https://arxiv.org/abs/1710.10467
Generalized End-to-End Loss for Speaker Verification
In this paper, we propose a new loss function called generalized end-to-end (GE2E) loss, which makes the training of speaker verification models more efficient than our previous tuple-based end-to-end (TE2E) loss function. Unlike TE2E, the GE2E loss functi
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 generalized end-to-end(GE2E) loss라는 새로운 loss function을 제안합니다. 이는 speaker verification model을 이전의 tuple-based end-to-end(TE2E)라는 loss function보다 더 효과적으로 학습하게 만듭니다. TE2E와 다르게, GE2E loss function은 train 과정에서 각 step에 검증하기 어려운 example을 강조하는 방식으로 network를 update합니다.
추가로, GE2E loss는 example을 고리는 initial stage가 필요하지 않습니다. 이러한 특성으로, 저자들이 제안한 loss를 사용한 model은 speaker verification EER을 10%보다 더 감소시키며, 학습 시간도 60%나 감소시킵니다. 저자들은 MultiReader 기술 또한 소개합니다. 이 기술은 multiple keyword(ex, "OK Goole" and "Hey Google" ... )를 support하는 model을 더 정확하게 학습할 수 있도록 domain adaptation하는 기술입니다.
Introduction
Background
저자들은 text independent speaker verification(TI-SV)와 global password TD-SV라고 알려진 TD-SV의 subtask에 focusing합니다. 이는 감지된 특정 keyword를 기반으로 verification하는 방식입니다(예를 들어 "OK Google"과 같은 keyword를 탐지하여 verification을 진행).
이전의 연구들에서, i-vector 기반 system들이 TD-SV(Text dependent speaker verification)와 TI-SV application에 주를 이뤘습니다. 그 이후엔 neural network를 이용한 end-to-end system들이 등장했습니다. 이러한 system들은 nerural network output vector가 주로 embedding vector로 불립니다(d-vector). 이러한 embedding vector는 utterance를 고정된 저차원 vector로 표현하여 더 다루기 간단한 형태가 되며, 해당 저차원 space에서 여러 기술들을 적용해 speaker verification을 진행했었습니다.
Tuple-Based End-to-End Loss
저자들의 이전 연구에서, tuple-based end-to-end(TE2E) model을 제안했습니다. 해당 model은 train이 enrollment와 verification 이라는 두 가지 과정으로 이루어졌습니다. LSTM을 적용한 TE2E model이 가장 좋은 성능을 당시에 보였습니다.
해당 model은 각 train step에서, 하나의 evaluation utterance x_j와 M개의 enrollment utterances x_km(m = 1, ... , M)의 tuple 쌍이 LSTM network의 input으로 들어갑니다. {x_j, (x_k1, ... , x_kM)}의 형태로 LSTM network의 input이 들어갑니다. 여기서 x는 고정된 길이의 segment로부터 얻은 feature(log-mel-filterbank energies)를 나타냅니다. j와 k는 utterance의 speaker를 나타내고, j와 k는 일치할 수도 있고 아닐 수도 있습니다. tuple은 speaker j로부터 1개의 utterance, speaker k로부터 M개의 utterance를 포함하고 있습니다. 만약 x_j와 M개의 enrollment utterance가 동일한 speaker에서 왔다면 positive tuple이라고 부르며 아닐 경우 negative tuple이라 부릅니다. 저자들인 positive tuple과 negative tuple을 번갈아가며 생성합니다.
각 input tuple에서, LSTM의 L2 normalize된 output {e_j, (e_k1, ... , e_kM)}을 계산합니다. 각 e는 고정된 차원의 embedding vector입니다. 이 vector는 LSTM에 의해 sequence에서 vector로 mapping되는 결과입니다. (e_k1, ... , e_kM)의 centroid은 M개의 utterance로부터 만들어진 voiceprint이며 이는 아래의 c_k입니다.

유사도는 cosine similarity function을 이용하여 계산됩니다.

위와 같은 식으로 similarity가 구해집니다. 여기서 w와 b는 학습되는 값입니다(linear regression).

