https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=9383531
ResNeXt and Res2Net Structures for Speaker Verification
The ResNet-based architecture has been widely adopted to extract speaker embeddings for text-independent speaker verification systems. By introducing the residual connections to the CNN and standardizing the residual blocks, the ResNet structure is capable
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
Res-Net기반 architecture는 text independent speaker verifcation system에서 speaker embedding을 추출하기 위해 많이 사용되어 왔습니다. 하지만, input feature space가 복잡해질 때, ResNet network의 depth와 width를 단순히 증가시키는 것은 충분하지 않습니다. 그래서 해당 논문에서, 저자들은 speaker verification에 사용할 수 있는 ResNet기반인 ResNeXt와 Res2Net을 소개합니다. image recognition을 위해 처음 제안된 ResNeXt와 Res2Net은 depth와 width 외에도, cardinality와 scale이라는 두 가지 차원을 도입해 model의 표현력을 늘렸습니다. scale 차원을 늘림으로써 Res2Net model은 다양한 세분화를 가진 multi scale feature를 표현할 수 있으며, 이는 짧은 utterance에 대한 speaker verification을 용이하게 합니다. 저자들의 system을 3가지 speaker verification task에서 evaluate합니다.
Introduction
최근 몇 년 동안, ResNet based convolutional neural network가 TI-SV system의 backbone에 채택되었습니다. ResNet network는 model의 representation 능력을 조절하고 train data의 양에 맞추기 위해 width와 depth를 조절합니다. 그러나 input feature space가 더 복잡해지거나 train과 test condition 사이의 다양한 불일치가 존재하는 경우, ResNet network의 depth와 width를 단순히 증가시키는 것은 overfitting을 유발하여 전체 network의 일반화 능력을 저해시킵니다. 그래서 수정된 ResNet based architecture를 제안하여 feature 활용을 극대화하고 model size를 관리 가능하게 유지하는 연구가 진행되었습니다.
이 논문에선, 저자들이 speaker verification system에서 사용할 수 있는 ResNeXt와 Res2Net을 통합합니다. 두 network는 depth와 width 뿐만 아니라 cardinality와 scale이라는 두 차원을 추가로 사용합니다. ResNeXt block은 residual block에 한 layer안에 여러 개의 convolution을 가지고 있는 group으로 도입하여, multi-branch transformation(하나의 input을 동시에 여러 개의 convolution을 적용해 병렬로 처리하는 방식)으로 대체합니다. Res2Net은 residual block을 재구성합니다. residual block에 계층적 residual connection을 구성하고, 한 layer 내에서 다양한 크기의 receptive field를 설정합니다(convolution에 들어가는 input feature의 scale이 여러가지). scale dimension에서, Res2Net model은 매우 짧은 utterance에 speaker verification을 용이하게 할 수 있는 multi-scale feature를 표현할 수 있습니다.
저자들은 VoxCeleb dataset을 이용한 실험을 통해 cardinality를 증가시키는 것이 depth와 width를 추가하는 것보다 더 효율적이라는 것을 보여줍니다. 그리고 Res2Net의 multi scale feature를 표현하는 능력이 짧은 utterance에 대한 성능을 크게 향상시킬 수 있음을 보입니다.
Resnet-based speaker embedidng
end-to-end speaker verification system의 4가지 구성요소를 보겠습니다. 먼저 input feature에 대한 utterance level normalization입니다. 그 후 ResNet을 사용하여 feature pattern을 인식하고 frame level speaker representation을 생성합니다. 고정된 길이의 utterance level speaker embedding을 가변 길이의 audio input으로부터 만들기 위해, attentive pooling layer을 추가합니다. 마지막으로, train을 위해 speaker discriminative criterion을 선택합니다.
Utterance-level mean normalization
utterance level mean normalization을 input feature에 실행하는 것은 test condition에서 불일치하는 acoustic condition에 대한 system robustness를 향상시킬 수 있으며, 분산 normalization은 효과가 없습니다. 그러므로 저자들은 mean normalization을 사용합니다.
하나의 utterance로부터 추출된 input feature sequence {m_1, ... , m_T}가 주어졌을 때, 시간 축을 따라 mean μ를 계산합니다. 그리고 normalize하면 됩니다.

위와 같이 식으로 표현할 수 있습니다. m_t^는 normalize된 feature입니다. 해당 normalized feature를 neural network의 input으로 사용할 것입니다.
