이 글은 '파이썬으로 만드는 OpenCV 프로젝트'를 보고 작성했습니다.
영상 매칭(matching)이란 서로 다른 두 영상을 비교해 영상 속 객체가 같은 것인지 알아내거나 여러 영상 중에서 짝이 맞는 영상을 찾아내는 것을 말합니다.
8.1 비슷한 그림 찾기
영상 속 객체를 인식하는 방법 중 하나가 화투처럼 비슷한 그림을 찾아내는 것입니다. 새로운 영상이 입력되면 이미 알고 있던 영상들 중에서 가장 비슷한 영상을 찾아 그 영상에 있는 객체로 판단하는 것입니다.
■ 평균 해시 매칭
평균 해시 매칭(average hash matching)은 쉽고 간단하게 비슷한 그림을 찾는 방법입니다. 평균 해시는 어떤 영상이든 동일한 크기의 하나의 숫자로 변환되는데, 이때 숫자를 얻기 위해 평균값을 이용한다는 뜻입니다. 평균을 얻기 전에 영상을 가로 세로 비율과 무관하게 특정한 크기로 축소하고 픽셀 전체의 평균값을 구해서 각 픽셀의 값이 평균보다 작으면 0, 크면 1로 바꿉니다. 그다음 0 또는 1로만 구성된 각 픽셀 값을 1행 1열로 변환하는데, 한 줄로 늘어선 0과 1의 숫자들은 한 개의 2진수 숫자로 볼 수 있습니다. 이를 10진수 또는 16진수로 변경해서 표현할 수도 있습니다.
import cv2
#영상 읽어서 그레이 스케일로 변환
img = cv2.imread('../img/pistol.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 8x8 크기로 축소 ---①
gray = cv2.resize(gray, (16,16))
# 영상의 평균값 구하기 ---②
avg = gray.mean()
print(avg)
# 평균값을 기준으로 0과 1로 변환 ---③
bin = 1 * (gray > avg)
print(bin)
# 2진수 문자열을 16진수 문자열로 변환 ---④
dhash = []
for row in bin.tolist():
print(row)
s = ''.join([str(i) for i in row])
dhash.append('%02x'%(int(s,2)))
dhash = ''.join(dhash)
print(dhash)
cv2.namedWindow('pistol', cv2.WINDOW_GUI_NORMAL)
cv2.imshow('pistol', img)
cv2.waitKey(0)

실행 결과를 보면 0과 1의 숫자로 표현되고 0으로 표현된 부분이 권총과 비슷합니다.
이렇게 얻은 평균 해시를 다른 영상의 것과 비교해서 얼마나 비슷한지를 알아내기 위해 두 값의 거리를 측정해서 그 거리가 가까우면 비슷한 것으로 판단하는 방법을 사용합니다. 두 값의 거리를 측정하는 방법은 여러가지가 존재하는데 대표적으로 유클리드 거리(Euclidian distance)와 해밍 거리(Hamming distance)가 있습니다.
유클리드 거리는 두 값의 차이로 거리를 계산합니다. 예를 들어 5와 비교할 값이 8과 3이 있다면 유클리드 거리는 3, 2가 되고 3이 5와 더 유사하다는 결과를 얻습니다.
해밍 거리는 두 값의 길이가 같아야 계산할 수 있습니다. 두 수의 같은 자리의 값이 서로 다른 것이 몇 개인지를 나타내는 것이 해밍 거리입니다. 예를 들어 12345와 비교할 값으로 12354와 92345가 있을 때 12345와 12354의 마지막 두 자리가 다르므로 해밍 거리는 2이고, 12345와 92345의 맨 처음 자리 하나만 다르므로 해밍 거리는 1이 됩니다. 이 결과 92345가 더 유사하다는 결과를 얻습니다.
유클리드 거리는 높은 자릿수가 다를수록 더 큰 거리로 인식하는 반면, 해밍 거리는 각 자릿수의 차이의 개수로만 비교하므로 앞서 얻은 영상의 평균 해시 값을 비교하는 데는 유클리드 거리가 아닌 해밍 거리가 더 적합합니다. 이처럼 숫자 2개를 비교할 때 그 수가 갖는 특징에 따라 어떤 방법으로 측정하는 것이 좋은 지 판단해야 합니다.
이번에는 미국의 캘리포니아 공대에서 101가지 물체를 담은 영상들을 이미지셋으로 제공하는데, 이 이미지 셋으로 권총과 유사한 영상을 찾아보겠습니다.
import cv2
import numpy as np
import glob
# 영상 읽기 및 표시
img = cv2.imread('../img/pistol.jpg')
cv2.imshow('query', img)
# 비교할 영상들이 있는 경로 ---①
search_dir = '../img/101_ObjectCategories'
# 이미지를 16x16 크기의 평균 해쉬로 변환 ---②
def img2hash(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.resize(gray, (16, 16))
avg = gray.mean()
bi = 1 * (gray > avg)
return bi
# 해밍거리 측정 함수 ---③
def hamming_distance(a, b):
a = a.reshape(1,-1)
b = b.reshape(1,-1)
# 같은 자리의 값이 서로 다른 것들의 합
distance = (a !=b).sum()
return distance
# 권총 영상의 해쉬 구하기 ---④
query_hash = img2hash(img)
min1 = []
# 이미지 데이타 셋 디렉토리의 모든 영상 파일 경로 ---⑤
img_path = glob.glob(search_dir+'/**/*.jpg')
for path in img_path:
# 데이타 셋 영상 한개 읽어서 표시 ---⑥
img = cv2.imread(path)
cv2.imshow('searching...', img)
cv2.waitKey(5)
# 데이타 셋 영상 한개의 해시 ---⑦
a_hash = img2hash(img)
# 해밍 거리 산출 ---⑧
dst = hamming_distance(query_hash, a_hash)
if dst/256 < 0.25: # 해밍거리 25% 이내만 출력 ---⑨
print(path, dst/256)
min1.append(dst/256)
cv2.imshow(path, img)
cv2.destroyWindow('searching...')
cv2.waitKey(0)
cv2.destroyAllWindows()
print(min(min1))

