https://www.isca-archive.org/interspeech_2017/snyder17_interspeech.pdf
해당 논문을 보고 작성했습니다.
Abstract
저자들은 text-independent speaker verification에서 사용할 수 있는 feed forward deep neural network에서 추출된 embedding을 i-vector의 대체자로 제안합니다. long-term speaker characteristic은 network에 존재하는 시간 pooling layer에 의해 capture된다고 합니다. 해당 pooling layer는 input speech을 aggregate합니다. 이를 통해 network가 가변길이의 speech 부분에서도 speaker를 구분할 수 있도록 학습될 수 있습니다. 학습 이후에, 발화는 고정된 차원의 speaker embedding으로 직접 mapping되며, embedding 쌍은 PLDA based backend에 의해 점수화됩니다.
저자들의 방식은 short speech에서는 i-vector보다 뛰어나며, long duration test에서는 경쟁력이 충분히 있다고 합니다. 저자들이 제안한 방식이 공개적으로 사용 가능한 corpus에서 train되고 test된 speaker discriminative neural network에서 가장 좋은 성능을 보인다고 합니다.
Introduction
Speaker verification(SV)는 speech signal과 등록된 speaker record를 기반으로 speaker의 identitiy를 인증하는 task입니다. 일반적으로, speaker information가 풍부한 저차원 표현은 enrollment speech와 test speech에서 추출되고, 이를 비교하여 동일한 speaker인지 다른 speaker인지 결정합니다. 이 논문은 text independent SV에 사용할 수 있는 i-vector를 대체하는 embeddings을 제안합니다. 이 embedding은 DNN을 이용해 생성됩니다. verification은 온라인 응용 프로그램에서의 지연을 피하거나 제한된 가용성 때문에 제한된 양의 test speech를 이용해 평가되어야 합니다. 저자들은 enrollment 발화를 full length로 사용하지만, test 발화는 음성의 처음 몇 초로 축소된 버전을 구성합니다.
Speaker verification with i-vectors
대부분의 text-independent SV system은 i-vector 기반입니다. UBM을 이용하고, i-vector를 추출하는 large projection matrix를 구하고, probabilistic linear distriminant analysis(PLDA)를 뒤에 붙여 i-vector 사이의 유사도를 계산합니다.
UBM은 acoustic feature로 학습된 gaussian mixture model(GMM)입니다. 최근 연구에서는, ASR DNN acoustic model을 통합하여 UBM의 음성 내용 modeling 성능을 향상시켰습니다. 그러나, 연산량이 너무 많이 증가하게 됩니다. 그리고 ASR DNN을 i-vector pipeline에 사용하였을 때 얻을 수 있는 장점은 영어에만 국한되었으며 multi language에서는 장점을 찾을 수 없었습니다. 이러한 이유때문에, GMM을 사용하는 전통적인 i-vector system에서 연구를 진행했습니다.
Speaker verification with DNNs
speaker를 바로 분리할 수 있는 SV system들도 연구되고 있습니다. speaker 구별 task에 대해 학습된 DNN을 사용하는 연구들도 등장했습니다. 초기 연구에서는 neural network가 training speaker를 분류하도록 학습되었거나, 동일 화자와 다른 화자 쌍을 분리하도록 학습되었습니다. 학습 이후에, frame level feature는 network에서 추출되어 gaussian speaker model의 input으로 사용됩니다. 그러나, 이러한 방식들은 text independent SV에서 현대에 등장한 i-vector system에 비해 경쟁력이 있다는 연구는 존재하지 않았습니다.
발전은 주로 대규모 dataset을 가진 text dependent system에 집중되었습니다. d-vector도 이 중 하나입니다. 최근 한 연구에서는 embedding과 similarity metric을 동시에 학습하는 end-to-end system도 등장했습니다. 이는 text-independent SV에서 i-vector보다 뛰어난 모습을 보였습니다. 하지만 이러한 방식은 효과적이기 위해 많은 수의 domain 내 train speaker가 필요했습니다. 그래서 저자들은 end-to-end method를 이용하지만 공개된 작은 양의 dataset을 이용해 성능을 향상시킬 수 있는 연구를 진행했습니다.