위 식에서 σ(s)는 sigmoid function입니다. δ(j, k)의 경우, j = k일 때 1이고 아닌 경우 0입니다. TE2E loss function은 k = j일 때 s의 값이 커지도록 유도합니다. 그리고 k와 j가 다를 때, s의 값은 작아지길 유도합니다.
Generaized End-to-End Model
Generalized end-to-end(GE2E) training은 한 번에 많은 utterance를 처리하는 것을 기반으로 합니다. 이는 평균적으로 각 speaker 당 M 개의 utterance를 포함하고 N명의 speaker가 있는 batch 형태입니다.

Training Method
저자들은 이 전에 말했던 것과 같이 N x M utterance를 가지고 batch를 만듭니다. 이 utterances는 N명의 다른 speaker로부터 오고, 각 speaker는 M개의 utterances를 갖습니다. 각 feature vector x_ji(i <= j <= N and 1 <= i <= M)는 speaker j의 utterance i로부터 추출된 feature를 의미합니다.
각 utterance x_ji로부터 추출되는 feature를 LSTM network의 input으로 넣어줍니다. linear layer는 LSTM의 마지막 layer로 연결됩니다. 전체 neural network의 output은 f(x_ji ; w) 형태로 표현가능합니다. 여기서 w는 neural network의 모든 parameter를 의미합니다(LSTM layer와 linear layer의 parameter입니다). embedding vector(d-vector)는 network의 output에 L2 normalization한 값으로 정의됩니다.

여기서 e_ji는 j번째 speaker의 i번째 utterance의 embedding vector입니다. 이 전에 봤던 것처럼 j번째 speaker로부터 얻어지는 embedding vector의 centroid은 c_j입니다. 이 c_j는 위에서 봤던 식으로 구할 수 있습니다.
similarity matrix S_ji,k는 각 embedding vector e_ji와 모든 centroids c_k(1 <= j, k <= N and 1 <= i <= M) 사이의 scale된 cosine similarity로부터 정의됩니다.

여기서 w와 b는 학습 가능한 parameter입니다. w는 양수로 제한을 두었는데, 저자들은 cosine similarity가 클수록 similarity가 커지길 원해 이와 같이 제한을 두었습니다. TE2E와 GE2E의 주된 차이는 다음과 같습니다.
- TE2E의 similarity는 embedding vector e_j아 single tuple cetroid c_k사이의 similarity로부터 정의된 scalar value입니다.
- GE2E는 similarity matrix를 만드는데, 이 matrix는 e_ji와 모든 cetroids c_k사이의 similarity를 나타냅니다.
train하는 과정에, 저자들은 각 utterance의 embdding이 동일 speaker의 embedding의 centroid와 유사하길 원하지만, 동시에 다른 speaker의 centroid와는 멀어지길 바랍니다. 위 그림에서 보이는 similarity matrix를 보았을 때, 색이 칠해진 부분의 값들은 커지길 원하고 회색 부분들은 값이 작아지길 원합니다.

위 그림으로 다시 설명을 하겠습니다. blue embedding vector는 해당 speaker의 centroid인 c_j와 가까워지길 원하며, 다른 speaker의 centroid와는 멀어지길 원합니다. 그중 특히 red centroid c_k와는 멀어지길 원합니다(가까운 거리에 있는 speaker의 centroid).
embedding vector e_ji와 all centriods c_k, similarity matrix S_ji, k가 주어졌을 때, 2가지 방법이 존재합니다.
- Softmax

위와 같이 softmax를 적용하는 방식이 있습니다. softmax를 적용하여, S_ji,k는 k와 j가 같을 때 1이 되도록 하고 k와 j가 다를 때 0이 되도록 합니다. 이 loss function은 각 embedding vector가 각 centroid에 가까워지도록 하면서 서로 다른 centroid와는 거리가 멀어지도록 합니다.
- Contrast

