이 글은 '파이썬으로 만드는 OpenCV 프로젝트'를 보고 작성했습니다.
9.1 OpenCV와 머신러닝
OpenCV는 컴퓨터 비전 라이브러리지만 최근 들어 머신러닝이 컴퓨터 비전 분야에 폭넓게 사용되면서, 기본적인 머신러닝 알고리즘은 물론 새로운 연구 결과도 빠르게 추가되고 있습니다.
■ 머신러닝
머신러닝(machine learning)은 인공지능(aritificial intelligence)의 한 분야로 어떤 알고리즘으로 데이터를 분석해서 그것을 바탕으로 새로운 데이터를 판단 또는 예측하는 것을 말합니다. 데이터를 분석하기 위해서는 데이터들의 특징이 잘 묘사된 숫자들을 추출해야 하는데, 그 숫자를 변수, 벡터(vector), 특징(feature) 등의 용어로 부르고 그 과정을 특징 벡터화 또는 특징 추출한다고 표현합니다. 영상에서는 특징 디스크립터가 좋은 특징 벡터가 될 수 있습니다. 추출된 특징 벡터를 어떤 알고리즘으로 분석하면 사용하는 알고리즘에 따라 회귀, 분류, 군집화라는 형태의 결과를 얻을 수 있습니다.
■ OpenCV와 머신러닝
OpenCV는 최근 머신러닝의 발전과 사용이 활발해짐에 따라 'ml(Machine Learning)'이라는 별도의 모듈을 구성해서 다양한 머신러닝 알고리즘을 통일된 인터페이스로 제공하고 있습니다. ml 모듈에는 상위 레벨 함수도 있는데, 마치 응용프로그램을 쓰듯이 알고리즘의 원리를 신경 쓰지 않고도 객체를 검출할 수 있습니다.
OpenCV에 구현된 머신러닝 알고리즘 중네는 아주 오래전부터 사용해 오던 레거시(legacy) 알고리즘들도 있는데, 이들은 기존의 호환성을 위해 ml 패키지에 포함되지 않고 통일된 인터페이스를 따르지도 않습니다.
- cv2.kmeans()
- cv2.Mahalanobis()
위 두 함수는 대표적인 레거시 알고리즘입니다. 아주 오래전부터 사용해왔기 때문에 ml 모듈로 옮기지 못하고 원래의 자리를 고수하고 있으며 통일된 인터페이스를 제공하지 않습니다.
그 밖의 머신러닝 알고리즘은 통일된 인터페이스 구조를 위해 ml 모듈로 따로 구성해서 SatModel 추상 클래스를 상속받아 구현했습니다. 대표적인 함수는 아래와 같습니다.
- cv2.ml.StatModel
- retval = train(samples, layout, responses): 훈련
- retval, results = predict(samples [, results, flags]): 예측
- samples: 학습 데이터
- layout: 학습 데이터의 형태 지정 플래그
- cv2.ml.ROW_SAMPLE: 행으로 구성된 데이터
- cv2.ml.COL_SAMPLE: 열로 구성된 데이터
- responses: 샘플 데이터의 레이블
- save(filename): 훈련된 모델 객체를 파일로 저장
- filename: 저장할 파일 이름
- obj = cv2.ml.StatModel.load(filename): 훈련해서 저장한 모델 객체 읽기
- filename: 파일 이름
- obj: 저장했던 객체
이 인터페이스를 상속한 모든 알고리즘 객체에는 train(), predict() 함수가 있고 한번 훈련한 객체를 저장했다가 다시 읽어 올 수 있는 save(), load() 함수도 있습니다.
아래는 StatModel을 상속받아 구현한 알고리즘 클래스들입니다.
- 회귀
- cv2.ml.LogisticRegression
- 베이즈 분류기
- cv2.ml.NormalBayesClassifier
- 트리
- cv2.ml.DTrees
- cv2.ml.Boost
- cv2.ml.RTrees
- 기대값 최대화
- cv2.ml.EM
- 최근접 이웃
- cv2.ml.KNearest
- 서포트 벡터 머신
- cv2.ml.SVM
- 인공신경망
- cv2.ml.ANN_MLP
9.2 k-means 클러스터
k-means 클러스터는 OpenCV에 구현되어 있는 대표적인 레거시 알고리즘입니다. 이는 뒤섞여 있는 데이터를 원하는 개수의 그룹으로 묶는 비지도학습 군집화 알고리즘입니다.
■ k-means 알고리즘
입력 데이터를 원하는 개수의 그룹으로 묶기 위해 평균을 이용하는 이 알고리즘은 데이터를 2개의 그룹으로 묶는다고 가정하면 대략 아래와 같은 절차를 따릅니다.
- 랜덤하게 두 점을 골라 2개의 중앙점(C1, C2)을 선정
- 두 중앙점에서 나머지 모든 점의 거리를 계산
- 각각의 점이 C1에 가까우면 빨강 그룹, C2에 가까우면 파랑 그룹으로 묶기
- 각 그룹의 평균값을 계산해서 그 값을 새로운 중앙점으로 선정
- 중앙점의 위치가 바뀌지 않고 고정될 때까지 2 ~ 4번 과정을 반복
이와 같은 기본적인 개념을 바탕으로 초기 중앙점 선택 방법을 비롯해서 반복 횟수를 줄여 속도를 높이기 위한 다양한 개선된 알고리즘이 있습니다.
- retval, bestlabels, centers = cv2.kmeans(data, K, bestLabels, criteria, attempts, flags)
- data: 처리 대상 데이터, dtype = np.float32, N x 1 형태
- K: 원하는 묶음 개수
- bestLabels: 결과 데이터
- criteria: 반복 종료 조건, tuple(type, max_iter, epsilon)
- attemps: 매번 다른 초기 레이블로 실행할 횟수
- flags: 초기 중앙점 선정 방법
- cv2.KMEANS_PP_CENTERS
- cv2.KMEANS_RANDOM_CENTERS
- cv2.KMEANS_USE_INITIAL_LABELS
- retval: 중앙점과 각 데이터의 거리의 합의 제곱
- bestLabels: 결과 레이블(0, 1, ...)
- centers: 각 묶음의 중앙점, 배열
data에 군집화할 데이터를 전달하고 K에 원하는 묶음의 계수를 전달하면 centers에 각 묶음의 중심 좌표를 배열로 반환합니다.
import numpy as np, cv2
import matplotlib.pyplot as plt
# 0~150 임의의 2수, 25개 ---①
a = np.random.randint(0,150,(25,2))
# 128~255 임의의 2수, 25개 ---②
b = np.random.randint(128, 255,(25,2))
# a, b를 병합 ---③
data = np.vstack((a,b)).astype(np.float32)
# 중지 요건 ---④
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 평균 클러스터링 적용 ---⑤
ret,label,center=cv2.kmeans(data,2,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# label에 따라 결과 분류 ---⑥
red = data[label.ravel()==0]
blue = data[label.ravel()==1]
# plot에 결과 출력 ---⑦
plt.scatter(red[:,0],red[:,1], c='r')
plt.scatter(blue[:,0],blue[:,1], c='b')
# 각 그룹의 중앙점 출력 ---⑧
plt.scatter(center[0,0],center[0,1], s=100, c='r', marker='s')
plt.scatter(center[1,0],center[1,1], s=100, c='b', marker='s')
plt.show()

위 코드는 간단한 예제입니다. 25 x 2의 랜덤 수를 생성하고, 병합해 data에 저장합니다. 중간에 겹치는 구간을 두어 완벽하게 두 개의 부류로 나누기 어렵게 배치했습니다. cv2.kmeans() 함수로 두 개의 묶음으로 군집화한 결과는 위와 같고 잘 구분하고 있습니다. 각 그룹의 중앙값은 네모로 표시했습니다.
import numpy as np
import cv2
K = 16 # 군집화 갯수(16컬러) ---①
img = cv2.imread('../img/taekwonv1.jpg')
# 군집화를 위한 데이타 구조와 형식 변환 ---②
data = img.reshape((-1,3)).astype(np.float32)
# 반복 중지 요건 ---③
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 평균 클러스터링 적용 ---④
ret,label,center=cv2.kmeans(data,K,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# 중심 값을 정수형으로 변환 ---⑤
center = np.uint8(center)
# 각 레이블에 해당하는 중심값으로 픽셀 값 선택 ---⑥
res = center[label.flatten()]
# 원본 영상의 형태로 변환 ---⑦
res = res.reshape((img.shape))
# 결과 출력 ---⑧
merged = np.hstack((img, res))
cv2.imshow('KMeans Color',merged)
cv2.waitKey(0)
cv2.destroyAllWindows()
16개의 그룹으로 이미지에 사용된 색을 군집화했습니다. 결과를 보면 원본의 색상 묘사보다는 거칠어졌지만 원본과 비슷하게 표현하는 것을 알 수 있습니다.