저자들은 end-to-end approach를 2개의 part로 나눴습니다. embedding을 생성하는 DNN과 embedding 쌍을 비교하는 backend로 분리했습니다. 최종적으로, 동일 speaker 쌍과 다른 speaker 쌍을 분리하는 system을 구현하지 않고, training speaker 자체를 구분하는 DNN을 구현했습니다.
Baseline i-vector system
baseline으로 전통적인 i-vector system을 사용했습니다. front-end feature는 frame length 25ms에서 20 MFCC로 구성됩니다. 최대 3초의 sliding window를 통해 평균 normalization됩니다. UBM은 2048개의 구성요소의 full covariance GMM입니다. 600차원의 i-vector extractor를 사용합니다. PLDA scoring전에, i-vector는 중심화되고, 차원은 LDA를 사용해 150으로 줄어듭니다. 그리고 길이는 정규화됩니다. PLDA score는 adaptive s-norm을 사용해 정규화됩니다.
DNN embedding system
Overview

system의 가변 길이의 aoucstic segment로부터 speaker embedding을 계산하는 feed-forward DNN은 위와 같은 형태입니다. 해당 구조는 end-to-end system을 제안한 논문에서 착안되었습니다. 하지만, end-to-end approach는 domain 내의 data 양이 많아야지 효과적입니다. 그래서 저자들은 end-to-end loss를 multiclass cross entropy로 대체했습니다. 그리고 별도로 학습된 PLDA backend는 embedding 쌍을 비교하는데 사용되었습니다. 이는 DNN과 similarity metric이 잠재적으로 다른 dataset에 대해 학습가능하게 만듭니다.
Features
feature는 25ms의 frame length에서 얻어지는 20차원의 MFCC입니다. 그리고 3초까지 늘어나는 sliding window를 이용해 평균 normalizing합니다. input에서 frame을 stacking 하는 대신, short term temporal context는 time delay DNN 구조에 의해 처리됩니다.
Neural network architecture
위 그림과 같이 network는 speech frame에서 동작하는 layer들로 이루어져 있습니다. 그리고 statistics pooling layer을 사용하여 frame level 표현을 aggregate합니다. 추가적인 layer는 segment level에서 동작하며, 마지막으로 softmax output layer가 붙은 형태입니다. activation function으로는 ReLU를 사용했습니다.
처음 5개의 layer는 frame level이며, time delay 구조(time delay neural network, TDNN)를 사용합니다. t가 현재 time step이라 하겠습니다. input에서 {t-2, t-1, t, t+1, t+2} frame을 함께 연결합니다. 그 다음 두개의 layer는 각각 이전 layer의 output을 {t-2, t, t+2} 및 {t-3, t, 3+3}에서 연결합니다. 그 다음 두 layer도 frame level에서 동작하지만, 더이상 시간적 context의 추가는 없습니다. 전체적으로 frame level 부분을 보면, t-8에서 t+8 layer까지의 temporal context를 가집니다. layer의 크기는 splicing context에 따라 512에서 1536까지 다양합니다.
statistic pooling layer는 마지막 frame level layer의 output을 input으로 받습니다. input segment를 aggregate하고 평균과 표준편차를 계산합니다. segment level statistcs은 서로 연결되고, 추가적은 2개의 hidden layer에 들어갑니다. 두 layer의 차원은 512와 300입니다. 마지막으로 softmax output layer을 거치면 마무리됩니다. softmax output layer을 제외하면, 총 4.4million parameter가 사용됩니다.
Training
network는 training speakers를 multiclass cross entropy function로 분류할 수 있도록 학습됩니다. 저자들의 system은 frame이 아닌 가변 길이의 segment에서도 speaker를 예측할 수 있도록 학습됩니다.

K명의 speaker가 N개의 training segment에 있다고 하자. T개의 input frame x_1, ... , x_T가 주어졌을 때, speaker k일 확률은 위 식의 P부분 입니다. d_nk의 경우, segment n에서의 speaker label이 k일 때, 1이고 나머지의 경우에서는 0입니다.