contrast loss는 positive pair와 most aggressive negative pair로 정의됩니다. 여기서 σ는 sigmoid function을 의미합니다. 모든 utterance에 대해, 정확이 2개의 component가 loss에 추가됩니다. 먼저 positive component입니다. 이는 embedding vector와 이에 맞는 true speaker centroid 사이의 positive match입니다. 두번째로 hard negative component입니다. 이는 embedding vector와 false speaker 중 가장 similarity가 높은 centroid 사이의 negative match입니다.
즉, 이 식을 통해 utterance가 해당 centroid와의 similarity를 높이고, 다른 speaker 중 가장 유사도가 높은 centroid와는 거리를 멀게 하도록 하는 효과가 있습니다.
저자들은 실험을 통해 Text dependent speaker verification에서는 contrast loss가 더 좋은 성능을 보이며, Text independent speaker verification에서는 softmax가 약간 더 좋은 성능을 보인다는 것을 알아냈습니다.
그리고, 저자들은 true speaker에 대한 centroid를 계산할 때 e_ji를 제거하는 것이 학습을 더 안정적으로 할 수 있도록 만들고, 단순한 solution을 찾는 것을 피하도록 도와준다고 합니다.
따라서, negative similarity(j != k)를 계산할 때는

위 식을 그대로 사용하면 되지만
k = j일 때는 아래의 식을 대신 사용하면 됩니다.

최종 GE2E loss L_G를 구해보겠습니다.

최종 similarity matrix(1 <= j <= N, and 1 <= i M)는 위와 같이 구할 수 있습니다. matrix를 이용한 L_G는 아래와 같습니다.

comparison between TE2E and GE2E
GE2E loss를 single batch에 대해 update하는 경우를 생각해 보겠습니다. 총 N 명의 speaker가 있고 각 speaker는 M개의 utterance가 있습니다. 각 single step update는 모든 N x M embedding vector를 그들의 centroid로 가깝게 만들 것이고 다른 centroid에는 멀게 만들 것입니다.
이는 TE2E loss function에서 각 x_ji에 대해 가능한 모든 tuple에 일어나는 것과 동일합니다. j라는 speaker로부터 P개의 utterance를 random하게 골랐다고 가정하겠습니다.
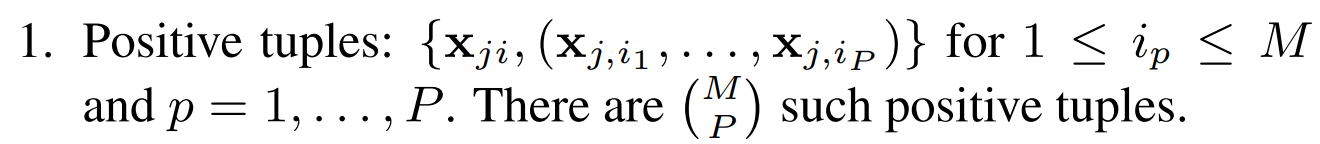
positive tuple은 위와 같습니다.
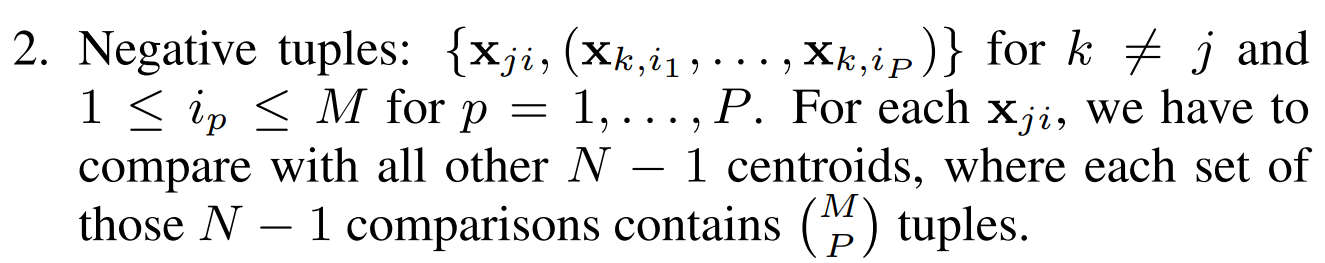
negative tuple은 위와 같습니다. k와 j가 다른 경우입니다. 각 positive tuple은 negative tuple과 균형을 이루므로, 총 tuple 수는 positive tuple과 negative tuple 중 더 큰 수의 2배를 곱한 만큼이 됩니다. 그래서 최종 TE2E loss에 사용되는 tuple 수는 다음과 같습니다.

