https://arxiv.org/pdf/1406.2661.pdf
해당 논문을 보고 작성했습니다.
Abstract
adversarial process를 통해 생성 모델을 추정하는 새로운 framework를 제언합니다. 이는 2개의 모델을 동시에 학습합니다. 데이터 분포를 capture하는 생성 모델 G(생성자), G에서 생성된 sample인지 train data에서 온 sample인지에 대한 확률을 추정하는 discriminative model D입니다(판별자).
G는 D가 mistake할 확률을 maximize하도록 학습합니다(즉, 본인이 만든 sample을 train data에서 왔다고 판별하도록). 이는 minimax two-player game과 같은 형태입니다. 임의의 함수 G와 D의 space에서, G가 training data 분포를 잘 학습하고 D는 모든 부분에서 1/2 확률로 판별을 하는 상태가 고유 해답인 game입니다.
G와 D가 multilayer로 정의된다면, 전체 system은 backpropagation으로 학습될 수 있습니다. 이러면 학습을 하거나 sample을 만들 때, Markov chain이나 approximate inference network가 필요하지 않게 됩니다. 실험을 통해 생성된 sample의 질적 및 양적 평가를 하여 framework의 potential을 입증합니다.
Introduction
Deep learning은 자연어 처리, audio waveform을 포함한 speech 등과 같은 data 종류에 대한 확률 분포를 나타내는 풍부하고 계층적 model을 발견하는 것입니다. 지금까지 가장 눈에 띄는 성공은 input을 labeling하는 discriminative model입니다. 이러한 성공은 주로 backpropagation, non-linear function 및 dropout algorithm을 기반으로 합니다.
생성 모델의 경우 덜 impact있었는데, MLE와 같은 방식을 사용할 때 많은 intractable 확률 계산을 추론하는 것에 대한 어려움 때문입니다. 또한, non-linear function의 장점을 활용하는 데 어려움이 있어 impact을 보이기 어려웠다고 합니다. 저자들은 이러한 어려움을 우회하는 새로운 generative model 추정 과정을 제안합니다.
저자들이 제안한 adversarial network frame에서 discriminative model은 sample이 model 분포에서 온 것인지, data 분포에서 온 것인지를 결정합니다. generative model은 가짜 화폐를 만들고 탐지되지 않으며 사용하려고 시도하는 위조범에 비유할 수 있으며, discriminative model은 위조 화폐를 탐지하려는 경찰에 비유할 수 있습니다. 이 상태에서 서로의 경쟁은 양 쪽이 그들의 방법을 개선하도록 만들며, 위조품이 진품과 구별될 수 없을 때까지 이어집니다.
저자들이 제안하는 framework(적대적 학습)은 많은 종류의 model과 optimization algorithm에 사용할 수 있는 training algorithm을 제공할 수 있습니다. 이 논문에서 random noise가 multi-layer perceptron을 통과하면서 sample을 생성하는 generavie model을 사용하며, discriminative model도 multi-layer perceptron입니다. 이러한 special case를 adversarial network라고 명시합니다. 이 경우, 두 model을 backpropagataion, dropout algorithm을 이용해 학습할 수 있으며 generative model은 forward propagation만 진행하여 sample을 만들 수 있습니다. 근사 추론이나 markov chain은 필요하지 않게 됩니다.
Related work
latent variable을 가지고 있는 directed graphical models의 대안으로 Boltzmann machines(RBMs), deep Boltzmann machines(DBMs) 등 latent variable을 가진 undirected graphical model에 대해 알아보겠습니다. 이러한 model 내의 상호작용은 정규화되지 않은 잠재 함수들의 곱으로 표현되며, 모든 random variable에 대한 global 합 또는 적분으로 정규화됩니다. 가장 간단한 예에서만 잠재 함수들과 그 함수의 기울기를 이용할 수 있으며, 복잡한 예에서는 사용 불가능 합니다. 그래서 Markov chain Monte Carlo method를 이용해 추정합니다(함수들의 기울기를 간접적으로 추정).
Deep belief networks(DBNs)는 undirected layer 1개와 몇 개의 directed layer로 이루어져 있습니다. 각 layer 별 빠른 근사 training critetrion이 존재하지만(각 층을 개별적으로 훈련시킨다는 방법), DNBs는 undirected model과 directed model 모두에 관련된 연산상 문제가 있습니다.