Network architecture
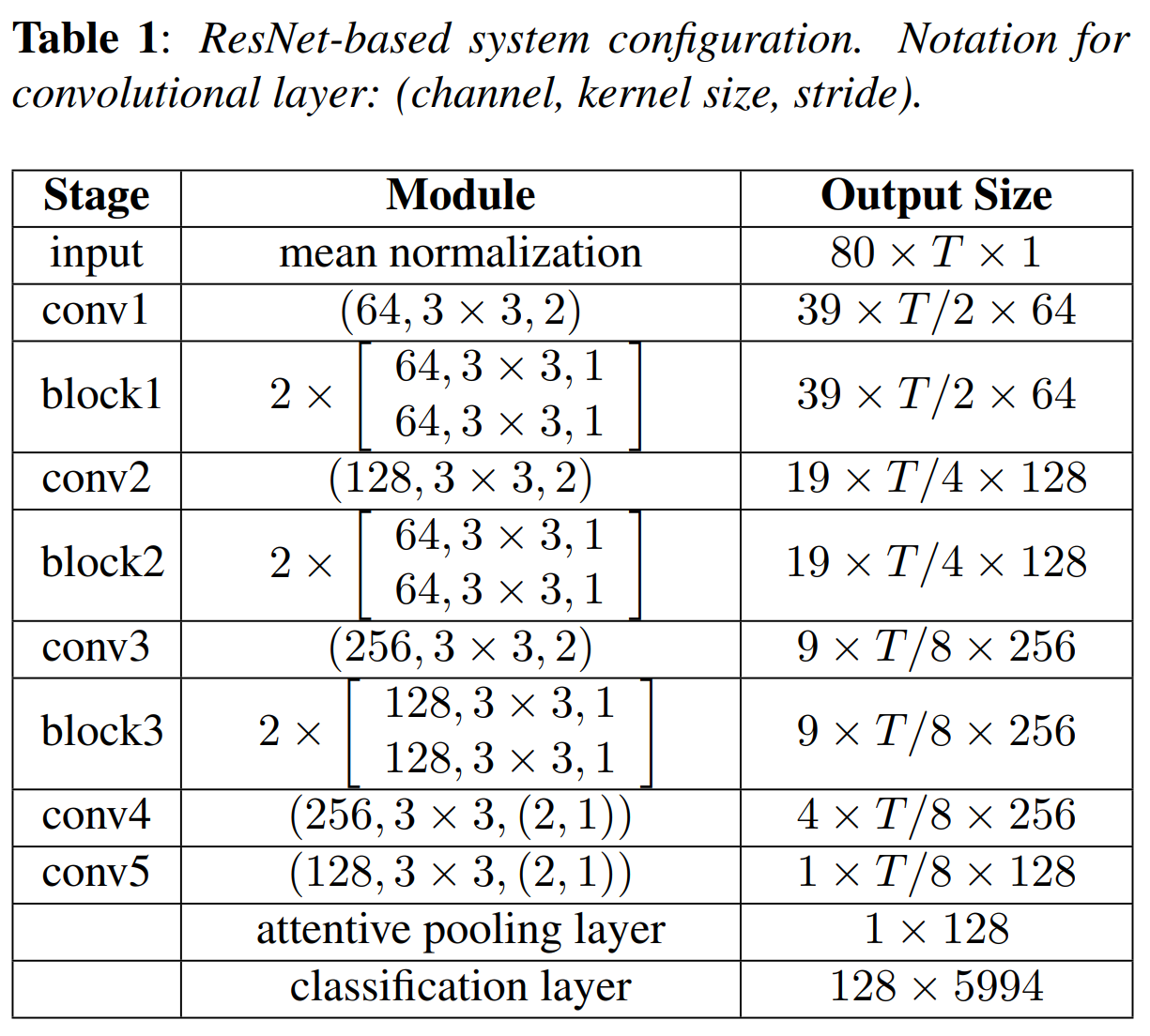
위 표는 저자들의 speaker embedding extractor 구조입니다. backbone structure는 17개의 convolutional layer가 존재하는 ResNet입니다. 80차원의 log Mel filter bank를 input feature로 받고 128차원의 speaker embedding을 생성합니다. 모든 convolutional layer 뒤에는 batch normalization layer이 있고 ReLU activation function이 있습니다. attentive pooling layer를 위해 frame level speaker embedding을 더 보존하고자 저자들은 conv4와 conv5의 layer에 time축을 stride 1으로 두고 진행했습니다.