해밍 거리가 25% 이내에 있는 영상만 그 파일의 이름으로 새 창을 띄워 보여준 모습입니다. 대부분 권총이 출력된 것을 볼 수 있지만 망원경, 사람 얼굴 등과 같은 틀린 영상 검출도 존재합니다.
위 예제는 영상의 특징을 하나의 숫자로 변환했지만, 회전, 크기, 방향 등에 영향이 없으면서 정확도를 높이려면 특징을 잘 나타내는 여러 개의 지점을 찾아 그 특징을 잘 표현하고 서술할 수 있는 여러 개의 숫자들로 변환해야 하는데 이것을 키 포인트(key point)와 특징 디스크립터(feature descriptor)라고 합니다. 또 두 영상의 특징을 비교해서 유사도를 측정하는 과정을 매칭(matching)이라 합니다.
■ 탬플릿 매칭
탬플릿 매칭(template matching)은 어떤 물체가 있는 영상을 준비해 두고 그 물체가 포함되어 있을 것이라고 예상할 수 있는 입력 영상과 비교해서 물체가 매칭 되는 위치를 찾는 것입니다. 이때 미리 준비해 둔 영상을 탬플릿 영상이라고 하며, 이것을 입력 영상에서 찾는 것이므로 탬플릿 영상은 입력 영상보다 크기가 항상 작아야 합니다.
- result = cv2.matchTemplate(img, templ, method, [, result, mask])
- img: 입력 영상
- templ: 템플릿 영상
- method: 매칭 메서드
- cv2.TM_SQDIFF: 제곱 차이 매칭, 완벽 매칭: 0, 나쁜 매칭: 큰 값
- R(x, y) = Σ_(x', y') (T(x', y') - I(x + x', y + y'))^2
- cv2.TM_SQDIFF_NORMED: 제곱 차이 매칭의 정규화
- cv2.TM_CCORR: 상관관계 매칭, 완벽 매칭: 큰 값, 나쁜 매칭: 0
- R(x, y) = Σ_(x', y') (T(x', y') * I(x + x', y + y'))^2
- cv2.TM_CCORR_NORMED: 상관관계 매칭의 정규화
- cv2.TM_CCOEFF: 상관계수 매칭, 완벽 매칭: 1, 나쁜 매칭: -1
- cv2.TM_CCOEFF_NORMED: 상관계수 매칭의 정규화
- cv2.TM_SQDIFF: 제곱 차이 매칭, 완벽 매칭: 0, 나쁜 매칭: 큰 값
- result: 매칭 결과, (W - w + 1) * (H - h + 1) 크기의 2차원 배열
- W, H: img의 열과 행
- w, h: tmpl의 열과 행
- mask: TM_SQDIFF, TM_CCORR_NORMED인 경우 사용할 마스크
- minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(src [, mask])
- src: 입력 1채널 배열
- minVal, maxVal: 배열 전체에서 최소 값, 최대 값
- minLoc, maxLoc: 최소 값과 최대 값의 좌표 (x, y)
cv2.matchTemplate() 함수는 입력 영상 img에서 templ 인자의 영상을 슬라이딩하면서 주어진 메서드에 따라 매칭을 수행합니다. 유클리드 거리를 변형한 형태의 제곱 차, 상관관계, 상관계수 매칭이라는 세 가지 메서드와 각각의 메서드를 정규화한 세 가지 메서드, 모두 여섯 가지의 메서드를 제공합니다. 함수의 결과는 img의 크기에서 templ 크기를 뺀 것에 1만큼 큰 2차원 배열을 result로 얻는데, 이 배열의 최대, 최소 값을 구하면 원하는 최선의 매칭 값과 매칭점을 찾을 수 있습니다. 이를 도와주는 함수가 cv2.minMaxLoc()입니다.
import cv2
import numpy as np
# 입력이미지와 템플릿 이미지 읽기
img = cv2.imread('../img/figures.jpg')
template = cv2.imread('../img/taekwonv1.jpg')
th, tw = template.shape[:2]
cv2.imshow('template', template)
# 3가지 매칭 메서드 순회
methods = ['cv2.TM_CCOEFF_NORMED', 'cv2.TM_CCORR_NORMED', \
'cv2.TM_SQDIFF_NORMED']
for i, method_name in enumerate(methods):
img_draw = img.copy()
method = eval(method_name)
# 템플릿 매칭 ---①
res = cv2.matchTemplate(img, template, method)
# 최대, 최소값과 그 좌표 구하기 ---②
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
print(method_name, min_val, max_val, min_loc, max_loc)
# TM_SQDIFF의 경우 최소값이 좋은 매칭, 나머지는 그 반대 ---③
if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:
top_left = min_loc
match_val = min_val
else:
top_left = max_loc
match_val = max_val
# 매칭 좌표 구해서 사각형 표시 ---④
bottom_right = (top_left[0] + tw, top_left[1] + th)
cv2.rectangle(img_draw, top_left, bottom_right, (0,0,255),2)
# 매칭 포인트 표시 ---⑤
cv2.putText(img_draw, str(match_val), top_left, \
cv2.FONT_HERSHEY_PLAIN, 2,(0,255,0), 1, cv2.LINE_AA)
cv2.imshow(method_name, img_draw)
cv2.waitKey(0)
cv2.destroyAllWindows()
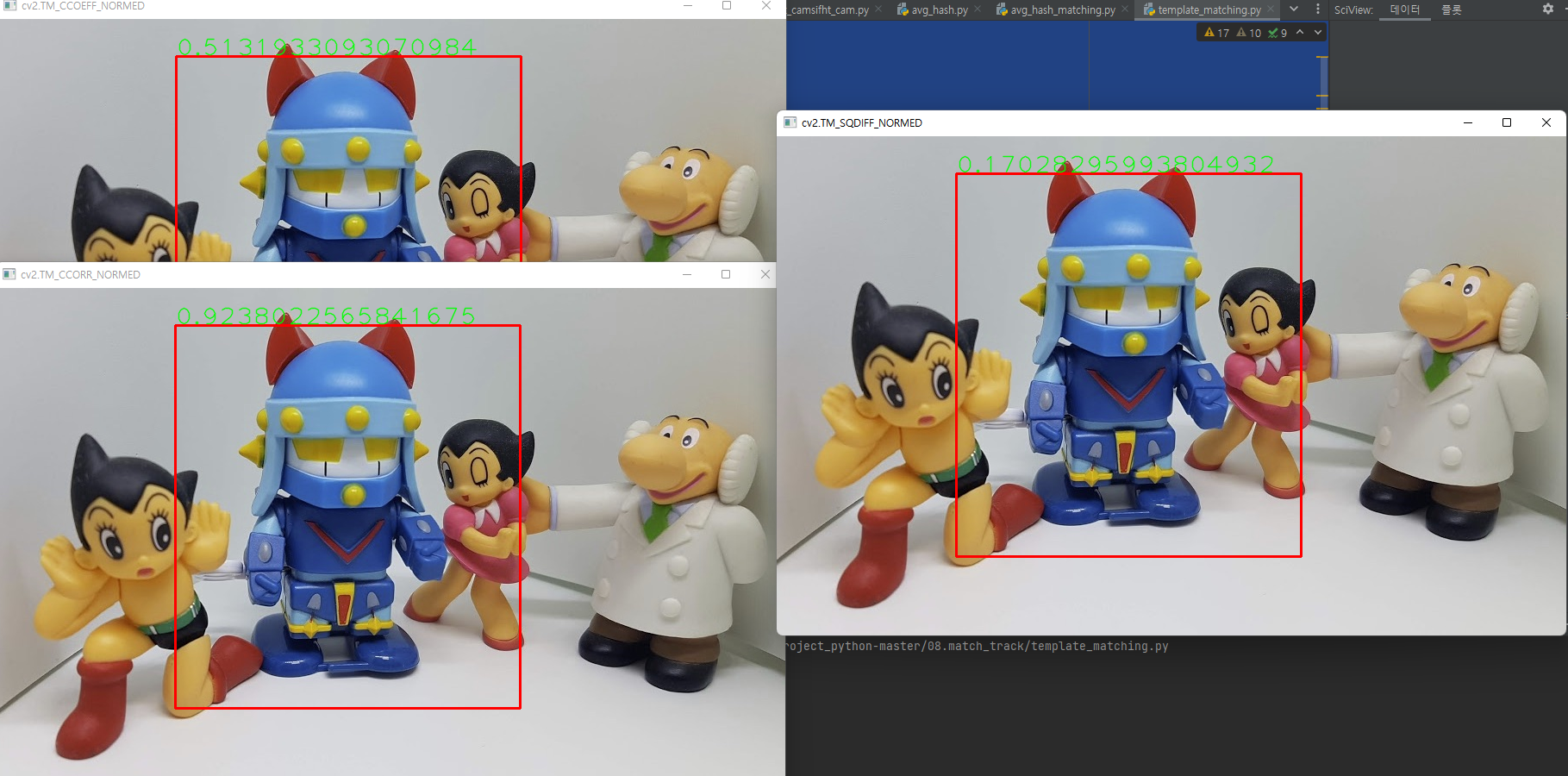
정규화된 세 가지 매칭 메서드만을 이용해서 템플릿 매칭을 각각 수행합니다. 템플릿 매칭은 크기, 방향, 회전 등의 변화에는 잘 검출되지 않고 속도가 느리다는 단점이 있습니다.
8.2 영상의 특징과 키 포인트
지금까지 다룬 특징 추출과 매칭 방법은 영상 전체를 전역적으로 반영하는 방법입니다. 전역적 매칭은 비교하려는 두 영상의 내용이 거의 대부분 비슷해야 하며, 다른 물체에 가려지거나 회전이나 방향, 크기 변화가 있으면 효과가 없습니다. 그래서 지역적 특징방법이 필요합니다.
■ 코너 특징 검출
사람은 영상 속 내용을 판단할 때 주로 픽셀의 변화가 심한 곳에 중점적으로 관심을 둡니다. 특히 엣지와 엣지가 만나는 코너(corner)에 가장 큰 관심을 두게 됩니다.
코너를 검출하기 위한 방법으로는 크리스 해리스(Chris Harris)의 논문에서 처음 소개된 해리스 코너 검출(Harris corner detection)이 원조격입니다. 해리스 코너 검출은 소벨(Sobel) 미분으로 엣지를 검출하면서 엣지의 경사도 변화량을 측정하여 변화량이 x축과 y축 모든 방향으로 크게 변화하는 것을 코너로 판단합니다.
- dst = cv2.cornerHarris(src, blockSize, ksize, k [, dst, borderType])
- src: 입력 영상, 그레이 스케일
- blockSize: 아웃 픽셀 범위
- ksize: 소벨 미분 커널 크기
- k: 코너 검출 상수, 경험적 상수(0.04 ~ 0.06)
- dst: 코너 검출 결과
- src와 같은 크기의 1채널 배열, 변화량의 값, 지역 최대 값이 코너점을 의미
- borderType: 외곽 영역 보정 형식
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # gray scale로 읽음
# 해리스 코너 검출 ---①
corner = cv2.cornerHarris(gray, 2, 3, 0.04)
# 변화량 결과의 최대값 10% 이상의 좌표 구하기 ---②
coord = np.where(corner > 0.1* corner.max())
coord = np.stack((coord[1], coord[0]), axis=-1)
# 코너 좌표에 동그리미 그리기 ---③
for x, y in coord:
cv2.circle(img, (x,y), 5, (0,0,255), 1, cv2.LINE_AA)
# 변화량을 영상으로 표현하기 위해서 0~255로 정규화 ---④
corner_norm = cv2.normalize(corner, None, 0, 255, cv2.NORM_MINMAX, cv2.CV_8U)
# 화면에 출력
corner_norm = cv2.cvtColor(corner_norm, cv2.COLOR_GRAY2BGR)
merged = np.hstack((corner_norm, img))
cv2.imshow('Harris Corner', merged)
cv2.waitKey()
cv2.destroyAllWindows()

코너 검출을 실행하고 그 결과에서 최대 값의 10% 이상인 좌표에만 빨간색 동그라미를 그린 결과입니다. cv2.cornerHarris() 함수의 결과는 입력 영상과 같은 크기의 1차원 배열로 지역 최대 값이 코너를 의미합니다. 왼쪽 그림은 코너 검출 결과를 255로 normalize 해서 영상으로 표시한 결과입니다. 동그라미로 표시된 코너 지점이 가장 밝은 것을 알 수 있습니다.
시(Shi)와 토마시(Tomasi)는 논문을 통해 해리스 코너 검출을 개선한 알고리즘을 발표했는데, 이 방법으로 검출한 코너는 객체 추적에 좋은 특징이 된다고 하며 이를 OpenCV는 cv2.goodFeaturesToTrack() 함수로 제공합니다.
- corners = cv2.goodFeaturesToTrack(img, maxCorners, qualityLevel, minDistance [, corners, mask, blockSize, useHarrisDetector, k])
- img: 입력 영상
- maxCorners: 얻고 싶은 코너 개수, 강한 것 순
- qualityLevel: 코너로 판단할 스레스홀드 값
- minDistance: 코너 간 최소 거리
- mask: 검출에 제외할 마스크
- blockSize = 3: 코너 주변 영역의 크기
- useHarrisDetector = False: 코너 검출 방법 선택
- True = 해리스 코너 검출 방법, False = 시와 토마시 검출 방법
- k: 해리스 코너 검출 방법에 사용할 k 계수
- corners: 코너 검출 좌표 결과, N x 1 x 2 크기의 배열, 실수 값이므로 정수로 변형 필요
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 시-토마스의 코너 검출 메서드
corners = cv2.goodFeaturesToTrack(gray, 80, 0.01, 10)
# 실수 좌표를 정수 좌표로 변환
corners = np.int32(corners)
# 좌표에 동그라미 표시
for corner in corners:
x, y = corner[0]
cv2.circle(img, (x, y), 5, (0,0,255), 1, cv2.LINE_AA)
cv2.imshow('Corners', img)
cv2.waitKey()
cv2.destroyAllWindows()