2(N-1)가 되는 경우는, P와 M의 수가 같을 때입니다. GE2E loss를 각 x_ji에 대해 update하는 것은 적어도 TE2E loss에서 2(N-1)개의 tuple 계산하는 것과 동일합니다. 즉 GE2E를 사용하는 것이 TE2E보다 더 빠르게 학습가능하다는 것을 의미합니다.
Training with MultiReader
적은 수의 dataset D1으로 이루어진 domain에서 model을 구현하는 상황이라고 생각하겠습니다. 동시에, 동일하진 않지만 비슷한 domain의 대규모 dataset D2가 있다고 하겠습니다. 이 상황에서 D2의 도움을 받아 D1에서 잘 동작하는 single model을 학습하는 것이 목표인 상황입니다.

이는 regularization technique과 유사합니다. 현재 상황에선 E[L(x;w)], x ∈ D2를 regularization합니다. D1이 충분한 data가 없기 때문에 D1만 사용하여 학습하면 overfitting이 일어날 수 있습니다. D2에서도 잘 동작하도록 만드는 것은, network를 정규화하는 데 도움을 줍니다.
이를 이용해 K개의 균형이 안맞는 dataset D_1, ... , D_K를 이용해 model을 generalize할 수 있습니다. 각 dataset에 weight α_k를 할당하여 각 dataset의 중요도를 부여할 수 있습니다. 학습 과정에 각 step은 각 dataset으로부터의 하나의 utterance batch/tuple을 가져오고, 이를 통합하여 하나의 loss로 표현할 수 있습니다.
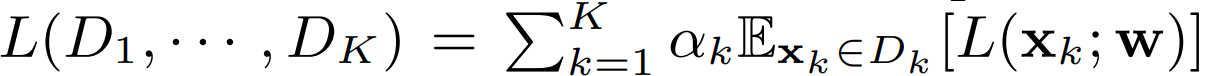
위 식과 같이 K개의 서로 다른 dataset을 통합하여 model을 학습할 수 있습니다. 여기서 L은 이 전에 살펴본 GE2E loss와 동일합니다.
Experiments
audio signal은 25ms 길이의 frame으로 변환됩니다. 그러고 40차원의 log mel-filterbank energies를 각 frame마다 feature로써 추출합니다. TD-SV에서, 동일한 feature가 keyword detection과 speaker verification에서 사용됩니다. keyword detection system은 keywrod를 담고 있는 frame만 speaker verification system에 통과시킵니다. TI-SV에서는, VAD 후에 임의의 고정된 길이의 segment를 추출하고, inference를 위해 slinding window approach를 사용합니다.
저자들은 projection을 가진 3개의 LSTM layer를 사용합니다. embedding vector(d-vector) size는 LSTM projection size와 동일합니다. TD-SV의 경우, 128개 hidden nodes와 64 크기의 projection size를 사용합니다. TI-SV의 경우, 768개 hidden nodes와 256크기의 projection size를 사용합니다.
GE2E model을 학습할 때, 각 batch는 64명의 speaker를 포함하며, 각 speaker는 10개의 utterance를 가집니다. SGD with learning rate 0.01을 이용해 network를 학습하며, learning rate는 매번 30M step마다 절반으로 줄어듭니다. loss function에 있는 scaling factor (w, b)을 보면, 초기에 (w, b) = (10, -5)로 설정했으며 gradient scale 0.01을 적용하는 것이 수렴을 부드럽게 하는 데 도움을 주었다고 합니다.
Text-Dependent Speaker Verification
기존의 voice assistant는 single keyword만 지원을 했지만, 사용자들은 multiple keyword를 선호합니다. multiple keyword speaker verification은 TD-SV와 TI-SV 사이에 위치합니다. keyword이 단일 문구로 제한되지 않지만, 완전히 제약이 없는 것은 또 아니기 때문입니다. 그래서 저자들은 이러한 multiple keyword speaker verification을 해결하기 위해 MultiReader technique을 사용합니다.
MultiReader는 서로 크기 balance가 맞지 않은 다른 data source를 다루는 데 사용될 수 있습니다. 그래서 저자들은 2개의 data source를 train할 때 사용할 때 MultiReader를 사용합니다.
"OK Google"이라는 630K명의 speaker와 150M개의 utterance로 구성된 training set과 "OK/Hey Google"이라는 18K명의 speaker와 1.2M개의 utterance로 구서오딘 training set을 사용합니다. 첫번째 dataset이 훨씬 size가 큰 상태입니다.
저자들은 2개의 data source를 활용하여 4가지 경우에 대한 evaluation을 진행합니다. 수치는 Equal Error Rate(EER)을 통해 확인합니다. evaluation dataset은 665명의 speaker가 평균적으로 speaker 당 enrollment utterance가 4.5개를 가지고 있고 speaker 당 10개의 evaluation utterance를 가지고 있는 상태입니다.