Multi-head attentive pooling
attentive pooling layer는 frame level speaker embedding을 aggregate하고 더 안정적인 utterance level speaker embedding을 만듭니다. 이전 연구 내용에서 보이듯이, 간단한 temporal average pooling과 비교했을 때 attentive pooling은 speaker discriminative frame을 적극적으로 선택할 수 있는 잠재력을 가지고 있습니다. 저자들은 multi attention head를 사용하여 system 성능을 큰 폭으로 향상시켰습니다. 저자들은 aggregation approach로 multi-head attentive pooling(input data에 weight를 다르게 할당하여, 중요한 feature를 더 focusing하도록 만들어줍니다. multi-head를 적용하면 attentive pooling을 여러 번 병렬로 적용하여 다양한 부분에서 중요한 feature를 동시에 구해 독립적으로 weight를 계산합니다)을 사용했습니다. 성능과 모델의 복잡성 사이의 tradeoff를 고려하여, attention head 수를 16으로 설정했습니다.
Training criterion
다양한 model 구조의 representation 능력을 비교하기 위해, 저자들은 수정된 softmax나 다른 discriminative loss function을 사용하지 않았습니다. training 단계에서, utterance level speaker embedding을 추출한 후 classification layer에 넣고 naive softmax loss를 사용합니다.
Residual Block
ResNeXt block

ResNeXt block은 split-transform-merge 전략을 따르지만, ResNet block에서 단일 transformation 대신 transformation set을 사용합니다. 위 그림을 보면 알 수 있듯이, input channel을 몇 개의 더 작은 group(위 그림에서는 4개로 나눕니다)으로 나누고 각 group에 각각 transformation을 적용합니다. 모든 group에서의 output은 1x1 convolutional layer를 통해 합칩니다. trasformation set의 수를 cardinality라 부릅니다. cardinality가 늘어나면, 넓히고 깊게 만드는 것보다 더 효과적이고 효율적입니다.

ResNeXt block은 같은 topology(구조)를 공유하기 때문에, conventional ResNet의 residual block을 ResNeXt block으로 대체할 수 있고, 원하는 구조를 구성하기 위해 쉽게 쌓을 수 있습니다. basic block을 사용하는 경우, network는 총 6개의 residual block이 있고, 다 동일한 topology를 공유하며 depth는 2입니다(위 (a)와 같은 형태). 결과적으로 bottleneck block을 (b, depth = 3)으로 시작하여, 그다음 layer에서는 multi-branch transformation을 사용합니다. 즉 위 (b)와 같이 ResNeXt block을 사용하는데, residual connection이 존재하고 두번째 layer에 ResNeXt module을 넣는 식으로 구현을 한다는 말입니다.
Res2Net block
Res2Net block은 하나의 layer에 이용 가능한 receptive field를 늘려 model의 multi-scale representation ability를 향상시키는 것을 목표로합니다. 몇몇의 block을 stacking할 때, 조합 효과로 인해 다양한 granularity의 feature representation을 얻을 수 있습니다.
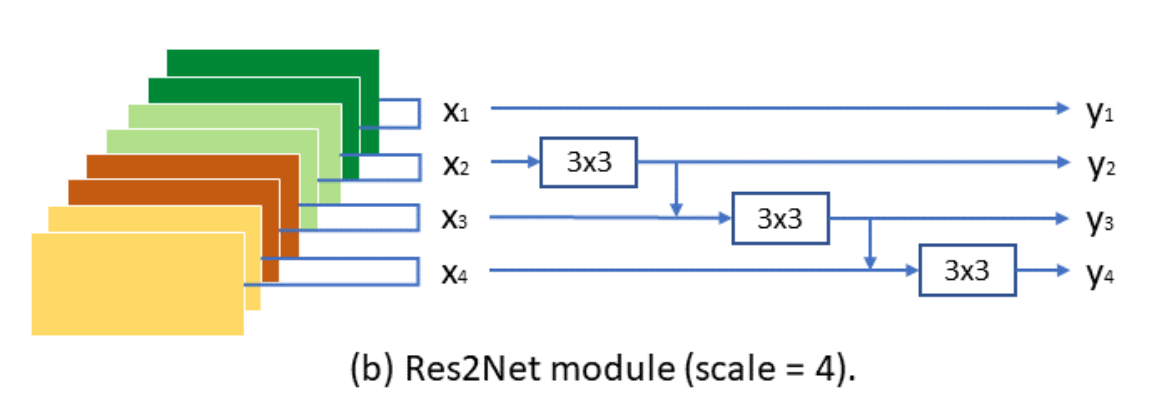
위 그림과 같이 Res2Net module이 구현됩니다.