cv2.goodFeaturesToTrack() 함수는 useHarrisDetector 인자에 True 값을 전달하면 해리스 코너 검출 방법을 사용하고 그렇지 않으면 시-토마시의 코너 검출 방법을 사용합니다. 결과 값은 코너의 좌표 개수만큼 1 x 2 크기로 구성되어 있어서 코너의 좌표를 알기 쉽습니다.
■ 키 포인트와 특징 검출기
영상에서 특징점을 찾아내는 알고리즘은 무척 다양하고 각각 특징점은 픽셀의 좌표 이외에도 표현할 수 있는 정보가 많습니다. OpenCV는 여러 특징점 검출 알고리즘 중 어떤 것을 사용하든 간에 동일한 코드로 특징점을 검출할 수 있게 하려고 각 알고리즘 구현 클래스가 추상 클래스를 상속받는 방법으로 인터페이스를 통일했습니다.
OpenCV는 모든 특징 검출기를 cv2.Feature2D 클래스를 상속받아 구현했으며, 이것으로부터 추출된 특징점은 cv2.KeyPoint라는 객체에 담아 표현했습니다. OpenCV에서 cv2.Feature2D를 상속받아 구현된 특징 검출기는 모두 12가지이며, 목록은 https://docs.opencv.org/3.4.1/d0/d13/classcv_1_1Feature2D.html 에서 확인 가능합니다.
OpenCV: cv::Feature2D Class Reference
Abstract base class for 2D image feature detectors and descriptor extractors. More... Abstract base class for 2D image feature detectors and descriptor extractors.
docs.opencv.org
cv2.Feature2D를 상속받은 특징 검출기는 detect() 함수를 구현하고 있고 이 함수는 특징점의 좌표와 추가 정보를 담은 cv2.KeyPoint 객체를 리스트에 담아 반환합니다.
- Keypoints = detector.detect(img, [, masl]): 키 포인트 검출 함수
- img: 입력 영상, 바이너리 스케일
- mask: 검출 제외 마스크
- keypoints: 특징점 검출 결과, KeyPoint의 리스트
- KeyPoint: 특징점 정보를 담는 객체
- pt: 키 포인트(x, y) 좌표, float 타입으로 정수로 변환 필요
- size: 의미 있는 키 포인트 이웃의 반지름
- angle: 특징점 방향(시계방향, -1 = 의미 없음)
- response: 특징점 반응 강도(추출기에 따라 다름)
- octave: 발견된 이미지 피라미드 계층
- class_id: 키 포인트가 속한 객체 ID
키 포인트의 속성 중에 특징점의 좌표 정보인 pt는 항상 값을 갖지만 나머지 속성은 사용하는 검출기에 따라 채워지지 않는 경우도 있습니다. 검출한 키 포인트를 표시하고 싶을 때는 앞선 예제의 cv2.circle() 함수로 pt의 좌표에 그려줄 수 있지만 OpenCV는 키 포인트를 영상에 표시해 주는 전용 함수를 제공합니다.
- outImg = cv2.drawKeypoints(img, keypoints, outImg [, color [, flags]])
- img: 입력 이미지
- keypoints: 표시할 키 포인트 리스트
- outImg: 키 포인트가 그려진 결과 이미지
- color: 표시할 색상(기본 값: 랜덤)
- flags: 표시 방법 선택 플래그
- cv2.DRAW_MATCHES_FLAGS_DEFAULT: 좌표 중심에 동그라미만 그림(기본 값)
- cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 동그라미의 크기를 size와 angle을 반영해서 그림
■ GFTTDetector
GFTTDetector는 앞서 본 cv2.goodFeaturesToTrack() 함수로 구현된 특징 검출기입니다. 검출기 생성 방법만 다르고 검출에 사용되는 함수는 cv2.Feature2D의 detect() 함수와 같습니다.
- detector = cv2.GFTTDetector_create([, maxCorners [, qualityLevel, minDistance, blockSize, useHarrisDetector, k]])
- 인자의 모든 내용은 cv2.goodFeaturesToTrack()과 동일
import cv2
import numpy as np
img = cv2.imread("../img/house.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Good feature to trac 검출기 생성 ---①
gftt = cv2.GFTTDetector_create(useHarrisDetector = False)
# 키 포인트 검출 ---②
keypoints = gftt.detect(gray, None)
# 키 포인트 그리기 ---③
img_draw = cv2.drawKeypoints(img, keypoints, None)
# 결과 출력 ---④
cv2.imshow('GFTTDectector', img_draw)
cv2.waitKey(0)
cv2.destroyAllWindows()
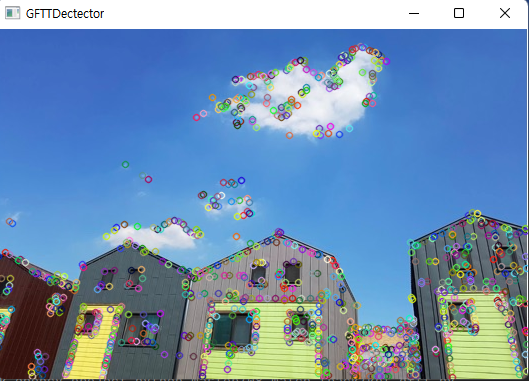
GFTTDetector로 검출한 키 포인트를 영상에 그려서 출력한 모습입니다. cv2.GFTTDetector_create() 함수로 default 값 그대로 시-토마시 알고리즘을 사용하는 검출기를 생성하고, 키 포인트를 검출해 그렸습니다.
■ FAST
FAST(Feature from Accelerated Segment Test)는 이름에서 알 수 있듯이, 속도를 개선한 알고리즘입니다. 2006년 에드워드 로스텐(Edward Rosten)과 톰 드러먼드(Tom Drummond)의 논문에 소개된 이 알고리즘은 코너를 검출할 때 미분 연산으로 엣지 검출을 하지 않고 픽셀을 중심으로 특정 개수의 픽셀로 원을 그려서 그 안의 픽셀들이 중심 픽셀보다 임계 값 이상 밝거나 어두운 것이 특정 개수 이상 연속되면 코너로 판단합니다.
- detector = cv2.FastFeatureDetector_create([threshold [, nonmaxSuppression, type])
- threshold = 10: 코너 판단 임계값
- nonmaxSuppression = True: 최대 점수가 아닌 코너 억제
- type: 엣지 검출 패턴
- cv2.FastFeatureDetector_TYPE_9_16: 16 개 중 9개 연속(기본 값)
- cv2.FastFeatureDetector_TYPE_7_12: 12개 중 7개 연속
- cv2.FastFeatureDetector_TYPE_5_8: 8개 중 5개 연속
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# FASt 특징 검출기 생성 ---①
fast = cv2.FastFeatureDetector_create(50)
# 키 포인트 검출 ---②
keypoints = fast.detect(gray, None)
# 키 포인트 그리기 ---③
img = cv2.drawKeypoints(img, keypoints, None)
# 결과 출력 ---④
cv2.imshow('FAST', img)
cv2.waitKey()
cv2.destroyAllWindows()

■ SimpleBlobDetector
BLOB(Binary Large Object)는 바이너리 스케일 이미지의 연결된 픽셀 그룹을 말하는 것으로, 자잘한 객체는 노이즈로 판단하고 특정 크기 이상의 큰 객체에만 관심을 두는 방법입니다. BLOB는 코너를 이용한 특징 검출과는 방식이 다르지만 영상의 특징을 표현하기 좋은 또 하나의 방법입니다.
- detector = cv2.SimpleBlobDetector_create( [parameters] ): BLOB 검출기 생성자
- parameters: BLOB 검출 필터 인자 객체
- cv2.SimpleBlobDetector_Params()
- minThreshold, maxThreshold, thresholdStep: BLOB를 생성하기 위한 경계 값(minThreshold에서 maxThreshold를 넘지 않을 때까지 ThresholdStep만큼 증가)
- minRepeatability: BLOB에 참여하기 위한 연속된 경계 값 개수
- minDistBetweenBlobs: 두 BLOB를 하나의 BLOB로 간주한 거리
- filterByArea: 면적 필터 옵션
- minArea, maxArea: min ~ max 범위의 면적만 BLOB로 검출
- filterByCircularity: 원형 비율 필터 옵션
- minCircularity, maxCircularity: min ~ max 범위의 원형 비율만 BLOB로 검출
- filterByColor: 밝기를 이용한 필터 옵션
- blobColor: 0 = 검은색 BLOB 검출, 255 = 흰색 BLOB 검출
- filterByConvexity: 볼록 비율 필터 옵션
- minConvexity, maxConvexity: min ~ max 범위의 볼록 비율만 BLOB로 검출
- filterByInertia: 관성 비율 필터 옵션
- minInertiaRatio, maxInertiaRatio: min ~ max 범위의 관성 비율만 BLOB로 검출
SimpleBlobDetector는 단순히 객체 생성 함수를 호출하여 사용할 수도 있지만, BLOB 검출 필터 인자 객체에 여러 가지 옵션을 전달해서 원하는 BLOB만 골라서 검출할 수도 있습니다.
import cv2
import numpy as np
img = cv2.imread("../img/house.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# SimpleBlobDetector 생성 ---①
detector = cv2.SimpleBlobDetector_create()
# 키 포인트 검출 ---②
keypoints = detector.detect(gray)
# 키 포인트를 빨간색으로 표시 ---③
img = cv2.drawKeypoints(img, keypoints, None,(0,0,255),\
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow("Blob", img)
cv2.waitKey(0)

SimpleBlobDetector를 기본 값으로 생성해서 BLOB를 검출한 결과로 창문에 몇 개 동그라미가 그려진 모습입니다.
import cv2
import numpy as np
img = cv2.imread("../img/house.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# blob 검출 필터 파라미터 생성 ---①
params = cv2.SimpleBlobDetector_Params()
# 경계값 조정 ---②
params.minThreshold = 10
params.maxThreshold = 240
params.thresholdStep = 5
# 면적 필터 켜고 최소 값 지정 ---③
params.filterByArea = True
params.minArea = 200
# 컬러, 볼록 비율, 원형비율 필터 옵션 끄기 ---④
params.filterByColor = False
params.filterByConvexity = False
params.filterByInertia = False
params.filterByCircularity = False
# 필터 파라미터로 blob 검출기 생성 ---⑤
detector = cv2.SimpleBlobDetector_create(params)
# 키 포인트 검출 ---⑥
keypoints = detector.detect(gray)
# 키 포인트 그리기 ---⑦
img_draw = cv2.drawKeypoints(img, keypoints, None, None,\
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 결과 출력 ---⑧
cv2.imshow("Blob with Params", img_draw)
cv2.waitKey(0)

이번에는 SimpleBlobDetector 객체를 필터 옵션 개게를 이용해서 생성했습니다.
8.3 디스크립터 추출기
■ 특징 디스크립터와 추출기
키 포인트는 영상의 특징이 있는 픽셀의 좌표와 그 주변 픽셀과의 관계에 대한 정보를 가집니다. 그중 가장 대표적인 것이 size와 angle 속성으로, 코너 특징인 경우 엣지의 경사도 규모와 방향을 나타냅니다. 특징을 나타내는 값을 매칭에 사용하기 위해서는 회전, 크기, 방향 등에 영향이 없어야 하는데, 이를 위해 특징 디스크립터(feature descriptor)가 필요합니다. 특징 디스크립터는 키 포인트 주변 픽셀을 일정한 크기의 블록으로 나누어 각 블록에 속한 픽셀의 그레디언트 히스토그램을 계산한 것으로, 키 포인트 주위의 밝기, 색상, 방향, 크기 등의 정보를 표현한 것입니다. 표현하는 방법은 다양한데 일반적으로는 키 포인트에 적용하는 주변 블록의 크기에 8방향의 경사도를 표현하는 형태로 사용합니다. OpenCV는 특징 디스크립터를 추출하기 위한 방법으로 통일된 인터페이스를 제공하기 위해 특징 검출기와 같은 cv2.feature2D 클래스를 상속받아 구현했습니다.
- Keypoints, descriptors = detector.detectAndCompute(image, mask [, descriptors, useProvidedKeypoints]): 키 포인트 검출과 특징 디스크립터 게산을 한 번에 수행
- image: 입력 영상
- keypoints: 디스크립터 계산을 위해 사용할 키 포인트
- descriptors: 계산된 디스크립터
- mask: 키 포인트 검출에 사용할 마스크
- useProvidedKeypoints: True인 경우 키 포인트 검출을 수행하지 않음(사용 안함)
GFTTDetector와 SimpleBlobDetector는 compute()와 detectAndCompute()가 구현되어 있지 않습니다.
■ SIFT
SIFT(Scale-Invariant Feature Transform)는 이미지 피라미드를 이용해서 크기 변화에 따른 특징 검출의 문제를 해결한 알고리즘입니다.
- detector = cv2.xfeatures2d.SIFT_create([, nfeatures [, nOctaveLayers [, contrastThreshold [, edge Threshold [, sigma]]]]])
- nfeatures: 검출 최대 특징 수
- nOctaveLayers: 이미지 피라미드에 사용할 계층 수
- contrastThreshold: 필터링할 빈약한 특징 문턱 값
- edgeThreshold: 필터링할 엣지 문턱 값
- sigma: 이미지 피라미드 0 계층에서 사용할 가우시안 필터의 시그마 값
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# SIFT 추출기 생성
sift = cv2.xfeatures2d.SIFT_create()
# sift = cv2.SIFT_create()
# 키 포인트 검출과 서술자 계산
keypoints, descriptor = sift.detectAndCompute(gray, None)
print('keypoint:',len(keypoints), 'descriptor:', descriptor.shape)
print(descriptor)
# 키 포인트 그리기
img_draw = cv2.drawKeypoints(img, keypoints, None, \
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 결과 출력
cv2.imshow('SIFT', img_draw)
cv2.waitKey()
cv2.destroyAllWindows()