저자들은 GPU memory의 한계를 고려하여 minibatch size를 32에서 64 사이로 설정하고, 음성은 2초에서 10초 사이로 설정했습니다(이는 200에서 1000frame이 됩니다). 그리고 natural gradient stochastic gradient descent를 사용해 학습했다고 합니다.
Speaker embeddings
결국 network를 학습하는 것의 목표는 train data에서 보지 못한 speaker에게도 잘 일반화된 embedding을 생성하는 것입니다. 저자들은 embedding이 frame-level보단 전체 발화에 걸쳐 speaker characteristic을 capture하길 원합니다. 그래서 statistics pooling layer 이후의 모든 layer는 embedding을 추출하기에 적절한 위치입니다. 저자들은 speaker수의 따라 달라지는 크기가 큰 presoftmax affine layer를 사용하지 않습니다. 저자들은 network 그림에서 볼 수 있듯이, a, b 부분이 있는데, embedding a는 statistic와 바로 연결된 affine layer의 output입니다. embedding b는 ReLU를 거치고 나온 값이 연결되는 affine layer로 부터 추출된 값이고, 이는 non linear statistic입니다. 이는 동일한 DNN에서 구해진 값들이기 때문에 embedding b는 embedding a의 내용을 다루고 있습니다.
PLDA backend
embedding은 centered되고 LDA를 이용해 차원이 감소됩니다. i-vector system처럼, original의 25%에 해당하는 LDA 차원을 사용해도 동작을 잘한다고 합니다. 차원을 감소한 후에, embedding은 length normalize되고 embedding 쌍이 PLDA에 의해 비교됩니다. PLDA score는 adaptive s-norm에 의해 정규화됩니다. a or b or a와 b의 조합을 embedding으로 사용합니다. embedding을 concat하는 대신, 저자들은 a와 b를 따로 PLDA backend하여 점수를 평균화했습니다.

해당 그림은 PLDA score를 설명한 그림입니다. u1, u2는 latent space에서 오는 example입니다. v는 latent space를 의미합니다.
s-norm을 사용하면, 점수들의 분포를 조정하여 다양한 환경 및 외부 요인에 의해 영향을 덜 받도록 하는데 도움을 줍니다.
s-norm은 t-norm와 z-norm으로 이루어집니다.
t-norm은 test speaker embedding과 non target speaker embedding들 간의 PLDA 점수를 구합니다. 해당 점수 분포에서 평균과 분산을 구한 후 test speaker embedding과 target speaker embedding사이의 점수를 정규화합니다.
z-norm은 target speaker embedding과 non target speaker embedding들 간의 PLDA 점수를 구합니다. 해당 점수 분포에서 평균과 분산을 구한 후 test speaker embedding과 target speaker embedding 사이의 점수를 정규화합니다.
이렇게 구한 두 normalized score를 결합하면 됩니다. 일반적으로 평균화합니다. 이렇게 최종 adaptive s-norm을 거친 PLDA 점수를 얻을 수 있습니다.
이렇게 a와 b를 이용한 PLDA score를 구한 후 정규화 하고 두 score의 평균을 구해 사용했다고 합니다.
Experiments
Training data
총 6500명의 speaker로부터 65000개의 recording을 가지고 학습했습니다. i-vector와 embedding system 둘 다 evaluation score를 normalization했습니다.
Evaluation
저자들의 evaluation은 extended core condition 5 and 10s-10s condition에서 진행됩니다. core SRE10 condition을 보완하기 위해, 저자들은 erollment utterance는 full length를 유지하되, test utterance는 잘라서 사용합니다. 10s-10s condition에서는 SRE10의 일부로, 10초의 speech를 사용하여 test와 enrollment를 진행합니다.
