라이즈 히스토그램 계산
cdf = np.ma.filled(cdf_m,0).astype('uint8') # NaN을 다시 0으로 환원
print(cdf.shape)
img2 = cdf[img] # 히스토그램을 픽셀로 맵핑
#--③ OpenCV API로 이퀄라이즈 히스토그램 적용
img3 = cv2.equalizeHist(img)
#--④ 이퀄라이즈 결과 히스토그램 계산
hist2 = cv2.calcHist([img2], [0], None, [256], [0, 256])
hist3 = cv2.calcHist([img3], [0], None, [256], [0, 256])
#--⑤ 결과 출력
cv2.imshow('Before', img)
cv2.imshow('Manual', img2)
cv2.imshow('cv2.equalizeHist()', img3)
hists = {'Before':hist, 'Manual':hist2, 'cv2.equalizeHist()':hist3}
for i, (k, v) in enumerate(hists.items()):
plt.subplot(1,3,i+1)
plt.title(k)
plt.plot(v)
plt.show()위 코드는 직접 이퀄라이즈를 하는 방식과 cv2.equalizeHist를 사용하는 방식을 이용해 이미지의 명암을 개선합니다.
실행 결과를 보면

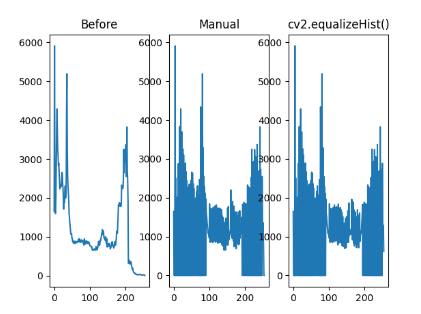
이미지의 명암이 개선된 것을 볼 수 있습니다. hist.cumsum()은 누적합을 구하는 함수이고, np.ma.masked_equal(cdf, 0)은 요소 값이 0인 것을 NaN으로 적용하는데, 불필요한 연산을 줄이고자 하는 이유로 사용했습니다. 다시 원래대로 돌리기 위해 np.ma.filled(cdf_m, 0)을 사용합니다. img2 = cdf[img]는 연산 결과를 원래의 픽셀 값에 매핑합니다(img는 그레이 스케일로 읽었고 각 픽셀은 0 ~ 255 사이의 값을 가지고 cdf에 픽셀 값이 인덱스로 들어가면서 해당 누적 값이 img2에 들어갑니다).
만약 밝기만 개선하고 싶다면 BGR를 HSV, YUV로 변경해 밝기 채널만 연산해서 최종 이미지에 적용하는 것이 더 좋습니다.
■ CLAHE
CLAHE(Contrast Limiting Adaptive Histogram Equalization)는 영상 전체에 이퀄라이즈를 적용했을 때 너무 밝은 부분이 날아가는 현상을 막기 위해 영상을 일정한 영역으로 나눠서 이퀄라이즈를 적용하는 것을 말합니다. 노이즈가 증폭되는 것을 막기 위해 어느 히스토그램 계급(bin)이든 지정된 제한 값을 넘으면 그 픽셀은 다른 계급으로 배분하고 나서 이퀄라이즈를 적용합니다.
- clahe = cv2.createCLAHE(clipLimit, tileGridSize): CLAHE 생성
- clipLimit: Contrast 제한 경계 값, 기본 40.0
- tileGridSize: 영역 크기, 기본 8 x 8
- clahe: 생성된 CLAHE 객체
- clahe.apply(src): CLAHE 적용
- src: 입력 영상
import cv2
import numpy as np
import matplotlib.pylab as plt
#--①이미지 읽어서 YUV 컬러스페이스로 변경
img = cv2.imread('../img/bright.jpg')
img_yuv = cv2.cvtColor(img, cv2.COLOR_BGR2YUV)
#--② 밝기 채널에 대해서 이퀄라이즈 적용
img_eq = img_yuv.copy()
img_eq[:,:,0] = cv2.equalizeHist(img_eq[:,:,0])
img_eq = cv2.cvtColor(img_eq, cv2.COLOR_YUV2BGR)
#--③ 밝기 채널에 대해서 CLAHE 적용
img_clahe = img_yuv.copy()
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8)) #CLAHE 생성
img_clahe[:,:,0] = clahe.apply(img_clahe[:,:,0]) #CLAHE 적용
img_clahe = cv2.cvtColor(img_clahe, cv2.COLOR_YUV2BGR)
#--④ 결과 출력
cv2.imshow('Before', img)
cv2.imshow('CLAHE', img_clahe)
cv2.imshow('equalizeHist', img_eq)
cv2.waitKey()
cv2.destroyAllWindows()

실행 결과는 위와 같이 나옵니다. CLAHE를 적용한 이미지가 좋은 결과를 보여줍니다. 원본 이미지는 너무 빛이 많이 들어간 모습입니다. 단순히 이퀄라이즈만 진행한 결과는 밝은 곳이 날아가는 증상이 발생한 것을 보여줍니다.