SIFT를 이용한 키 포인트와 디스크립터를 계산해서 결과 화면에 표시하고 디스크립터의 크기와 일부 데이터를 출력한 모습입니다.
■ SURF
SIFT는 크기 변화에 따른 특징 검출 문제를 해결하기 위해 이미지 피라미드를 사용하므로 속도가 느리다는 단점이 있습니다. SURF(Speeded Up Robust Features)는 이미지 피라미드 대신 필터의 커널 크기를 바꾸는 방식으로 성능을 개선한 알고리즘입니다.
- detector = cv2.xfeatures2d.SURF_create([hessianThreshold, nOctaves, nOctaveLayers, extended, upright])
- hessianThreshold: 특징 추출 경계 값(100)
- nOctaves: 이미지 피라미드 계층 수(3)
- extended: 디스크립터 생성 플래그(False), True: 128개, False: 64개
- upright: 방향 계산 플래그(False), True: 방향 무시, False: 방향 적용
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# SURF 추출기 생성 ( 경계:1000, 피라미드:3, 서술자확장:True, 방향적용:True)
surf = cv2.xfeatures2d.SURF_create(1000, 3, extended = True, upright = True)
# 키 포인트 검출 및 서술자 계산
keypoints, desc = surf.detectAndCompute(gray, None)
print(desc.shape, desc)
# 키포인트 이미지에 그리기
img_draw = cv2.drawKeypoints(img, keypoints, None, \
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imshow('SURF', img_draw)
cv2.waitKey()
cv2.destroyAllWindows()
■ ORB
ORB(Oriented and Rotated BRIEF)는 특징 검출을 지원하지 않는 디스크립터 추출기인 BRIEF(Binary Robust Independent Elementary features)에 방향과 회전을 고려하도록 개선한 알고리즘입니다. 에단 루블리(Ethan Rublee) 등의 논문에서 소개된 이 알고리즘은 특징 검출 알고리즘으로 FAST를 사용하고 회전과 방향을 고려하지 않은 디스크립터 알고리즘인 BRIEF를 개선하고 회전과 방향에 영향을 받지 않으면서도 속도가 빨라서 SIFT와 SURF의 좋은 대안으로 사용됩니다.
- detector = cv2.ORB_create([nfeatures, scaleFactor, nlevels, edgeThreshold, firstLevel, WTA_K. scoreType, patchSize, fastThreshold])
- nfeatures = 500: 검출할 최대 특징 수
- scaleFactor = 1.2: 이미지 피라미드 비율
- nlevels = 8: 이미지 피라미드 계층 수
- edgeThreshold = 31: 검색에서 제외할 테두리 크기, patchSize와 맞출 것
- firstLevel = 0: 최초 이미지 피라미드 계층 단계
- WTA_K = 2: 임의 좌표 생성 수
- scoreType: 키 포인트 검출에 사용할 방식
- cv2.ORB_HARRIS_SCORE: 해리스 코너 검출(기본 값)
- cv2.ORB_FAST_SCORE: FAST 코너 검출
- patchSize = 31: 디스크립터의 패치 크기
- fastThreshold = 20: Fast에 사용할 임계 값
cv2.ORB_HARRIS_SCORE가 기본 값인데, FAST 알고리즘으로 검출한 코너를 해리스 코너 검출 알고리즘으로 다시 점수를 매겨서 최상의 특징점을 검출하므로 속도가 느릴 수 있습니다. 이때는 cv2.ORB_FAST_SCORE를 지정하면 속도를 높일 수 있으나 잘못된 특징점이 검출될 수 있습니다.
import cv2
import numpy as np
img = cv2.imread('../img/house.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# ORB 추출기 생성
orb = cv2.ORB_create()
# 키 포인트 검출과 서술자 계산
keypoints, descriptor = orb.detectAndCompute(img, None)
# 키 포인트 그리기
img_draw = cv2.drawKeypoints(img, keypoints, None, \
flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# 결과 출력
cv2.imshow('ORB', img_draw)
cv2.waitKey()
cv2.destroyAllWindows()

8.4 특징 매칭
특징 매칭(featuer matching)이란 서로 다른 두 영상에서 구한 키 포인트와 특징 디스크립터들을 각각 비교해서 그 거리가 비슷한 것끼리 짝짓는 것을 말합니다. 짝지어진 특징점들 중에 거리가 유의미한 것들을 모아서 대칭점으로 표시하면 그 개수에 따라 두 영상이 얼마나 비슷한지 측정할 수 있고 충분히 비슷한 영상이라면 비슷한 모양의 영역을 찾아낼 수도 있습니다.
■ 특징 매칭 인터페이스
OpenCV는 특징 매칭에 사용하는 여러 가지 알고리즘을 통일된 인터페이스로 제공하기 위해 모든 특징 매칭 알고리즘을 추상 클래스인 cv2.DescriptorMatcher를 상속받아 구현했습니다. 매칭 결과는 cv2.DMatch 객체에 담아 반환합니다.
- matcher = cv2.DescriptorMatcher_create(matcherType): 매칭기 생성자
- matcherType: 생성할 구현 클래스의 알고리즘, 문자열
- "BruteForce": NORM_L2를 사용하는 BFMatcher
- "BruteForce-L1": NORM_L1을 사용하는 BFMatcher
- "BruteForce-Hamming": NORM_HAMMING을 사용하는 BFMatcher
- "BruteForce-Hamming(2)": NORM_HAMMING2를 사용하는 BFMatcher
- "FlannBased": NORM_L2를 사용하는 FlannBasedMatcher
- matcherType: 생성할 구현 클래스의 알고리즘, 문자열
- matches = matcher.match(queryDescriptors, trainDescriptors [, mask]): 3개의 최적 매칭
- queryDescriptor: 특징 디스크립터 배열, 매칭의 기준이 될 디스크립터
- trainDescriptor: 특징 디스크립터 배열, 매칭의 대상이 될 디스크립터
- mask: 매칭 진행 여부 마스크
- matches: 매칭 결과, DMatch 객체의 리스트
- matches = matcher.knnMatch(queryDescriptors, trainDescriptors, k [, mask [, compactResult]]): k개의 가장 근접한 매칭
- k: 매칭할 근접 이웃 개수
- compactResult = False: True: 매칭이 없는 경우 매칭 결과에 불포함
- matches = matcher.radiusMatch(queryDescriptors, trainDescriptors, maxDistance [, mask, compactResult]): maxDistance 이내의 거리 매칭
- maxDistance: 매칭 대상 거리
- DMatch: 매칭 결과를 표현하는 객체
- queryIdx: queryDescriptor인 인덱스
- trainIdx: trainDescriptor인 인덱스
- imgIdx: trainDescriptor의 이미지 인덱스
- distance: 유사도 거리
- cv2.drawMatches(img1, kp1, img2, kp2, matches, flags): 매칭점을 영상에 표시
- img1, kp1: queryDescriptor의 영상과 키 포인트
- img2, kp2: trainDescriptor의 영상과 키 포인트
- matches: 매칭 결과
- flags: 매칭점 그리기 옵션
- cv2.DRAW_MATCHES_FLAGS_DEFAULT: 결과 이미지 새로 생성(기본 값)
- cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG: 결과 이미지 새로 생성 안 함
- cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS: 키 포인트 크기와 방향도 그리기
- cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS: 한쪽만 있는 매칭 결과 그리기 제외
BFMatcher와 FLannBasedMatcher로 특징 매칭기를 만들어도 되지만 cv2.DescriptorMatcher_create()에 원하는 매칭 알고리즘과 거리 계산 알고리즘을 나타내는 문자열을 전달해서 생성할 수 있습니다. 경우에 따라 queryDescriptor와 trainDescriptor 간에 최적 매칭을 찾지 못하는 경우도 있어서 결과 매칭의 개수는 queryDescriptor의 개수보다 적을 수 있습니다.
knnMatch() 함수는 queryDescriptor 한 개당 k 인자에 전달한 최근접 이웃 개수만큼 trainDescriptor에서 찾아 결과 매칭에 반영합니다. radiusMatch() 함수는 queryDescriptor에서 maxDistance 이내에 있는 trainDescriptor를 찾아 결과 매칭에 반영합니다. 매칭 결과를 시각적으로 나타내기 위해서는 두 영상을 하나로 합쳐서 두 매칭점의 좌표를 선으로 연결하는 작업이 필요한데, cv2.drawMatches() 함수는 이 작업을 대신해줍니다.
■ BFMacher
Brute-Force 매칭기는 queryDescriptor와 trainDescriptor를 일일이 전수조사해서 매칭하는 알고리즘으로 OpenCV는 cv2.BFMatcher 클래스로 제공합니다. 이 클래스에서 객체를 생성하려면 추상 클래스의 생성 함수인 cv2.DescriptorMatcher_create()로도 가능하지만 직정 생성할 수도 있습니다.
거리 측정 알고리즘은 세 가지 유클리드 거리와 두 가지 해밍 거리 중에 선택할 수 있는데, SIFT와 SURF로 추출할 디스크립터의 경우 NORM_L1, NORM_L2가 적합하고 ORB는 NORM_HAMMING가 적합하며, NORM_HAMMING2는 ORB의 WTA_K가 3이나 4인 경우에 적합합니다. crossCheck를 True로 설정하면 양쪽 디스크립터 모두에게서 매칭이 완성된 것만 반영하므로 불필요한 매칭을 줄일 수 있지만 그만큼 속도가 느려집니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 서술자 추출기 생성 ---①
detector = cv2.SIFT_create()
# detector = cv2.xfeatures2d.SIFT_create()
# 각 영상에 대해 키 포인트와 서술자 추출 ---②
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, L1 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_L1, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 결과 출력
cv2.imshow('BFMatcher + SIFT', res)
cv2.waitKey()
cv2.destroyAllWindows()