■ 숫자 손글씨 군집화
이 책에서 사용하는 MNIST 이미지는 손으로 쓰인 0 ~ 9 숫자를 숫자당 500자씩 담고 있습니다. 이미지 안에 있는 글자는 모두 5000자이고, 각 글자 하나는 20 x 20 픽셀로 구성되어 있습니다. 다시 말해서 글자 하나가 400개의 픽셀로 구성되어 있고 그런 게 5000개 있으니까 5000 x 400개의 숫자를 다루는 이미지입니다.
import numpy as np, cv2
data = None # 이미지 데이타 셋
k = list(range(10)) # [0,1,2,3,4,5,6,7,8,9] 레이블 셋
# 이미지 데이타 읽어들이는 함수 ---①
def load():
global data
# 0~9 각각 500(5x100)개, 총5000(50x100)개, 한 숫자당 400(20x20)픽셀
image = cv2.imread('../img/digits.png')
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
# 숫자 한개(20x20)씩 구분하기 위해 행별(50)로 나누고 열별(100)로 나누기
cells = [np.hsplit(row,100) for row in np.vsplit(gray,50)]
# 리스트를 NumPy 배열로 변환 (50 x 100 x 20 x 20 )
data = np.array(cells)
# 모든 숫자 데이타 반환 ---②
def getData(reshape=True):
if data is None: load() # 이미지 읽기 확인
# 모든 데이타를 N x 400 형태로 변환
if reshape:
full = data.reshape(-1, 400).astype(np.float32) # 5000x400
else:
full = data
labels = np.repeat(k,500).reshape(-1,1) # 각 숫자당 500번 반복(10x500)
return (full, labels)
# 훈련용 데이타 반환 ---③
def getTrain(reshape=True):
if data is None: load() # 이미지 읽기 확인
# 50x100 중에 90열만 훈련 데이타로 사용
train = data[:,:90]
if reshape:
# 훈련 데이타를 N X 400으로 변환
train = train.reshape(-1,400).astype(np.float32) # 4500x400
# 레이블 생성
train_labels = np.repeat(k,450).reshape(-1,1) # 각 숫자당 45번 반복(10x450)
return (train, train_labels)
# 테스트용 데이타 반환 ---④
def getTest(reshape=True):
if data is None: load()
# 50x100 중에 마지막 10열만 훈련 데이타로 사용
test = data[:,90:100]
# 테스트 데이타를 N x 400으로 변환
if reshape:
test = test.reshape(-1,400).astype(np.float32) # 500x400
test_labels = np.repeat(k,50).reshape(-1,1)
return (test, test_labels)
# 손글씨 숫자 한 개를 20x20 로 변환후에 1x400 형태로 변환 ---⑤
def digit2data(src, reshape=True):
h, w = src.shape[:2]
square = src
# 정사각형 형태로 만들기
if h > w:
pad = (h - w)//2
square = np.zeros((h, h), dtype=np.uint8)
square[:, pad:pad+w] = src
elif w > h :
pad = (w - h)//2
square = np.zeros((w, w), dtype=np.uint8)
square[pad:pad+h, :] = src
# 0으로 채워진 20x20 이미지 생성
px20 = np.zeros((20,20), np.uint8)
# 원본을 16x16으로 축소해서 테두리 2픽셀 확보
px20[2:18, 2:18] = cv2.resize(square, (16,16), interpolation=cv2.INTER_AREA)
if reshape:
# 1x400형태로 변환
px20 = px20.reshape((1,400)).astype(np.float32)
return px20
위 코드는 책에서 계속 사용하는 MNIST이미지를 다루기 위해 미리 구현한 함수들입니다. train data 4500개와 test data 500개로 나눠서 반환하는 함수(getTrain(), getTest())와 사용자가 직접 입력한 데이터를 같은 크기로 변환하는 함수(digit2 data()), load 된 모든 이미지들을 5000 x 400 형태로 바꿔주는 함수(getData())들입니다.
import cv2, numpy as np
import matplotlib.pyplot as plt
import mnist
# 공통 모듈로 부터 MINST 전체 이미지 데이타 읽기 ---①
data, _ = mnist.getData()
# 중지 요건
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 평균 클러스터링 적용, 10개의 그룹으로 묶음 ---②
ret,label,center=cv2.kmeans(data,10,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# 중앙점 이미지 출력
for i in range(10):
# 각 중앙점 값으로 이미지 생성 ---③
cent_img = center[i].reshape(20,20).astype(np.uint8)
plt.subplot(2,5, i+1)
plt.imshow(cent_img, 'gray')
plt.xticks([]);plt.yticks([])
plt.show()
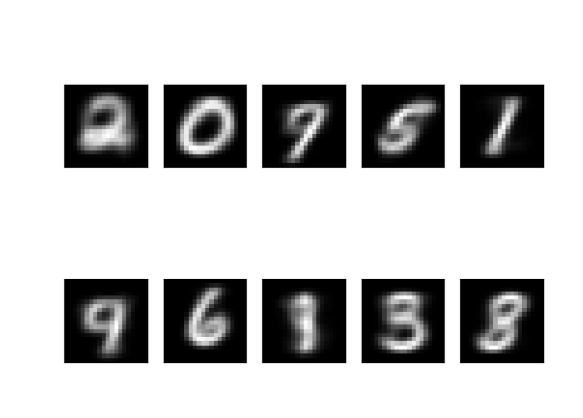
getData() 함수로 MNIST 손글씨 숫자 데이터를 읽어 들여서 10개의 그룹으로 군집화하는 코드입니다. 군집화한 결과의 중앙점을 20 x 20 크기의 이미지로 만들어서 출력한 결과를 보여주고 있습니다. 0 ~ 9 숫자와 비슷한 형태로 중앙점들이 그려진 것을 볼 수 있습니다.
9.3 k-NN
k-NN(k-Nearest Neighbor)은 최근접 이웃 알고리즘이라고 불리며, 지도학습 방식 중에 분류(classify)에 해당하는 알고리즘입니다. OpenCV에서는 cv2.ml.StatModel 추상 클래스를 상속받아 구현했습니다.
■ k-NN 알고리즘
k-NN 알고리즘은 학습 데이터가 어떤 부류에 해당하는지 알고 있을 때, 새로운 데이터를 주면 이것이 어느 부류에 해당하는지 예측합니다. 예측해야 하는 새로운 점과 가장 가까운 이웃이 어느 부류로 분류되는지에 따라 새로운 점을 분류하는 방식입니다. 이때 가장 가까운 이웃의 범위는 K 값으로 조정 가능하며 가까운 거리와 먼 거리에 따라 가중치를 부여할 수 있습니다.
OpenCV의 k-NN 알고리즘은 cv2.ml.StatModel을 상속받았으므로 train()과 predict() 함수와 같은 통일된 인터페이스를 사용할 수 있습니다. 하지만 predict() 함수는 예측 결과만을 반환하고 가까운 이웃에 관련한 정보를 제공할 수 있는 구조가 아니므로 findNearest() 함수를 추가로 제공합니다.
