https://arxiv.org/abs/1509.08062
End-to-End Text-Dependent Speaker Verification
In this paper we present a data-driven, integrated approach to speaker verification, which maps a test utterance and a few reference utterances directly to a single score for verification and jointly optimizes the system's components using the same evaluat
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문은 test utterance와 적은 수의 reference utterance를 직접 검증을 위한 단일 점수로 매핑하고, test 시간에 사용되는 동일한 평가 protocol 및 metric를 이용하여 system의 component를 공동으로 최적화하는 data 기반의 통합 접근 방식을 제시합니다. 이러한 접근법은 domain specific knowledge가 거의 필요하지 않고 model에 관한 추정도 거의 필요하지 않습니다. 그래서 간단하고 효과적인 system을 결과로 갖게 됩니다. 저자들의 idea는 1개의 neural network 구조로 문제를 해결하는 방식이며, model은 적은 수의 utterance만 가지고 speaker model을 추정할 수 있습니다. test dependent이므로 "OK Google" benchmark를 이용해 평가합니다.
Introduction
저자들은 text dependent speaker verification task에 맞는 system을 제시합니다. text dependent speaker verification은 phonetic variability(음성 변이)에 compensate를 부여하는 것을 목표로 합니다.
해당 논문에서 저자들은 speaker model을 build하기 위해 tset utterance와 few utterance를 verification하기 위한 single score로 직접 mapping하는 방식을 제안합니다. 모든 component는 standard speaker verification protocol을 따르는 verification based loss를 이용해 동시에 최적화됩니다.
end-to-end approach은 몇 가지 이점이 존재합니다. utterance로부터 직접 modeling하여 long range context를 capture할 수 있고 complexity를 줄일 수 있다는 장점이 그중 하나입니다. 그리고 직접적으로 동시에 estimation하기 때문에 더 compact한 model을 구현할 수 있습니다.
이 논문은 text dependent speaker verification을 소형 system으로 구현하는 데에 초점을 두고 있습니다. 소형 system의 경우, direct하게 deep learning modeling하는 것이 매우 효과적입니다. RNN을 이용한 speaker identification과 language identification이 등장했었습니다. 저자들이 제시한 network 구조는 generative-discriminative hybrid을 동시에 optimization된다고 생각할 수 있습니다.
Speaker Verification Protocol
standard verification protocol은 3단계로 나눠집니다. training, enrollment, evaluation입니다.
Training
train 단계에서는, utterance로부터 적절한 speaker 표현법을 찾아야 하며, 해당 표현법은 scoring function을 간단하게 해줍니다. speaker 표현은 model의 종류, representation level(ex, frame, utterance), model training loss(ex, MLE, softmax,...)에 따라 달라집니다. 최근 기술은 frame-level information을 i-vector나 d-vector로 표현하는 방식입니다.
Enrollment
enrollment 단계에서는, speaker가 적은 수의 utterance를 제공합니다. 이를 이용해 speaker model을 추정합니다. i-vector 또는 d-vector로 해당 utterance들의 평균을 구합니다.
Evaluation
evaluation 단계에선, verification task가 수행되고 system이 평가됩니다. verification을 위해, utterance X와 test speaker spk에 대한 scoring function은 S(X, spk)와 이미 정의된 threshold를 비교합니다. 해당 점수를 통해 speaker를 accpet할 지 reject 할지 정합니다.
이때, 2가지의 error가 발생할 수 있습니다. false reject과 false accept입니다. false reject rate와 false accept rate는 threshold에 영향을 받습니다. 두 rate가 동일하면, EER이라 불립니다.
간단한 scoring function 중 하나로 cosine similarity가 있습니다. 이는 evaluation utterance x에 대한 speaker representation f(x)와 speaker model m_spk 사이의 similiarity를 측정하는 방식입니다.

위와 같이 작성할 수 있습니다. PLDA라는 scoring도 있는데, 이는 더 refine하고 data 기반으로 점수를 얻는 방식입니다.
D-Vector Baseline Approach

D-vector는 DNN으로부터 얻어지는 값으로, utterance의 speaker representation입니다. DNN은 몇 개의 non-linear function을 연속으로 적용한 방식으로 구성되며, speaker utterance를 vector로 변환하기 위해 사용됩니다. 이를 통해 decision이 더 간단하게 진행됩니다.
DNN 구조는 위와 같습니다. locally connected layer 뒤에는 fully connected layer가 있습니다. 마지막을 제외한 모든 layer는 ReLU activation function이 있습니다. train 과정에, DNN의 parameter는 softmax loss를 이용해 학습됩니다.