Results
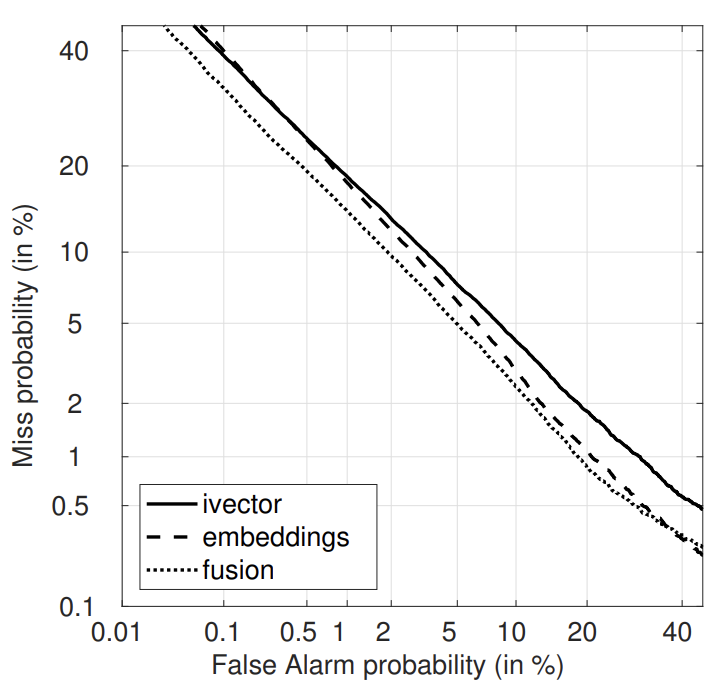
위 표에서 embeddings은 embedding a와 embedding b에서 구한 PLDA score의 평균을 의미합니다. fusion의 경우, i-vector와 embeddings의 동일한 weighted를 갖는 sum fusion을 의미합니다.

위 표는 utterance length에 따른 선능을 보여줍니다. i-vector아 여전히 longest recording에선 가장 좋은 성능을 보이지만, test utterance 길이가 줄어들면 저자들이 제안한 방식의 성능이 더 좋은 것을 알 수 있습니다. 저자들이 제안한 embeddings는 enrollment와 test utterance의 길이가 짧을 때, i-vector보다 훨씬 좋은 모습을 보였습니다.
i-vector와 DNN system은 매우 다르기 때문에, 그 둘을 섞었을 때 좋은 성능을 기대할 수 있었습니다. 그래서 저자들은 fusion한 결과도 비교해봤습니다. fusion은 모든 조건에서 ivector에 비해 좋은 결과를 얻을 수 있었습니다.

위 표를 보면, i-vector와 embedding은 english train data로 학습되었지만, test는 다른 언어로 한 결과입니다. 이 결과를 보았을 때, embedding이 domain mismatch에서 더 강건한 모습을 보인다는 걸 알 수 있습니다.
Conclusion
저자들은 text independent speaker verification에 사용할 수 있는 DNN embeding을 제안했습니다. i-vector에 비해 충분히 경쟁력있는 결과를 보였으며 fusion되었을 때 더 좋은 모습을 보였습니다. i-vector는 full length에 더 효과적이였으며, 저자들이 제시한 embedding은 short condtion에서 더 좋은 모습을 보였습니다. 그리고 embedding이 domain mismatch에서 더 강건한 모습을 보입니다. 저자들은 PLDA가 embedding에 완전 최적화된 측정방식이 아닐 수 있다고 생각하며, 앞으로 다른 방향으로 연구를 진행하겠다고 합니다.
'연구실 공부' 카테고리의 다른 글
| [논문] End-to-End Text-Dependent Speaker Verification (0) | 2024.02.04 |
|---|---|
| [논문] X-Vectors: Robust DNN Embeddings For Speaker Recognition (0) | 2024.02.02 |
| [논문] Deep Neural Networks for Small Footprint Text-dependent Speaker Verification (0) | 2024.01.31 |
| GMM supervector, Eigenvoice vector, JFA, I-vector (0) | 2024.01.31 |
| [논문] Front-End Factor Analysis for Speaker Verification (0) | 2024.01.30 |