- knn = cv2.ml.KNearest_create(): k-NN 알고리즘 객체 생성
- retval, results, neighborResponses, dist = knn.findNearest(samples, K): 예측
- samples: 입력 데이터
- k: 이웃 범위 지정을 위한 K(K는 1보다 큰 값)
- results: 입력 데이터에 대한 예측 결과, 입력 데이터와 같은 크기의 배열
- neighborResponses: K 범위 내에 있는 이웃 데이터
- dist: 입력 데이터와 이웃 데이터와의 거리
- retval: 예측 결과 데이터, 입력 데이터가 1개인 경우
import cv2, numpy as np, matplotlib.pyplot as plt
# 0~99 사이의 랜덤한 수 25x2개 데이타 생성 ---①
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# 0~1 사이의 랜덤 수 25x1개 레이블 생성 ---②
labels = np.random.randint(0,2,(25,1))
# 레이블 값 0과 같은 자리는 red, 1과 같은 자리는 blue로 분류해서 표시
red = trainData[labels.ravel()==0]
blue = trainData[labels.ravel()==1]
plt.scatter(red[:,0], red[:,1], 80, 'r', '^') # 빨강색 삼각형
plt.scatter(blue[:,0], blue[:,1], 80, 'b', 's')# 파랑색 사각형
# 0 ~ 99 사이의 랜덤 수 신규 데이타 생성 ---③
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o') # 초록색 원
# KNearest 알고리즘 객체 생성 ---④
knn = cv2.ml.KNearest_create()
# train, 행 단위 샘플 ---⑤
knn.train(trainData, cv2.ml.ROW_SAMPLE, labels)
# 예측 ---⑥
#ret, results = knn.predict(newcomer)
ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)#K=3
# 결과 출력
print('ret:%s, result:%s, negibours:%s, distance:%s' \
%(ret,results, neighbours, dist))
plt.annotate('red' if ret==0.0 else 'blue', xy=newcomer[0], \
xytext=(newcomer[0]+1))
plt.show()
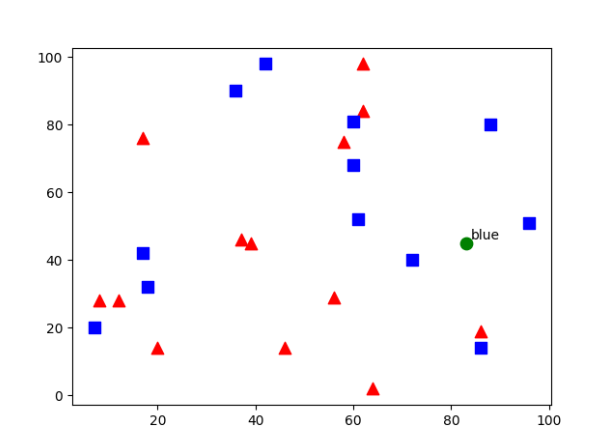
25 x 2 크기의 무작위 수 2개를 각각 red와 blue로 생성하고 각각 0과 1로 레이블을 만들어 빨간색 삼각형과 파란색 사각형으로 분류해서 표시합니다. k-NN 알고리즘을 이용해 난수를 분류합니다. 위 결과는 파란색(1 레이블)으로 분류된 것을 볼 수 있습니다. 위 코드에서 cv2.ml.ROW_SAMPLE이 있는데 이는 train data가 행 단위인지 열 단위인지 알려줘야 하는데, 행 단위라는 것을 나타내기 위해 사용했습니다.
k-NN 알고리즘은 예측에 사용한 최근접 이웃에 대한 정보를 추가로 제공하는 findNearest() 함수를 사용하는 것이 좋습니다. ret는 예측 결과를 나타내는데, 만약 newcomer가 배열이라면 각 자리에 해당하는 예측 결과는 results에 배열 형태로 얻을 수 있습니다. 위 코드에서는 ret와 results의 첫 번째 요소의 값이 같고 neighbours는 K 범위 내에 있는 학습 데이터를 나타내며, distance는 각 학습 데이터와의 거리를 나타냅니다.
이번에는 영화 속 장면에서 발차기 장면과 키스 장면의 횟수로 액션 영화인지 멜로 영화인지 장르를 분류하는 코드를 보겠습니다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 0~99 사이의 랜덤 값 25x2 ---①
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# trainDatat[0]:kick, trainData[1]:kiss, kick > kiss ? 1 : 0 ---②
responses = (trainData[:, 0] >trainData[:,1]).astype(np.float32)
# 0: action : 1romantic ---③
action = trainData[responses==0]
romantic = trainData[responses==1]
# action은 파랑 삼각형, romantic은 빨강색 동그라미로 표시 ---④
plt.scatter(action[:,0],action[:,1], 80, 'b', '^', label='action')
plt.scatter(romantic[:,0],romantic[:,1], 80, 'r', 'o',label="romantic")
# 새로운 데이타 생성, 0~99 랜덤 수 1X2, 초록색 사각형으로 표시 ---⑤
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],200,'g','s', label="new")
# Knearest 알고리즘 생성 및 훈련 --- ⑥
knn = cv2.ml.KNearest_create()
knn.train(trainData, cv2.ml.ROW_SAMPLE, responses)
# 결과 예측 ---⑦
ret, results, neighbours ,dist = knn.findNearest(newcomer, 3)#K=3
print("ret:%s, result:%s, neighbours:%s, dist:%s" \
%(ret, results, neighbours, dist))
# 새로운 결과에 화살표로 표시 ---⑧
anno_x, anno_y = newcomer.ravel()
label = "action" if results == 0 else "romantic"
plt.annotate(label, xy=(anno_x + 1, anno_y+1), \
xytext=(anno_x+5, anno_y+10), arrowprops={'color':'black'})
plt.xlabel('kiss');plt.ylabel('kick')
plt.legend(loc="upper right")
plt.show()

랜덤한 수 2개를 갖는 25쌍의 데이터를 생성합니다. 이때 0번째는 발차기 횟수를, 1번째는 키스 횟수를 의미하는 것으로 합니다. 발차기 횟수가 키스 횟수보다 큰 것을 1, 그렇지 않은 것을 0으로 지정하는데, 1은 액션영화고 0은 멜로영화를 뜻합니다.
■ 손글씨 인식
이번에는 k-NN 알고리즘으로 MNIST 데이터를 훈련해 숫자를 인식해보겠습니다.
import numpy as np, cv2
import mnist
# 훈련 데이타와 테스트 데이타 가져오기 ---①
train, train_labels = mnist.getTrain()
test, test_labels = mnist.getTest()
# kNN 객체 생성 및 훈련 ---②
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
# k값을 1~10까지 변경하면서 예측 ---③
for k in range(1, 11):
# 결과 예측 ---④
ret, result, neighbors, distance = knn.findNearest(test, k=k)
# 정확도 계산 및 출력 ---⑤
correct = np.sum(result == test_labels)
accuracy = correct / result.size * 100.0
print("K:%d, Accuracy :%.2f%%(%d/%d)" % (k, accuracy, correct, result.size) )
getTrain()과 getTest()로 데이터를 불러옵니다. k-NN 알고리즘 객체를 생성한 다음 학습 데이터로 훈련시킵니다. 예측할 데이터 test가 500개이므로 예측 결과인 result도 500개의 배열로 구성됩니다. 정답에 해당하는 test_labels도 500개이므로 result와 비교하면 각각 데이터가 맞았는지 알 수 있습니다.
결과를 보면 k 값을 변경함에 따라 정확도가 달라집니다.
import numpy as np, cv2
import mnist
# 훈련 데이타 가져오기 ---①
train, train_labels = mnist.getData()
# Knn 객체 생성 및 학습 ---②
knn = cv2.ml.KNearest_create()
knn.train(train, cv2.ml.ROW_SAMPLE, train_labels)
# 인식시킬 손글씨 이미지 읽기 ---③
image = cv2.imread('../img/4027.png')
cv2.imshow("image", image)
cv2.waitKey(0)
# 그레이 스케일 변환과 스레시홀드 ---④
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
_, gray = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
cv2.imshow("gray", gray)
# 최외곽 컨투어만 찾기 ---⑤
contours, _ = cv2.findContours(gray, cv2.RETR_EXTERNAL, \
cv2.CHAIN_APPROX_SIMPLE)
# 모든 컨투어 순회 ---⑥
for c in contours:
# 컨투어를 감싸는 외접 사각형으로 숫자 영역 좌표 구하기 ---⑦
(x, y, w, h) = cv2.boundingRect(c)
# 외접 사각형의 크기가 너무 작은것은 제외 ---⑧
if w >= 5 and h >= 25:
# 숫자 영역만 roi로 확보하고 사각형 그리기 ---⑨
roi = gray[y:y + h, x:x + w]
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 1)
# 테스트 데이타 형식으로 변환 ---⑩
data = mnist.digit2data(roi)
# 결과 예측해서 이미지에 표시---⑪
ret, result, neighbours, dist = knn.findNearest(data, k=1)
cv2.putText(image, "%d"%ret, (x , y + 155), \
cv2.FONT_HERSHEY_DUPLEX, 2, (255, 0, 0), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
이번에는 직접 쓴 숫자를 인식하는 코드입니다. 불러온 이미지는 직접 쓴 숫자입니다. k-NN 알고리즘 객체를 생성하고 학습시킵니다. 외곽 컨투어를 구하고 컨투어를 하나씩 순회하며 외접 사각형 영역을 찾아 숫자가 있을 영역의 좌표를 구합니다. 구한 좌표를 기반으로 ROI를 확보하고 초록색 사각형으로 표시합니다. ROI를 MNIST 숫자 한 개와 동일한 규격의 데이터로 만든 후 예측해 이미지에 결과를 표시하는 코드입니다.
