https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=6854363
Deep neural networks for small footprint text-dependent speaker verification
In this paper we investigate the use of deep neural networks (DNNs) for a small footprint text-dependent speaker verification task. At development stage, a DNN is trained to classify speakers at the framelevel. During speaker enrollment, the trained DNN is
ieeexplore.ieee.org
해당 논문을 보고 작성했습니다.
Abstract
저자들은 small footprint text-dependent speaker verification task에 Deep Neural Networks를 적용하는 연구를 진행했습니다. small footprint란, 상대적으로 적은 자원을 사용하는 것을 의미합니다. development 단계여서, DNN은 frame 단위로 speaker를 분류하기 위해 학습됩니다. speaker enrollment에선, last hidden layer에서 speaker의 특정 feature를 extract하는 데 학습된 DNN이 사용됩니다. 이러한 speaker feature의 평균, 또는 d-vector는 speaker model로 사용됩니다.
evaluation 단계에선, d-vector는 각 발화에서 추출되고 verification decision을 하기 위해 등록된 speaker model과 비교를 진행합니다. 실험을 통해 small footprint text-dependent speaker verification task에서 유명한 i-vector보다 더 좋은 성능을 보인다는 것을 입증합니다. 그리고 DNN 기반 system은 첨가된 소음에 더 강건하며, false rejection operating point가 낮은 상황에서 i-vector보다 더 좋은 성능을 보입니다.
Introduction
speaker verification(SV)은 그/그녀의 speech signal로부터 얻은 정보를 기반으로 speaker를 accept할지 reject할 지 정하는 task입니다. SV는 text-dependent와 text-independent로 나눌 수 있습니다. text-dependent SV는 정해진 text로 생성된 speech를 가지고 진행하는 방식입니다.
이 논문에서는 small footprint text-dependent SV task에 focusing합니다.
먼저 SV process를 보겠습니다.
- Development: background model이 speaker manifold를 정의하기 위해 대규모 data로 학습됩니다. background model은 다양합니다.
- Enrollment: speaker-dependent model을 얻기 위해 speaker의 특정한 정보를 가지고 새로운 speaker를 등록하는 과정입니다.
- Evaluation: 각 test 발화는 등록된 speaker model과 background model을 이용하여 평가됩니다. decision은 test speaker를 accept할지, reject할지 정하는 것입니다.
여태까지 SV system은 여러 통계적 tool을 통해 연구되었습니다. i-vector 기반 SV system, probabilistic linear discriminant analysis(PLDA) 등 존재합니다. 이러한 system들은 JFA를 feature extractor로 사용합니다. JFA는 SV를 위해 speech 발화의 내용을 압축한 저차원의 i-vector를 추출합니다.
저자들은 DDN을 feature extractor로 사용하는 SV를 제안했습니다. 새로운 종류의 DNN based background model은 speaker space를 바로 modeling합니다. DNN은 frame level feature를 speaker identity target으로 mapping하도록 학습된니다. enrollment동안에, speaker model은 DNN의 last hidden layer로부터 고안되는 activation의 평균으로 계산되며, 이를 'deep vector' 또는 'd-vector'라고 부릅니다. evaluation에선, target d-vector와 test d-vector의 거리를 이용해 결정합니다. i-vector SV system과 유사한 형태입니다(i-vector는 cosine distance scoring 방식으로 decision하니까).
DNN을 사용할 때 얻는 이점으로, 최근 등장한 speech recognition과 쉽게 통합될 수 있습니다. DNN inference engine과 filterbank energies frontend를 공유할 수 있기 때문입니다.