처음 3x3 layer를 거친 후, feature map은 s개의 부분집합으로 분할되며, {x1, x2, ... , x_s}로 표시됩니다. x_1을 제외한 각 부분집합은 3x3 convolution(K_i로 표기)에 들어갑니다. x_3를 시작으로 각 K_i-1의 output은 K_i에 들어가기 전에 x_i와 더해집니다. 위 그림과 같이 x_3가 K_3에 들어가기 전에 x_2가 K_2를 거친 후에 나오는 output과 더해집니다. 계층적 residual connection과 같은 구조는 하나의 layer 내에서 가능한 receptive field를 더욱 증가시켜, 다양한 feature scale을 결과로 합니다.
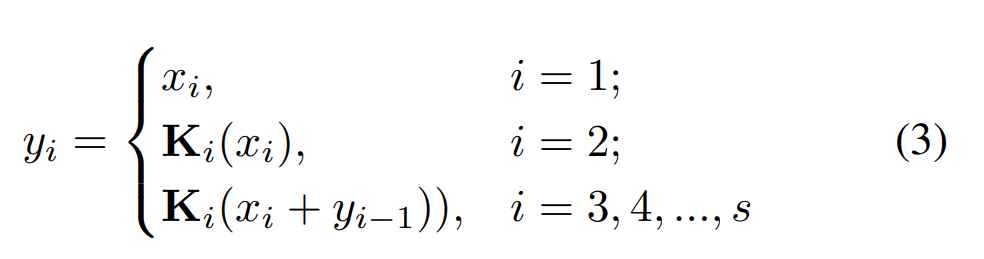
최종 수식으로 나타내면 이와 같습니다. {y_1, ... , y_i}는 module의 output이며, concat된 후에 residual block의 channel size를 유지하기 위해 1x1 convolutional layer에 들어갑니다. 여기서 s는 scale이라고 불립니다. scale이라는 값을 늘리는 것이 width, depth, cardinality를 늘리는 것보다 더 효과적이라고 합니다.
그래서 저자들의 baseline ResNet structure에 있는 basic block이 Res2Net block으로 수정하기 위해, 첫번째 3x3 layer를 유지하고 두번째를 Res2Net module로 대체합니다.
Experiments
Data Description
저자들이 제안한 방식을 VoxCeleb corpus와 2개의 Microsoft internal test set을 이용해 평가합니다.
- VoxCeleb: VoxCeleb은 공개된 text-independent dataset입니다. 이는 제약 없는 condition에서 일상생활 대화로 이루어진 dataset입니다. 다양한 acoustic 환경과 short-term utterance를 포함하고 있기 때문에 verification하기 어렵습니다.
저자들은 VoxCeleb2 development set에 존재하는 5994명의 speaker를 이용해 모든 model을 학습합니다. model의 robustness를 향상시키기 위해, 저자들은 4개의 augmentation technique(babble, music, noise, reverb)을 사용했습니다. 저자들이 제시한 모델을 40명의 speaker로 이루어진 VoxCeleb1 test set으로 평가했습니다. 완벽성을 위해, 저자들은 test condition을 2가지 더 이용하여 평가했습니다. VoxCeleb1 set(1251 speaker)를 확장한 VoxCeleb1-E를 사용하는 evaluation, 동일한 성별과 국적을 가진 speaker로 이루어진 Vox-Celeb1-H를 사용하는 evaluation입니다.
- MS-SV test set: text-independent speaker verification을 실험하기 위해 모은 test set입니다. 각 speaker는 마이크 근처에서 짧은 문단을 읽어 enroll됩니다. 그 후, 회의실 여러 곳에서 머리 떨어진 마이크를 통해 그들의 일상적인 대화를 녹음하여 test set을 만들었습니다. test set은 약 150명의 speaker로 이루어지며, 2초에서 15초 사이(평균 4초)의 test utterance를 포함합니다.
- Cortana test set: 이는 text dependent speaker verification을 위해 녹음된 test set입니다. 해당 test set은 'Cortant' 또는 'Hey Cortana'라는 시작 구문을 183명 speaker로부터 수집하여 구성되었습니다. 각 speaker는 다양한 noise 환경에서 다른 녹음 거리로 녹음했습니다. 4개의 enrollment utterance는 마이크에서 1미터 떨어진 clean condition에서 녹음되었습니다. CTC based keyword detector를 이용하여 test segment를 잘라냈습니다. CTC endpoint는 뒤로 1.5초 이동되고 앞으로 2초 이동되어, 평균 길이가 3초인 test segment가 됩니다. keyword 자체의 지속시간은 평균 0.7초입니다.