9.4 SVM과 HOG
SVM(Support Vector Machine)은 훈련 데이터를 기반으로 두 가지 부류로 분류하는 대표적인 분류 알고리즘입니다. 앞서 살펴본 k-NN 알고리즘은 predict()를 호출하는 시점에 각 요소들 간의 거리 계산이 시작되지만, SVM은 train() 함수에 학습 데이터와 레이블을 전달하면 각 부류를 구분하는 선을 찾아 그 선을 만족하는 방정식을 구하고 나서 predict() 함수에 예측 데이터를 전달하면 이미 구해 놓은 방정식을 적용해서 어떤 부류인지 예측합니다. 이 방정식을 모델(model)이라 하고 한번 구한 모델을 계속해서 재활용할 수 있습니다.
■ SVM 알고리즘
SVM(Support Vector Machine)은 두 그룹으로 나뉜 학습 데이터를 받아서 두 그룹의 영역을 나누는 선을 찾습니다. 학습 데이터에 이미 각 데이터가 어느 그룹에 속하는지 레이블을 함께 제공하므로 데이터들은 이미 두 그룹으로 나뉘어 있습니다. 각 영역의 중심에서 가장 멀고 경계면을 접하고 있는 점을 서포트 벡터(support vector)라고 합니다. 각 영역의 서포트 벡터를 지나는 선을 서포트 평면(support plane)이라고 하고 그 선은 무수히 많습니다. 그들 중에 서로의 거리가 가장 먼 선이 지나는 면을 결정 평면(decision boundary)이라고 하고, SVM은 궁극적으로 이 선을 찾는 알고리즘입니다.
- svm = cv2.ml.SVM_create(): SVM 알고리즘 객체 생성
- svm = cv2.ml.SVM_load(file): 저장한 SVM 객체를 읽어서 생성
- file: 저장한 파일 경로(xml 또는 yml)
- svm.setType(type): SVM 알고리즘 타입 선택
- C_SVC: C 파라미터를 이용한 다중 서포트 벡터 분류기
- NU_SVC: Nu 파라미터를 이용한 다중 서포트 벡터 분류기(SVC)
- ONE_CLASS: 단일 분류기
- EPS_SVR: 엡실론 서포트 벡터 회귀
- NU_SVR: Nu 서포트 벡터 회귀
- svm.setKernel(kernelType = LINEAR): 커널 타입 선택
- CUSTOM: 사용자 정의 커널
- LINEAR: 선형 커널
- POLY: 다항식 커널
- RBF: 방사형 기저 함수(radial basis function) 커널
- SIGMOID: 시그모이드(sigmoid) 함수 커널
- CHI2: 카이제곱 터널
- INTER: 히스토그램 교차점 커널
- svm.setC(val): C_SVC, EPS_SVR의 C 파라미터 설정
- svm.setNu(val): NU_SVC, NU_SVR의 Nu 파라미터 설정
- svm.setP(val): EPS_SVR의 P 파라미터 설정
- svm.setGamma(val): 커널의 감마 값 설정
- svm.setCoef0(val): 커널의 coeff0 값 설정
- svm.setDegree(val): 커널의 degree 값 설정
- svm.trainAuto(trainData, layout, label): 자동으로 파라미터 설정 및 학습 훈련
SVM은 svm.setType() 함수로 확장 알고리즘을 선택할 수 있습니다. C_SVC와 NU_SVC는 분류 알고리즘이고 EPS_SVR과 NU_SVR은 회귀 알고리즘이며 ONE_CLASS는 단일 분류기입니다.
여러 가지 이유로 분류가 잘못되거나 서포트 벡터가 상대편 경계면에 너무 가까운 경우 이것을 특이점이라 하는데, C_SVC는 setC() 함수에 전달하는 C 파라미터로 특이점이 있을 수 있는 거리를 조정할 수 있게 합니다. NU_SVC는 숫자로 표현하는 C 파라미터 대신에 퍼센트를 표현하는 Nu 파라미터를 setNu() 함수로 전달하고 값은 0.0 ~ 1.0 사이의 값만 사용할 수 있습니다. EPS_SVR과 NU_SVR은 분류가 아닌 값 그 자체를 예측하는 회귀 알고리즘입니다. EPS_SVR은 setP() 함수에 P 파라미터 값을 전달해서 거리 계산의 비용을 판단합니다.
사실 현실 데이터는 항상 직선으로 분류할 수 있는 것은 아닙니다. 이런 경우 데이터의 차원을 변경하면 처리하기 쉬워집니다. setKernel() 함수에 어떤 커널 함수를 사용할지를 지정할 수 있습니다.
SVM 알고리즘을 사용하기 위해선 여러 가지 복잡한 파라미터를 적절히 설정해야 좋은 결과를 얻을 수 있는데, 이 값을 알아서 세팅해주는 trainAuto() 함수가 있습니다. 하지만 직접 설정해주는 것에 비해 train 시간이 훨씬 오래 걸립니다. SVM 객체는 save() 함수와 cv2.ml.SVM_load() 함수가 구현되어 있어 훈련된 SVM 객체를 저장했다 다시 읽어 들여 예측에 사용 가능합니다.
import cv2
import numpy as np
import matplotlib.pylab as plt
# 0~158 구간 임의의 수 25 x 2 생성 ---①
a = np.random.randint(0,158,(25,2))
# 98~255 구간 임의의 수 25 x 2 생성 ---②
b = np.random.randint(98, 255,(25,2))
# a, b를 병합, 50 x 2의 임의의 수 생성 ---③
trainData = np.vstack((a, b)).astype(np.float32)
# 0으로 채워진 50개 배열 생성 ---④
responses = np.zeros((50,1), np.int32)
# 25 ~ 50 까지 1로 변경 ---⑤
responses[25:] = 1
# 0과 같은 자리의 학습 데이타는 빨강색 삼각형으로 분류 및 표시 ---⑥
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# 1과 같은 자리의 학습 데이타는 파랑색 사각형으로 분류 및 표시 ---⑦
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
# 0~255 구간의 새로운 임의의 수 생성 및 초록색 원으로 표시 ---⑧
newcomer = np.random.randint(0,255,(1,2)).astype(np.float32)
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
# SVM 알고리즘 객체 생성 및 훈련---⑨
svm = cv2.ml.SVM_create()
svm.trainAuto(trainData, cv2.ml.ROW_SAMPLE, responses)
# svm_random.xml 로 저장 ---⑩
svm.save('./svm_random.xml')
# 저장한 모델을 다시 읽기 ---⑪
svm2 = cv2.ml.SVM_load('./svm_random.xml')
# 새로운 임의의 수 예측 ---⑫
ret, results = svm2.predict(newcomer)
# 결과 표시 ---⑬
plt.annotate('red' if results[0]==0 else 'blue', xy=newcomer[0], xytext=(newcomer[0]+1))
print("return:%s, results:%s"%(ret, results))
plt.show()
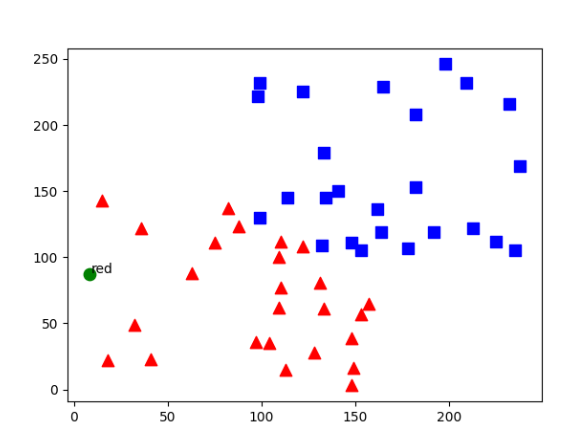
25개의 난수를 약간 겹치는 구간이 있도록 생성했습니다. 총 50개의 난수가 존재하고 이 값들의 레이블이 될 50 x 1 크기의 배열을 만들고 0과 1로 나눴습니다. 각 레이블에 맞춰 red와 blue로 분류를 하고 SVM 알고리즘 객체를 생성한 후 trainAuto()를 사용해 훈련을 했습니다. 예측 결과가 red로 나온 모습입니다.