SIFT 추출기를 생성하고 두 영상의 키 포인트와 디스크립터를 각각 추출합니다. BFMatcher 객체를 생성하면서 L1 거리 알고리즘과 상호 체크 옵션을 지정해 사용한 코드입니다.
import cv2
import numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SURF 서술자 추출기 생성 ---①
detector = cv2.xfeatures2d.SURF_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, L2 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_L2, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('BF + SURF', res)
cv2.waitKey()
cv2.destroyAllWindows()
위 코드는 SURF를 사용했습니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 서술자 추출기 생성 ---①
detector = cv2.ORB_create()
# 각 영상에 대해 키 포인트와 서술자 추출 ---②
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BFMatcher 생성, Hamming 거리, 상호 체크 ---③
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 결과 그리기 ---⑤
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('BFMatcher + ORB', res)
cv2.waitKey()
cv2.destroyAllWindows()
위 코드는 ORB를 사용한 코드입니다.
■ FLANN
BFMatcher는 특징 디스크립터를 전수 조사하므로 매칭에 사용할 영상이 큰 경우 속도가 느려지는데 이때 FLANN을 사용할 수 있습니다. FLANN(Fast Library for Approximate Nearest Neighbors Matching)은 모든 특징 디스크립터를 비교하기보다는 가장 가까운 이웃의 근사 값으로 매칭합니다. OpenCV는 cv2.FlannBasedmatcher 클래스로 FLANN을 구현했는데 플래그 상수 선언이 모두 빠져 있어서 객체의 멤버 변수에 할당하는 대신 파이썬 딕셔너리 객체의 키와 값으로 입력해서 생성자에 각각 전달해야 합니다.
- matcher = cv2.FlannBasedMatcher([indexParams [, searchParams]])
- indexParams: 인덱스 파라미터, 딕셔너리
- algorithm: 알고리즘 선택 키, 선택한 키에 따라 종석 키 결정
- FLANN_INDEX_LINEAR = 0: 선형 인덱싱, BFMatcher와 동일
- FLANN_INDEX_KDTREE = 1: KD-트리 인덱싱
- trees = 4: 트리 개수(16을 권장)
- FLANN_INDEX_KMEANS = 2: K 평균 트리 인덱싱
- branching = 32: 트리 분기 계수
- iterations = 11: 반복 수
- centers_init = 0: 초기 중심점 방식
- FLANN_CENTERS_RANDOM = 0
- FLANN_CENTERS_GONZALES = 1
- FLANN_CENTERS_KMEANSPP = 2
- FLANN_CENTERS_GROUPWISE = 3
- FLANN_INDEX_COMPOSITE = 3: KD 트리, K 평균 혼합 인덱싱
- trees = 4: 트리 개수
- branching = 32: 트리 분기 계수
- iterations = 11: 반복 수
- centers_init = 0: 초기 중심점 방식
- FLANN_INDEX_LSH = 6: LSH 인덱싱
- table_number: 해시 테이블 수
- key_size: 키 비트 크기
- multi_probe_level: 인접 버킷 검색
- FLANN_INDEX_AUTOTUNED = 255: 자동 인덱스
- target_precision = 0.9: 검색 백분율
- build_weight = 0.01: 속도 우선순위
- memory_weight = 0.0: 메모리 우선순위
- sample_fraction = 0.1: 샘플 비율
- searchParams: 검색 파라미터, 딕셔너리 객체
- checks = 32: 검색할 후보 수
- eps = 0.0: 사용 안 함
- sorted = True: 정렬해서 반환
- algorithm: 알고리즘 선택 키, 선택한 키에 따라 종석 키 결정
- indexParams: 인덱스 파라미터, 딕셔너리
인덱스 파라미터에 값을 조금만 잘못 지정해도 매칭에 실패하고 오류가 발생하므로 FLANN 매칭을 이용하기 위해 인덱스 파라미터를 지정하는 것은 무척 까다로운 일입니다. 그래서 OpenCV 튜토리얼 문서에서는
<SIFT나 SURF를 사용하는 경우>
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
<ORB를 사용하는 경우>
FLANN_INDEX_LSH = 6
index_params = dict(algorithm = FLANN_INDEX_LSH, table_number = 6, key_size = 12, multi_probe_level = 1)위와 같은 인덱스 파라미터를 위한 설정을 권장하고 있습니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 생성
detector = cv2.xfeatures2d.SIFT_create()
# 키 포인트와 서술자 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# 인덱스 파라미터와 검색 파라미터 설정 ---①
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Flann 매처 생성 ---③
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 그리기
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Flann + SIFT', res)
cv2.waitKey()
cv2.destroyAllWindows()
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# SIFT 생성
detector = cv2.xfeatures2d.SIFT_create()
# 키 포인트와 서술자 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# 인덱스 파라미터와 검색 파라미터 설정 ---①
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
# Flann 매처 생성 ---③
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 매칭 계산 ---④
matches = matcher.match(desc1, desc2)
# 매칭 그리기
res = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Flann + SIFT', res)
cv2.waitKey()
cv2.destroyAllWindows()

위 코드는 SIFT로 매칭을 한 코드입니다.
■ 좋은 매칭점 찾기
어떤 디스크립터 추출 알고리즘과 매칭 알고리즘을 선택했든 간에 잘못된 매칭 정보를 너무 많이 포함합니다. 그래서 매칭 결과에서 쓸모없는 매칭점은 버리고 좋은 매칭점만 골라내는 작업이 필요합니다.
cv2.DescriptorMatcher 추상 클래스에는 매칭을 위한 세 가지 함수가 있는데, 그중에 지정된 거리 이내의 매칭점만을 반환하는 radiusMatch() 함수는 maxDistance 값을 조정하는 것 말고는 의미가 없으므로 제외시키고, match()와 knnMatch() 함수에 의한 결과 매칭점들 중에서 좋은 매칭점을 찾는 방법을 사용해야 합니다. match() 함수는 디스크립터 하나당 한 개의 매칭을 반환하므로 매칭점마다 어떤 것은 거리 값이 작고 어떤 것은 크고 하는 식으로 뒤섞여 있으므로 상위 몇 퍼센트만을 골라서 좋은 매칭점으로 분류하면 됩니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# ORB로 서술자 추출 ---①
detector = cv2.ORB_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# BF-Hamming으로 매칭 ---②
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = matcher.match(desc1, desc2)
# 매칭 결과를 거리기준 오름차순으로 정렬 ---③
matches = sorted(matches, key=lambda x:x.distance)
# 최소 거리 값과 최대 거리 값 확보 ---④
min_dist, max_dist = matches[0].distance, matches[-1].distance
# 최소 거리의 15% 지점을 임계점으로 설정 ---⑤
ratio = 0.2
good_thresh = (max_dist - min_dist) * ratio + min_dist
# 임계점 보다 작은 매칭점만 좋은 매칭점으로 분류 ---⑥
good_matches = [m for m in matches if m.distance < good_thresh]
print('matches:%d/%d, min:%.2f, max:%.2f, thresh:%.2f' \
%(len(good_matches),len(matches), min_dist, max_dist, good_thresh))
# 좋은 매칭점만 그리기 ---⑦
res = cv2.drawMatches(img1, kp1, img2, kp2, good_matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 결과 출력
cv2.imshow('Good Match', res)
cv2.waitKey()
cv2.destroyAllWindows()

ORB로 디스크립터를 추출하고 BF-Hamming 매칭기로 매칭을 계산하는 코드입니다. 매칭 결과를 distance를 기준으로 정렬하고 나서 맨 처음 것을 최소 거리, 맨 마지막 것을 최대 거리로 설정하고 최대와 최소 두 지점의 20% 지점을 임계점으로 설정해 good_matches에 따로 보관하는 방식입니다.
knnMatch() 함수로 얻은 매칭은 디스크립터당 k 개의 최근접 이웃 매칭점을 더 가까운 순서대로 반환합니다. k개의 이웃하는 매칭점들 중 거리가 가까운 것은 좋은 매칭점이고 거리가 먼 것은 나쁜 매칭점일 가능성이 큽니다. 이웃 간의 거리 차이가 일정 범위 이내인 것만 골라내면 좋은 매칭점을 얻을 수 있습니다.
■ 매칭 영역 원근 변환
좋은 매칭점으로만 구성된 매칭점 좌표들로 두 영상 간의 원근 변환 행렬을 구하면 찾는 물체가 영상 어디에 있는지 표시할 수 있습니다. 이 과정에서 좋은 매칭점 중에 원근 변환 행렬에 들어맞지 않는 매칭점을 구분할 수 있어서 나쁜 매칭점을 또 한 번 제거할 수 있습니다.
여러 개의 매칭 쌍으로 원근 변환 행렬을 근사해서 찾아주는 함수 cv2.findHomography()가 있습니다. 원래의 좌표들을 변환 행렬로 원근 변환해 주는 함수는 cv2.perspectiveTransform()입니다.
- mtrx, mask = cv2.findHomography(srcPoints, dstPoints [, method [, ransacReprojThreshold [, mask [, maxIters [, confidence]]]]])
- srcPoints: 원본 좌표 배열
- dstPoints: 결과 좌표 배열
- method = 0: 근사 계산 알고리즘 선택
- 0: 모든 점으로 최소 제곱 오차 계산
- cv2.RANSAC
- cv2.LMEDS
- cv2.RHO
- ransacReprojThreshold = 3: 정상치 거리 임계 값(RANSAC, RHO인 경우)
- maxIters = 2000: 근사 계산 반복 횟수
- confidence = 0.995: 신뢰도(0 ~ 1)
- mtrx: 결과 변환 행렬
- mask: 정상치 판별 결과, N x 1 행 배열(0: 비정상치, 1: 정상치)
- dst = cv2.perspectiveTransform(src, m [, dst])
- src: 입력 좌표 배열
- m: 변환 행렬
- dst: 출력 좌표 배열
이 두 함수는 cv2.getPerspectiveTransform()과 cv2.warpPerspective() 함수와 비슷합니다. cv2.findHomography()는 여러 개의 점으로 근사 계산한 원근 변환 행렬을 반환합니다. cv2.warpPerspective()가 주어진 변환 행렬로 입력 이미지의 픽셀 위치를 이동시킨다면 cv2.perspectiveTransform()은 이동할 새로운 좌표 배열을 반환합니다.
알고리즘을 기본 값(0)으로 두면 입력한 모든 좌표를 최소 제곱법으로 근사 계산을 합니다. 모든 점을 만족하는 근사 결과이므로 매칭점에 잘못된 매칭점이 포함되어 있는 경우 오차가 클 수 있습니다.
cv2.RANSAC은 모든 입력점을 사용하지 않고 임의의 점들을 선정해서 만족도를 구하는 것을 반복해서 만족도가 가장 크게 선정된 점들만으로 근사 계산합니다. 선정된 점을 정상치(inlier)로 분류하고 그 외의 점들을 이상치(outlier)로 분류해서 노이즈로 판단합니다.
cv2.LMEDS는 LMedS(Least Median of Squares) 알고리즘으로 제곱의 최소 중간값을 사용합니다. 이 방법은 추가 파라미터를 요구하지 않아 사용하기 편리하지만, 정상치가 50% 이상 있는 경우에만 정상적으로 동작합니다.
cv2.RHO는 RANSAC을 개선한 PROSAC(Progressive Sample Consensus) 알고리즘을 사용합니다. 이 방식은 이상치가 많은 경우 더 빠릅니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# ORB, BF-Hamming 로 knnMatch ---①
detector = cv2.ORB_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
matcher = cv2.BFMatcher(cv2.NORM_HAMMING2)
matches = matcher.knnMatch(desc1, desc2, 2)
# 이웃 거리의 75%로 좋은 매칭점 추출---②
ratio = 0.75
good_matches = [first for first,second in matches \
if first.distance < second.distance * ratio]
print('good matches:%d/%d' %(len(good_matches),len(matches)))
# 좋은 매칭점의 queryIdx로 원본 영상의 좌표 구하기 ---③
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good_matches ])
# 좋은 매칭점의 trainIdx로 대상 영상의 좌표 구하기 ---④
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good_matches ])
# 원근 변환 행렬 구하기 ---⑤
mtrx, mask = cv2.findHomography(src_pts, dst_pts)
# 원본 영상 크기로 변환 영역 좌표 생성 ---⑥
h,w, = img1.shape[:2]
pts = np.float32([ [[0,0]],[[0,h-1]],[[w-1,h-1]],[[w-1,0]] ])
# 원본 영상 좌표를 원근 변환 ---⑦
dst = cv2.perspectiveTransform(pts,mtrx)
# 변환 좌표 영역을 대상 영상에 그리기 ---⑧
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
# 좋은 매칭 그려서 출력 ---⑨
res = cv2.drawMatches(img1, kp1, img2, kp2, good_matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Matching Homography', res)
cv2.waitKey()
cv2.destroyAllWindows()
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# ORB, BF-Hamming 로 knnMatch ---①
detector = cv2.ORB_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
matcher = cv2.BFMatcher(cv2.NORM_HAMMING2)
matches = matcher.knnMatch(desc1, desc2, 2)
# 이웃 거리의 75%로 좋은 매칭점 추출---②
ratio = 0.75
good_matches = [first for first,second in matches \
if first.distance < second.distance * ratio]
print('good matches:%d/%d' %(len(good_matches),len(matches)))
# 좋은 매칭점의 queryIdx로 원본 영상의 좌표 구하기 ---③
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good_matches ])
# 좋은 매칭점의 trainIdx로 대상 영상의 좌표 구하기 ---④
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good_matches ])
# 원근 변환 행렬 구하기 ---⑤
mtrx, mask = cv2.findHomography(src_pts, dst_pts)
# 원본 영상 크기로 변환 영역 좌표 생성 ---⑥
h,w, = img1.shape[:2]
pts = np.float32([ [[0,0]],[[0,h-1]],[[w-1,h-1]],[[w-1,0]] ])
# 원본 영상 좌표를 원근 변환 ---⑦
dst = cv2.perspectiveTransform(pts,mtrx)
# 변환 좌표 영역을 대상 영상에 그리기 ---⑧
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
# 좋은 매칭 그려서 출력 ---⑨
res = cv2.drawMatches(img1, kp1, img2, kp2, good_matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
cv2.imshow('Matching Homography', res)
cv2.waitKey()
cv2.destroyAllWindows()

