https://arxiv.org/abs/2005.07143
ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification
Current speaker verification techniques rely on a neural network to extract speaker representations. The successful x-vector architecture is a Time Delay Neural Network (TDNN) that applies statistics pooling to project variable-length utterances into fixed
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
speaker verification technique은 speaker representation을 추출하기 위해 neural network를 사용합니다. 성공적인 x-vector architecture는 Time Delay Neural Network(TDNN)을 사용합니다. TDNN은 가변 길이의 utterance를 고정된 길이의 speaker characterizing embedding으로 투영하기 위해 statistis pooling을 사용합니다. 이 논문에서 저자들은 face verification과 computer vision의 최근 trend를 바탕으로, architecture의 여러 가지 개선사항을 소개합니다.
첫째로, 초기 frame layer는 skip connection이 있는 1차원 Res2Net modules로 restructure됩니다. SE-ResNet과 유사하게, module에 Squeeze-and-Excitation block을 도입하여 채널 간의 상호 의존성을 명시적으로 모델링합니다. SE block은 recording의 global properties에 따라 channel을 rescale함으로써 frame layer의 temporal context를 확장합니다.
둘째로, neural network가 각 layer를 다른 complexity level에서 동작하도록하여 계층적 feature를 학습한고 알려져 있습니다. 이 상호보완적 정보를 활용하기 위해, 다양한 계층적 level의 feature를 aggregate하고 propagate합니다.
마지막으로, 저자들은 channel dependent frame attention을 사용하여 statistics pooling을 개선합니다. 이는 network가 각 channel의 통계 추정 중에 frame들의 다양한 subset에 focusing하도록 만듭니다.
저자들이 제안하는 ECAPA-TDNN architecture는 TDNN 기반 system보다 VoxCeleb test set과 2019 VoxCeleb Speaker Recognition Challenge에서 좋은 성능을 보입니다.
Introduction
x-vector를 활용한 연구들이 speaker verification task에서 매우 좋은 성능을 보였으며, Time Delay Neural Network 연구들도 계속되고 있습니다. 주로 neural network가 speaker identification task에 학습됩니다. 수렴 후에, output layer 앞의 bottleneck layer로부터 input recording의 speaker를 characterize하는 저차원 speaker embedding을 추출할 수 있습니다. speaker verification은 enrollment recording과 test recording에 해당하는 두 embedding을 비교하여 accpet할 지 reject할 지 판단하여 수행됩니다. cosine distance 측정을 통해 비교할 수 있습니다. 또한, PLDA와 같은 더 복잡한 scoring backend를 학습하여 사용할 수도 있습니다.
x-vector와 관련된 연구들이 자주 등장하면서, 원래 approach에 비해 상당한 구조적 개선과 최적화된 train procedure가 등장했습니다. system의 topology는 ResNet architecture를 이용해 향상되었습니다. frame level layer 사이에 residual connection을 추가하여 embedding 능력을 향상시켰습니다. 추가적으로, residual connection은 backpropagation이 가능하며 이를 통해 수렴을 더 빠르게 하고 gradient vanishing 문제를 해결하는 데 도움을 줍니다.
x-vector system에서 statistics pooling layer는 시간에 걸쳐 hidden node activation의 간단한 통계를 수집하여 가변 길이의 input을 고정된 길이의 representation으로 project합니다. 이후 연구에서, pooling layer에 temporal self-attention system을 추가하여, 중요한 frame에만 focusing하도록 만들기도 했습니다. 이는 관련 없는 non-speech frame을 감지합니다.
이 논문에서 저자들은 TDNN architecture와 statistics pooling layer에 구조적 개선을 보입니다. 저자들은 system 전반에 걸쳐 channel을 propagate하고 aggregate하기 위해 skip connection을 추가합니다. global context를 사용하는 channel attention은 frame layer와 statistics pooling layer에서 통합되어 결과를 더욱 개선합니다.
DNN speaker recognition systems
Extended-TDNN x-vector
original x-vector system을 개선한 Extended-TDNN x-vector입니다. 첫 frame layer는 dense layer와 번갈아서 등장하는 1차원 dilated convolutional layer로 이루어집니다. 모든 filter는 이전 layer 또는 input layer의 모든 feature를 다룰 수 있습니다. dilated convolution layer의 task는 temporal context를 점점 넓히는 것입니다. residual connection은 모든 frame level layer에 존재합니다. frame layer 뒤에는 final frame-level feature의 평균과 표준편차를 계산하는 attentive statistics pooling layer가 존재합니다. attentive system은 model이 관련성 있다고 생각하는 frame을 고릅니다. statistics pooling 후에, 2개의 fully connected layer가 있습니다. 첫 번째 fully connected layer는 저차원 speaker characterizing embedding을 생성하는 bottleneck layer로 사용됩니다.
ResNet-based r-vector
ResNet18과 ResNet34를 기반인 r-vector입니다. 이 network의 convolutional frame layer는 pooling layer에서 평균과 표준편차를 모으기 전에, feature를 2차원 signal로 처리합니다.
Proposed ECAPA-TDNN architecture
x-vector architecture의 몇 가지 한계가 있으며, 이를 ECAPA-TDNN으로 해결합니다.
Channel- and context-dependent statistics pooling
최근 x-vector 구조에서, soft self-attention은 temporal pooling layer에서 weighted statistics을 계산하는 데 사용됩니다. 특정 speaker 속성은 다른 frame으로부터 추출될 수 있음을 multi-headed attetion으로부터 알 수 있습니다. 그래서 저자들은 temporal attention mechanism을 channel dimension까지 확장하여 benefit을 얻습니다. 이를 통해 network가 동일하거나 유사한 시간 instance에서 활성화되지 않는 speaker characteristic에 더 focusing할 수 있습니다. 예를 들어 모음에 대한 speaker specific 속성과 자음에 대한 speaker specific 속성 등에 더 focusing할 수 있게 합니다.
저자들은 attention mechanism을 구현하고 이를 channel-dependent으로 조정합니다.