■ HOG 디스크립터
HOG(Histogram of Oriented Gradient)는 보행자 검출을 목적으로 만들어진 특징 디스크립터 중 하나로 엣지의 기울기 방향과 규모를 히스토그램으로 나타낸 것입니다. SIFT, SURF, ORB 등과 같은 특징 디스크립터들은 특징점 하나하나에 대해서 서술하고 있어서 객체의 지역적 특성을 표현하는 데는 뛰어나지만, 전체적인 모양을 특징으로 표현하기는 어렵습니다. 그에 반해서, HOG는 지역적인 특징보다는 전체적인 모양을 표현하기에 적합합니다. HOG는 대상 객체의 상태나 자세가 약간 다르더라도 그 특징을 일반화해서 같은 객체로 인식하는 것이 특징입니다.
HOG 디스크립터를 만들기 위해서는 우선 전체 이미지에서 인식하고자 하는 영역을 잘라내야 합니다. 이것을 윈도(window)라고 하며, 그 크기는 인식할 객체의 크기를 담을 수 있는 정도여야 합니다. 보행자를 검출할 때는 사람이 세로로 긴 상태라서 보통 64 x 128 크기로 하는 것이 일반적입니다.
잘라낸 영역을 소벨 필터를 이용해 엣지의 기울기를 gx, gy를 구하고, 기울기의 방향(direction)과 크기(magnitude)를 계산합니다. 얻은 엣지의 경사도에 대해서 히스토그램을 계산합니다.윈도 전체를 하나의 히스토그램으로 계산하는 것이 아니라 작은 영역으로 다시 나누어서 히스토그램을 계산하는데, 이 영역을 셀(cell) 이라고 합니다. 셀의 크기는 경험저긍로 구해야 하지만, 일반적으로 보행자 검출에서는 8 x 8 크기의 셀로 나눕니다. 한 셀의 엣지 기울기 값으로 히스토그램을 계산하는 데 기울기의 방향을 계급(bin)으로 하고 기울기의 크기를 값으로 누적하는 방식입니다.
히스토그램 계산을 마치고 나면 다시 normalize를 합니다. 엣지 기울기는 전체 밝기에 민감하므로 주변 픽셀과의 차이를 고려해 민감성을 제거하는 과정입니다. normalize를 위해서 다시 한번 윈도를 잘게 나누는데, 이것을 블록(block)이라고 합니다. 블록의 크기는 흔히 셀 크기의 2배로 하는 것이 일반적입니다. 8 x 8 크기의 셀인 경우 블록의 크기는 16 x 16으로 볼 수 있고 36 x 1 크기의 벡터로 표현할 수 있습니다. 각 블록은 셀들을 순차적으로 이동하면서 normalize를 하는데, 이때 겹치는 부분을 블록 스트라이드(block stride)라고 합니다. 64 x 128 윈도에 16 x 16 크기의 블록이 8 x 8만큼 겹치면서 계산할 경우, 경우의 수는 7 x 15 = 105입니다. 따라서 최종 HOG 디스크립터의 크기는 105 x 36 = 3780이 됩니다.
- descriptor = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins): HOG 디스크립터 추출기 생성
- winSize: 윈도 크기, HOG 추출 영역
- blockSize: 블록 크기, 정규화 영역
- blockStride: 정규화 블록 겹침 크기
- cellSize: 셀 크기, 히스토그램 계산 영역
- nbins: 히스토그램 계급 수
- descriptor: HOG 특징 디스크립터 추출기
- hog = descriptor.compute(img): HOG 계산
- img: 계산 대상 이미지
- hog: HOG 특징 디스크립터 결과
import cv2
import numpy as np
import mnist
import time
# 기울어진 숫자를 바로 세우기 위한 함수 ---①
affine_flags = cv2.WARP_INVERSE_MAP|cv2.INTER_LINEAR
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*20*skew], [0, 1, 0]])
img = cv2.warpAffine(img,M,(20, 20),flags=affine_flags)
return img
# HOGDescriptor를 위한 파라미터 설정 및 생성---②
winSize = (20,20)
blockSize = (10,10)
blockStride = (5,5)
cellSize = (5,5)
nbins = 9
hogDesc = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nbins)
if __name__ =='__main__':
# MNIST 이미지에서 학습용 이미지와 테스트용 이미지 가져오기 ---③
train_data, train_label = mnist.getTrain(reshape=False)
test_data, test_label = mnist.getTest(reshape=False)
# 학습 이미지 글씨 바로 세우기 ---④
deskewed = [list(map(deskew,row)) for row in train_data]
# 학습 이미지 HOG 계산 ---⑤
hogdata = [list(map(hogDesc.compute,row)) for row in deskewed]
train_data = np.float32(hogdata)
print('SVM training started...train data:', train_data.shape)
# 학습용 HOG 데이타 재배열 ---⑥
train_data = train_data.reshape(-1,train_data.shape[2])
# SVM 알고리즘 객체 생성 및 훈련 ---⑦
svm = cv2.ml.SVM_create()
startT = time.time()
svm.trainAuto(train_data, cv2.ml.ROW_SAMPLE, train_label)
endT = time.time() - startT
print('SVM training complete. %.2f Min'%(endT/60))
# 훈련된 결과 모델 저장 ---⑧
svm.save('svm_mnist.xml')
# 테스트 이미지 글씨 바로 세우기 및 HOG 계산---⑨
deskewed = [list(map(deskew,row)) for row in test_data]
hogdata = [list(map(hogDesc.compute,row)) for row in deskewed]
test_data = np.float32(hogdata)
# 테스트용 HOG 데이타 재배열 ---⑩
test_data = test_data.reshape(-1,test_data.shape[2])
# 테스트 데이타 결과 예측 ---⑪
ret, result = svm.predict(test_data)
# 예측 결과와 테스트 레이블이 맞은 갯수 합산 및 정확도 출력---⑫
correct = (result==test_label).sum()
print('Accuracy: %.2f%%'%(correct*100.0/result.size))위 코드는 MNIST 손글씨 숫자를 HOG 디스크립터로 표현해서 이것을 SVM으로 훈련하는 코드입니다. deskew() 함수는 숫자 하나의 모멘트를 계산해서 중심점을 기준으로 기울어진 숫자를 바로 세웁니다. 학습을 한 후 재사용하기 위해 svm_mnist, xml로 저장했습니다.