식은 위와 같습니다. 여기서 y는 마지막 layer의 output을 의미하고, spk는 correct speaker를 의미합니다. normalize는 모든 competing train speaker spk^에 대해 이루어집니다.
train이 끝나면, DNN의 parameter는 fix됩니다. utterance d-vector는 하나의 utterance에서 얻어지는 모든 frame에 대한 last hidden layer output의 평균으로 얻어집니다. 각 utterance는 1개의 d-vector를 생성합니다.
enrollment를 위해, speaker model은 enrollment utterance에 대한 d-vector의 평균을 사용합니다. 마지막으로 evaluation 단계에서, scoring function은 speaker model d-vector와 test utterance의 d-vector 사이의 cosine similarity를 사용합니다.
이러한 방식은 frame 단위로부터 제한된 context의 d-vector를 얻는다는 문제가 있습니다. 그리고 loss에 대한 문제도 존재합니다. softmax loss는 true speaker와 모든 다른 speaker사이를 구분하도록 시도하지만, standard verification protocol을 따르지 않습니다. 결국 일관성이 없다는 문제를 해결하기 위해 scoring normalization과 같은 기술들이 필수요소가 되었습니다. 게다가 softmax loss는 speaker 수에 비례하여 연산량이 늘어나며 speaker specific weight와 bias를 추정하기 위해선 각 speaker마다 일정량 이상의 data가 필요하다는 문제가 존재합니다.
추가적인 문제로 connection이 부족한 component를 갖거나 직접적으로 speaker verification optimizing이 안되는 경우도 있습니다. 예를 들어 GMM-UBM 또는 i-vector model은 직접적으로 verification problem을 최적화하지 않습니다. PLDA model을 통해 verification하는데, 이는 i-vector extraction의 refinement를 따르지 않습니다. 그리고 frame based GMM-UBM model은 long contextual feature를 무시하기도 합니다.
End-to-End Speaker Verification

이제 저자들은 앞서 말했던 문제를 해결하기 위해 speaker verification problem을 단일 network architecture로 해결합니다. 위 그림과 같이 speaker representation을 계산하기 위해 train component를 사용하고, speaker model을 추정하기 위해 enrollment component를 사용하며, 최적화를 하기 위해 적절한 loss function을 가지는 evaluation component로 구성됩니다.
저자들은 utterance의 speaker representation을 얻기 위해 neural network를 사용합니다. 저자들은 2가지 종류의 network를 사용합니다. 먼저 locally conntected & fully connected layer로 이루어진 deep neural network(DNN)입니다. 그리고 single output을 갖는 long short-term memory recurrecnt neural network(LSTM)이 있습니다.
DNN은 고정된 길이의 input을 받습니다. 이러한 제약을 준수하기 위해, 저자들은 utterance에 충분히 큰 고정된 크기의 window의 frame을 쌓아 input으로 사용합니다. 이 trick은 LSTM에서는 필요없지만, 동일한 frame window를 사용하여 비교를 진행합니다.

기본적인 LSTM은 여러 개의 output을 갖지만, 저자들인 제시한 network은 위 그림과 같이, 오직 마지막 output만 loss에 적용하여 1개의 utterance level speaker representation을 갖습니다.
speaker model은 적은 수의 enrollment representation의 평균입니다. 저자들은 test utterance의 internal representation과 speaker model을 위한 utterance의 internal representation을 동일한 network에서 비교합니다. train에서 사용할 수 있는 각 speaker에 대한 utterance들의 실질적인 수(몇 백개 혹은 그 이상)는 enrollment utterance 수(10개 이하)에 비해 훨씬 많습니다. mismatch를 피하기 위해, 저자들은 train time에 speaker model을 build하기 위해, 동일한 speaker로부터 얻어지는 적은 수의 utterance를 train uttrerance로 사용합니다. 일반적으로, 각 speaker에 대해 N개의 utterance를 가지고 있다고 가정할 수 없습니다. 그래서 utterance 수의 변동성을 위해, 저자들은 utterance를 사용할지 여부를 나타내기 위해 utterance와 함께 weight를 pass합니다.
마지막으로, speaker representation과 speaker model의 cosine similarity S(X, spk)를 계산합니다. 그리고 bias가 있는 linear layer를 포함하는 logistic regression에 input으로 넣습니다. 이 arcitecture는 end-to-end loss 에 의해 최적화됩니다.