■ 역투영
2차원 히스토그램과 HSV 컬러 스페이스를 이용하면 색상으로 특정 물체나 사물의 일부분을 배경에서 분리할 수 있습니다. 기본 원리는 물체가 있는 관심영역의 H와 V 값의 분포를 얻어낸 후 전체 영상에서 해당 분포의 픽셀만 찾아내는 것입니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
win_name = 'back_projection'
img = cv2.imread('../img/pump_horse.jpg')
hsv_img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
draw = img.copy()
#--⑤ 역투영된 결과를 마스킹해서 결과를 출력하는 공통함수
def masking(bp, win_name):
disc = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5))
cv2.filter2D(bp,-1,disc,bp)
_, mask = cv2.threshold(bp, 1, 255, cv2.THRESH_BINARY)
result = cv2.bitwise_and(img, img, mask=mask)
cv2.imshow(win_name, result)
#--⑥ 직접 구현한 역투영 함수
def backProject_manual(hist_roi):
#--⑦ 전체 영상에 대한 H,S 히스토그램 계산
hist_img = cv2.calcHist([hsv_img], [0,1], None,[180,256], [0,180,0,256])
#--⑧ 선택영역과 전체 영상에 대한 히스토그램 그램 비율계산
hist_rate = hist_roi/ (hist_img + 1)
#--⑨ 비율에 맞는 픽셀 값 매핑
h,s,v = cv2.split(hsv_img)
bp = hist_rate[h.ravel(), s.ravel()]
bp = np.minimum(bp, 1)
print(hsv_img.shape)
bp = bp.reshape(hsv_img.shape[:2])
print(bp)
cv2.normalize(bp,bp, 0, 255, cv2.NORM_MINMAX)
bp = bp.astype(np.uint8)
#--⑩ 역 투영 결과로 마스킹해서 결과 출력
masking(bp,'result_manual')
# OpenCV API로 구현한 함수 ---⑪
def backProject_cv(hist_roi):
# 역투영 함수 호출 ---⑫
bp = cv2.calcBackProject([hsv_img], [0, 1], hist_roi, [0, 180, 0, 256], 1)
# 역 투영 결과로 마스킹해서 결과 출력 ---⑬
masking(bp,'result_cv')
# ROI 선택 ---①
(x,y,w,h) = cv2.selectROI(win_name, img, False)
if w > 0 and h > 0:
roi = draw[y:y+h, x:x+w]
cv2.rectangle(draw, (x, y), (x+w, y+h), (0,0,255), 2)
#--② 선택한 ROI를 HSV 컬러 스페이스로 변경
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
#--③ H,S 채널에 대한 히스토그램 계산
hist_roi = cv2.calcHist([hsv_roi],[0, 1], None, [180, 256], [0, 180, 0, 256] )
#--④ ROI의 히스토그램을 매뉴얼 구현함수와 OpenCV 이용하는 함수에 각각 전달
backProject_manual(hist_roi)
backProject_cv(hist_roi)
cv2.imshow(win_name, draw)
cv2.waitKey()
cv2.destroyAllWindows()위 코드는 마우스 드래그를 통해 ROI를 선택해 특정 물체만 배경에서 분리해 내는 모습을 보여줍니다. 먼저 cv2.selectROI() 함수를 이용해 ROI 영역을 정해줍니다. ROI 영역을 HSV 컬러 스페이스로 변경하고 H, S차원에 대한 2차원 히스토그램을 구합니다. 두 함수가 있는데 backProject_cv는 cv2.calcBackProject() 함수를 사용해 역투영합니다. backProject_manual() 함수는 직접 역투영합니다. 직접 역투영하는 함수를 보면 전체 이미지에 대한 히스토그램으로 ROI의 히스토그램을 나눠 비율을 구합니다. 비율을 구한다는 것은 관심영역과 비슷한 색상 분포를 갖는 히스토그램은 1에 가까운 값을 갖고 그 반대는 0에 가까운 값을 갖습니다. 즉 이는 마스킹에 사용할 수 있다는 뜻입니다. 이렇게 구한 비율을 원래 영상의 H, S에 매핑합니다.
bp = hist_rate[h.ravel(), s.ravel()]부분을 보겠습니다. hist_rate는 히스토그램 비율을 값으로 가지고 있고, h와 s는 실제 영상의 각 픽셀에 해당합니다. 따라서 H와 S가 교차되는 지점의 비율을 그 픽셀의 값으로 하는 1차원 배열을 얻게 됩니다.