import cv2
import numpy as np
import mnist
import svm_mnist_hog_train
# 훈련해서 저장한 SVM 객체 읽기 ---①
svm = cv2.ml.SVM_load('./svm_mnist.xml')
# 인식할 손글씨 이미지 읽기 ---②
image = cv2.imread('../img/4027.png')
cv2.imshow("image", image)
cv2.waitKey(0)
# 인식할 이미지를 그레이 스케일로 변환 및 스레시홀드 적용 ---③
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
_, gray = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY_INV)
# 최외곽 컨투어만 찾기 ---④
contours, _ = cv2.findContours(gray, cv2.RETR_EXTERNAL, \
cv2.CHAIN_APPROX_SIMPLE)
for c in contours:
# 컨투어를 감싸는 외접 사각형 구하기 ---⑤
(x, y, w, h) = cv2.boundingRect(c)
# 외접 사각형의 크기가 너무 작은것은 제외 ---⑥
if w >= 5 and h >= 25:
# 숫자 영역만 roi로 확보하고 사각형 그리기 ---⑦
roi = gray[y:y + h, x:x + w]
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 1)
# 테스트 데이타 형식으로 변환 ---⑧
px20 = mnist.digit2data(roi, False)
# 기울어진 숫자를 바로 세우기 ---⑨
deskewed = svm_mnist_hog_train.deskew(px20)
# 인식할 숫자에 대한 HOG 디스크립터 계산 ---⑩
hogdata = svm_mnist_hog_train.hogDesc.compute(deskewed)
testData = np.float32(hogdata).reshape(-1, hogdata.shape[0])
# 결과 예측해서 표시 ---⑪
ret, result = svm.predict(testData)
cv2.putText(image, "%d"%result[0], (x , y + 155), \
cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)
cv2.imshow("image", image)
cv2.waitKey(0)
cv2.destroyAllWindows()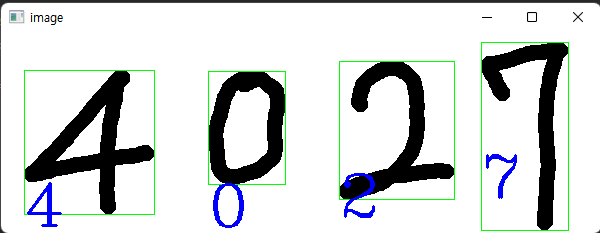
저장했던 svm_mlist.xml 파일에서 모델을 로드해 객체를 준비한 후 이미지에 적용한 코드입니다. 결과를 보면 잘 구분하는 것을 알 수 있습니다.
■ 보행자 인식
HOG와 SVM을 이용해서 보행자를 인식하는 것은 간단하지만은 않습니다. 방대한 보행자 영상을 구해 훈련을 해야 하는데, MNIST 손글씨를 학습하는 데도 무척 긴 시간과 컴퓨팅 파워가 필요했습니다. 보행자 영상은 MNIST 영상보다 크고 복잡하므로 더 오랜 시간과 컴퓨팅 파워가 필요합니다. 또한, 객체 인식에서는 항상 고려되어야 하는 것이 학습한 객체와 인식하려는 객체의 크기 변화와 회전이 발생했는가입니다. 보행자의 경우 하상 서 있는 자세이므로 회전에 대한 부분은 고려하지 않는다 하더라도 영상에 따라 크기가 달라지는 것은 어쩔 수 없습니다. 그래서 윈도 크기를 달리하면서 검출 작업을 반복해야 합니다.
cv2.HOGDescriptor 클래스는 단순히 HOG 디스크립터를 계산해 줄 뿐만 아니라 훈련된 SVM 모델을 전달받아 객체 인식을 할 수 있습니다.
- svmdetector = cv2.HOGDescriptor_getDefaultPeopleDetector(): 64 x 128 윈도 크기로 훈련된 모델
- svmdetector = cv2.HOGDescriptor_getDaimlerPeopleDetector(): 48 x 96 윈도 크기로 훈련된 모델
- descriptor = cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins): HOG 생성
- descriptor.setSVMDetector(svmdetector): 훈련된 SVM 모델 설정
- rects, weights = descriptor.detectMultiScale(img): 객체 검출
- img: 검출하고자 하는 이미지
- rects: 검출된 결과 영역 좌표 N x 4(x, y, w, h)
- weights: 검출된 결과 계수 N x 1
import cv2
# default 디덱터를 위한 HOG 객체 생성 및 설정--- ①
hogdef = cv2.HOGDescriptor()
hogdef.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# dailer 디덱터를 위한 HOG 객체 생성 및 설정--- ②
hogdaim = cv2.HOGDescriptor((48,96), (16,16), (8,8), (8,8), 9)
hogdaim.setSVMDetector(cv2.HOGDescriptor_getDaimlerPeopleDetector())
cap = cv2.VideoCapture('../img/walking.avi')
mode = True # 모드 변환을 위한 플래그 변수
print('Toggle Space-bar to change mode.')
while cap.isOpened():
ret, img = cap.read()
if ret :
if mode:
# default 디텍터로 보행자 검출 --- ③
found, _ = hogdef.detectMultiScale(img)
for (x,y,w,h) in found:
cv2.rectangle(img, (x,y), (x+w, y+h), (0,255,255))
else:
# daimler 디텍터로 보행자 검출 --- ④
found, _ = hogdaim.detectMultiScale(img)
for (x,y,w,h) in found:
cv2.rectangle(img, (x,y), (x+w, y+h), (0,255,0))
cv2.putText(img, 'Detector:%s'%('Default' if mode else 'Daimler'), \
(10,50 ), cv2.FONT_HERSHEY_DUPLEX,1, (0,255,0),1)
cv2.imshow('frame', img)
key = cv2.waitKey(1)
if key == 27:
break
elif key == ord(' '):
mode = not mode
else:
break
cap.release()
cv2.destroyAllWindows()

위 코드는 HOGDescriptor_getDefaultPeopleDetector() 함수에 의해서 제공되는 64 x 128 크기의 윈도로 훈련된 모델을 이용하는데, HOGDescriptor() 생성자의 기본 값도 이와 같으므로 디폴트 생성자로 생성해 사용합니다. HOGDescriptor_getDaimlerPeopleDetector() 함수가 제공하는 48 x 96 크기의 윈도로 훈련된 모델을 쓰기 때문에 생성자도 이에 맞게 설정합니다. 위 코드는 스페이스바를 누를 때마다 디폴트 보행자 검출기와 다임러 보행자 검출기를 바꾸어 사용하도록 했습니다. 디폴트의 경우 불필요한 검출이 적은 대신 멀리 있는 작은 보행자는 검출하지 못하며, 다임러 검출기는 작은 보행자뿐만 아니라 삼각대와 건물 그림자도 보행자로 인식하는 것을 알 수 있습니다.
9.5 BOW
BOW(Bag of Words)는 우리 말로는 단어 주머니라고도 하는데, 원래 문서 분류에 사용하던 알고리즘인데 컴퓨터 비전 분야에서 이 아이디어를 가져다 쓰고 있습니다. 문서를 분류하려고 할 때 컴퓨터로 문서의 문맥을 이해하고 분류하는 것은 매우 어려우므로 문맥이 아닌 문서에 등장하는 낱말의 빈도를 세서 자주 나타나는 낱말로 문서 카테고리를 구분하는 원리입니다.
■ BOW 알고리즘과 객체 인식
BOW 알고리즘은 문서에 어떤 낱말이 자주 나타나는지에 따라 분류한다고 했는데, 간단한 예로 문서에 훈련, 사격, 작전, 조준, 폭파와 같은 낱말이 자주 나온다면 아마두 구사와 관련된 문서일 것입니다. BOW는 분류하고자 하는 모든 분야의 특징으로 볼 수 있는 낱말들을 미리 조사해서 사전을 만들고 이미 분류되어 있는 문서들마다 사전에 등록된 단어가 얼마나 자주 나오는지를 히스토그램으로 만들어서 분류 항목별 학습 데이터를 만듭니다.
컴퓨터 비전 분야에서는 낱말 대신 SIFT, SURF와 같은 특징 디스크립터를 사용한다는 차이만 있을 뿐 같은 절차를 따릅니다. 영상에 SIFT와 같은 특징 디스크립터를 계산해서 하나의 저장 공간에 저장합니다. 그다음 마구잡이로 뒤섞여 있는 특징 디스크립터를 k-means 클러스터 알고리즘으로 군집화합니다.
그 다음 사전을 만들 때와 같은 특징 디스크립터를 계산해서 시각 사전에 등록된 특징 디스크립터와 매칭되는 것이 얼마나 되는지 히스토그램을 작성하고 레이블을 만들어 짝지어 준비합니다. 각 이미지의 히스토그램과 레이블로 SVM과 같은 분류 알고리즘에게 학습 데이터의 입력으로 주고 훈련시킵니다. 예측할 이미지를 읽어 사전을 만들 때와 같은 특징 디스크립터를 계산해서 사전에 등록된 특징점과의 매칭 히스토그램으로 SVM을 예측시킵니다.
BOW 알고리즘을 구현하기 위해서는 k-mean 클러스터, SIFT와 같은 특징 디스크립터 추출기, BF와 같은 특징점 매칭기가 필요하고 매칭점에 대한 히스토그램을 계산하는 구현이 필요합니다. OpenCV는 객체만 전달해준다면 세부적인 과정은 알아서 처리해 주는 BOW 관련 API를 제공해줍니다.