Previous Work
i-vector와 PLDA를 결합하여 사용하는 방식이 text-independent speaker recognition task에서 주로 사용되었습니다. i-vector은 total variability space라고 불리는 저차원 space에서 발화를 표현합니다. 발화가 주어졌을 때, speaker/session dependent GMM supervector는

이와 같은 식으로 표현됩니다. m은 speaker/session independent supervector이고 주로 UBM supervector입니다. T는 rectangular matrix of low rank이며, total variability marix(TVM)입니다. w는 standard normal distribution에서 얻어지는 random vector입니다. w는 total factor를 포함하며 i-vector라 불립니다.
i-vector에 PLDA를 적용하여 total variability를 speaker variability와 session variability로 분해할 수 있습니다. 이는 JFA보다 더 효율적인 방식이며, text-dependent speaker recognition에서도 성공적인 모습을 보였습니다.
neural network를 활용한 speaker recognition 연구들도 등장했습니다. nonlinear classifier로서, neural network는 다른 speaker의 특징을 구별할 수 있습니다. neural network는 일반적으로 이진 분류기 또는 multicategory 분류기로 사용되었습니다. auto-associative neural networks(AANN)은 UBM-AANN과 speaker specific AANN의 reconstruction erro difference를 verification score로 사용하는 방식을 제안했습니다. Multi-layer perceptrons(MLPs) with bottleneck layer는 speaker recognition을 위한 robust feature를 얻어내는데 사용되었습니다. 더 최근엔, convolutional deep belief network나 Boltzmann machine classifier와 같은 deep learning을 speaker recognition에 사용하기 위한 초기 연구가 진행되었습니다.
DNN for Speaker Verification
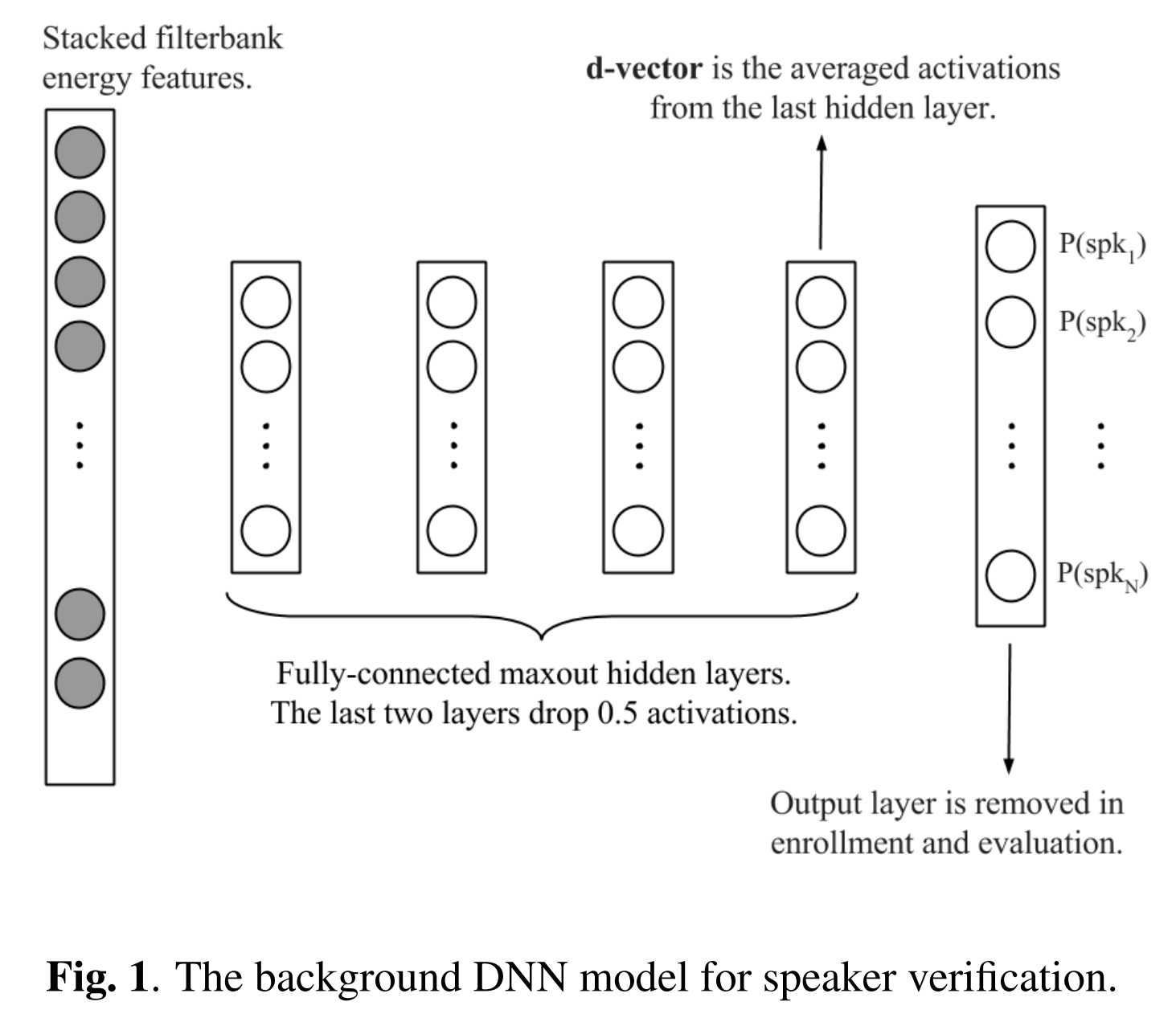
저자들이 제안한 background DNN model은 위 그림과 같습니다. neural network은 speaker specific feature를 학습합니다. 저자들은 supervised learning을 하고, DNN을 사용합니다.
DNN as a feature extractor