loss 식은 위와 같습니다. target은 {accept, reject} 둘 중 하나입니다. p(accept) = (1 + exp(-wS(X, spk) - b))^-1 이고 p(reject) = 1 - p(accept)입니다. -b/w는 verification threshold입니다.
end-to-end의 input은 1 + N 개의 utterance입니다. 1개의 test utterance와 speaker model을 추정하기 위한 N개의 동일한 speaker로부터 얻은 utterance입니다. data shuffling과 memory 사이의 좋은 tradeoff를 이루기 위해서, input layer는 각 train 단계에 대해 1+N개의 utterance를 sampling하기 위한 utterance pool을 유지하고 더 나은 data shuffling을 위해 자주 update해야 합니다. 같은 speaker로부터 얻어지는 일정 수의 utterance가 speaker model을 구할 때 필요하기 때문에, data는 동일한 speaker의 작은 수의 utterance group으로 제시됩니다.
end-to-end구조는 일관된 speaker model과 함께 standard evaluation protocol을 사용하여 evaluation metrix를 직접 최적화할 수 있습니다. 이는 heuristic 및 후처리 단계(ex, score normalization)없이 더 좋은 결과를 얻을 수 있게 됩니다. 게다가 이 접근법은 evaluation step에서 train speaker 수에 의존하지 않으며 한 명의 speaker당 최소 utterance 수를 요구하지 않습니다.
Experimental Evaluation
Data sets & Basic setup

저자들은 noise에 robustness를 향상시키기 위해, 여러 style의 noise를 추가하여 학습했다고 합니다. 인공적으로 다양한 noise을 추가하여 data augmentation했습니다. enrollment와 evaluation은 real data만 사용하여 진행했습니다. data는 위와 같이 준비되었습니다.
DNN method의 경우, 80개의 input frame을 concat했습니다. 그 결과로 80x40 차원의 feature vector가 됩니다. 모든 hidden layer는 504개의 node를 가지며, 마지막 layer를 제외한 layer들은 ReLU를 activation function으로 사용합니다. locally connected layer는 10x10 크기의 patch size를 사용합니다.
LSTM method의 경우, 각 frame마다 40차원읜 feature vector를 사용합니다. 504개의 node를 가진 projection layer가 없는 단일 LSTM layer을 사용합니다. batch size는 32로 두고 진행했습니다. 실험들의 결과인 EER은 t-norm score normalization을 적용하지 않았습니다.
Frame-level vs Utterance-level Representation
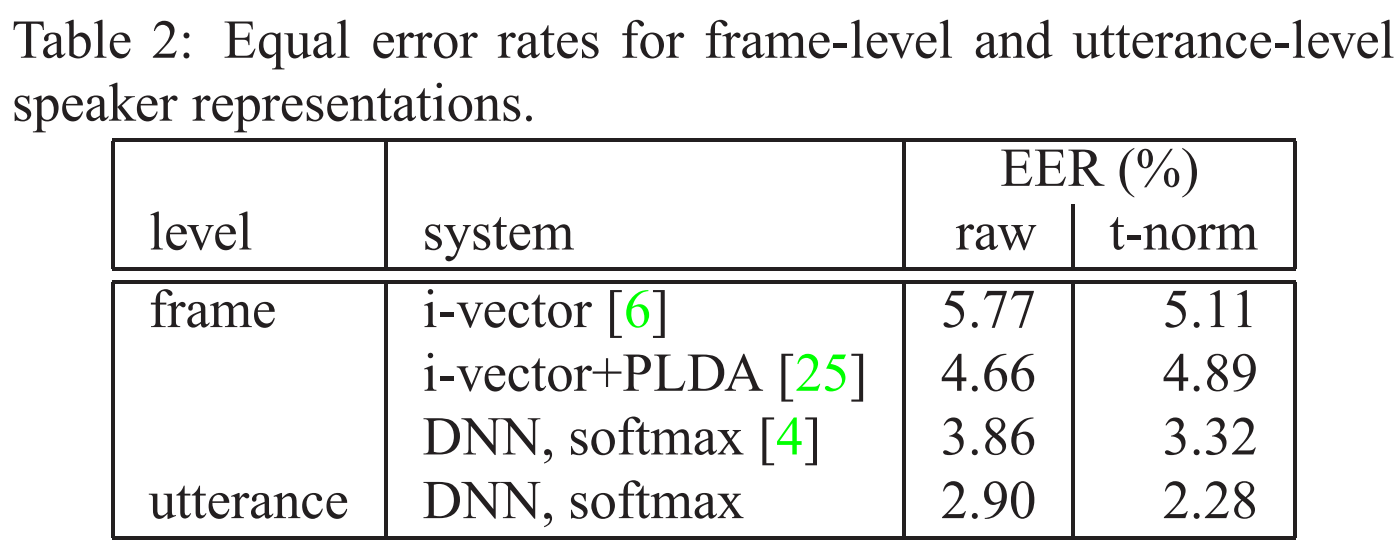
먼저 frame-level과 utterance-level speaker representation을 비교하겠습니다. 저자들은 마지막에 softmax layer가 있는 DNN을 사용했으며, train_2M data를 가지고 학습했으며 50% dropout을 linear layer에서 사용했습니다. utterance-level 접근법은 frame-level보다 30%가량 뛰어난 성능을 보입니다.
Softmax vs End-to-End Loss