Experiments on VoxCeleb1 test set
- Regular test set

위 표는 VoxCeleb1 test set에 다양한 residual block을 적용했을 때의 결과를 보여줍니다. w는 ResNeXt 또는 Res2Net module안에 존재하는 각 3x3 convolution의 base width를 의미합니다. model complexity를 보존하기 위해 cardinality나 scale이 늘어남에 따라 w가 조절되었습니다.
complexity를 유지하는 상태에선, ResNet baseline보다 ResNeXt와 Res2Net의 성능이 좋으며, Res2Net이 가장 좋은 모습을 보입니다.
model complexity를 50% 늘렸을 때, ResNet model(ResNet-deeper, ResNet-wider)는 크게 성능이 향상하지 못했습니다. 하지만, Res2Net model인 'Res2Net-26w6s'는 큰 성능 향상이 있었습니다. model complexity가 80% 정도 늘어났을 땐, 'Res2Net-26w8s'가 모든 실험에서 가장 좋은 결과를 보였습니다. 이를 통해 width & depth보단, cardinality와 scale을 늘리는 것이 더 효과적이라는 것을 알 수 있었으며, 특히 scale이 효과적이었다는 것을 알 수 있었습니다.
- Truncated test set
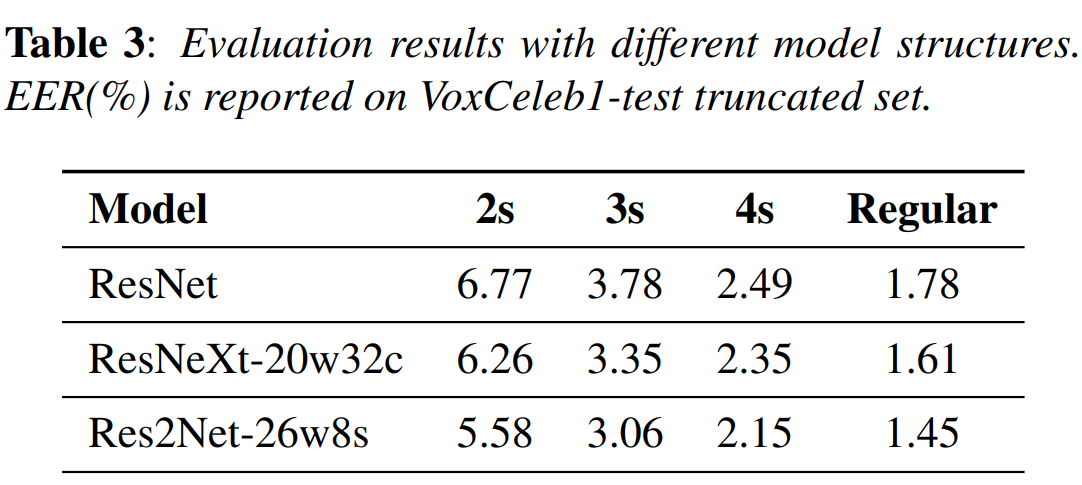
VoxCeleb1 test set에 있는 utterance는 평균 8초입니다. test pair을 각각 2초, 3초, 4초의 segment로 축소하여 짧은 segment의 축소된 test set을 도출합니다. 이 test set은 제안한 model의 multi-scale feature representation ability을 평가하는 데 사용됩니다. 위 표는 short segment에 대한 실험 결과입니다. short segment이다 보니 성능이 저하된 것을 볼 수 있습니다. 하지만 ResNeXt와 Res2Net은 여전히 ResNet보다 좋은 성능을 보입니다. Res2Net의 경우 short utterance에 상당히 좋은 모습을 보여줍니다.
- Experiments on text-independent MS-SV test set

VoxCeleb data로 학습된 model을 text independent MS-SV test set으로 평가합니다. 이를 통해 model의 일반화 능력을 평가할 수 있습니다. 결과는 위와 같습니다. enrollment utterance는 평균 20초입니다. test segment를 3개의 group으로 나눴습니다(1-2초, 2-4초 4초 이상). Res2Net이 ResNeXt보다 더 좋은 일반화 능력을 보였습니다. 이를 통해 Res2Net이 short utterance에서 ResNeXt보다 speaker representation 능력이 더 좋은 걸 알 수 있습니다.