저자들이 제안한 방식의 핵심은, DNN을 speaker feature extractor로 사용한다는 점입니다. i-vector 방식처럼 speaker acoustic frame을 보다 추상적이고 간결한 형태로 표현하려고 합니다.
그래서 저자들은 frame level에서 development set에서 speaker를 분류하는 supervised DNN을 먼저 구축합니다. 이 background network의 input은 각 training frame을 left & right context frame과 함께 쌓아올리는 형태입니다. output의 수는 development set에 있는 speaker 수에 해당합니다. 이를 N으로 나타냅니다. target label은 1-hot N차 vector로 표현됩니다. speaker identity만 1이고 나머지는 다 0입니다.
DNN이 성공적으로 학습된다면, last hidden layer의 output activation을 새로운 speaker 표현으로 사용합니다. 새로운 speaker에 속하는 주어진 발화들의 모든 frame에 대해, 학습된 DNN에 standard feedforward propagation을 진행해 last hidden layer의 output activation을 얻습니다. 그리고 그렇게 나온 결과를 누적하여 새로운 형태로 speaker를 표현합니다. 이를 d-vector라 합니다.
softmax output layer 대신 마지막 hidden layer로부터 얻은 output을 사용하는 데에는 2가지 이유가 있습니다. 먼저, 출력 계층을 제거해 runtime에서 DNN model 크기를 줄일 수 있으며, development set의 speaker 수를 늘리더라도 DNN size를 키우지 않아도 사용할 수 있기 때문입니다. 두번째로, last hidden layer output으로부터 더 나은 speaker generalization을 발견할 수 있었기 때문입니다.
Enrollment and evaluation
speaker s로부터 X_s = {O_s1, O_s2, ..., O_sn}이라는 발화 집합이 주어졌을 때, 관측값 O_si = {o_1, o_2, .... , o_m}을 가지고 enrollment 하는 과정은 다음과 같습니다.
먼저, O_si에 있는 모든 관측 o_j를 context와 함께 사용하여, supervised trained DNN에 넣습니다. last hidden layer의 output이 나오게 될 갓이고, L2 normalization을 한 다음, 모든 observation을 누적합니다. speaker s에 대한 최종 표현은 발화 X_s의 발화에 해당하는 d-vector의 평균을 내어 도출합니다.
evaluation 과정 중에는, test utterance로부터 정규화된 d-vector를 추출합니다. 그 다음 test d-vector와 요청된 speaker의 d-vector 사이의 cosine distance를 계산합니다. cosine distance와 threshold를 비교하여 최종 verification decision을 하면 됩니다.