good_matches에 있는 매칭점과 같은 자리에 있는 키포인트 객체에서 각 영상의 매칭점 좌표를 구합니다. 구한 좌표로 findHomography()로 원근 변환 행렬을 얻어 내고, 원본 영상의 크기와 같은 좌표를 얻어낸 다음 원근 변환을 적용해 선으로 표시하는 코드입니다.
import cv2, numpy as np
img1 = cv2.imread('../img/taekwonv1.jpg')
img2 = cv2.imread('../img/figures2.jpg')
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# ORB, BF-Hamming 로 knnMatch ---①
detector = cv2.ORB_create()
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
matcher = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = matcher.match(desc1, desc2)
# 매칭 결과를 거리기준 오름차순으로 정렬 ---③
matches = sorted(matches, key=lambda x:x.distance)
# 모든 매칭점 그리기 ---④
res1 = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 매칭점으로 원근 변환 및 영역 표시 ---⑤
src_pts = np.float32([ kp1[m.queryIdx].pt for m in matches ])
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in matches ])
# RANSAC으로 변환 행렬 근사 계산 ---⑥
mtrx, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
h,w = img1.shape[:2]
pts = np.float32([ [[0,0]],[[0,h-1]],[[w-1,h-1]],[[w-1,0]] ])
dst = cv2.perspectiveTransform(pts,mtrx)
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
# 정상치 매칭만 그리기 ---⑦
matchesMask = mask.ravel().tolist()
res2 = cv2.drawMatches(img1, kp1, img2, kp2, matches, None, \
matchesMask = matchesMask,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 모든 매칭점과 정상치 비율 ---⑧
accuracy=float(mask.sum()) / mask.size
print("accuracy: %d/%d(%.2f%%)"% (mask.sum(), mask.size, accuracy))
# 결과 출력
cv2.imshow('Matching-All', res1)
cv2.imshow('Matching-Inlier ', res2)
cv2.waitKey()
cv2.destroyAllWindows()

RANSAC을 사용해 변환행렬을 구했고 결과인 mask를 매칭점 그리기 마스크로 사용하는 모습입니다. mask는 입력 매칭점과 같은 길이의 배열이고 같은 자리의 매칭점이 정상치면 1을, 이상치면 0을 가지므로 그 자체를 리스트로 변환해서 매칭점 그리기 함수의 마스크로 사용할 수 있습니다. 253개의 전체 매칭점 중에 근사 계산에서 정상치로 판단한 매칭점은 35개입니다. 정상치 매칭점 개수 자체만으로도 그 수가 많을수록 원본 영상과의 정확도가 높다고 볼 수 있고, 전체 매칭점 수와의 비율이 높으면 더 확실하다고 볼 수 있습니다. 좋은 매칭점을 먼저 선별한 후 나쁜 매칭점을 제거하는 것이 속도면에서 유리할 수 있습니다.
import cv2, numpy as np
img1 = None
win_name = 'Camera Matching'
MIN_MATCH = 10
# ORB 검출기 생성 ---①
detector = cv2.ORB_create(1000)
# Flann 추출기 생성 ---②
FLANN_INDEX_LSH = 6
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6,
key_size = 12,
multi_probe_level = 1)
search_params=dict(checks=32)
matcher = cv2.FlannBasedMatcher(index_params, search_params)
# 카메라 캡쳐 연결 및 프레임 크기 축소 ---③
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
while cap.isOpened():
ret, frame = cap.read()
if img1 is None: # 등록된 이미지 없음, 카메라 바이패스
res = frame
else: # 등록된 이미지 있는 경우, 매칭 시작
img2 = frame
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 키포인트와 디스크립터 추출
kp1, desc1 = detector.detectAndCompute(gray1, None)
kp2, desc2 = detector.detectAndCompute(gray2, None)
# k=2로 knnMatch
matches = matcher.knnMatch(desc1, desc2, 2)
# 이웃 거리의 75%로 좋은 매칭점 추출---②
ratio = 0.75
good_matches = [m[0] for m in matches \
if len(m) == 2 and m[0].distance < m[1].distance * ratio]
print('good matches:%d/%d' %(len(good_matches),len(matches)))
# 모든 매칭점 그리지 못하게 마스크를 0으로 채움
matchesMask = np.zeros(len(good_matches)).tolist()
# 좋은 매칭점 최소 갯수 이상 인 경우
if len(good_matches) > MIN_MATCH:
# 좋은 매칭점으로 원본과 대상 영상의 좌표 구하기 ---③
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good_matches ])
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good_matches ])
# 원근 변환 행렬 구하기 ---⑤
mtrx, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
accuracy=float(mask.sum()) / mask.size
print("accuracy: %d/%d(%.2f%%)"% (mask.sum(), mask.size, accuracy))
if mask.sum() > MIN_MATCH: # 정상치 매칭점 최소 갯수 이상 인 경우
# 이상점 매칭점만 그리게 마스크 설정
matchesMask = mask.ravel().tolist()
# 원본 영상 좌표로 원근 변환 후 영역 표시 ---⑦
h,w, = img1.shape[:2]
pts = np.float32([ [[0,0]],[[0,h-1]],[[w-1,h-1]],[[w-1,0]] ])
dst = cv2.perspectiveTransform(pts,mtrx)
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
# 마스크로 매칭점 그리기 ---⑨
res = cv2.drawMatches(img1, kp1, img2, kp2, good_matches, None, \
matchesMask=matchesMask,
flags=cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
# 결과 출력
cv2.imshow(win_name, res)
key = cv2.waitKey(1)
if key == 27: # Esc, 종료
break
elif key == ord(' '): # 스페이스바를 누르면 ROI로 img1 설정
x,y,w,h = cv2.selectROI(win_name, frame, False)
if w and h:
img1 = frame[y:y+h, x:x+w]
else:
print("can't open camera.")
cap.release()
cv2.destroyAllWindows()
카메라를 이용해 실시간 매칭되면서 영역을 표시하는 코드입니다. ORB로 특징 검출기를 사용했고 매칭기 객체로는
FLANN을 사용했습니다.
8.5 객체 추적
한번 지정한 객체의 위치를 연속된 영상 프레임에서 지속적으로 찾아내는 것을 객체 추적이라고 합니다. 사람이 그렇듯 컴퓨터도 객체 검출이나 인식은 많은 자원을 필요로 하고 속도가 느리기 때문에 상대적으로 빠르고 단순한 객체 추적 방법이 필요합니다. 매 장면을 하나의 장면으로 분석하는 객체 인식 알고리즘은 시간의 흐름에 따른 객체의 유일성을 알 수 없지만 장면과 장면의 흐름에 기반하는 객체 추적 기법은 이전 장면의 객체와 다음 장면의 객체가 서로 같고 다르다는 것을 알 수 있습니다.
■ 동영상 배경 제거
객체의 움직임을 판단하기 가장 쉬운 방법은 배경만 있는 영상에서 객체가 있는 영상을 빼면 됩니다. 하지만 주변환경이 계속해서 변하는 실세계에서 배경만 있는 영상을 찾기는 거의 불가능합니다. OpenCV는 동영상에서 배경을 제거하는 다양한 알고리즘을 하나의 인터페이스로 통일하기 위해서 cv2.BackgroundSubtractor 추상 클래스를 만들고 이것을 상속받은 10가지 알고리즘 구현 클래스를 제공합니다.
cv2.BackgroundSubtractor에 선언된 공통 인터페이스 함수를 보겠습니다.
- fgmask = bgsubtractor.apply(image [, fgmask [, learningRate]])
- image: 입력영상
- fgmask: 전경 마스크
- learningRate = -1: 배경 훈련 속도(0 ~ 1. -1: 자동)
- backgroundImage = bgsubtractor.getBackgroundImage([, backgroundImage])
- backgroundImage: 훈련용 배경 이미지
이번에는 알고리즘 구현 객체 생성 함수를 보겠습니다.
- cv2.bgsegm.createBackgroundSubtractorMOG([history, nmixtures, backgroundRatio, noiseSigma])
- history = 200: 히스토리 길이
- nmixtures = 5: 가우시안 믹스쳐의 개수
- backgroundRatio = 0.7: 배경 비율
- noiseSigma = 0: 노이즈 강도(0 = 자동)
2001년 KadewTraKuPong과 Bowden이 논문에서 소개한 KB 알고리즘을 OpenCV는 cv2.bgsegm.createBackgroundSubtractorMOG() 함수로 구현했습니다. 기본값이 세팅되어 있어서 추가적인 튜닝이 필요하지 않은 이상 apply() 함수의 호출만으로 결과를 얻을 수 있습니다.
import numpy as np, cv2
cap = cv2.VideoCapture('../img/walking.avi')
fps = cap.get(cv2.CAP_PROP_FPS) # 프레임 수 구하기
delay = int(1000/fps)
# 배경 제거 객체 생성 --- ①
fgbg = cv2.bgsegm.createBackgroundSubtractorMOG()
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 배경 제거 마스크 계산 --- ②
fgmask = fgbg.apply(frame)
cv2.imshow('frame',fgmask)
cv2.imshow('bgsub',fgbg.getBackgroundImage())
if cv2.waitKey(1) & 0xff == 27:
break
cap.release()
cv2.destroyAllWindows()
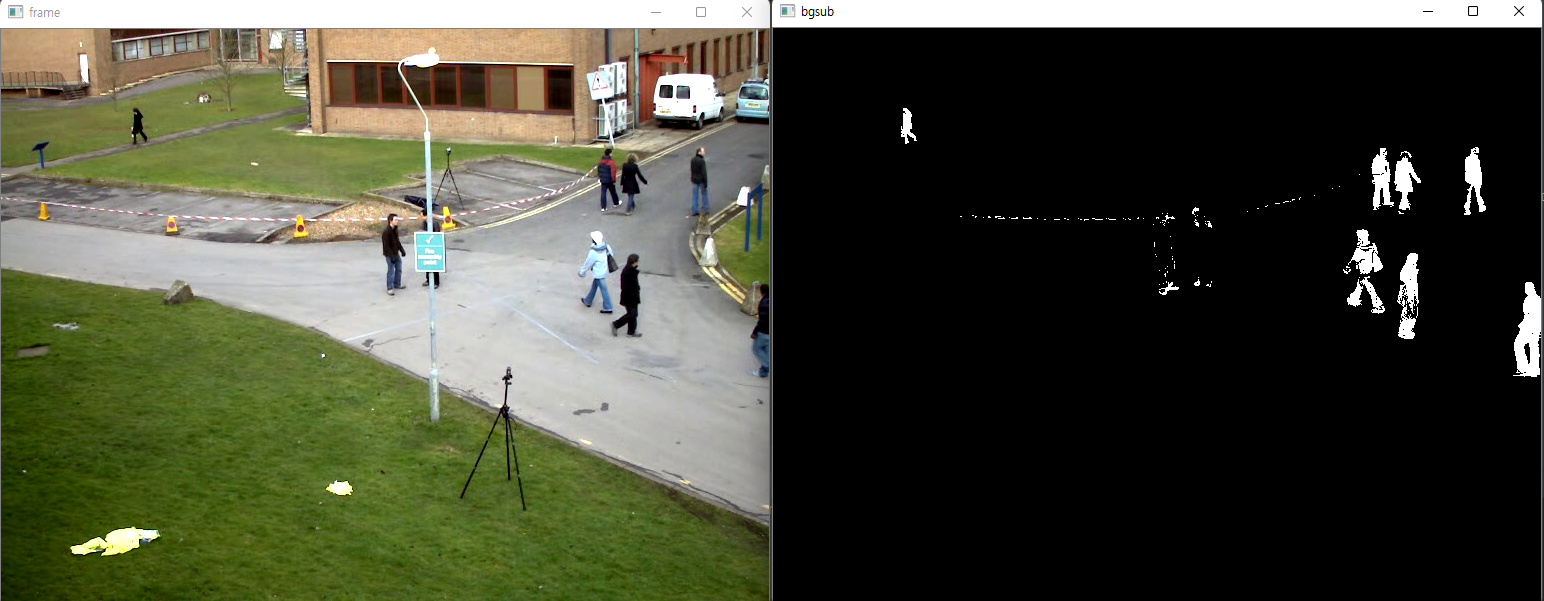
객체를 생성하고 apply() 함수를 호출해 배경이 제거된 전경 마스크를 얻어 보여주는 코드입니다.
또 다른 배경 제거 객체 생성 함수는 cv2.createBackgroundSubtractorMOG2()입니다.
- retval = cv2.createBackgroundSubtractorMOG2)[, history [, varThreshold [, detectShadows]]])
- history = 500: 히스토리 개수
- varThreshold = 16: 분산 임계 값
- detectShadows = True: 그림자 표시
import numpy as np, cv2
cap = cv2.VideoCapture('../img/walking.avi')
fps = cap.get(cv2.CAP_PROP_FPS) # 프레임 수 구하기
delay = int(1000/fps)
# 배경 제거 객체 생성 --- ①
fgbg = cv2.createBackgroundSubtractorMOG2()
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# 배경 제거 마스크 계산 --- ②
fgmask = fgbg.apply(frame)
cv2.imshow('frame',frame)
cv2.imshow('bgsub',fgmask)
if cv2.waitKey(delay) & 0xff == 27:
break
cap.release()
cv2.destroyAllWindows()