- trainer = cv2.BOWTrainer: BOW 알고리즘 추상 클래스
- trainer.add(descriptors): 특징 디스크립터 추가
- descriptors: 특징 디스크립터(SIFT, SURF, ORB 등)
- dictionary = trainer.cluster(): 군집화해서 사전 생성
- dictionary: 시각 사전
- trainer = cv2.BOWKMeansTrainer(clusterCount): k-means 클러스터로 구현된 클래스
- clusterCount: 군집화할 클러스터 개수
- extractor = cv2.BOWImgDescriptorExtractor(dextractor, dmatcher): 매칭점으로 히스토그램을 계산하는 클래스 생성자
- dextractor: DescriptorExtractor를 상속한 특징 검출기
- dmatcher: DescriptorMatcher를 상속한 특징 매칭기
- extractor.setVocabulary(dictionary): 사전 객체 설정
- dictionary: BOWTrainer로 생성한 사전 객체
- histogram = extractor.compute(img, keypoint): 이미지와 사전의 매칭점으로 히스토그램 계산
- img: 계산할 이미지
- keypoint: 이미지에서 추출한 키 포인트
- histogram: 이미지와 사전의 매칭점 히스토그램
import cv2
import numpy as np
import os, glob, time
# 각종 변수 선언---①
startT = time.time() # 소요시간 측정을 위한 시간 저장
categories = ['airplanes', 'Motorbikes' ] # 카테고리 이름
dictionary_size = 50 # 사전 크기, 클러스터 갯수
base_path = "../img/101_ObjectCategories/" # 학습 이미지 기본 경로
dict_file = './plane_bike_dict.npy' # 사전 객체 저장할 파일 이름
svm_model_file = './plane_bike_svm.xml' # SVM 모델 객체 저장할 파일 이름
# 추출기와 BOW 객체 생 --- ②
detector = cv2.SIFT_create() # 추출기로 SIFT 생성
matcher = cv2.BFMatcher(cv2.NORM_L2) # 매칭기로 BF 생성
bowTrainer = cv2.BOWKMeansTrainer(dictionary_size) # KMeans로 구현된 BWOTrainer 생성
bowExtractor = cv2.BOWImgDescriptorExtractor(detector, matcher) # 히스토그램 계산할 BOW추출기 생성
# 특징 디스크립터를 KMeansTrainer에 추가---③
train_paths = [] # 훈련에 사용할 모든 이미지 경로
train_labels = [] # 학습 데이타 레이블
print('Adding descriptor to BOWTrainer...')
for idx, category in enumerate(categories): # 카테고리 순회
dir_path = base_path + category
img_paths = glob.glob(dir_path +'/*.jpg')
img_len = len(img_paths)
for i, img_path in enumerate(img_paths): # 카테고리 내의 모든 이미지 파일 순회
train_paths.append(img_path)
train_labels.append(idx) # 학습 데이타 레이블, 0 또는 1
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 특징점과 특징 디스크립터 추출 및 bowTrainer에 추가 ---④
kpt, desc= detector.detectAndCompute(gray, None)
bowTrainer.add(desc)
print('\t%s %d/%d(%.2f%%)' \
%(category,i+1, img_len, (i+1)/img_len*100), end='\r')
print()
print('Adding descriptor completed...')
# KMeans 클러스터로 군집화하여 시각 사전 생성 및 저장---⑤
print('Starting Dictionary clustering(%d)... \
It will take several time...'%dictionary_size)
dictionary = bowTrainer.cluster() # 군집화로 시각 사전 생성
np.save(dict_file, dictionary) # 시각 사전 데이타(넘파일)를 파일로 저장
print('Dictionary Clustering completed...dictionary shape:',dictionary.shape)
# 시각 사전과 모든 이미지의 매칭점으로 히스토그램 계산---⑥
bowExtractor.setVocabulary(dictionary) # bowExtractor에 시각 사전 셋팅
train_desc = [] # 학습 데이타
for i, path in enumerate(train_paths): # 모든 학습 대상 이미지 순회
img = cv2.imread(path) # 이미지 읽기
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 매칭점에 대한 히스토그램 계산 --- ⑦
hist = bowExtractor.compute(gray, detector.detect(gray))
train_desc.extend(hist)
print('Compute histogram training set...(%.2f%%)'\
%((i+1)/len(train_paths)*100),end='\r')
print("\nsvm items", len(train_desc), len(train_desc[0]))
# 히스토그램을 학습데이타로 SVM 훈련 및 모델 저장---⑧
print('svm training...')
svm = cv2.ml.SVM_create()
svm.trainAuto(np.array(train_desc), cv2.ml.ROW_SAMPLE, np.array(train_labels))
svm.save(svm_model_file)
print('svm training completed.')
print('Training Elapsed: %s'\
%time.strftime('%H:%M:%S', time.gmtime(time.time()-startT)))
# 원래의 이미지로 테스트 --- ⑨
print("Accuracy(Self)")
for label, dir_name in enumerate(categories):
labels = []
results = []
img_paths = glob.glob(base_path + '/'+dir_name +'/*.*')
for img_path in img_paths:
labels.append(label)
img = cv2.imread(img_path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
feature = bowExtractor.compute(gray, detector.detect(gray))
ret, result = svm.predict(feature)
resp = result[0][0]
results.append(resp)
labels = np.array(labels)
results = np.array(results)
err = (labels != results)
err_mean = err.mean()
print('\t%s: %.2f %%' % (dir_name, (1 - err_mean)*100))
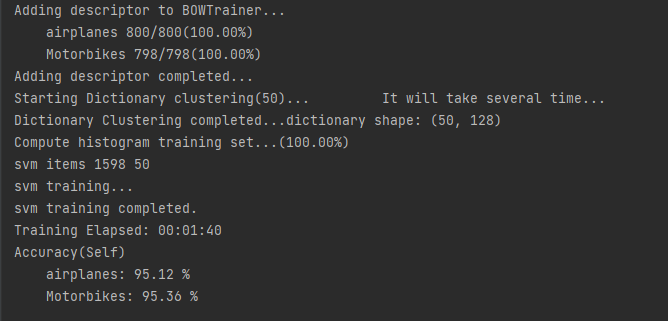
BOW와 SVM으로 비행기와 모터사이클을 인식하도록 훈련하는 코드입니다. categories에 저장한 airplanes과 Motorbikes는 해당 디렉터리의 이름과 같습니다. 특징 추출기로 SIFT와 특징 매칭기로 BF를 각각 생성해서 BOWImgDescriptorExtractor()에 전달하고 BOWKMeansTrainer()도 생성합니다.
이미지들을 읽어서 SIFT로 특징 디스크립터를 추출한 후에 BOWKMeansTrainer에 추가합니다. BOWKMeansTrainer에는 수많은 비행기와 모터사이클의 특징 디스크립터가 뒤섞여 저장되어 있습니다. dictionary에는 비행기와 모터사이클의 평균적인 특징을 나타내는 50개의 디스크립터가 있습니다.
위 코드에 마지막에는 훈련한 자신의 데이터로 예측해서 정확도를 구해 출력합니다. 원래 테스트를 위해서는 별도의 데이터셋을 준비해야 하지만 클러스터 수가 50개로 너무 적어서 높은 인식률을 기대하기 어렵기 때문에 정확도를 측정하는 방식으로 했습니다.
import cv2
import numpy as np
categories = ['airplanes', 'Motorbikes' ]
dict_file = './plane_bike_dict.npy'
#dict_file = './plane_bike_dict_4000.npy'
svm_model_file = './plane_bike_svm.xml'
#svm_model_file = './plane_bike_svm_4000.xml'
# 테스트 할 이미지 경로 --- ①
imgs = ['../img/aircraft.jpg','../img/jetstar.jpg',
'../img/motorcycle.jpg', '../img/motorbike.jpg']
# 특징 추출기(SIFT) 생성 ---②
detector = cv2.SIFT_create()
# BOW 추출기 생성 및 사전 로딩 ---③
bowextractor = cv2.BOWImgDescriptorExtractor(detector, \
cv2.BFMatcher(cv2.NORM_L2))
bowextractor.setVocabulary(np.load(dict_file))
# 훈련된 모델 읽어서 SVM 객체 생성 --- ④
svm = cv2.ml.SVM_load(svm_model_file)
# 4개의 이미지 테스트
for i, path in enumerate(imgs):
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 테스트 이미지에서 BOW 히스토그램 추출 ---⑤
hist = bowextractor.compute(gray, detector.detect(gray))
# SVM 예측 ---⑥
ret, result = svm.predict(hist)
# 결과 표시
name = categories[int(result[0][0])]
txt, base = cv2.getTextSize(name, cv2.FONT_HERSHEY_PLAIN, 2, 3)
x,y = 10, 50
cv2.rectangle(img, (x,y-base-txt[1]), (x+txt[0], y+txt[1]), (30,30,30), -1)
cv2.putText(img, name, (x,y), cv2.FONT_HERSHEY_PLAIN, \
2, (0,255,0), 2, cv2.LINE_AA)
cv2.imshow(path, img)
cv2.waitKey(0)
cv2.destroyAllWindows()

위 코드는 학습한 데이터를 가지고 test 하는 내용입니다. 훈련된 SVM 모델을 읽어 들여 객체를 생성합니다. 그다음 테스트할 이미지를 하나씩 읽어 BOW 히스토그램을 추출한 결과로 SVM으로 예측하고 그 결과를 출력합니다.