위 식에서 h_t는 time step t에서 last frame layer의 activation을 의미합니다. parameter W ∈ R^(RxC)와 b ∈ R^(Rx1)는 information을 self-attention에 대한 smaller R-dimensional representation으로 투영합니다. 이는 overfitting에 대한 위험을 줄이고 parameter 수를 줄이기 위해 모든 C channel에 걸쳐 공유됩니다. f()는 ReLU를 의미하고, ReLU를 거친 후 information은 v_c라는 weight와 bias k_c로 이루어진 linear layer을 통해 channel-dependent self attention score가 됩니다. 이 scalar score e_t,c는 시간에 걸쳐 channel별로 softmax를 적용하여 모든 frame에 대해 정규화합니다.

self-attention score α_t,c는 channel로부터 얻어진 각 frame의 중요도를 나타내며 channel c의 weighted statistic을 계산하는 데 사용됩니다. 각 utterance에 대한 weighted mean vector의 구성요소인 μ_c는 다음과 같이 추정됩니다.

weighted 표준편차 vector σ의 구성요소인 σ_c는 다음과 같이 구성됩니다.

pooling layer의 마지막 output은 weighted mean과 weighted 표준편차들의 vector를 concat하여 주어집니다.
추가적으로, 저자들은 pooling layer의 temporal context를 확장하기 위해, utterance의 global properties를 고려할 수 있도록 self-attention을 적용합니다. 저자들은 local input h_t에 time domain 전체에 걸친 h_t의 global non-weighted mean과 표준편차를 concat합니다. 이러한 context vector가 attention mechanism이 noise나 recording condition과 같은 utterance의 global property에 적응할 수 있도록 만듭니다.
1-Dimensional Squeeze-Excitation Res2Blocks
original x-vector system에서 frame layer의 temporal context는 15 frame으로 제한됩니다. network는 더 넓은 temporal context로부터 benefit을 얻기 때문에, 저자들은 frame-level feature를 recording의 global 속성으로 rescale합니다. 이를 하기 위해서 저자들은 1차원 squeeze-excitation(SE) block을 사용합니다.
SE-block의 첫 번째 구성요소는 각 채널에 대한 descriptor를 생성하는 squeeze 연산입니다. squeeze 연산은 단순히 time domain에 걸쳐 frame-level feature의 mean vector z를 계산하는 것을 의미합니다.