BackgroundSubtractorMOG2를 이용해 전경 마스크를 얻은 코드입니다. 이번에는 그림자까지 표시된 모습입니다. 이 함수는 각 픽셀의 적절한 가우시안 분포 값을 선택하므로 빛에 대한 변화가 많은 장면에 적합합니다.
■ 옵티컬 플로
옵티컬 플로(optical flow)는 이전 장면과 다음 장면 사이의 픽셀이 이동한 방향과 거리에 대한 분포입니다. 이것은 영상 속 물체가 어느 방향으로 얼마만큼 움직였는지를 알 수 있으므로 움직임 자체에 대한 인식은 물론 여기에 추가적인 연산을 가하면 움직임을 예측할 수도 있습니다.
옵티컬 플로는 크게 두 가지로 나뉩니다. 일부 픽셀만을 계산하는 희소(sparse) 옵티컬 플로와 영상 전체 픽셀을 모두 계산하는 밀집(dense) 옵티컬 플로입니다. 희소 방식의 루카스-카나데(Lucas-Kanade) 알고리즘을 구현한 cv2.calcOpticalFlowPyrLK() 함수와 밀집 방식의 군나르 파너백(Gunnar Farneback) 알고리즘을 구현한 cv2.calcOpticalFlowFarneback()을 보겠습니다.
- nextPts, status, err = cv2.calcOpticalFlowPyrLK(prevImg, nextImg, prevPts, nextPts [, status, err, winSize, maxLevel, criteria, flags, minEigThreshold])
- prevImg: 이전 프레임 영상
- nextImg: 다음 프레임 영상
- prevPts: 이전 프레임의 코너 특징점, cv2.goodFeaturesToTrack()으로 검출
- nextPts: 다음 프레임에서 이동한 코너 특징점
- status: 결과 상태 벡터, nextPts와 같은 길이, 대응점이 있으면 1, 없으면 0
- err: 결과 에러 벡터, 대응점 간의 오차
- winSize = (21, 21): 각 이미지 피라미드의 검색 윈도 크기
- maxLevel =3: 이미지 피라미드 계층 수
- criteria = (COUNT + EPS, 30, 0.01): 반복 탐색 중지 요건
- type
- cv2.TERM_CRITERIA_EPS: 정확도가 epsilon보다 작으면
- cv2.TERM_CRITERIA_MAX_ITER: max_iter 횟수를 채우면
- cv2.TERM_CRITERIA_COUNT: MAX_ITER와 동일
- max_iter: 최대 반복 횟수
- epsilon: 최소 정확도
- flags = 0: 연산 모드
- 0: prevPts를 nextPts의 초기 값으로 사용
- cv2.OPTFLOW_USE_INITIAL_FLOW: nextPts의 값을 초기 값으로 사용
- cv2.OPTFLOW_LK_GET_MIN_EIGENVALS: 오차를 최소 고유 값으로 계산
- minEigThreshold = 1e-4: 대응점 계산에 사용할 최소 임계 고유값
- type
cv2.calcOpticalFlowPyrLK() 함수는 픽셀 전체를 계산하지 않고 cv2.goodFeaturesToTrack() 함수로 얻은 코너 특징점만 가지고 계산합니다. prevImg와 nextImg에 각각 이전 이후 프레임을 전달하고 prevPts에 이전 프레임에서 검출한 코너 특징점을 전달하면 그 코너점이 이후 프레임의 어디로 이동했는지 찾아서 nextPts로 반환합니다. 이때 두 코너점이 서로 대응하는지 여부를 status에 1과 0으로 표시해서 함께 반환합니다. 이 함수는 작은 윈도를 사용해서 큰 움직임을 계산하지 못하는 문제가 있는데 이미지 피라미드를 사용해 보완합니다. maxlevel에 0을 지정하면 이미지 피라미드를 사용하지 않습니다.
import numpy as np, cv2
cap = cv2.VideoCapture('../img/walking.avi')
fps = cap.get(cv2.CAP_PROP_FPS) # 프레임 수 구하기
delay = int(1000/fps)
# 추적 경로를 그리기 위한 랜덤 색상
color = np.random.randint(0,255,(200,3))
lines = None #추적 선을 그릴 이미지 저장 변수
prevImg = None # 이전 프레임 저장 변수
# calcOpticalFlowPyrLK 중지 요건 설정
termcriteria = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03)
while cap.isOpened():
ret,frame = cap.read()
if not ret:
break
img_draw = frame.copy()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 최초 프레임 경우
if prevImg is None:
prevImg = gray
# 추적선 그릴 이미지를 프레임 크기에 맞게 생성
lines = np.zeros_like(frame)
# 추적 시작을 위한 코너 검출 ---①
prevPt = cv2.goodFeaturesToTrack(prevImg, 200, 0.01, 10)
else:
nextImg = gray
# 옵티컬 플로우로 다음 프레임의 코너점 찾기 ---②
nextPt, status, err = cv2.calcOpticalFlowPyrLK(prevImg, nextImg, \
prevPt, None, criteria=termcriteria)
# 대응점이 있는 코너, 움직인 코너 선별 ---③
prevMv = prevPt[status==1]
nextMv = nextPt[status==1]
for i,(p, n) in enumerate(zip(prevMv, nextMv)):
px,py = p.ravel().astype(np.int32)
nx,ny = n.ravel().astype(np.int32)
# 이전 코너와 새로운 코너에 선그리기 ---④
cv2.line(lines, (px, py), (nx,ny), color[i].tolist(), 2)
# 새로운 코너에 점 그리기
cv2.circle(img_draw, (nx,ny), 2, color[i].tolist(), -1)
# 누적된 추적 선을 출력 이미지에 합성 ---⑤
img_draw = cv2.add(img_draw, lines)
# 다음 프레임을 위한 프레임과 코너점 이월
prevImg = nextImg
prevPt = nextMv.reshape(-1,1,2)
cv2.imshow('OpticalFlow-LK', img_draw)
key = cv2.waitKey(delay)
if key == 27 : # Esc:종료
break
elif key == 8: # Backspace:추적 이력 지우기
prevImg = None
cv2.destroyAllWindows()
cap.release()