DNN training procedure
"ok google"이라는 같은 구절을 여러 번, 여러 session에 걸쳐 말하고 있는 646명의 speaker를 포함한 dataset을 가지고 학습합니다. 성별은 balance 잡혀있고, 496명의 speaker가 background model을 학습하기 위해 random하게 선택해 사용되었습니다. 그리고 남아있는 150명의 speaker는 enrollment와 evaluation에 사용되었습니다. 한명의 speaker의 발화수는 60에서 130 사이입니다. enrollment speaker의 경우, 처음 20개의 발화는 enrollment에 사용되고, 남은 발화는 evaluation에 사용되었습니다. 기본적으로 speaker model을 추출하기 위해 enrollment 발화 중 처음 4개를 사용했습니다.
이와 같은 dataset 형태에서 DNN을 학습하는 과정을 보겠습니다. background DNN을 maxout DNN using dropout의 형태로 학습합니다. DNN을 small training set으로 학습할 때, dropout을 사용하면 overfitting을 예방할 수 있습니다. maxout DNN은 dropout의 특성을 적절히 활용하기 위해 고안되었습니다. maxout network는 standard MLP와 달리 각 계층에 있는 hidden unit이 중복되지 않는 group으로 나눠집니다. 각 group은 max pooling을 통해 single activation을 생성합니다(즉, 중복되지 않는 group들로 unit이 나눠지고, 각 group마다 max pooling을 적용해 각 group의 single activation을 생성한다는 말). maxout network를 학습하는 것은 각 unit의 activation function을 optimize할 수 있습니다.
저자들은 maxoutDNN을 256개의 node로 이루어진 4개의 hidden layer로 구현합니다. pool size 2를 모든 layer에 적용했습니다. 처음 2개의 layer는 dropout을 사용하지 않습니다. 남은 2개의 layer는 50% dropout을 적용합니다.
다른 parameter에 관련해서, 저자들은 hidden unit에 적용할 non-linear activation function으로 recitified linear unit(ReLU)을 사용했으며, learning rate는 0.001로 설정한 다음 5M step마다 0.1씩 감소하도록 했습니다.
DNN의 input은 주어진 frame과 context frame을 통해 추출된 log filterbank energy feature 쌓아 40차원으로 만들었습니다. 이때 left로 30 frame, right로 10 frame에 해당된다고 합니다. 총 41개의 frame이 들어오고 각 frame마다 40차원의 stack이 형성되는 모습입니다. training target vector의 차원은 496이고, 이는 development set의 speaker 수와 동일합니다. 최종 maxout DNN model은 600K개의 parameter를 가지고 있으며, 가장 작은 i-vector system과 유사합니다.
Experimental Results
Baseline system

small footprint text-dependent SV task에서, 저자들은 좋은 성능을 위해 model size를 작게 했습니다. baseline system으로 i-vector based SV system을 선택했습니다. equal error rate(EER)을 이용해 다른 크기의 i-vector system에 대한 결과를 보이고 있습니다. 위 표에서 알 수 있듯이, i-vector system의 성능은 model size가 줄어들면서 저하됩니다. 그래도 t-norm을 이용해 성능을 향상시켰습니다. 그래서 저자들은 가장 크기가 작은 540K개의 parameter로 이루어진 i-vector model을 기준으로 삼고 실험을 진행했다고 합니다.