- Experiments on text-dependent Cortana test set

text dependent Cortana test set을 이용해 실험을 진행한 결과는 위와 같습니다. 저자들은 편의를 위해, VoxCeleb data로 학습된 model을 그대로 사용합니다. 결과적으로, training data과 test data에서 발화된 context는 맞지 않습니다만, enrollment와 test utterance는 동일합니다. 위 표는 noisy condition과 마이크로부터 거리를 다양하게 설정하여 실험을 진행한 결과를 보여줍니다. Res2Net은 ResNet에 비해 noisy condition과 마이크 거리의 차이에서 더 좋은 성능을 보입니다. 하지만, ResNeXt는 ResNet에 비해 noisy condition에 취약한 것을 알 수 있습니다.
- Visualization
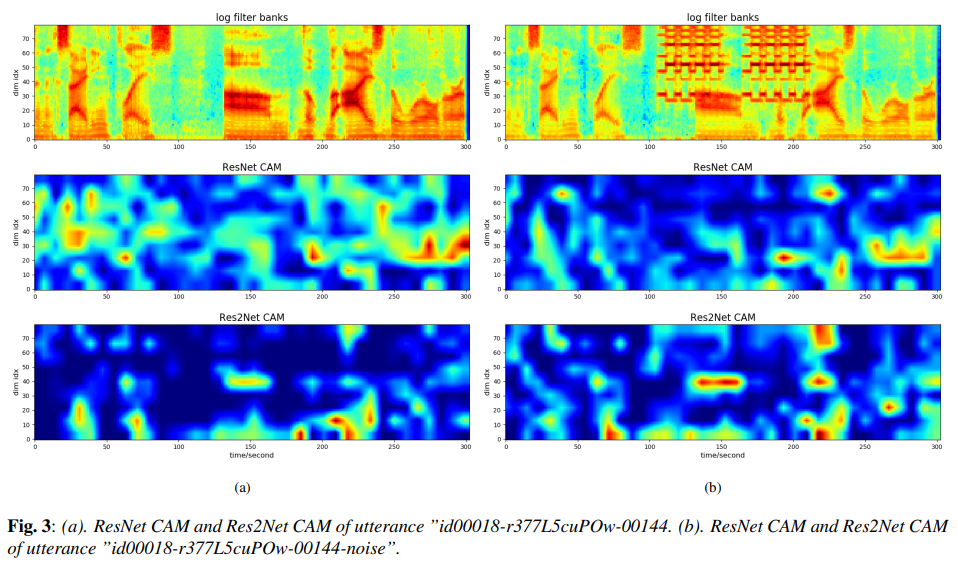
class activation mapping(CAM) 분석을 이용해 저자들은 speech data에 대한 Res2Net의 능력을 직관적으로 보여줍니다.
저자들은 clean condition과 그 시뮬레이션 버전(전화벨 noise가 추가된)을 선택하여 진행합니다. 저자들은 ResNet과 Res2Net에 두개의 utterance를 넣고 Grad-CAM을 이용해 CAM을 그립니다. 위와 같이 CAM을 얻을 수 있습니다.
clean speech의 경우, Res2Net CAM은 ResNet CAM보다 더 집중되어 그려지는 것을 볼 수 있습니다. noise가 있는 speech의 경우, Res2Net CAM의 activation map이 덜 변하는 것을 볼 수 있습니다. 추가적으로 clean condition에서의 Res2Net CAM은 speech part에 더 강조되는 것을 볼 수 있습니다. 즉 Res2Net은 불변하는 feature representation(speaker information)을 잘 추출하고, 좋지 않은 환경에서도 speaker를 잘 recognition할 수 있는 잠재력을 가지고 있습니다.
Conclusion
해당 논문에서, 저자들은 speaker verification task에서 ResNeXt와 Res2Net architecture의 효과를 연구했습니다. VoxCeleb을 이용한 실험에서 두 network의 representation 능력이 좋다는 것을 입증했습니다. 두 network 모두 ResNet baseline보다 더 좋은 성능을 보이며, 특히 Res2Net이 더 좋은 모습을 보입니다. Res2Net의 경우 short utterance와 mismatched scenario에서도 좋은 성능을 유지합니다. 또한 MS SV test set에서 Res2Net model은 더 좋은 일반화 능력을 보여줍니다.