scoring matching과 noise-contrastive estimation(NCE)와 같이 likelihood를 근사하거나 bound를 사용하지 않는 criteria도 제안되었습니다. 이러한 방식들은 학습된 확률 밀도를 정규화 상수까지 분석적으로 명시될 것을 요구합니다. 즉, 확률 밀도 함수는 모든 state에 대해 확률의 총 합이 1이 되도록 만드는 상수로 나누어 졍규화되어야 한다는 뜻입니다. 하지만 DBN이나 DBM와 같은 generative model의 경우, 확률 밀도를 완전히 표현하는 것을 불가능할 수 있습니다. denoising auto-encoder와 contractive autoencoder와 같은 몇몇 model들은 RBM에서 사용되는 score macthing과 매우 유사한 learning rule을 가지고 있습니다. NCE에서는 discriminative training criterion을 사용해 generative model을 학습합니다. 저자들이 제안한 방식도 discriminative training criterion 방식입니다. 그러나 분리된 discriminative model을 fitting하는 것이 아니라 generative model을 고정된 noise distribution에서 sample해 data를 생성한 것을 구분하는 데 사용됩니다. NCE는 고정된 noise distribution을 사용하기 때문에, 관측된 variable의 작은 부분 집합에 대한 분포를 정확하게 근사한 이후에는 매우 느리게 model이 학습됩니다. 왜냐하면 학습초기에는 discriminative model이 noise로부터 생성된 data와 real data를 쉽게 구분할 수 있으며 이를 통해 성능이 향상될 수 있습니다. 하지만, generative model이 어느 정도 정확하게 근사하기 시작하면, 즉, observed variable의 작은 subset에 대해 생성된 data와 real data 사이의 차이가 줄어들기 시작하면 학습이 느려지게 됩니다.
몇몇 기술들은 확률 분포를 명시적으로 정의하는데 사용되지 않지만, 요구되는 분포로부터 sample을 만들도록 generative machine을 학습하는 데 사용됩니다. 이러한 접근법은 model이 backpropagation을 통해 학습되어 design될 수 있다는 장점을 가지고 있습니다. 최근에는 일반화된 denoising auto-encoder에서 확장된 generative stochastic network(GSN) framework가 등장했습니다. denoising auto-encoder와 generative stochastic network는 정의된 parameterized Markov chain, 즉 generative Markov chain의 한 단계를 수행하는 machine의 parameter를 학습하는 것으로 볼 수 있습니다. GSN과 비교했을 때, adversarial network frame은 Markov chain을 이용한 sampling을 필요로 하지 않습니다. adversarial network는 생성과정에서 feedback loop를 필요로 하지 않기 때문에(generator network가 직접적으로 data sample을 만들어내기 때문에 이전 step에서의 생성 결과에 의존하지 않는다는 뜻), backpropagation 성능을 향상시키지만 feedback loop에서 사용될 때 무한 활성화 문제가 있는 linear unit을 더 잘 활용할 수 있습니다(gradient exploding). 더 최근에 등장한 backpropagation을 이용하여 generative model을 학습시키는 연구에서는 auto-encoding variational Bayes나 stochastic backpropagation을 이용합니다.
Adversarial nets
adversarial modeling framework는 genrative model과 discriminative model 둘 다 multi-layer perceptron(MLP)일 때, 가장 straightforward하게 적용됩니다. data x에 대한 generator의 분포 p_g를 학습하기 위해, input noise variable p_z(z)의 prior를 정의합니다. 그다음 data space로 mapping하는 것을 G(z;θ_g)로 표현하는데, 여기서 G는 parameter θ_g를 가진 multi-layer perceptron에 의해 표현되는 미분가능한 함수를 의미합니다. 또한, 두 번째 multi-layer perceptron D(x; θ_d)를 정의하는데, 이는 single scalar를 output으로 출력합니다. D(x)는 x가 p_g로부터 온 것이 아닌 data로부터 왔을 확률을 의미합니다.
D를 train example과 G로부터 생성된 sample의 맞는 label을 할당할 확률을 최대화하도록 학습합니다. 동시에, G는 log(1-D(G(z)))를 minimize하도록 학습됩니다. 다시 말해, D와 G의 two-player minimax game V(G, D)로 표현할 수 있습니다.