이젠 OpenCV에서 제공하는 함수를 보겠습니다.
- cv2.calcBackProject(img, channel, hist, ranges, scale)
- img: 입력 영상, [img] 처럼 리스트로 감싸서 표현
- channel: 처리할 채널, 리스트로 감싸서 표현
- 1채널: [0], 2채널: [0, 1], 3채널: [0, 1, 2]
- hist: 역투영에 사용할 히스토그램
- ranges: 각 픽셀이 가질 수 있는 값의 범위
- scale: 결과에 적용할 배율 계수
■ 히스토그램 비교
히스토그램은 영상의 픽셀 값의 분포를 갖는 정보이므로 이것을 비교하면 영상에 사용한 픽셀의 색상 비중이 얼마나 비슷한지 알 수 있습니다. 이것은 영상이 서로 얼마나 비슷한지를 알 수 있는 하나의 방법입니다.
- cv2.compareHist(hist1, hist2, method)
- hist1, hist2: 비교할 2개의 히스토그램, 크기와 차원이 같아야 함
- method: 비교 알고리즘 선택 플래그 상수
- cv2.HISTCMP_CORREL: 상관관계(1: 완전 일치, -1: 최대 불일치, 0: 무관계)
- cv2.HISTCMP_CHISQR: 카이제곱(0: 완전 일치, 큰 값(미정): 최대 불일치)
- cv2.HISTCMP_INTERSECT: 교차(1: 완전 일치, 0: 최대 불일치(1로 정규화한 경우))
- cv2.HISTCMP_BHATTACHARYYA: 바타차야(0: 완전 일치, 1: 최대 불일치)
- cv2.HISTCMP_HELLINGER: HISTOCMP_BHATTACHARYYA와 동일
import cv2, numpy as np
import matplotlib.pylab as plt
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/taekwonv2.jpg')
img3 = cv2.imread('../img/taekwonv3.jpg')
img4 = cv2.imread('../img/dr_ochanomizu.jpg')
cv2.imshow('query', img1)
imgs = [img1, img2, img3, img4]
hists = []
for i, img in enumerate(imgs) :
plt.subplot(1,len(imgs),i+1)
plt.title('img%d'% (i+1))
plt.axis('off')
plt.imshow(img[:,:,::-1])
#---① 각 이미지를 HSV로 변환
hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
#---② H,S 채널에 대한 히스토그램 계산
hist = cv2.calcHist([hsv], [0,1], None, [180,256], [0,180,0, 256])
#---③ 0~1로 정규화
cv2.normalize(hist, hist, 0, 1, cv2.NORM_MINMAX)
hists.append(hist)
query = hists[0]
methods = {'CORREL' :cv2.HISTCMP_CORREL, 'CHISQR':cv2.HISTCMP_CHISQR,
'INTERSECT':cv2.HISTCMP_INTERSECT,
'BHATTACHARYYA':cv2.HISTCMP_BHATTACHARYYA}
for j, (name, flag) in enumerate(methods.items()):
print('%-10s'%name, end='\t')
for i, (hist, img) in enumerate(zip(hists, imgs)):
#---④ 각 메서드에 따라 img1과 각 이미지의 히스토그램 비교
ret = cv2.compareHist(query, hist, flag)
if flag == cv2.HISTCMP_INTERSECT: #교차 분석인 경우
ret = ret/np.sum(query) #비교대상으로 나누어 1로 정규화
print("img%d:%7.2f"% (i+1 , ret), end='\t')
print()
plt.show()

위 이미지로 히스토그램을 구해 비교하는 코드입니다. 실행 결과를 보면
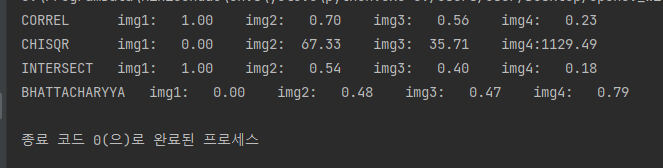
이와 같이 나옵니다. img1과 img1은 같다는 결과를 얻고 img4와는 큰 차이를 보이는 것을 알 수 있습니다.
'Deep Learning(강의 및 책) > OpenCV' 카테고리의 다른 글
| [OpenCV] 영상 매칭과 추적 (0) | 2022.08.20 |
|---|---|
| [OpenCV] 영상 분할 (0) | 2022.08.04 |
| [OpenCV] 영상 필터 (0) | 2022.08.01 |
| [OpenCV] 기하학적 변환 (0) | 2022.07.30 |
| [OpenCV] 기본 입출력 (0) | 2022.07.11 |