이전 프레임의 코너를 검출한 후 calcOpticalFlowPyrLK() 함수로 옵티컬 플로로 이동한 다음 프레임의 코너 특징점을 찾습니다. 대응이 잘 된 것을 선별해 선과 점으로 표시합니다. 추적선은 매 장면마다 누적해서 보여줘야 하므로 텅 빈 이미지에 선을 그린 다음에 원본 영상과 합성하는 방식으로 표현했습니다.
- flow = cv2.calcOpticalFlowFarneback(prev, next, flow, pyr_scale, levels, winsize, iterations, poly_n, poly_isgma, flags)
- prev, next: 이전, 이후 프레임
- flow: 옵티컬 플로 계산 결과, 입력과 동일한 크기의 각 픽셀이 이동한 거리
- pyr_scale: 이미지 피라미드 스케일
- levels: 이미지 피라미드 개수
- winsize: 평균 윈도 크기
- iterations: 각 피라미드에서 반복할 횟수
- poly_n: 다항식 근사를 위한 이웃 크기, 5 또는 7
- poly_sigma: 다항식 근사에서 사용할 가우시안 시그마
- poly_n = 5일 때는 1.1, poly_n = 7일 때는 1.5
- flags: 연산 모드
- cv2.OPTFLOW_USE_INITIAL_FLOW: flow 값을 초기 값으로 사용
- cv2.OPTFLOW_FARNEBACK_GAUSSIAN: 박스 필터 대신 가우시안 필터 사용
밀집 방식은 영상 전체의 픽셀로 계산하므로 추적할 특징점을 따로 전달할 필요가 없지만 속도가 느립니다.
import cv2, numpy as np
# 플로우 결과 그리기 ---①
def drawFlow(img,flow,step=16):
h,w = img.shape[:2]
# 16픽셀 간격의 그리드 인덱스 구하기 ---②
idx_y,idx_x = np.mgrid[step/2:h:step,step/2:w:step].astype(np.int32)
indices = np.stack( (idx_x,idx_y), axis =-1).reshape(-1,2)
for x,y in indices: # 인덱스 순회
# 각 그리드 인덱스 위치에 점 그리기 ---③
cv2.circle(img, (x,y), 1, (0,255,0), -1)
# 각 그리드 인덱스에 해당하는 플로우 결과 값 (이동 거리) ---④
dx,dy = flow[y, x].astype(np.int32)
# 각 그리드 인덱스 위치에서 이동한 거리 만큼 선 그리기 ---⑤
cv2.line(img, (x,y), (x+dx, y+dy), (0,255, 0),2, cv2.LINE_AA )
prev = None # 이전 프레임 저장 변수
cap = cv2.VideoCapture('../img/walking.avi')
fps = cap.get(cv2.CAP_PROP_FPS) # 프레임 수 구하기
delay = int(1000/fps)
while cap.isOpened():
ret,frame = cap.read()
if not ret: break
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
# 최초 프레임 경우
if prev is None:
prev = gray # 첫 이전 프레임 --- ⑥
else:
# 이전, 이후 프레임으로 옵티컬 플로우 계산 ---⑦
flow = cv2.calcOpticalFlowFarneback(prev,gray,None,\
0.5,3,15,3,5,1.1,cv2.OPTFLOW_FARNEBACK_GAUSSIAN)
# 계산 결과 그리기, 선언한 함수 호출 ---⑧
drawFlow(frame,flow)
# 다음 프레임을 위해 이월 ---⑨
prev = gray
cv2.imshow('OpticalFlow-Farneback', frame)
if cv2.waitKey(delay) == 27:
break
cap.release()
cv2.destroyAllWindows()

계산 결과인 flow는 입력 영상과 같은 크기의 Numpy 배열로 각 요소는 해당 위치의 픽셀이 이동한 거리를 (x, y) 꼴로 가집니다. drawFlow 함수는 영상에 16픽셀 간격의 격자 모양으로 점을 그리고 각 점에 해당하는 픽셀이 이동한 거리만큼 선을 표시하여 시각화합니다. 밀집 옵티컬 플로는 모든 픽셀을 관찰하는 모습을 보입니다.
■ MeanShift 추적
MeanShift 추적은 대상 객체의 색상 정보로 추적하는 방법으로 평균 이동 알고리즘으로 객체의 색상을 추적합니다. MeanShift는 3단계 절차를 통해 이뤄집니다.
- 추적 대상을 선정해서 HSV 컬러 스페이스의 H(색조) 값 히스토그램 계산
- 전체 영상의 히스토그램(HSV 컬러 스페이스의 H 값) 계산 결과로 역투영
- 역투영 결과에서 이동한 객체를 MeanShift로 추적
영상에서 추적할 대상 좌표를 구하고 대상 영역의 히스토그램을 계산합니다. 계산된 히스토그램은 객체의 색상 정보만 갖습니다. 매 장면마다 객체를 추적하기 위해 영상 전체를 HSV 컬러 스페이스로 변환해 H 값의 히스토그램을 계산하고 대상 객체의 히스토그램과 역투영(back projection)을 합니다. 역투영한 결과는 추적 대상 객체의 색상 값과 비슷한 영역의 픽셀들만 큰 값을 갖습니다. 역투영한 결과에서 최초 객체를 지정한 좌표를 기준으로 평균 이동을 하면 이동한 객체의 중심점을 찾을 수 있게 됩니다.
- retval, window = cv2.meanShift(probImage, window, criteria)
- probImage: 검색할 히스토그램의 역투영 결과
- window: 검색 시작 위치, 검색 결과 위치(x, y, w, h)
- criteria: 검색 중지 요건, 튜플 객체로 전달
- type
- cv2.TERM_CRITERIA_EPS: 정확도가 epsilon보다 작으면
- cv2.TERM_CRITERIA_MAX_ITER: max_iter 횟수를 채우면
- cv2.TERM_CRITERIA_COUNT: MAX_ITER와 동일
- max_iter: 최대 반복 횟수
- epsilon: 최소 정확도
- type
- retval: 수렴한 반복 횟수
cv2.meanShift() 함수는 probImage 인자에 추적할 객체가 역투영된 히스토그램을 전달하고 window에 초기 추적 위치를 전달하면 반복 시도한 횟수와 함께 새로운 객체의 위치를 반환합니다.
import numpy as np, cv2
roi_hist = None # 추적 객체 히스토그램 저장 변수
win_name = 'MeanShift Tracking'
termination = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
while cap.isOpened():
ret, frame = cap.read()
img_draw = frame.copy()
if roi_hist is not None: # 추적 대상 객체 히스토그램 등록 됨
# 전체 영상 hsv 컬로 변환 ---①
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# 전체 영상 히스토그램과 roi 히스트그램 역투영 ---②
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0,180], 1)
# 역 투영 결과와 초기 추적 위치로 평균 이동 추적 ---③
ret, (x,y,w,h) = cv2.meanShift(dst, (x,y,w,h), termination)
# 새로운 위치에 사각형 표시 ---④
cv2.rectangle(img_draw, (x,y), (x+w, y+h), (0,255,0), 2)
# 컬러 영상과 역투영 영상을 통합해서 출력
result = np.hstack((img_draw, cv2.cvtColor(dst, cv2.COLOR_GRAY2BGR)))
else: # 추적 대상 객체 히스토그램 등록 안됨
cv2.putText(img_draw, "Hit the Space to set target to track", \
(10,30),cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 1, cv2.LINE_AA)
result = img_draw
cv2.imshow(win_name, result)
key = cv2.waitKey(1) & 0xff
if key == 27: # Esc
break
elif key == ord(' '): # 스페이스-바, ROI 설정
x,y,w,h = cv2.selectROI(win_name, frame, False)
if w and h : # ROI가 제대로 설정됨
# 초기 추적 대상 위치로 roi 설정 --- ⑤
roi = frame[y:y+h, x:x+w]
# roi를 HSV 컬러로 변경 ---⑥
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = None
# roi에 대한 히스토그램 계산 ---⑦
roi_hist = cv2.calcHist([roi], [0], mask, [180], [0,180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
else: # ROI 설정 안됨
roi_hist = None
else:
print('no camera!')
cap.release()
cv2.destroyAllWindows()ROI를 지정하고 지정한 곳은 추적할 객체가 됩니다. 추적할 객체의 히스토그램을 계산합니다. 그다음 역투영한 값을 이용해 meanShift() 함수로 좌표를 받는 코드입니다. MeanShift 추적은 색상을 기반으로 하므로 추적하려는 객체의 색상이 주변과 비슷하거나 여러 가지 색상으로 이루어진 경우 효과를 보기 어렵고 객체의 크기와 방향과는 상관없이 항상 같은 윈도를 반환하는 단점이 있습니다.
■ CamShift 추적
CamShift(Continuously Adaptive MeanShift) 추적은 MeanShift 추적의 문제점인 고정된 윈도 크기와 방향을 개선한 것으로 윈도 크기와 방향을 재설정합니다. 절차는 MeanShift와 동일하고 평균 중심점을 찾는 함수만 다릅니다.
import numpy as np, cv2
roi_hist = None # 추적 객체 히스토그램 저장 변수
win_name = 'Camshift Tracking'
termination = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
while cap.isOpened():
ret, frame = cap.read()
img_draw = frame.copy()
if roi_hist is not None: # 추적 대상 객체 히스토그램 등록 됨
# 전체 영상 hsv 컬로 변환 ---①
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
# 전체 영상 히스토그램과 roi 히스트그램 역투영 ---②
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0,180], 1)
# 역 투영 결과와 초기 추적 위치로 평균 이동 추적 ---③
ret, (x,y,w,h) = cv2.CamShift(dst, (x,y,w,h), termination)
# 새로운 위치에 사각형 표시 ---④
cv2.rectangle(img_draw, (x,y), (x+w, y+h), (0,255,0), 2)
# 컬러 영상과 역투영 영상을 통합해서 출력
result = np.hstack((img_draw, cv2.cvtColor(dst, cv2.COLOR_GRAY2BGR)))
else: # 추적 대상 객체 히스토그램 등록 안됨
cv2.putText(img_draw, "Hit the Space to set target to track", \
(10,30),cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 1, cv2.LINE_AA)
result = img_draw
cv2.imshow(win_name, result)
key = cv2.waitKey(1) & 0xff
if key == 27: # Esc
break
elif key == ord(' '): # 스페이스-바, ROI 설정
x,y,w,h = cv2.selectROI(win_name, frame, False)
if w and h : # ROI가 제대로 설정됨
# 초기 추적 대상 위치로 roi 설정 --- ⑤
roi = frame[y:y+h, x:x+w]
# roi를 HSV 컬러로 변경 ---⑥
roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = None
# roi에 대한 히스토그램 계산 ---⑦
roi_hist = cv2.calcHist([roi], [0], mask, [180], [0,180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
else: # ROI 설정 안됨
roi_hist = None
else:
print('no camera!')
cap.release()
cv2.destroyAllWindows()위 코드는 camShift를 사용했으며 객체의 방향이 변경되어도 인식이 잘 됩니다.
'Deep Learning(강의 및 책) > OpenCV' 카테고리의 다른 글
| [OpenCV] 머신러닝 (0) | 2022.08.31 |
|---|---|
| [OpenCV] 영상 분할 (0) | 2022.08.04 |
| [OpenCV] 영상 필터 (0) | 2022.08.01 |
| [OpenCV] 기하학적 변환 (0) | 2022.07.30 |
| [OpenCV] 이미지 프로세싱 기초 (0) | 2022.07.23 |