이번엔 utterance level speaker representation을 사용하는 softmax loss와 end-to-end loss를 비교하겠습니다. DNN을 이용했을 때 얻을 수 있는 EER 수치는 위와 같습니다. small training set(train_2M)으로 학습할 경우, raw EER score은 비교가능합니다. dropout은 softmax에 1%의 이득을 준 반면, end-to-end loss에 dropout을 적용한 것이 도움이 되지 않는다는 것을 실험을 통해 알아냈다고 합니다. 비슷하게, t-normalization이 softmax의 경우 도움이 되지만, end-to-end loss에는 도움이 되지 않습니다. end-to-end 방식은 train과정에서 global threshold를 추정합니다. 그렇기 때문에 다른 noise condition에서도 변동성이 없는 normalized score을 암시적으로 학습합니다. end-to-end train을 위해 softmax DNN initialization을 사용하면, EER은 2.86%에서 2.25%로 감소합니다.
만약 더 큰 dataset(train_22M)을 이용하 학습한다면, end-to-end loss는 명확하게 softmax보다 좋습니다. t-normalization을 softmax에 사용하는 경우, 이득을 볼 수 있었으며 다른 loss만큼 성능이 좋아지는 것을 볼 수 있습니다. end-to-end training의 초기 설정(random vs pre-trained softmax DNN)이 큰 차이를 보여주지 못합니다.
end-to-end approach는 speaker model을 바로 계산하기 때문에 step time이 softmax 보다 더 크지만, 전체 time은 비슷합니다.

train에서 speaker model을 추정할 때 사용하는 최적의 utterance 수는 enrollment utterance의 수에 의존합니다. 그러나, 실제로는 더 작은 speaker model 크기는 training time을 줄이기에 더 매력적입니다. 그래서 model의 크기에 따른 결과는 위와 같습니다. speaker model을 추정하기 위해 사용되는 utterance 수와 같이, speaker model size에 따른 EER 결과입니다. 5개의 utterance를 사용했을 때 2.04라는 EER 수치를 보입니다. 이 수치는 저자들의 enrollment set으로 6개의 utterance를 사용하는 것과 유사한 model size입니다. 저자들이 제안한 방식이 일관성있고 특정 task에 맞는 training에 적합하다는 것을 보여줍니다.
Feedforward vs Recurrent Neural Network

이번에는 다른 network 구조에 대해 살펴보겠습니다. small footprint DNN과 비교하였을 때, best DNN은 추가적인 hidden layer를 사용하는 것이고 10% 정도의 성능 향상이 있었습니다. LSTM은 best DNN에 비해 30%의 성능 향상이 있었습니다. parameter수는 DNN과 LSTM이 비슷하지만, LSTM이 10배 이상 더 많은 연산량이 들었습니다. hyperparameter를 잘 수정한다면, 연산량 복잡도는 더 줄어들 수 있습니다. 최종 결과를 보았을 때, softmax보다 end-to-end가 더 좋은 결과를 보입니다.
Summary & Conclusion
저자들은 end-to-end approach를 제안합니다. 이는 speaker verification task에 사용됩니다. 저자들이 제안한 방식은 utterance를 score로 직접 mapping하며, train과 evaluation에 동일한 loss function을 사용하여 internal speaker representation과 speaker model을 동시에 최적화할 수 있습니다. 충분한 train data가 있다고 가정했을 때, 저자들의 방식은 성능을 향상시켰습니다. 대부분의 성능향상은 utterance-level과 frame-level modeling의 비교에서 왔습니다(저자들의 방식은 utterance level modeling을 사용하여 full context를 고려할 수 있었음).
다른 loss와 비교하여, end-to-end loss는 동일하거나 약간 더 좋은 결과를 보여주었으며 추가적인 concept이 덜 필요했습니다. 예를 들어 softmax의 경우, score normalization, candidate sampling, dropout을 사용해야 EER이 좋은 성능을 보였습니다.
그리고 저자들은 간단한 DNN대신 RNN을 사용하여 1.4%의 EER 성능 향상이 있었습니다. 하지만 더 많은 연산량이 들었습니다.