9.6 캐스케이드 분류기
캐스케이드 분류기(cascade classifier)는 개발자가 직접 머신러닝 학습 알고리즘을 사용하지 않고도 객체를 검출할 수 있도록 OpenCV가 제공하는 대표적인 상위 레벨 API입니다. 캐스케이드 분류기는 트리 기반 부스트된 거절 캐스케이드 개념을 기초로 하며 얼굴 인식을 목적으로 했다가 이후 그 목적을 일반화해서 얼굴 말고도 대부분의 물체(강체) 인식이 가능합니다.
OpenCV에서 처음으로 구현할 때는 알프레드 하르(Alfred Haar)가 처음 제안한 하르 웨이블릿(Haar wavelet)이라는 피처만 지원하여 하르 캐스케이드(Haar cascade)로 더 많이 알려져 있지만, 이후 대각선 피처와 로컬 바이너리 패턴(LBP)을 추가 확장하여 이제는 다른 피러를 직접 작성해서 사용할 수도 있습니다.
■ 하르 캐스케이드 얼굴 검출
OpenCV는 캐스케이드 분류기에 사용할 수 있는 훈련된 검출기를 xml 파일 형태로 제공합니다. 이 파일은 OpenCV 저장소의 'data' 디렉터리 안에 피처에 따라 디렉터리로 나누어져 있습니다. 'haarcascade'는 얼굴 검출을 목적으로 만들어졌으므로 가장 좋은 얼굴 인식률을 보입니다.
- classifier = cv2.CascadeClassifier([filename]): 캐스케이드 분류기 생성자
- filename: 검출기 저장 파일 경로
- classifier: 캐스케이드 분류기 객체
- rect = classifier.detectMultiScale(img, scaleFactor, minNeighbors [, flags, minSize, maxSize])
- img: 입력 이미지
- scaleFactor: 이미지 확대 크기에 제한, 1.3 ~ 1.5(큰 값: 인식 기회 증가, 속도 감소)
- minNeighbors: 요구되는 이웃 수(큰 값: 품질 증가, 검출 개수 감소)
- flags: 구식 API를 위한 것, 지금은 사용 안 함
- minSize, maxSize: 해당 사이즈 영역을 넘으면 검출 무시
- rect: 검출된 영역 좌표(x, y, w, h)
import numpy as np
import cv2
# 얼굴 검출을 위한 케스케이드 분류기 생성 --- ①
face_cascade = cv2.CascadeClassifier('./data/haarcascade_frontalface_default.xml')
# 눈 검출을 위한 케스케이드 분류기 생성 ---②
eye_cascade = cv2.CascadeClassifier('./data/haarcascade_eye.xml')
# 검출할 이미지 읽고 그레이 스케일로 변환 ---③
img = cv2.imread('../img/children.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 얼굴 검출 ---④
faces = face_cascade.detectMultiScale(gray)
# 검출된 얼굴 순회 ---⑤
for (x,y,w,h) in faces:
# 검출된 얼굴에 사각형 표시 ---⑥
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# 얼굴 영역을 ROI로 설정 ---⑦
roi = gray[y:y+h, x:x+w]
# ROI에서 눈 검출 ---⑧
eyes = eye_cascade.detectMultiScale(roi)
# 검출된 눈에 사각형 표 ---⑨
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(img[y:y+h, x:x+w],(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
# 결과 출력
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()위 코드는 얼굴을 인식한 다음 해당 영역에서 눈까지 인식하는 코드입니다. haarcascade_frontalface_default.xml 파일로 캐스케이드 분류기를 생성하는데, 이것은 얼굴 검출을 위해 훈련된 검출기입니다. 얼굴로 검출된 영역을 파란색 박스로 표시합니다. 그 영역을 ROI로 설정하고 ROI 내에서 눈을 검출해 녹색 박스로 표시합니다.
■ LBPH 얼굴 인식
영상에서 얼굴을 검출하는 것에서 한걸음 더 나아간다면 그 얼굴이 누구인지를 알아내는 것입니다. 누구 얼굴인지 인식하기 위한 일반적인 절차는 크게 3단계로 볼 수 있습니다. 먼저 인식하고자 하는 사람의 얼굴 사진을 최대한 많이 수집하는 것입니다. 그다음 이것을 학습 데이터셋으로 해서 눈, 코, 입 같은 얼굴의 주요 부위를 위주로 피처를 분석해서 학습 모델을 만듭니다. 마지막으로 인식하고자 하는 얼굴을 학습한 모델로 예측해서 누구의 얼굴인지 분류하고 정확도를 표시합니다. OpenCV는 3 버전에서부터 엑스트라 모듈로 face 모듈을 추가하고 세 가지 얼굴 인식기를 제공했습니다.
- EigenfaceRecognizer
- FisherFaceRecognizer
- LBPHFaceRecognizer
LBPHFsceRecognizer는 로컬 바이너리 패턴 히스토그램(local binary pattern histogram)으로 얼굴을 인식합니다. LBP 또는 LBPH라고 불리는 이 특징 디스크립터는 공간적 관계를 유지하면서 지역적 특징을 추출합니다. LBP는 얼굴 이미지를 3 x 3 픽셀 크기의 셀로 나누고 셀 중심의 픽셀과 이웃하는 8방향의 픽셀을 비교해 중심 픽셀의 값이 이웃 픽셀 값보다 크면 0, 아니면 1로 표시하는 8자리 이진수를 만듭니다. 모든 셀의 8피트 숫자로 히스토그램을 계산하면 256차원의 특징 벡터가 만들어지고 이것을 분류기의 학습 데이터로 사용해 사용자의 얼굴을 분류합니다.
- cv2.face.FaceRecognizer: 얼굴 인식기 추상 클래스
- train(datas, labels): 학습 데이터로 훈련
- datas: 학습에 사용할 이미지의 배열
- labels: 학습 데이터 레이블
- label, confidence = predict(img): 예측
- label: 예측한 분류 결과 레이블
- confidence: 예측한 레이블에 대한 정확도(거리)
- read(file): 훈련된 모델을 파일에서 읽기
- write(file): 훈련된 모델을 파일로 쓰기
- file: 모델 저장 파일
- recognizer = cv2.face.LBPHFaceRecognizer_create(radius, neighbors, grid_x, grid_y, threshold): LBP 얼굴 인식기 생성
- radius = 1: LBP 얼굴 인식기 생성
- neighbors = 8: 값을 계산할 이웃 개수
- grid_x = 8: x 방향 셀의 크기
- grid_y = 8: y 방향 셀의 크기
- threshold = DBL_MAX: 예측 값에 적용할 스레시홀드
- train(datas, labels): 학습 데이터로 훈련
'Deep Learning(강의 및 책) > OpenCV' 카테고리의 다른 글
| [OpenCV] 영상 매칭과 추적 (0) | 2022.08.20 |
|---|---|
| [OpenCV] 영상 분할 (0) | 2022.08.04 |
| [OpenCV] 영상 필터 (0) | 2022.08.01 |
| [OpenCV] 기하학적 변환 (0) | 2022.07.30 |
| [OpenCV] 이미지 프로세싱 기초 (0) | 2022.07.23 |