z의 descriptor는 각 channel의 weight를 게산하는 excitation 연산에 사용됩니다. excitation 연산은 아래와 같습니다.
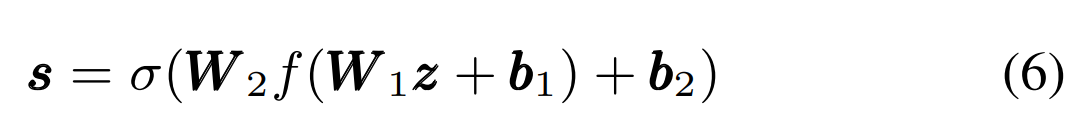
여기서 σ은 sigmoid function을 의미하고, f()는 ReLU이고 W_1∈R^(RxC), W_2∈R^(CxR)입니다. 이 연산은 C와 R로 이루어진 bottleneck layer로써 동작합니다. 여기서 C는 input channel 수를 의미하고 R은 감소될 차원을 의미합니다. 결과 vector s는 0에서 1 사이의 값인 weight s_c를 포함하고 있습니다. 이는 original input에 channel-wise 곱셈으로 적용됩니다. 식으로 표현하면 아래와 같습니다.

1차원 SE-block은 다양항 방식으로 x-vector에 통합될 수 있으며, 각 dilated convolution 뒤에 사용하는 것이 가장 직관적인 방식입니다. 그러나, 저자들은 이를 residual connection의 이점과 결합하길 원합니다. 동시에, 저자들은 baseline system에 비해 parameter수가 많이 늘어나는 것을 막으려 합니다.

위는 이전에 말했던 내용을 통합한 구조입니다. 저자들은 1 frame의 context를 다루는 dense layer의 전과 후에 dilated convolution을 두었습니다. 첫 dense layer는 feature dimension을 줄이는 데 사용될 수 있고, 두 번째 dense layer는 original dimension으로 차원을 복원하는 데 사용될 수 있습니다. 이어서 SE-block이 각 channel을 조정합니다. 그리고 skip connection이 연결됩니다.
최근 Res2Net module에서는 central convolutional layer를 개선하여, multi-scale feature를 처리할 수 있도록 내부에 계층적 residual connection을 구성합니다. 이 module의 통합은 성능을 향상시키면서 model parameter 수는 줄일 수 있었습니다. 그래서 저자들도 이러한 이점을 사용하여 위와 같이 model을 구현했습니다.
Multi-layer feature aggregation and summation