위 식과 같이 작성할 수 있습니다.
adversarial network의 이론적 분석을 보이기 위해, 충분한 capacity를 가진 G와 D가 주어졌을 때, data generating 분포를 복구할 수 있다는 것을 보입니다.

위 그림을 보면 더 이해하기 쉽습니다. 실제로, 반복적이고 수많은 approach를 이용한 game을 이행해야만 합니다. train의 내부 loop에서 D를 완전히 최적화하는 것은 계산상 불가능하며, 유한한 dataset을 사용한다면 overfitting을 초래합니다. 대신에, D를 최적화하는 과정을 k step 진행하고 G를 최적화하는 과정을 1 step 진행하는 것을 번갈아 가며 수행합니다. 이 방법은 G가 충분히 천천히 변하는 한 D가 최적의 solution에 근접한 상태를 유지하게 됩니다. 이 전략은 학습의 내부 loop에서 Markov chain의 손실을 피하기 위해 한 train step에서 다음 step으로 넘어갈 때마다 SML/PCD 학습이 Markov chain의 sample을 유지하는 방식과 유사합니다.

위 알고리즘을 보면 더 이해하기 쉽습니다.

실제로, 위 식은 G가 잘 학습될 수 있는 충분한 gradient를 제공하지 않습니다. 학습 초기엔 G는 좋지 않은 상태이며, D는 training data와 생성한 data에 명확한 차이가 있기 때문에 잘 구분합니다. 이 경우 log(1-D(G(z)))는 포화상태가 됩니다. log(1-D(G(z)))를 G가 minimize하도록 학습하는 대신에 logD(G(z))를 G가 maximize하도록 학습할 수 있습니다. 이를 통해 학습 초기에 훨씬 더 강한 gradient를 제공할 수 있습니다.
Theoretical Results
생성 model G는 z~p_z를 이용해 G(z)를 생성하는데, 이 때 생성한 sample들의 분포로서 확률 분포 p_g를 암시적으로 정의합니다. 그러므로 충분한 양의 학습 시간과 용량이 주어진다면, alogorithm 1이 p_data의 좋은 추정치로 수렴하기를 원합니다.
Global Optimality of p_g = P_data
먼저, 주어진 generator G에 optimal한 discriminator D에 대해 생각을 해보겠습니다.

G가 고정되어 있을 때, optimal discriminator는 위와 같습니다.

이 상황에서 training criterion V(G,D)를 maximize합니다. G는 고정된 상황이므로 z에 대한 적분이 아닌 x로 표현할 수 있게 됩니다. y = alog(y) + blog(1-y)를 maximize하는 y는 a/(a+b)입니다.
D의 train 목표는 x가 p_data(with y= 1)에서 온 것인지 p_g(with y = 0)에서 온 것인지 나타내는 조건부 확률 P(Y = y | x)을 추정하는 log likelihood를 maximize하는 것으로 볼 수 있습니다. 그래서 V(G, D)를 maximize하는 식을 G에 대한 criterion으로 다시 작성해 보면 아래와 같습니다.

이 상황에서 V(G, D)를 maximize할 때는 p_data(x) = p_g(x)일 때입니다. 이때 C(G)는 -log4라는 값을 갖게 됩니다. log(1/2) + log(1/2)이다 보니 -log4가 됩니다.
이번에는 p_data(x) = p_g(x)일 때만 maximize라는 것을 KL divergence를 이용해 확인해 보겠습니다.
V(D_G*, G)에 대한 criterion에 -log4를 더하고 빼보겠습니다.

여기서 expectation을 KL divergence로 표현해주고 log를 이용해 표현한다로 표현해주면

위와 같은 수식이 됩니다. 이를 이용해 C(G)를 정리하면
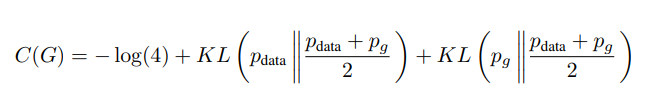
위와 같은 식으로 작성할 수 있습니다.

그리고 이 식은 위와 같이 data distribution과 generator sample distribution에 대한 Jensen-Shannon divergence로 표현할 수 있게 됩니다.
두 분포에 대한 Jensen-Shannon divergence은 항상 음의 값이 아니고, 두 분포가 같을 때만 0입니다. 즉 optimal criternion은 -log4이며, 이 값을 갖기 위해선 p_data(x)와 p_g(x)가 같아야만 합니다. 즉 generator G의 criterion은 해당 식을 minimize하도록 학습하게 되는데, optimal한 상황의 경우 p_data와 p_g가 같을 때이며 해당 경우는 -log4의 값을 갖게 됩니다. 다시 말해, generator criterion C(G)의 global minimum은 -log4이고, solution은 오직 p_g = p_data일 때입니다. 이는 generator G가 data 분포를 그대로 복제했을 때를 의미합니다.
Convergence of Algorithm 1

이번에는, G와 D가 충분한 용량을 가지고 있고 위 algorithm 1을 적용했다고 할 때, 주어진 G에 대해 discriminator D는 optimum을 찾을 수 있게 되고, p_g는 criterion을 maximize하기 위해 p_data로 수렴하게 된다는 것을 증명하겠습니다.
V(G, D)를 p_g에 대한 함수 U(p_g, D)로 가정하겠습니다. U(p_g, D)는 p_g에서 볼록한 함수라고 하겠습니다. 볼록함수의 최댓값의 부분도함수는 최대가 달성되는 지점에서 함수의 도함수를 포함합니다. U(p_g, D)는 p_g에 대한 함수이며 볼록함수이기 때문에, 어떠한 D를 input으로 받아도 똑같이 볼록하고 미분했을 때 U(p_g, D)를 미분했을 때 결과 중 하나입니다. 우리는 이 전에 global optimal은 1개(p_g = p_data)일 때라는 걸 알고 있으며, 저자들이 제안한 alogrithm을 통해 p_g를 update하면서 global optimal인 p_data를 찾을 수 있게 됩니다.
즉, 저자들이 제안한 algorithm을 통해 global optimal p_data를 잘 표현하는 p_g를 학습하여 찾을 수 있다는 것을 보였습니다.
Advantages and disadvantages
저자들이 제안한 방식은 G와 D가 동시에 잘 학습이 되어야지(G가 D보다 더 빠르게 잘 학습되거나, D가 G보다 더 빠르게 학습되는 상황이 있으면 안 되며, 'Helvetical scenario'라는 상황을 피해야 합니다. z가 동일한 x로 생성되어 p_data의 다양성을 표현하지 못하는 상황을 의미합니다) 좋은 성능을 보입니다. 하지만 backpropagation만을 이용해 gradient를 찾고 학습이 가능하다는 장점이 있습니다(inference가 필요하지 않다).