위 표를 보면 결과를 볼 수 있습니다. MultiReader 방식이 Mixed data에 비해 EER 수치가 낮은 것을 볼 수 있습니다.

또한, 저자들은 83K명의 speaker와 다양한 환경 조건에서 수집된 더 많은 dataset을 얻은 포괄적인 evaluation을 진행해 봤습니다. 각 speaker마다 평균 7.3개의 enrollment utterance와 5개의 evaluation utterance를 가지고 있습니다.
위 표는 다른 loss function, MultiReader의 사용여부에 따른 결과를 보여줍니다. baseline model은 single layer LSTM with 512 node and emedding vector size of 128입니다. 그 아래에 model은 3개 LSTM layer를 갖는 경우를 의미합니다. 결과를 보면 GE2E가 TE2E보다 더 나은 결과를 보이는 것을 알 수 있습니다. 그리고 MultiReader를 사용하는 것이 더 좋은 결과를 보인다는 것을 알 수 있습니다. 그리고 GE2E가 TE2E보다 60% 더 적은 훈련시간이 걸렸다는 것도 주목할 만한 결과입니다.
Text-Independent Speaker Verification
TI-SV training을 위해, 저자들은 training utterance를 더 작은 segment로 나눕니다. 모든 부분 utterance가 같은 length일 필요는 없지만, 같은 batch에 존재하는 partial utterance는 같은 length여야 합니다. 그래서 각 batch에 대해, 140~180 frame 내에서 무작위로 time length t를 선택하고, 그 batch에 존재하는 partial utterance는 t길이가 되도록 만들었습니다.

위 그림과 같이 한 batch에 존재하는 partial utterance의 길이는 동일하게 만들었습니다.

inference time동안, 모든 utterance에 고정된 크기의 160frame 50% overlap sliding window를 사용했습니다. 각 window마다 d-vector를 계산했습니다. utterance마다 마지막 d-vector는 window마다 d-vector를 L2 normalization하고 평균을 취해 구해집니다. 위 그림과 같은 형태입니다.
저자들의 TI-SV model은 18K명의 speaker로부터 얻어진 36M개 utterance로 학습됩니다. evaluation을 위해, 저자들은 1000명의 추가적인 speaker를 사용합니다. 각 speaker는 평균 6.3개의 enrollment utterance와 7.2개의 evaluation utterance를 가지고 있습니다.

evaluation 결과는 위와 같습니다. loss function마다의 결과를 보여줍니다. GE2E가 가장 좋은 성능을 보인다는 것을 알 수 있습니다. 또한, GE2E가 다른 loss보다 더 빠르게 학습된다는 것도 알 수 있었다고 합니다.
Conclusion
저자들은 speaker verification model을 더 효율적으로 학습할 수 있는 generalized end-to-end(GE2E) loss function을 소개합니다. 또한 다른 data source를 결합하는 기술 중 하나인 MultiReader를 소개합니다. 이를 통해 multiple keyword 또는 multiple language를 지원하는 model을 구현할 수 있습니다.