original x-vector system은 pooled statistic을 계산하기 위해 마지막 frame layer의 feature map만 사용합니다. TDNN의 계층적 특성을 고려했을 때, 깊은 level feature는 가장 복잡한 것들 중 하나이며, speaker identity와 매우 밀접하게 연관되어 있어야 합니다. 하지만 몇몇 연구들은 더 얕은 feature map도 더 robust한 speaker embedding에 기여할 수 있다고 주장합니다. 각 frame에서 저자들이 제안한 system은 모든 SE-Res2Block의 output feature map을 concat합니다. 이와 같은 Multi-layer Feature Aggregation(MFA) 이후에, dense layer가 연결된 information을 처리하여 attentive statistics pooling을 위한 feature를 생성합니다.
multi-layer information을 활용할 수 있는 또 다른 보완적인 방법은 각 frame layer block의 input으로 초기 convolutional layer와 모든 선행 SE-Res2Blocks의 output을 사용하는 것입니다. 저자들은 각 SE-Res2Block의 residual connection을 모든 이전 block의 output의 합으로 정의함으로써 이를 구현합니다. 저자들은 model parameter 수를 제한하기 위해 feature map concat대신 feature map 합을 이용합니다. 합산된 residual connection이 없는 최종 architecture는 위와 같습니다.
Experimental setup
Training the speaker embedding extractors
저자들은 VoxSRC 2019 training 제한 조건을 사용하고 VoxCeleb2 dataset에서 5994명 speaker만 training data로 골라 사용했습니다. data의 약 2%만 validation data로 사용했습니다. 저자들은 각 uttreance에 대해 6개의 extra sample을 생성해 사용했습니다.
25ms window with 10ms frame shift로부터 80차원 MFCC를 얻어내어 input feature로 사용했습니다. MFCC feature vector에서 2초 random crop한 것은 cepstral 평균을 빼서 정규화했으며, voice activity detection은 사용하지 않았습니다. 마지막 augmentation step에서, 저자들은 SpecAugment를 sample의 log mel spectrogram에 적용했습니다. algorithm은 time domain에서 0에서 5 frame, frequency domain에서 0에서 10 channel을 random하게 masking합니다.
모든 model은 1e-08에서 1e-03 사이에서 변화하는 cyclical learning rate를 사용하고 adam optimizer를 사용해 train됩니다. 하나의 cycle은 130k iteration동안 지속됩니다. 모든 sytem은 AAM-softmax를 사용하여 학습됩니다. AAM-softmax는 4 cycle동안 margin 0.2와 softmax prescaling 30으로 사용됩니다. overfitting을 막기 위해, 저자들은 모든 weight에 2e-05의 weight decay를 적용하고, AAM-softmax weight는 2e-04를 사용합니다. mini-batch size는 128입니다.
저자들은 convolutional frame layer에 512 또는 1024 channel의 ECAPA-TDNN architecture을 제안합니다. SE-Block에서 bottleneck 차원과 attention module의 차원은 128입니다. Res2Block에 있는 scale dimension s는 8로 설정합니다. 마지막 fully connected layer의 node 수는 192입니다.
Speaker verification
speaker embedding은 모든 system의 final fully connected layer에서 추출됩니다. trial score는 embedding 사이의 cosine distance를 사용하여 계산됩니다. 이후, 모든 score는 adaptive s-norm을 사용해 정규화됩니다. imposter cohort는 모든 training utterance의 길이 정규화된 embedding의 speaker 별 평균으로 구성됩니다. VoxCeleb test set에서는 imposter cohort 크기를 1000으로 설정했으며 cross dataset VoxSRC 2019 evaluation을 위해 50을 설정했습니다.
Results

baseline system과 ECAPA-TDNN의 성능은 위와 같습니다. parameter수도 위 표에 작성되어 있습니다. 저자들은 convolutional layer의 filter 수 C를 512와 1024로 두어 실험을 진행했습니다. 저자들의 architecture가 다른 model들에 비해 더 적은 parameter수로 가장 뛰어난 모습을 보입니다.

위 표는 ablation study입니다. 개별 구성 요소들을 제거하면서 성능을 확인해 본 결과입니다. A를 보면 channel에 대해 다른 temporal attetion을 적용하는 것의 이점을 확인할 수 있습니다. B를 보았을 때, Res2Block에 SE-module을 통합하는 것이 상당한 성능 향상을 야기한다는 걸 알 수 있습니다. C를 보면, 모든 SE-Res2Block의 information을 aggregate하여 사용하는 것이 성능 향상을 야기한다는 걸 알 수 있습니다.
Conclusion
저자들은 ECAPA-TDNN을 제안하며, 이는 speaker verification에 사용할 수 있는 TDNN 기반 speaker embedding extractor입니다. 저자들은 x-vector architecture를 기반으로 더 발전시키고, channel attention과 propagation 및 aggregation에 더 강조를 두었습니다. squeeze-excitation block, multi scale Res2Net feature, extra skip connections and channel dependent attentive statistics pooling의 통합은 VoxCeleb과 VoxSRC 2019 evaluation set에서 baseline system에 비해 많은 성능 향상을 이끌었습니다.