DNN verification system

왼쪽 그래프를 보겠습니다. 왼쪽 그래프는 detection error tradeoff(DET) curve를 보여줍니다. d-vector system의 raw score가 t-norm score에 비해 약간 더 좋은 것을 볼 수 있습니다. 반면에i-vector system은 t-norm score가 상당히 더 결과가 좋습니다. d-vector system의 raw score을 histogram 분석하면, normal distribution이 아니라 heavy tailed distribution인 것을 알 수 있습니다. d-vector SV system에서 더 정교한 score normalization method가 필요하다는 것을 의미할 수도 있습니다. 게다가, t-norm은 추가적인 저장공간과 연산 시간이 걸리므로, 앞으로 d-vector system을 raw score로 평가하겠다고 합니다.
i-vector system의 전반적인 성능은 d-vector system보다 뛰어납니다. 그러나, 위 두 그래프에서 low False Rejection 부분, 즉 우측 하단 부분을 부면, d-vector system이 i-vector보다 뛰어난 성능을 보입니다.
저자들은 DNN model의 각 layer의 node수를 늘려보기도 하고, maxout을 없애는 등 다양한 방식으로 여러 training을 해봤지만 다 좋지 않은 결과를 얻었습니다.
Effect of enrollment data
d-vector SV system에서, enrollment 단계에는 speaker adaptation 통계가 관련되어 있지 않습니다. 대신, background DNN model이 enrollment와 evaluation 과정에서 각 speaker에 대한 speaker specific feature를 추출하는 역할을 합니다. 그래서 저자들은 speaker마다 enrollment할 때 사용되는 발화 수를 변경하면서 verification 성능을 비교했습니다.

이와 같이 발화 수가 늘어날수록 두 system모두 EER 값이 낮아지는 것을 알 수 있습니다.
Noise robustness
development와 runtime condition은 일반적으로 약간 다릅니다. 저자들은 실험을 통해 d-vector SV system이 i-vector system에 비해 noisy condition에 대해 robustness함을 보이니다. clean data로 두 model을 학습하고, enrollment와 evaluation data에는 10dB cafetria noise를 추가했습니다. 오른쪽 그래프와 같이, 두 system 모두 성능이 떨어진 것을 볼 수 있습니다. 하지만, d-vector system이 성능 하락이 덜 일어났습니다. 10dB보다 더 작은 noise가 있을 땐, d-vector system의 성능이 i-vector system의 성능과 매우 유사했습니다.
System combination
결국 d-vector의 경우, 가볍고 noise에 강건하며, false rejection rate가 낮아야 하는 경우 더 적합합니다. 저자들은 i/d-vector system이라는 결합한 형태의 system도 분석합니다.

feature level에서 combination을 더 복잡하게 적용할 수도 있지만, 위 그래프는 i-vector와 d-vector를 sum fusion만 했습니다. 각 trial 때마다 각 system들의 score를 더했습니다. score 결합을 용이하게 하기 위해 두 system 모두에 t-norm이 적용되었습니다. 결과는 위와 같습니다. 모든 condition에서 우수한 결과를 보이는 것을 알 수 있습니다.
Conclusions
small footprint text-dependent speaker verification task에 사용할 수 있는 새로운 DNN 기반 speaker verification method를 소개합니다. 학습된 DNN은 speaker specific feature를 추출합니다. speaker feature의 평균을 d-vector라고 합니다. 실험을 통해 SV system에서의 d-vector의 성능을 확인했습니다. noise에 강건해야 하고 가벼우며 false rejection rate가 낮아야 할 땐, d-vector를 사용하는 것이 효과적인 것을 확인했으며, d-vector와 i-vector를 fusion하면 더 향상된 결과를 얻을 수 있습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] X-Vectors: Robust DNN Embeddings For Speaker Recognition (0) | 2024.02.02 |
|---|---|
| [논문] Deep Neural Network Embeddings for Text-Independent Speaker Verification (0) | 2024.02.01 |
| GMM supervector, Eigenvoice vector, JFA, I-vector (0) | 2024.01.31 |
| [논문] Front-End Factor Analysis for Speaker Verification (0) | 2024.01.30 |
| 음성 인식 관련 용어 정리 (0) | 2024.01.28 |



